




Vertica监控
怎么监控Vertica数据库?从哪些方面进行监控?本文从以下几个方面进行阐述,并给出相应的脚本。
- 系统健康
- 资源使用
- 活动的session
- 活动的事务
- 故障恢复
- 数据重分布
- Historical activities
- 统计信息
- 查询性能
- Monitor DataCollector tables
系统健康
节点状态
当一个节点挂了过后,节点状态会变成DOWN,自然该节点的LGE不会往前推,数据库AHM亦不会往前走,如果此时再遇到硬件故障、机房掉电等原因导致整个集群宕机,会导致数据丢失,所以监控节点状态就变得非常重要。
可以通过以下几个方法查看节点状态:
select node_name,
node_state
from nodes
order by node_name;
node_name | node_state
------------------+------------
v_vmart_node0001 | UP
v_vmart_node0002 | UP
v_vmart_node0003 | DOWN
(3 rows)
[dbadmin@szxtsp101 ~]$ admintools -t view_cluster
DB | Host | State
-------+-----------------+-------
vmart | 192.168.100.101 | UP
vmart | 192.168.100.102 | UP
vmart | 192.168.100.103 | DOWN
[dbadmin@szxtsp101 ~]$ admintools -t list_allnodes
Node | Host | State | Version | DB
------------------+-----------------+-------+-----------------+-------
v_vmart_node0001 | 192.168.100.101 | UP | vertica-8.1.1.2 | vmart
v_vmart_node0002 | 192.168.100.102 | UP | vertica-8.1.1.2 | vmart
v_vmart_node0003 | 192.168.100.103 | DOWN | vertica-8.1.1.2 | vmart
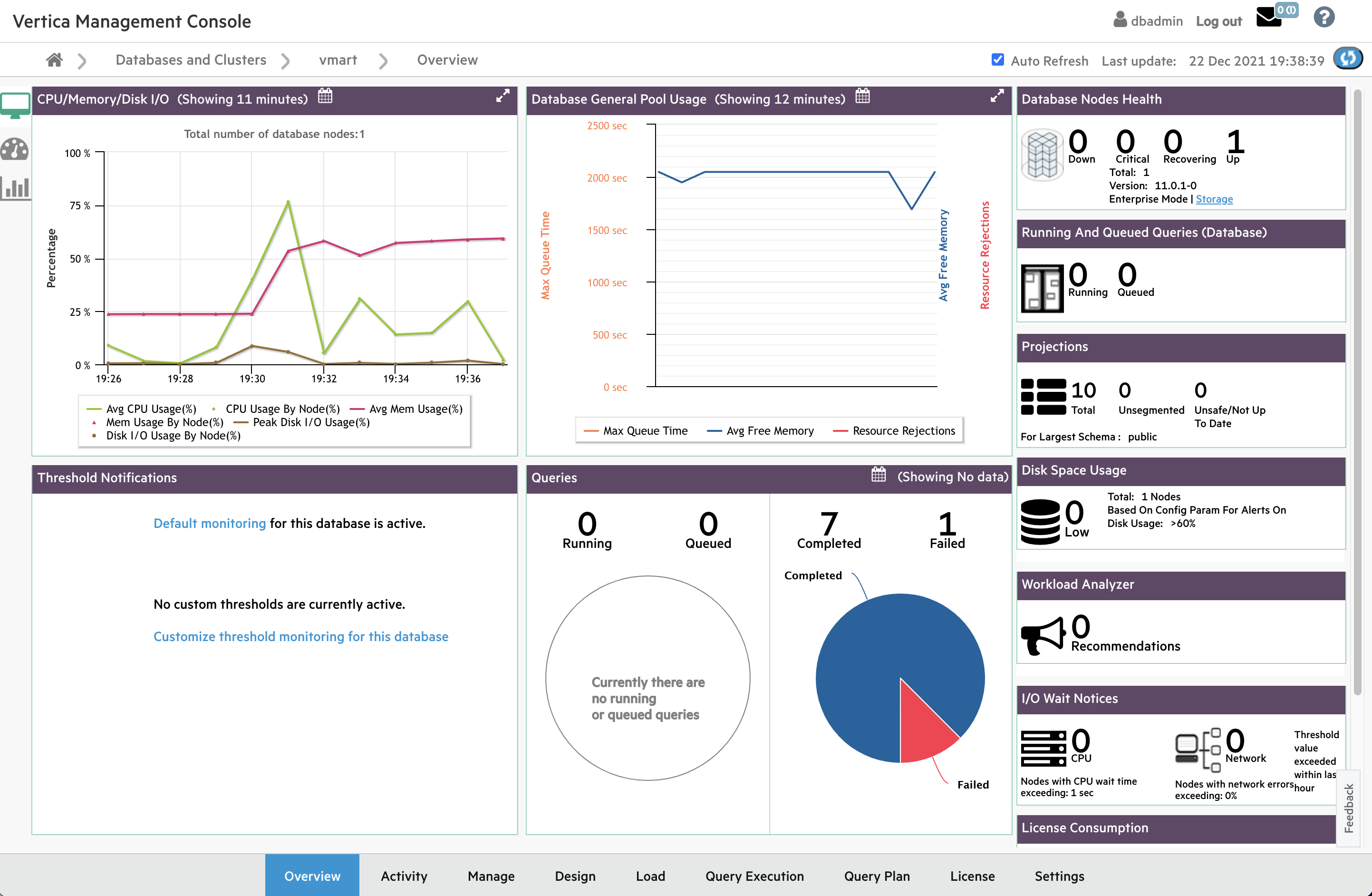
还可以通过Management Console图形化界面查看节点状态:
(img)
上图显示节点3宕机,重启该节点过后,检查该节点的vertica.log、dbLog、/var/log/dmesg、/var/log/messages等日志,排除故障。
Epoch状态
数据库将从物理存储中清除在AHM时间点之前delete掉的数据,可以以下两个方法查询epoch状态:
dbadmin=> \x
Expanded display is on.
dbadmin=>
dbadmin=>
SELECT current_epoch,
ahm_epoch,
last_good_epoch,
designed_fault_tolerance,
current_fault_tolerance,
wos_used_bytes,
ros_used_bytes
FROM system;
-[ RECORD 1 ]------------+-----------
current_epoch | 86
ahm_epoch | 85
last_good_epoch | 85
designed_fault_tolerance | 1
current_fault_tolerance | 1
wos_used_bytes | 0
ros_used_bytes | 1291892355
dbadmin=>
SELECT get_ahm_time(),
get_ahm_epoch(),
get_last_good_epoch(),
get_current_epoch(),
sysdate;
-[ RECORD 1 ]-------+------------------------------------------------
get_ahm_time | Current AHM Time: 2017-09-06 09:29:00.227942+08
get_ahm_epoch | 85
get_last_good_epoch | 85
get_current_epoch | 86
sysdate | 2017-09-14 17:06:50.336555
从上面的结果可以得到以下信息:
- designed_fault_tolerance和current_fault_tolerance是否一致?
- ahm_epoch和last_good_epoch相差多少?如果ahm_epoch比last_good_epoch小很多,则表明AHM没有往前推。需要手动将AHM往前推,select make_ahm_now()。如果执行失败,尽快检查原因排除故障。
- WOS和ROS的使用量。在跑批系统中,尽量使用批量加载数据不要将数据存储在WOS中,当节点宕机时,WOS里的数据会丢失,可以使用select do_tm_task(‘moveout’);将WOS的数据移到ROS中。
- 默认状态下数据库会将AHM尽快往前推,AHM时间点之前的删除向量会被清除,数据会被从物理存储中清除。
删除向量(Delete Vector)
