




关注微信公众号《云原生CTO》更多云原生干货等你来探索
专注于 云原生技术
分享
提供优质 云原生开发
视频技术培训
面试技巧
,及技术疑难问题 解答

云原生技术分享不仅仅局限于Go
、Rust
、Python
、Istio
、containerd
、CoreDNS
、Envoy
、etcd
、Fluentd
、Harbor
、Helm
、Jaeger
、Kubernetes
、Open Policy Agent
、Prometheus
、Rook
、TiKV
、TUF
、Vitess
、Argo
、Buildpacks
、CloudEvents
、CNI
、Contour
、Cortex
、CRI-O
、Falco
、Flux
、gRPC
、KubeEdge
、Linkerd
、NATS
、Notary
、OpenTracing
、Operator Framework
、SPIFFE
、SPIRE
和 Thanos
等


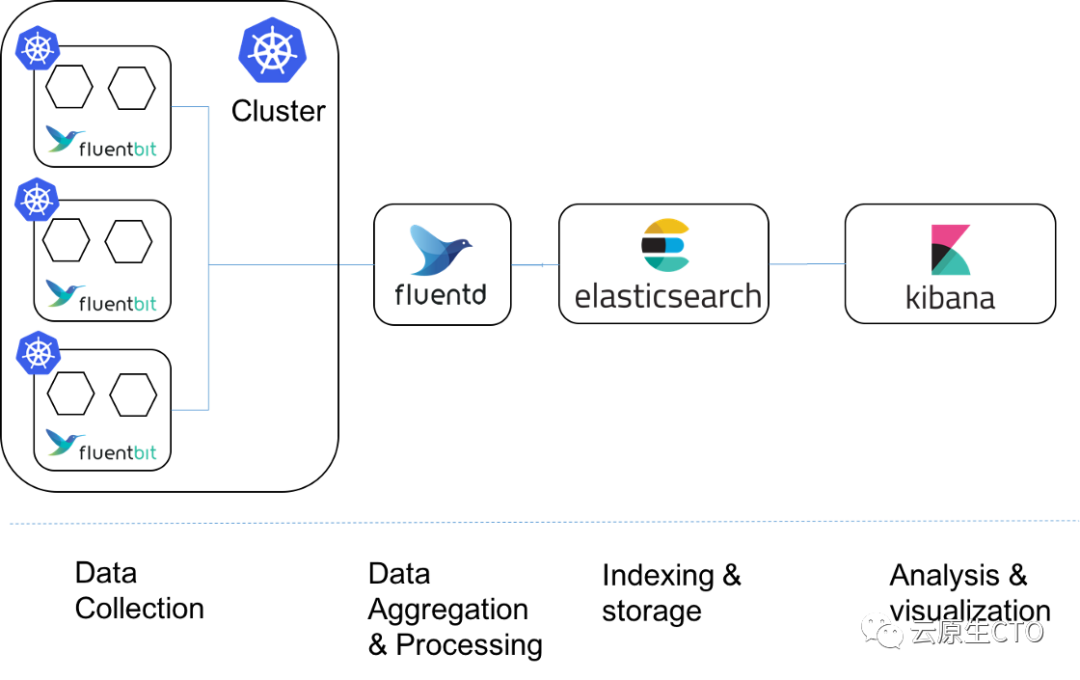
kubernetes上的Fluent日志采集架构 - Fluent Bit、Fluentd 和 Elasticsearch
在本文中,我将尝试解释我们如何使用
Fluent Bit
、Fluentd
和Elasticsearch
创建可靠的日志架构。
我们总结一下在本次在介绍当中的kubernetes
日志架构工作流,首先Fluent Bit
充当Kubernetes
集群中的守护进程集。运行在Kubernetes
收集并转发标准输出日志到每个节点Fluentd
,它位于Kubernetes
簇之外。Fluentd
修改、过滤和处理这些日志并将它们发送到Elasticsearch
集群。最后,Kibana
将这些日志可视化。
为什么日志很重要?
