





前提条件
需要安装好helm3,参考helm安装与使用。
添加仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add stable https://charts.helm.sh/stable
helm repo update
获取helm模板值
修改改文件配置邮件告警,持久化等。
[root@ecs-6272 ~]# helm show values prometheus-community/kube-prometheus-stack > /tmp/values.yaml
如果已经部署了,修改完配置用helm upgrade
可以更新配置。
[root@ecs-6272 ~]# helm upgrade --install prometheus prometheus-community/kube-prometheus-stack -f values.yaml
配置邮件告警示例
修改values.yaml
## Alertmanager configuration directives
config:
global:
resolve_timeout: 5m
smtp_from: 'vickeywu557@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: 'vickeywu557@qq.com'
smtp_auth_password: 'POP3/SMTP授权码'
smtp_require_tls: false
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'test-alert'
routes:
- match:
alertname: Watchdog
#alertname: DeadMansSnitch
receiver: 'test-alert'
receivers:
- name: test-alert
email_configs:
- to: 'vickeywu557@qq.com'
配置动态卷
1.安装nfs
如果用云服务商的nas可忽略,如果使用自建nfs首先要安装好nfs服务,自行百度或参考k8s实践记录(二)中nfs安装。我这里挂载的共享目录是/share
,将/share/dynamic
子目录作为prometheus
的动态卷目录。
2.配置nfs动态卷
所需yaml文件从github仓库复制过来修改一下nfs变量your_nfs_server_ip, your_nfs_share_dir,还有namespace改为跟安装prometheus的namespace一致,然后kubectl apply -f .
安装即可。
https://github.com/Vickey-Wu/nfs-provisioner
[root@ecs-6272 nfs-provisioner]# kubectl apply -f storageclass.yaml
storageclass.storage.k8s.io/managed-nfs-storage created
[root@ecs-6272 nfs-provisioner]# kubectl get sc
NAME PROVISIONER AGE
managed-nfs-storage vickey-wu.com/nfs 4s
[root@ecs-6272 nfs-provisioner]# kubectl apply -f rbac.yaml
serviceaccount/nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
[root@ecs-6272 nfs-provisioner]# kubectl get rolebindings.rbac.authorization.k8s.io
NAME AGE
leader-locking-nfs-client-provisioner 19s
