




简介
StreamSets Data Collector(一般简称StreamSets),是一款开源的实时大数据集成工具。它面向用户提供了简洁易用的操作界面,通过构建实时数据管道(Pipeline)的方式,将数据从源端(Origin)摄取后,经过中间过程处理(Processor),最终保存到目的端(Destination),从而实现实时数据的ETL流程构建。
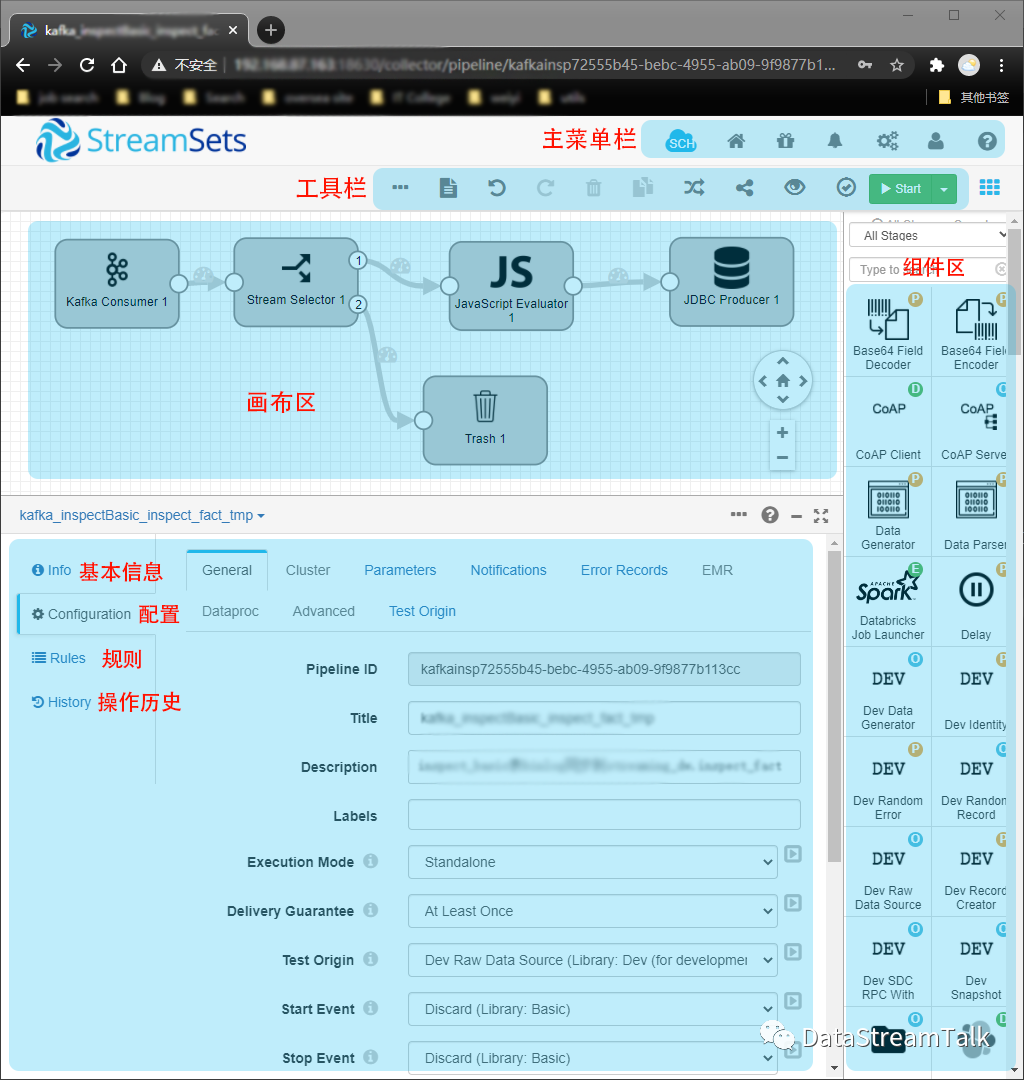
图一:pipeline编辑状态的StreamSets
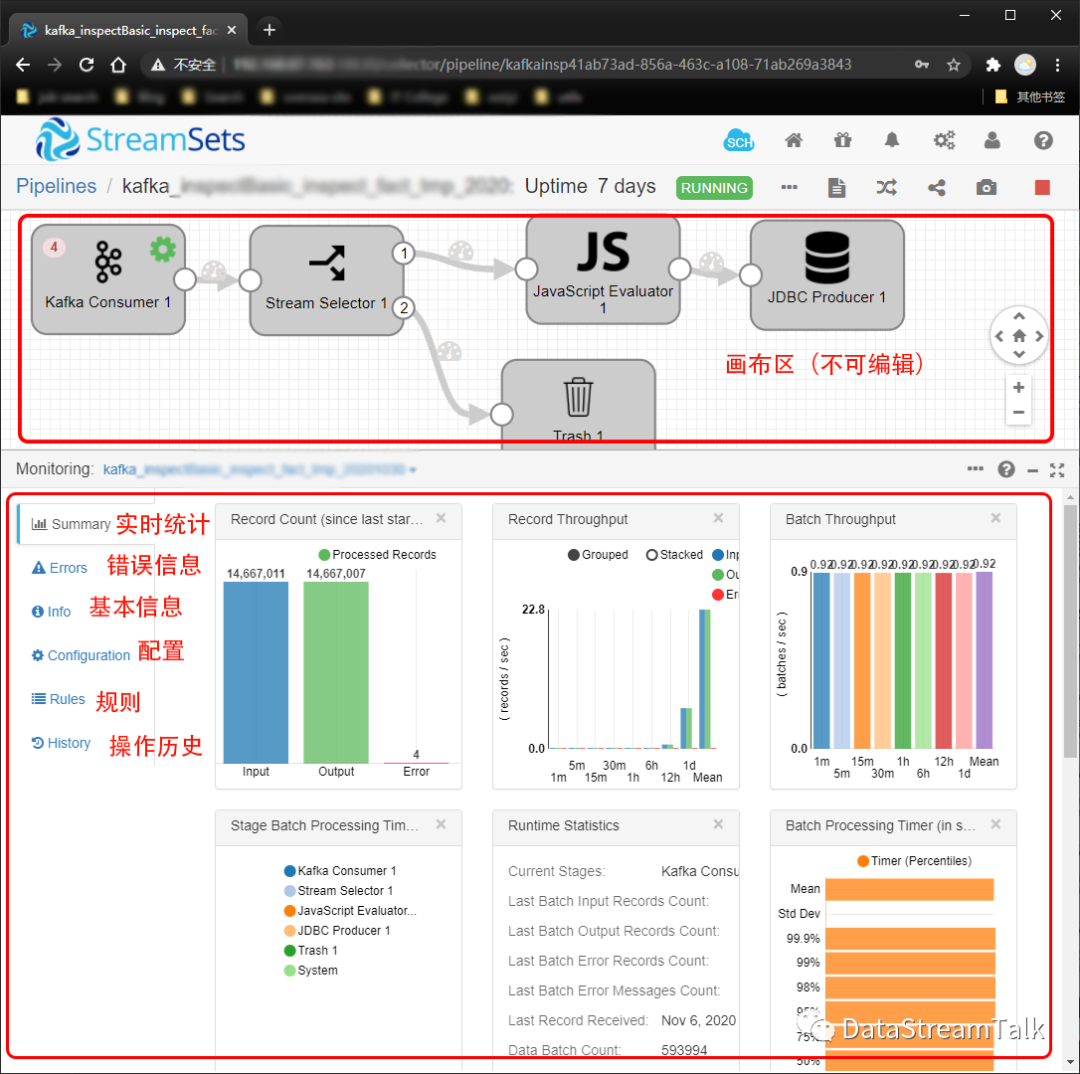
图二:pipeline运行状态的StreamSets
2.StreamSets基本概念:
Pipeline-顾名思义,就是数据流管道,每个Pipeline都有唯一的数据源采集端(Origin),多个中间转换器(Processor),以及多个目的端(Destination)用于接收最终的数据。
(1) Origin-数据源采集端,每个Pipeline的数据都是通过Origin组件接收,然后交给后续的步骤
(2) Destination-数据接收端,用于接收前置步骤处理好的数据
(3) Processor-中间转换器,介于Origin和Destination之间的组件,用于对上游的数据进行各种转换/过滤操作,每个Pipeline可以使用多个Processor协同进行数据处理。
ETL-在一个完整的Pipeline定义中,Origin对应的是Extract,Processor对应着Transform,Destination则对应着Load步骤。