众所周知,在Vertica中删除、更新数据时并不是真正从物理存储中删除数据,而是在该条数据打上删除向量。当数据库中存在大量的删除向量时,将对数据库性能产生影响。使用如下查询可以找出每个projection的删除向量数量:
delete from test;
OUTPUT
--------
1
(1 row)
commit;
SELECT node_name,
schema_name,
projection_name,
total_row_count,
deleted_row_count,
delete_vector_count
FROM storage_containers
WHERE deleted_row_count > total_row_count*.05::float
ORDER BY deleted_row_count desc;
node_name | schema_name | projection_name | total_row_count | deleted_row_count | delete_vector_count
------------------+-------------+-----------------+-----------------+-------------------+---------------------
v_vmart_node0001 | public | test_b1 | 1 | 1 | 1
v_vmart_node0003 | public | test_b0 | 1 | 1 | 1
(2 rows)
dbadmin=> SELECT COUNT(*) FROM v_monitor.delete_vectors;
COUNT
-------
2
(1 row)
减少删除向量,可以查看Best Practices for Deleting Data。
缺省状态下,每个projection最多只能有1024个ros containers,如果数据库中的ros container大量增加,亦会影响数据库性能,可以通过以下查询得到每个projection的ros container:
SELECT node_name,
projection_schema,
projection_name,
SUM(ros_count) AS ros_count
FROM v_monitor.projection_storage
GROUP BY node_name, projection_schema, projection_name
ORDER BY ros_count DESC;
node_name | projection_schema | projection_name | ros_count
------------------+-------------------+-----------------------------+-----------
v_vmart_node0002 | store | store_sales_fact_test_super | 251
v_vmart_node0003 | store | store_sales_fact_test_super | 251
v_vmart_node0001 | store | store_sales_fact_test_super | 251
v_vmart_node0002 | store | store_sales_fact_b0 | 250
v_vmart_node0003 | store | store_sales_fact_b1 | 250
v_vmart_node0001 | store | store_sales_fact_b1 | 250
v_vmart_node0001 | store | store_sales_fact_b0 | 250
v_vmart_node0003 | store | store_sales_fact_b0 | 250
v_vmart_node0002 | store | store_sales_fact_b1 | 250
一般来说,过多的ros container是由于表的分区字段设置不合理导致,也可能是merge out后台处理进程问题。详细参见HPE-Vertica-Partitions-The-FAQs。
资源使用
资源池
Vertica缺省是在内建的general资源池执行sql,你也可以根据你的业务负载情况来新建自定义资源池,通过资源池可以控制cpu和内存等资源分配。通过下面的查询查看general资源池状态:
SELECT SYSDATE AS CURRENT_TIME,
node_name,
pool_name,
memory_inuse_kb,
general_memory_borrowed_kb,
running_query_count
FROM resource_pool_status
WHERE pool_name IN ('general')
ORDER BY 1,2,3;
current_time | node_name | pool_name | memory_inuse_kb | general_memory_borrowed_kb | running_query_count
---------------------------+-----------------+-----------+-----------------+----------------------------+---------------------