因为日志提供了对正在运行的应用程序行为的可见性和监控。最终,每个应用程序都会崩溃,服务器会宕机,或者用户会对错误感到沮丧。如果我们有一个良好的日志记录和监控基础设施,我提到的这些困难的解决方案就会变得更容易。日志记录是我们的遗留应用程序和当今现代应用程序中最关键的方面之一。因此,我们需要仔细考虑。
因为日志提供了对正在运行的应用程序行为的可见性和监控: https://12factor.net/logs
为什么要使用日志路由器?
我们的主要目标是;将日志视为事件流。根据十二因素应用程序方法,应用程序从不关心其输出流的路由或存储。
应用程序从不关心其输出流的路由或存储: https://12factor.net/logs
转发和处理日志以及存储它们不应该由我们的应用程序处理。如果我们使用日志路由器/转发器,我们的应用程序将不会处理不必要的责任。当我们的应用程序与日志存储和处理进行分离时,我们的代码将变得更简单。
什么是 Fluentd、Fluent Bit 和 Elasticsearch?
Fluentd
是2011
年创建的基于Ruby
的开源日志收集器和处理器。Fluentd
使用大约40 MB
的内存,每秒可以处理超过10,000
个事件。有超过500
种不同的插件可用。Fluentd
在操作上类似于elk
堆栈上的logstash
。Fluent Bit
与Fluentd
由同一家公司开发,以实现高性能和低内存消耗。更适合在k8s
环境下使用。(k8s
是Kubernetes
的缩写)你可以在这里查看两者的比较。Elasticsearch
是一个分布式、可扩展、基于JSON
的搜索和分析引擎。它被广泛用作elk
堆栈(Elasticsearch
、Kibana
、Beats
和Logstash
)。Kibana
是Elasticsearch
数据的可视化工具。
“我们软件系统中的可观察性一直很有价值,在这个云和微服务时代变得更加重要” - Martin Fowler
Fluentd: https://www.fluentd.org/architecture
Fluent Bit: https://docs.fluentbit.io/manual/about/what-is-fluent-bit
Elasticsearch: https://www.elastic.co/elasticsearch/
Kibana: https://www.elastic.co/kibana/
示范
在我们的实现过程中,首先我们需要一个容器化的应用程序,将日志作为JSON
发送到stdout
。然后 我们需要一个 Kubernetes
集群,安装 Fluentd
,以及安装 elk stack
。(我的演示建议是将 docker
用于 efk
堆栈。您可以在此处找到详细信息)。
https://docs.fluentd.org/container-deployment/docker-compose
您可以将Minikube
用作 Kubernetes
环境。我们要为 Fluentd
和 Elasticsearch
使用单独的服务器的原因是,其中一个的任何瓶颈都不会影响另一个。这样,我们就可以实现松耦合的日志架构。
stdout
是指由Linux
和其他类 Unix
操作系统中的命令行程序生成的标准化数据流。
作为起点,我们将向基于 dotnet
的 Web API
应用程序添加库,以将日志转换为 JSON
。我们将使用 Serilog
及其插件,它是最受欢迎的库之一。
$ dotnet add package Serilog
$ dotnet add package Serilog.Sinks.Console
$ dotnet add package Serilog.Formatting.Elasticsearch
$ dotnet add package Serilog.AspNetCore
之后,我们必须如下配置我们的 Program.cs
。
public class Program
{
public static async Task Main(string[] args)
{
Log.Logger = new LoggerConfiguration()
.Enrich.FromLogContext()
.WriteTo.Console(new ElasticsearchJsonFormatter() { })
.CreateLogger();
await BuildWebHost(args).Build().RunAsync();
}
public static IWebHostBuilder BuildWebHost(string[] args)
{
return WebHost.CreateDefaultBuilder(args)
.ConfigureLogging((hostingContext, config) => { config.ClearProviders(); })
.UseKestrel()
.UseSerilog()
.UseStartup<StartUp>();
}
}
您可以使用以下 Deployment YAML
和 Service YAML
在您的 k8s
集群或 minikube
环境中运行 dockerized
来演示应用程序。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fluent-demo-k8s
spec:
replicas: 2
template:
metadata:
labels:
app: fluent-demo-k8s
spec:
containers:
- name: fluent-demo-k8s
imagePullPolicy: Always
image: fluent-demo-k8s-image
ports:
- containerPort: 8080
apiVersion: v1
kind: Service
metadata:
name: fluent-demo-k8s
labels:
run: fluent-demo-k8s
spec:
ports:
- port: 8080
protocol: TCP
selector:
app: fluent-demo-k8s
type: NodePort
使用以下命令在 k8s
环境中运行我们的 dotnet
应用程序。
kubectl create -f deployment.yml
kubectl create -f service.yml
您可以使用kubectl get svc
命令列出服务并获取映射到 8080
的端口。为了从浏览器访问我们的应用程序,运行kubectl cluster-info
命令并获取运行 k8s master
的 IP
地址,并使用映射服务端口的 pod
访问它。
(示例:k8s master IP
为 192.168.57.80
,映射服务端口为 32077
。您可以从 => http://192.168.57.80:32077
访问该应用程序)
现在是时候在 k8s
上安装 Fluent Bit
作为守护进程了。首先,我们将创建一个名为logging
的新命名空间。
apiVersion: v1
kind: Namespace
metadata:
name: logging
kubectl create -f namespace.yml
接下来,我们将创建一个名为fluent-bit
的服务帐户并为 pod
提供身份。