3.Pipeline开发
确定好数据采集的来源,数据存放位置,中间处理逻辑后,就能快速基于StreamSets搭建对应的数据加工处理管道,编码量几乎为0。
4.StreamSets相关资源
(1)官方网站:
https://streamsets.com/
(2)官方教程:
https://streamsets.com/documentation/datacollector/latest/help/datacollector/UserGuide/Tutorial/Tutorial-title.html
(3) github:
https://github.com/streamsets/datacollector
5.StreamSets和其它ETL工具对比
StreamSets Data Collector定位是数据集成平台,不仅仅是ETL工具。和主流ETL工具相比较(Alibaba DataX,Canal,Sqoop),StreamSets有以下优势:
(1)支持CDC(changed data capture)技术,能实时捕捉rdbms数据库的数据变更(canal也有类似功能)
(2)数据源支持非常广泛,关系型数据库/消息队列/HDFS/本地文件/日志流,基本囊括了各类型主流的数据源结构
(3)通过丰富的插件机制,能实现ETL流程中的各种数据转换/过滤/映射操作,比DataX/Canal更强大
(4)UI界面简介易用,上手非常容易,所有的功能插件被分为4大类,能触类旁通,学习成本低
(5)监控及故障处理机制比较完善,能基于事件机制触发故障上报及处理。