2017-04-14 13:49:22.630529 | v_demo_node0001 | general | 7132121 | 0 | 3
2017-04-14 13:49:22.630529 | v_demo_node0002 | general | 7133456 | 0 | 3
2017-04-14 13:49:22.630529 | v_demo_node0003 | general | 7133261 | 0 | 3
(3 rows)
从结果可以看到这个资源池用了多少内存,有多少的sql在这个资源池中执行。
SELECT *
FROM resource_acquisitions
ORDER BY memory_inuse_kb desc
limit X;
上面这个sql按查询占用的内存从大到小进行排序,如果一个查询消耗了大量的内存,通常性能都不会太好,需要对sql进行优化。
资源池排队
可以通过以下sql查询资源池是否有排队的事务:
SELECT *
FROM v_monitor.resource_queues;
node_name | transaction_id | statement_id | pool_name | memory_requested_kb | priority | position_in_queue | queue_entry_timestamp
----------------+-------------------+--------------+-----------+---------------------+----------+-------------------+-------------------------------
v_demo_node0001 | 45035996273705862 | 1 | general | 2374617 | 0 | 1 | 2017-04-14 13:53:44.042381+09
v_demo_node0002 | 45035996273705862 | 1 | general | 2375067 | 0 | 1 | 2017-04-14 13:53:44.04009+09
v_demo_node0003 | 45035996273705862 | 1 | general | 2374998 | 0 | 1 | 2017-04-14 13:53:44.034676+09
(3 rows)
如果资源池有大量的事务在排队,检查是否有夯住的sql,是否有sql占用大量内存,资源池的maxconcurrency参数设置是否合理,是否需要根据实际负载状况优化资源池参数设置。
资源请求拒绝
查看被资源池拒绝的事务以及被拒绝的原因:
SELECT * FROM v_monitor.resource_rejections;
node_name | pool_id | pool_name | reason | resource_type | rejection_count | first_rejected_timestamp | last_rejected_timestamp | last_rejected_value
-----------------+-------------------+-----------+-----------------------------+---------------+-----------------+-------------------------------+-------------------------------+----------------------
v_vmart_node0001 | 45035996273704996 | general | Request exceeded high limit | Memory(KB) | 1 | 2017-02-21 13:10:42.873417-05 | 2017-02-21 13:10:42.873417-05 | 3140435
v_vmart_node0002 | 45035996273704996 | general | Request exceeded high limit | Memory(KB) | 1 | 2017-02-21 13:10:42.873334-05 | 2017-02-21 13:10:42.873334-05 | 3111145
v_vmart_node0003 | 45035996273704996 | general | Request exceeded high limit | Memory(KB) | 1 | 2017-02-21 13:10:42.878341-05 | 2017-02-21 13:10:42.878341-05 | 3111143
查看系统硬件资源使用情况(cpu、内存、IO、网络):
SELECT *
FROM v_monitor.system_resource_usage
ORDER BY end_time DESC;
node_name | end_time | average_memory_usage_percent | average_cpu_usage_percent | net_rx_kbytes_per_second | net_tx_kbytes_per_second | io_read_kbytes_per_second | io_written_kbytes_per_second