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluent-bit
namespace: logging
kubectl create -f serviceaccount.yml
我们需要定义集群角色并将这个角色绑定到fluent-bit
服务帐户。我们可以使用下面的 YAML
文件进行这些操作。
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: fluent-bit-read
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
verbs: ["get", "list", "watch"]
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: fluent-bit-read
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluent-bit-read
subjects:
- kind: ServiceAccount
name: fluent-bit
namespace: logging
kubectl create -f clusterrole.yml
kubectl create -f clusterrolebinding.yml
之后,我们需要为 Fluent Bit
创建ConfigMap
, 它允许我们将特定于环境的配置与我们的容器镜像分离。我需要在下面的配置文件中解释一些参数。在[INPUT]
部分,我们使用Fluent Bit
的尾部插件,它允许我们监视多个文本文件并读取Path
模式中的每个匹配文件。
Kubernetes
将容器日志文件存储在/var/log/containers
中,这些日志文件与 Path
属性映射。使用Tag
和Tag_Regex
配置,我们正在设置一个标签,该标签将放置在 read
和 regex
行上,以从文件名中提取字段。在[输出]
部分,我们使用转发插件将捕获的日志发送到 Fluentd
。至少在 [PARSER]
部分,我们正在解析事件记录中的字段。(这部分我尝试简单解释一些配置参数。详细文档请看这里。)
Fluent Bit
的尾部插件: https://docs.fluentbit.io/manual/pipeline/inputs/tail
配置参数: https://docs.fluentbit.io/manual/concepts/data-pipeline
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
data:
fluent-bit.conf: |
[SERVICE]
Flush 5
Log_Level info
Parsers_File parsers.conf
Daemon off
@INCLUDE all_container_input.conf
@INCLUDE output-fleuntd-forward.conf
all_container_input.conf: |
[INPUT]
Name tail
Tag <container_name>-<namespace_name>
Tag_Regex (?<pod_name>[a-z0-9]([-a-z0-9]*[a-z0-9])?(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)-
Parser docker
Path /var/log/containers/*
DB /var/log/flb_kube.db
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 5
Docker_Mode On
output-fleuntd-forward.conf: |
[OUTPUT]
Name forward
Match *
Host ${FLUENTD_HOST}
Port ${FLUENTD_PORT}
Retry_Limit False
parsers.conf: |
[PARSER]
Name json
Format json
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name docker
Format json
#Time_Key time
Time_Key @timestamp
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_Keep Off # on
kubectl create -f configmap.yml
日志记录是一个跨领域的问题。最好在插件组件中完成 - Robert C. Martin
最后,我们需要让 Fluent Bit
在 Kubernetes
中作为DaemonSet
运行。这确保所有节点都运行 Fluent Bit pod
的副本。另外,我们需要在这个文件中定义Fluentd
服务器的IP
地址和端口信息作为环境变量。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: logging
labels:
k8s-app: fluent-bit-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
name: fluent-bit
template:
metadata:
labels:
name: fluent-bit
k8s-app: fluent-bit-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
containers:
- name: fluent-bit
image: fluent/fluent-bit:1.6.0
imagePullPolicy: Always
ports:
- containerPort: 2020
env:
- name: FLUENTD_HOST
value: "127.0.0.1" #YOUR FLUENTD HOST IP
- name: FLUENTD_PORT
value: "24224"
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluent-bit-config
mountPath: /fluent-bit/etc/
terminationGracePeriodSeconds: 10
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluent-bit-config
configMap:
name: fluent-bit-config
serviceAccountName: fluent-bit
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
kubectl create -f daemonset.yml
您还可以在单个清单文件中编辑和应用上述所有配置。我更喜欢使用单独的文件来使一切变得更简单易懂。
到目前为止一切顺利,但我们还有一些工作要做。我们必须配置我们的 Fluentd
来捕获 Fluent Bit pod
转发的日志。之后,Fluentd
将处理、过滤、聚合这些日志,并将它们发送到 Elasticsearch
。坚持住,我们快完成了!