[root@ecs-6272 nfs-provisioner]# kubectl apply -f deployment.yaml
deployment.apps/nfs-client-provisioner created
[root@ecs-6272 nfs-provisioner]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-7fc4bcf9c7-9nz9g 1/1 Running 0 73s
3.使用动态卷持久化
修改values.yaml,将storageClassName值替换为创建的managed-nfs-storage
prometheus
## Prometheus StorageSpec for persistent data
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: managed-nfs-storage
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 10Gi
alertmanager
storage:
volumeClaimTemplate:
spec:
storageClassName: managed-nfs-storage
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 10Gi
grafana
grafana本身没有提供持久化配置,我用下面的配置持久化好像也不行。。。可以查看github issue
https://github.com/prometheus-community/helm-charts/pull/323
persistence:
type: pvc
enabled: true
finalizers:
- kubernetes.io/pvc-protection
existingClaim: prom-grafana
安装kube-prometheus-stack
[root@ecs-6272 tmp]# helm install prometheus prometheus-community/kube-prometheus-stack -f values.yaml
NAME: default
LAST DEPLOYED: Mon Nov 9 11:33:04 2020
NAMESPACE: prometheus
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace default get pods -l "release=prometheus"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
第一次部署需要拉一堆镜像,等了14分钟终于起来了,还有就是alertmanager启动比其他容器慢。
[root@ecs-6272 tmp]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 44s
pod/nfs-client-provisioner-7fc4bcf9c7-9nz9g 1/1 Running 0 86m
pod/prometheus-grafana-85f8846978-phfhj 2/2 Running 0 81s
pod/prometheus-kube-prometheus-operator-8d69c4598-584vq 1/1 Running 0 81s
pod/prometheus-kube-state-metrics-6df5d44568-mcblx 1/1 Running 0 81s
pod/prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 26s
pod/prometheus-prometheus-node-exporter-m58hs 1/1 Running 0 81s