-----------------+---------------------+------------------------------+---------------------------+--------------------------+--------------------------+---------------------------+-------------------------------
v_vmart_node0001 | 2017-04-13 10:08:00 | 23.97 | 51.6 | 72.89 | 0.9 | 0 | 286.8
v_vmart_node0002 | 2017-04-13 10:08:00 | 9.88 | 0.84 | 72.14 | 0.26 | 0 | 255.47
v_vmart_node0003 | 2017-04-13 10:08:00 | 9.7 | 0.94 | 72.14 | 0.27 | 0 | 214
v_vmart_node0001 | 2017-04-13 10:07:00 | 23.97 | 51.81 | 105.23 | 0.84 | 0 | 272.06
v_vmart_node0002 | 2017-04-13 10:07:00 | 9.88 | 0.9 | 104.42 | 0.31 | 0 | 264.96
v_vmart_node0003 | 2017-04-13 10:07:00 | 9.72 | 0.95 | 104.51 | 0.22 | 0 | 267.63
v_vmart_node0001 | 2017-04-13 10:06:00 | 23.97 | 51.82 | 101.15 | 1.12 | 0 | 284.23
建议存储空间保持空余40%以上:
SELECT *
FROM v_monitor.storage_usage
ORDER BY poll_timestamp DESC;
poll_timestamp | node_name | path | device | filesystem | used_bytes | free_bytes | usage_percent
------------------------------+------------------+------+-----------+------------+-------------+-------------+-------------------------
2017-03-20 12:02:00.008656-04 | v_vmart_node0002 | | | vertica | 10454126592 | 40141549568 | 20.66000000000000000000
2017-03-20 12:02:00.008653-04 | v_vmart_node0002 | /dev | devtmpfs | devtmpfs | 151552 | 1997717504 | 0.01000000000000000000
2017-03-20 12:02:00.008648-04 | v_vmart_node0002 | / | /dev/sda2 | ext4 | 10454142976 | 40141533184 | 20.66000000000000000000
2017-03-20 12:02:00.00563-04 | v_vmart_node0001 | | | vertica | 17218465792 | 33377210368 | 34.03000000000000000000
2017-03-20 12:02:00.005629-04 | v_vmart_node0001 | /dev | devtmpfs | devtmpfs | 151552 | 1997725696 | 0.01000000000000000000
实时监控集群硬件资源使用情况
通过监控集群硬件资源使用情况,可以大致掌握数据库的大致状态。硬件使用情况可以通过MC的Overview页的CPU/Memory/Disk I/O栏检查以及通过操作系统工具(iostat、vmstat、dstat等)进行监控。
MC
系统工具监控硬件使用,推荐使用dstat,该工具使用简单。
下面分享一个脚本,该脚本基于dstat和watch,可以持续对硬件资源进行监控。
#!/bin/bash
# ===========================================================================================================================
# SCRIPT NAME : mondb.sh
# PURPOSE : Vertica集群系统资源监控工具
# USAGE : 1. 修改end参数里的3为集群的节点数量。
# AUTHOR : DingQiang Liu, CJiang
# HISTORY : v1.0 Created By DingQiang Liu
# v2.0 Added By CJiang 2016 1.支持超过10个节点。
# v2.1 Added By CJiang 20210423 1.支持redhat8。2.精简脚本。
# ===========================================================================================================================
begin=${1:-1}
end=${2:-30} # 将-30进行修改,如果有5个节点修改为-5,10个节点修改为-10,以此类推。