在这一部分,我们将使用td-agent
。Treasure Agent(td-agent
)是Fluentd
的一个稳定分发包,由Treasure Data
和云原生计算基金会共同维护。(td-agent
和 Fluentd
之间有什么区别?另外, 我假设你已经安装了Fluentd
)因为我们使用td-agent
包安装 Fluentd
,配置文件应该在/etc/td-agent/td-agent.conf
(如果你使用 Ruby Gem
或 docke
r 容器安装 Fluentd
,你应该有看这里) Fluentd
假设我们的配置文件具有 UTF-8
或 ASCII
编码。这是我们的示例td-agent.conf
文件:
Treasure Data: https://www.treasuredata.com/
云原生计算基金会共同维护: https://www.cncf.io/projects/
td-agent 和 Fluentd 之间有什么区别?: https://www.fluentd.org/faqs
安装了Fluentd: https://docs.fluentd.org/installation
# source: where all the data come from
# Receive events from 24224/tcp
# This is used by log forwarding and the fluent-cat command
<source>
@type forward
bind 0.0.0.0
port 24224
</source>
#filter: Event processing pipeline
<filter *.**>
@type parser
key_name log
reserve_data true
remove_key_name_field true
emit_invalid_record_to_error false
<parse>
@type json
</parse>
</filter>
# kube-system related logs excluded
<match *kube-system**>
@type null
</match>
# match: Tell fluentd what to do with other logs!
<match *.**>
@type elasticsearch
@log_level info
include_tag_key true
host 127.0.0.1 #YOUR ELASTICSEARCH HOST
port 9200 #DEFAULT ELASTICSEARCH PORT
scheme http
ssl_verify false
logstash_format true
logstash_prefix ${tag}-k8s
reload_connections false
reconnect_on_error true
reload_on_failure true
request_timeout 15s
flush_interval 10s
<buffer>
timekey 10s