pod/prometheus-prometheus-node-exporter-w4rrl 1/1 Running 0 81s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 45s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7d
service/prometheus-grafana ClusterIP 10.103.121.152 <none> 80/TCP 81s
service/prometheus-kube-prometheus-alertmanager ClusterIP 10.108.151.27 <none> 9093/TCP 81s
service/prometheus-kube-prometheus-operator ClusterIP 10.109.9.191 <none> 443/TCP 81s
service/prometheus-kube-prometheus-prometheus ClusterIP 10.100.218.177 <none> 9090/TCP 81s
service/prometheus-kube-state-metrics ClusterIP 10.97.253.143 <none> 8080/TCP 81s
service/prometheus-operated ClusterIP None <none> 9090/TCP 26s
service/prometheus-prometheus-node-exporter ClusterIP 10.110.221.110 <none> 9100/TCP 81s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-prometheus-node-exporter 2 2 2 2 2 <none> 81s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nfs-client-provisioner 1/1 1 1 86m
deployment.apps/prometheus-grafana 1/1 1 1 81s
deployment.apps/prometheus-kube-prometheus-operator 1/1 1 1 81s
deployment.apps/prometheus-kube-state-metrics 1/1 1 1 81s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nfs-client-provisioner-7fc4bcf9c7 1 1 1 86m
replicaset.apps/prometheus-grafana-85f8846978 1 1 1 81s
replicaset.apps/prometheus-kube-prometheus-operator-8d69c4598 1 1 1 81s
replicaset.apps/prometheus-kube-state-metrics-6df5d44568 1 1 1 81s
NAME READY AGE
statefulset.apps/alertmanager-prometheus-kube-prometheus-alertmanager 1/1 44s
statefulset.apps/prometheus-prometheus-kube-prometheus-prometheus 1/1 26s
验证持久化
可以看到共享目录已经自动创建了一个prometheus的目录,k8s也自动创建了pv及pvc。
[root@ecs-6272 tmp]# ls /share/dynamic/
default-prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0-pvc-bb6edf5c-2eef-49dd-b433-cb39db32df79