# usage:
# watch -n 3 "sh mondb.sh 13 25 2> /dev/null" # 其中13 25参数意为监控第13到25节点状态。
# watch -n 3 "sh mondb.sh 2> /dev/null" # 监控所有30个节点
for i in $(seq ${begin} ${end}); do srvname=v$(printf '%03d' ${i}); ssh ${srvname} "HOSTNAME=${srvname}; [ \${HOSTNAME:1:3} -eq ${begin} ]; dstat -cdnmplsy 1 2 | awk -v HOSTNAME=\${HOSTNAME} -v TITLE=\"v000\" 'NR==1,NR==2{print TITLE \": \" \$0}; NR==4{print HOSTNAME \": \" \$0}'" & done | sort -u
使用该脚本前请修改/etc/hosts文件,以v001格式添加节点host别名,并配置用户免密登陆(通常在创建集群时会自动配置dbadmin用户免密):
vi /etc/hosts 192.168.100.104 v001 192.168.100.104 v002 192.168.100.104 v003 ... 192.168.100.104 v030
使用方法:
[dbadmin@szxtsp104 ~]$ watch -n 3 "sh mondb.sh 2> /dev/null"

实时监控资源池使用情况
select a.pool_name,
min(a.running_query_count) min_r_sql,
max(a.running_query_count) max_r_sql,
nvl(b.queue_cnt,0) queue_cnt,
min(a.memory_inuse_kb)/1024//1024 minUse_GB,
max(a.memory_inuse_kb)/1024//1024 maxUse_GB,
min(a.general_memory_borrowed_kb)/1024//1024 minBorr_GB,
max(a.general_memory_borrowed_kb)/1024//1024 maxBorr_GB,
avg(a.max_concurrency)||'|'||avg(a.planned_concurrency) max_planned_cc
from resource_pool_status a
left join
(select pool_name, max(position_in_queue) queue_cnt from resource_queues group by 1) b
on a.pool_name=b.pool_name
group by 1,4
order by 3 desc,1;
通常来说min_r_sql与max_r_sql、minUse_GB与maxUse_GB、minBorr_GB与maxBorr_GB相同。
- min_r_sql与max_r_sql相差较大,说明集群中某个节点比其他节点慢。
- minUse_GB与maxUse_GB相差较大,说明正在执行的某个sql数据存在倾斜。
活动的Sessions
监控活动的Sessions
一个用户可以同时连接多个Session到数据库,使用如下查询检查当前活动的sessions:
SELECT user_name,
session_id,
current_statement,
statement_start
FROM v_monitor.sessions;
user_name | session_id | current_statement | statement_start
----------+-------------------------------+-------------------------------------------------------------------------------------------+------------------------------
dbadmin | v_vmart_node0001-73892:0x3b52 | | 2017-03-21 11:32:50.029212-04
dbadmin | v_vmart_node0001-73892:0x5e78 | SELECT user_name, session_id, current_statement, statement_start FROM v_monitor.sessions; | 2017-03-21 16:22:19.145425-04
(2 rows)
通过sessions表,可以得到:
- 一直没跑完的sql是那个用户发起的
- 是哪个用户一直没提交导致表锁一直不能释放
- 停库之前检查还有哪个用户在执行SQL
- 登录数据库所使用的验证方式
- 查看连库的客户端信息,比如客户端驱动版本等等
关闭Session连接
在某些情况下,需要强制关闭某个session,可以使用:
SELECT close_session ('session id');
CLOSE_SESSION
--------------------------------------------------------------------
Session close command sent. Check v_monitor.sessions for progress.