flush_thread_count 5
flush_interval 10s
chunk_limit_size 16m
queue_limit_length 96
flush_mode interval
retry_max_interval 30
retry_forever false
flush_at_shutdown true
</buffer>
</match>
我们试着解释一下配置文件中的一些参数。source
指令确定输入源。match
指令确定输出目的地。filter
指令确定事件处理管道。(更详细的解释在这里)在这个简短的解释之后,通过运行以下命令,我们必须通过 systemd
重新加载我们的 td-agent
服务。(如果您遇到任何问题,您可以查看日志 /var/logs/td-agent/td-agent.log
)
更详细的解释在这里: https://docs.fluentd.org/configuration/config-file
sudo systemctl reload td-agent
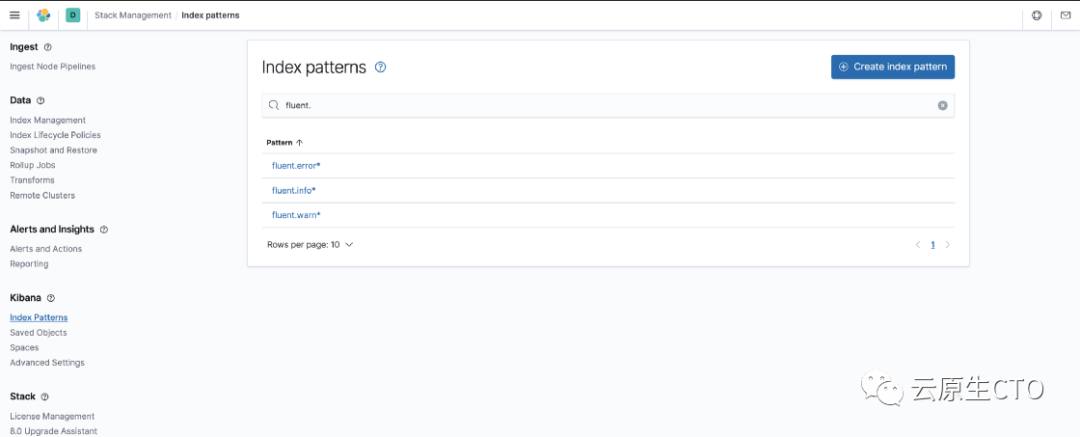
我们的日志应该已经开始流入 Elasticsearch
。让我们在 Kibana
上查看它们。点击management
-> stack management
从Kibana
侧边栏。在打开的屏幕上选择索引模式。(在某些安装中,您可能会发现此部分带有 management
-> index patterns
)
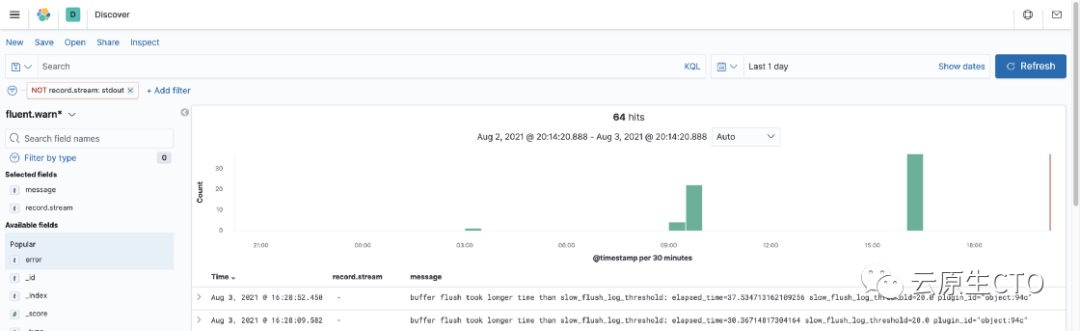
当我们切换到 Kibana
上的 Discovery
部分时,我们可以查看我们的日志。
结论
与软件世界中的任何解决方案一样,这种结构也需要权衡取舍。Fluent Bit
可以收集、处理和过滤所有日志,并将它们直接转发到 Elasticsearch
。在这种情况下,当系统负载过重时,这可能会导致我们的Kubernetes
集群成为资源消耗的瓶颈。即使 Fluent Bit pod
出现问题也可能导致我们的 Kubernetes
集群崩溃。这就是为什么我们减少了 Fluent Bit
的责任,并赋予 Fluent Bit
转发日志的任务,因此我们在 Kubernetes
集群中节省了大量内存使用。作为回报,我们遇到了 Fluentd
,我们必须对其进行组织和维护。
Fluent Bit
和 Fluentd
是有据可查的解决方案。因此,如果您遇到任何问题,我认为您可以轻松解决它。为了不让文章复杂化,我没有提到一些安装(Fluentd & ELK
)。您可以在此处找到一个简单的演示示例。
https://github.com/senvardarsemih/fluent-logging-demo
如果您已经阅读了到目前为止,我感谢您的耐心和支持。我希望它对你有用。
进一步阅读[1]
参考资料
参考地址: https://medium.com/hepsiburadatech/fluent-logging-architecture-fluent-bit-fluentd-elasticsearch-ca4a898e28aa