[root@ecs-6272 tmp]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-bb6edf5c-2eef-49dd-b433-cb39db32df79 10Gi RWX Delete Bound default/prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 managed-nfs-storage 90s
[root@ecs-6272 tmp]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-prometheus-kube-prometheus-prometheus-db-prometheus-prometheus-kube-prometheus-prometheus-0 Bound pvc-bb6edf5c-2eef-49dd-b433-cb39db32df79 10Gi RWX managed-nfs-storage 99s
访问grafana
修改svc的端口类型为type: NodePort
保存退出即可自动分配一个端口给prometheus,然后用公网加该端口在浏览器就可访问了,当然,云服务器安全组记得将该端口放通。也可以在ports
下指定端口如nodePort: 31524
,同样方法将grafana端口修改为31525
以便访问。grafana 默认账号密码为admin:prom-operator
[root@ecs-6272 ~]# kubectl edit svc prometheus-prometheus-oper-prometheus
service/prometheus-prometheus-oper-prometheus edited
[root@ecs-6272 ~]# kubectl edit svc prometheus-grafana
service/prometheus-grafana edited
prometheus-operator
自带了一些默认的模板,在首页dashboard > manage可以看到。
创建自定义看板,在首页create > add new panel > Metrics > 输入监控项名,如disk选中包含的监控项 > apply即可

去grafana官方模板库查找更多模板,找到想要的模板,复制id。然后在grafana的dashboard > manage > import > 填写id > load > VictoriaMetrics选择metrics > import 就可以看到已经应用了该模板。
https://grafana.com/grafana/dashboards
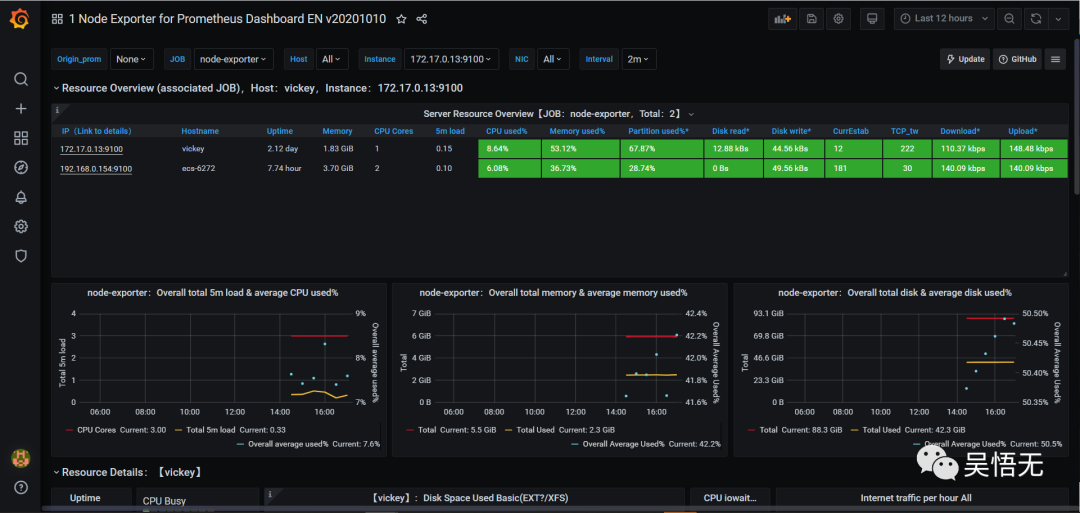
验证邮件告警
当prometheus服务起来后会监控k8s集群组件的监控,因为我是单节点etcd,它就会开始告警发送邮件了。
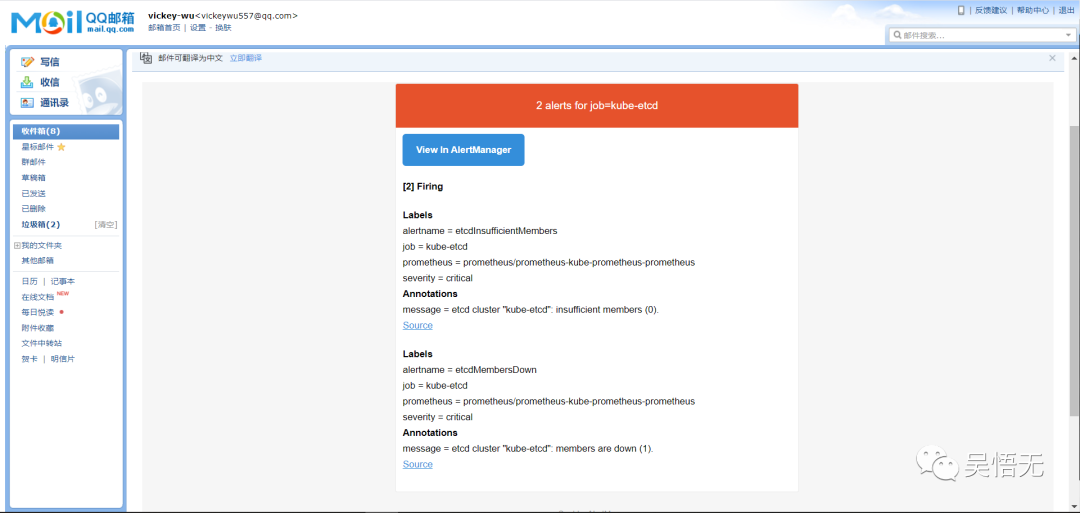
不过奇怪的是在grafana的alerting页面使用email测试一直是失败的。。。希望有大佬能告诉我。
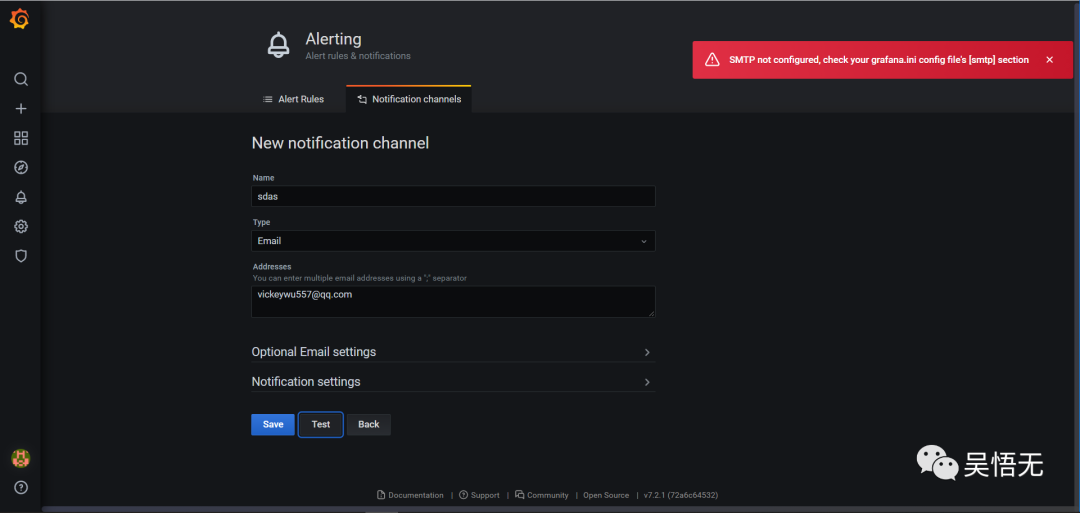
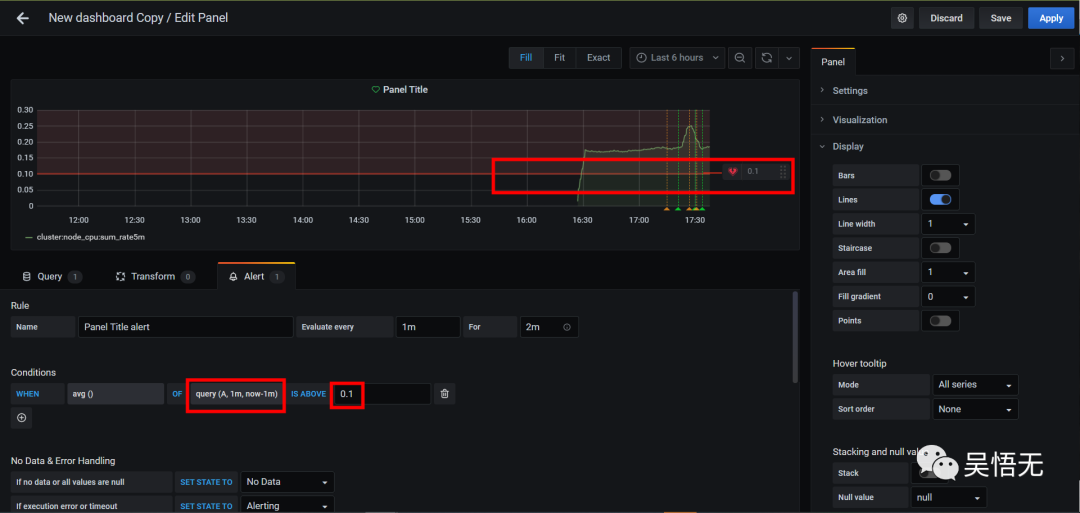
测试钉钉告警
创建一个钉钉群机器人;在grafana首页alerting创建一个钉钉的通知频道,将机器人的Webhook地址加进去即可;最后在自定义看板的页面下的alert位置设置合理的告警条件,点击测试即可。

参考文章
https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
https://github.com/prometheus-community/helm-charts/issues/250
https://www.youtube.com/watch?v=CmPdyvgmw-A