(1 row)
如果不想关闭整个session,而只中断该session中的某个事务,可以使用:
Select INTERRUPT_STATEMENT( 'session‑id', statement‑id );
历史Session记录
从v_monitor.user_sessions系统表可以查看历史session记录
select * from v_monitor.user_sessions limit 1;
-[ RECORD 1 ]-----------+-----------------------------------
node_name | v_vmart_node0001
user_name | dbadmin
session_id | v_vmart_node0001-56717:0x140a8f
transaction_id |
statement_id |
runtime_priority |
session_start_timestamp | 2021-12-22 19:27:01.174286+08
session_end_timestamp | 2021-12-22 19:27:02.176269+08
is_active | f
client_hostname | [::1]:33170
client_pid | 330688
client_label |
ssl_state | None
authentication_method | Password
client_type | vsql
client_version | 11.00.0100
client_os | Linux 3.10.0-862.el7.x86_64 x86_64
client_os_user_name | dbadmin
requested_protocol | 3.8
effective_protocol | 3.8
可以使用该表关联query_requests表进行数据库审计,检查发起执行某条SQL的客户端IP、用户名等等信息。
活动的查询
正在执行的查询
query_profiles系统表可以查询执行的sql,通过以下查询可以得到当前正在执行的sql:
SELECT node_name,
query,
query_start,
user_name,
is_executing
FROM v_monitor.query_profiles
WHERE is_executing = 't';
node_name | query | query_start | user_name | is_executing
------------------+-----------------------------------------------------------------------------------------------------------------------+-------------------------------+-----------+--------------
v_vmart_node0001 | SELECT node_name, query, query_start, user_name, is_executing FROM v_monitor.query_profiles WHERE is_executing = 't'; | 2017-09-15 16:44:58.975627+08 | dbadmin | t
(1 row)
数据装载的状态
SELECT table_name,
read_bytes,
input_file_size_bytes,
accepted_row_count,
rejected_row_count,
parse_complete_percent,
sort_complete_percent
FROM load_streams
WHERE is_executing = 't'
ORDER BY table_name;
table_name | read_bytes | input_file_size_bytes | accepted_row_count | rejected_row_count | parse_complete_percent | sort_complete_percent
-----------------+------------+-----------------------+--------------------+--------------------+------------------------+-----------------------
store_sales_fact | 375766803 | 375766803 | 5000000 | 0 | 100 | 0
(1 row)
锁状态
SELECT locks.lock_mode,
locks.lock_scope,
substr(locks.transaction_description, 1, 100) AS "left",
locks.request_timestamp,
locks.grant_timestamp
FROM v_monitor.locks;
lock_mode | lock_scope | left | request_timestamp | grant_timestamp
----------+-------------+------------------------------------------------------------------------------------------------------+-------------------------------+------------------------------
I | TRANSACTION | Txn: a0000000003082 'COPY store.Store_Sales_Fact FROM '/opt/vertica/examples/VMart_Schema/Store_Sale | 2017-03-17 18:47:46.462589+09 | 2017-03-17 18:47:46.462594+09
(1 row)
实时监控数据库长时间未释放的锁资源
select object_name as "对象名称",
l.transaction_id as "事务ID",
ra.pool_name as "资源池名称",
lock_mode as "锁类型",
substr(request_timestamp::char(19),6,19) as "锁请求时间",
substr(grant_timestamp::char(19),12,19) as "获取锁时间",
substr(queue_entry_timestamp::char(19),12,19) as "查询进入时间",
substr(acquisition_timestamp::char(19),12,19) as "查询开始时间",
timestampdiff(s,queue_entry_timestamp,acquisition_timestamp) as "等待资源时长",
timestampdiff(s,acquisition_timestamp,sysdate) as "实际执行时长",
substr(transaction_description,instr(transaction_description,'''') + 1, 60) SQL
from locks l left join resource_acquisitions ra using(transaction_id)
where ra.is_executing
and right(ra.node_name,4) = '0001'
order by request_timestamp
;
一般来说,锁请求时间与获取锁时间一致,查询进入时间与查询开始时间一致,等待资源时长为0。
如果发现,锁请求时间与获取锁时间相差很大,说明存在锁阻塞现象;查询进入时间与查询开始时间相差很大,即等待资源时长很大,说明内存资源、并发资源紧张,需要对优化SQL降低单个任务内存消耗、调整资源池并发设置,在资源允许的情况下适当增加并发数量。
恢复
监控节点恢复状态
在Vertica中,在一个节点宕机过后,该节点就不再写入数据,当重启这个节点,该节点需要从它的逻辑相邻节点将缺少的数据拷过来,这个过程就是节点的恢复,在节点进行恢复的过程中,可以通过以下查询监控进度:
SELECT node_name,
recover_epoch,
recovery_phase,
current_completed,
current_total,
is_running
FROM v_monitor.recovery_status
ORDER BY 1;
node_name | recover_epoch | recovery_phase | current_completed | current_total |is_running
-----------------+---------------+----------------+------------------+---------------+-----------
v_vmart_node0001 | | | 0 | 0 | f
v_vmart_node0002 | | | 0 | 0 | f
v_vmart_node0003 | | | 0 | 0 | f
(3 rows)
- is_running-正在进行恢复
- current_completed-已经恢复完的projections数量
- current_total-需要恢复的projections的总量
数据重分布
监控重分布状态
当从Vertica集群中添加计算节点过后,在节点间重新分布数据可以提高性能,不然旧的数据仍然在以前的节点上,新加的节点并不能参与计算。当从集群中删除节点的时候,为了数据的完整性,必须进行数据重分布。
SELECT GET_NODE_DEPENDENCIES();
GET_NODE_DEPENDENCIES
--------------------------------
Deps:
011 - cnt: 16
101 - cnt: 16
110 - cnt: 16
111 - cnt: 16
001 - name: v_vmart_node0001
010 - name: v_vmart_node0002
100 - name: v_vmart_node0003
(1 row)
前三行表示segmented的projection数量,最后一行表示unsegmented的projection数量。以二进制的方式表示,每个数字代表一个节点,比如第一行的011表示:node1=1,node2=1,node3=0,1表示segments在该节点存在,0表示segments在该节点不存在。
重分布的进度
通过下面这个查询可以得到当前正在Rebalance的进度:
SELECT rebalance_method Rebalance_method, Status, COUNT(*) AS Count
FROM ( SELECT rebalance_method, CASE WHEN (separated_percent = 100
AND transferred_percent = 100) THEN 'Completed'
WHEN ( separated_percent <> 0
AND separated_percent <> 100)
OR (transferred_percent <> 0
AND transferred_percent <> 100) THEN 'In Progress'
ELSE 'Queued'
END AS Status
FROM v_monitor.rebalance_projection_status
WHERE is_latest) AS tab
GROUP BY 1, 2
ORDER BY 1, 2;
Rebalance_method | Status | Count
-----------------+-------------+-------
ELASTIC_CLUSTER | Completed | 8
ELASTIC_CLUSTER | In Progress | 2
ELASTIC_CLUSTER | Queued | 2
REPLICATE | Completed | 50
(4 rows)
- Rebalance_method-当前projection的rebalance方法,包括REFRESH、REPLICATE、ELASTIC_CLUSTER
- Status-状态
- Count-projection数量
历史SQL
按执行时长排序查询历史SQL
TOP10慢的sql:
SELECT user_name,
start_timestamp,
request_duration_ms,
transaction_id,
statement_id,
substr(request, 0, 1000) as request
FROM v_monitor.query_requests
WHERE transaction_id > 0
ORDER BY request_duration_ms DESC
limit 10;
user_name | start_timestamp | request_duration_ms | transaction_id | statement_id | request
----------+-------------------------------+---------------------+-------------------+--------------+---------------------------------------------------------------------
dbadmin | 2017-03-30 12:33:56.381062-04 | 7567403 | 45035996274122533 | 1 | SELECT identifier, query FROM query_profiles;
dbadmin | 2017-03-23 13:17:45.350174-04 | 6993612 | 45035996274068604 | 2 | select counter_name from execution_engine_profiles;
dbadmin | 2017-03-13 13:17:12.618154-04 | 2195859 | 45035996273989990 | 2 | select * from customer_dimension;
dbadmin | 2017-03-23 15:14:44.586491-04 | 988246 | 45035996274068604 | 4 | select * from execution_engine_profiles;
dbadmin | 2017-04-13 10:08:21.999011-04 | 735847 | 45035996274232535 | 13 | SELECT * FROM v_monitor.system_resource_usage ORDER BY end_time DESC;
v_monitor.query_requests这张系统表里面记录着用户发出的历史SQL信息,request_duration_ms字段是每个sql执行的时长,单位为毫秒。
内存使用
通过下面的sql可以查询每个sql执行时所占用的内存大小:
SELECT node_name,
transaction_id,
statement_id,
user_name,
start_timestamp,
request_duration_ms,
memory_acquired_mb,
substr(request, 1, 100) AS request
FROM v_monitor.query_requests
WHERE transaction_id = transaction_id AND statement_id = statement_id;
node_name | transaction_id | statement_id | user_name | start_timestamp | request_duration_ms | memory_acquired_mb | request
----------------+-------------------+--------------+-----------+-------------------------------+---------------------+--------------------+-------------------------------------------------------------------------------
v_demo_node0001 | 45035996273715536 | 1 | dbadmin | 2017-03-17 15:53:20.645486+09 | 19662 | 1838.12 | COPY mountains from '/home/dbadmin/data/flex/data.json' parser fjsonparser();
(1 row)
如果一个sql占用了大量的内存,通常该sql效率都不会太好,可以通过projection设计、重新分布表数据来进行优化。
统计信息
分区数量
对表进行分区,更便于数据周期管理,通过删除分区,可以快速回收磁盘空间。你可以使用create table语句中指定分区键值,Vertica在装载数据的时候将更具分区键值将不同的数据放到不同的分区,当然你也可也使用alter table语句在一个存在的表加上分区,但是需要使用partition_table语句将表中的数据进行分区。缺省情况下,每个projection的最大ROS_COUNT=1024,通过以下查询可以得到每个projection在每个节点上的分区数量:
SELECT node_name,
projection_name,
count(partition_key)
FROM v_monitor.partitions
GROUP BY node_name, projection_name
ORDER BY node_name, projection_name;
node_name | projection_name | count
----------------+-----------------------------+-------
v_demo_node0001 | inventory_fact_partition_b0 | 5
v_demo_node0001 | inventory_fact_partition_b1 | 5
如果一个projection的分区数量过多,可以通过alter table改变该表的分区键值,放大分区粒度。
分段和数据倾斜
在集群节点间对数据进行分段(segmented by),可以提高查询的性能以及加快数据清除的效率。分段的目的是将数据根据一定的哈希散列规则打散存储在集群的所有节点上,以让在执行查询的时候每个节点都能参与计算。你可以在create projection语句中使用segmented by关键字指定数据在节点间的哈希散列规则,如果哈希的列选择不当,就可能导致该表在节点间分布不均匀,导致数据倾斜。通过下面这个sql可以得到projection在每个节点上的数据量:
SELECT ps.node_name,
ps.projection_schema,
ps.projection_name,
ps.row_count
FROM v_monitor.projection_storage ps
INNER JOIN v_catalog.projections p
ON ps.projection_schema = p.projection_schema
AND ps.projection_name = p.projection_name
WHERE p.is_segmented
ORDER BY ps.projection_schema, ps.projection_name, ps.node_name;
node_name | projection_schema | projection_name | row_count
----------------+-------------------+------------------------+----------
v_demo_node0001 | online_sales | online_sales_fact_b0 | 5001927
v_demo_node0002 | online_sales | online_sales_fact_b0 | 4999302
v_demo_node0003 | online_sales | online_sales_fact_b0 | 4998771
如果projection在每个节点上的数据量大致相同,则表示分布均匀,如果有较大差别,甚至相差好几个数量级,就需要重新选择该projection的哈希散列字段。
性能
查询性能
当你向Vertica提交一个查询的时候,Vertica优化器会根据表的projection(如果有多个projection,会自动选择最优的projection参与计算)自动生成一个最优的执行计划。随着数据量的增加,查询的效率可能会下降,这时监控查询的性能-特别是经常执行的sql、大表查询sql的性能-就变的尤为重要。可以通过query_events系统表查询执行计划的相关信息。
数据装载监控
在load_streams系统表中可以查到当前和历史数据装载作业中成功的数据量和被拒绝的数据量。查看数据装载的进度:
SELECT schema_name,
table_name,
load_start,
load_duration_ms,
is_executing,
parse_complete_percent,
sort_complete_percent,
accepted_row_count,
rejected_row_count
FROM v_monitor.load_streams;
schema_name | table_name | load_start | load_duration_ms | is_executing | parse_complete_percent | sort_complete_percent | accepted_row_count | rejected_row_count
-------------+-------------------+-------------------------------+------------------+--------------+------------------------+-----------------------+---------------------+------------------
myschema | table01 | 2017-02-13 15:48:49.983308-05 | 9283 | f | | 100 | 4 | 0
public | fruits | 2017-02-21 14:01:51.549974-05 | 343115 | f | | 100 | 4 | 0
store | store_orders_fact | 2017-02-06 10:55:24.073555-05 | 1513 | f | 100 | 100 | 300000 | 0
myschema | table01 | 2017-02-14 14:16:39.336496-05 | 7711 | f | | 100 | 3 | 0
public | casey1 | 2017-03-16 14:48:46.446581-04 | 15419 | f | | 100 | 3 | 0
online_sales | online_sales_fact | 2017-02-06 10:55:25.634915-05 | 17401 | f | 100 | 100 | 5000000 | 0
myschema | table01 | 2017-02-13 11:57:05.532119-05 | 15973 | f | | 100 | 5 | 0

