




什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。
因此,逐渐演化出布隆过滤器。
布隆过滤器的原理
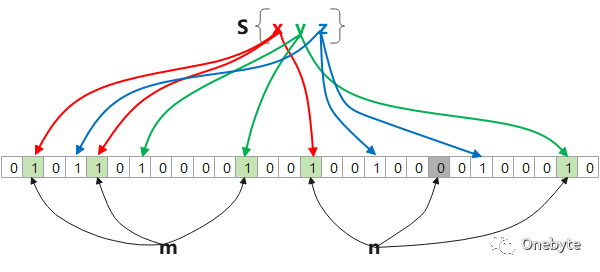
上图中,数据集是S{x,y,z},每个hash函数以一条有向线段表示。这里我们约定二进制数组的长度为m,且此二进制数组的初始值均为0;hash函数的数目为k。
当把数据元素“插入”过滤器时:
通过 k个散列函数将这个数据元素映射成一个位数组中的 k个槽位,并把它们置为 1。图中所示是3个数据元素(x、y、z)各自被3个hash函数映射到3个槽位。
检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:
如果这些点有任何一个0,则被检元素一定不在;如上图中的n数据元素;
如果都是1,则被检元素很可能在,如m数据元素。
误判率及其分析
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个bit槽位并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
既然无法避免其误判率,那么如何降低其误判率呢?我们知道,在构建布隆过滤器时,有几个相关变量:
位数组(Bit Array)长度:m
哈希函数(Hash Function)个数:k
已添加元素数量(Items in the filter):n
误判率(False positive probability):fpp
误判率(False positive probability):
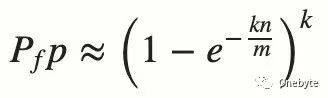
位数组(Bit Array)长度m:
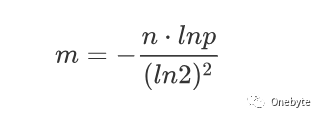
哈希函数(Hash Function)个数k:
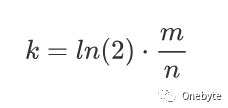
上述推导可以参见:https://en.wikipedia.org/wiki/Bloom_filter
优缺点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。
布隆过滤器存储空间和插入/查询时间复杂度都是常数O(k);
散列函数相互之间没有关系,方便由硬件并行实现;
布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势;
布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点:
但是布隆过滤器的缺点和优点一样明显。
误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣;
一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面,这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
布隆过滤器的使用场景
Google Bigtable,Apache HBase和Apache Cassandra以及Postgresql 使用布隆过滤器来减少对不存在的行或列的磁盘查找;
缓存类:
Redis使用布隆过滤器防止缓存穿透;
去重类:
Medium使用布隆过滤器避免推荐给用户已经读过的文章;
网页爬虫对URL去重,避免爬取相同的URL地址;
安全类(黑名单):
反垃圾邮件,从数十亿个垃圾邮件列表中判断某个邮箱是否是垃圾邮箱;
Chrome使用布隆过滤器识别恶意URL。
上述使用场景源自B站凯特Kate_zts的总结。
Bloom Filter开源实现
常见的开源实现有如下几种:
Rebloom - Bloom Filter Module for Redis (注:redis Module在redis4.0引入) 谷歌的guava中的Bloom Filter Redisson中的Bloom Filter实现
笔者基于guava的Bloom Filter写了测试误判率的测试代码,详见:
引用
[2] https://crossoverjie.top/2018/11/26/guava/guava-bloom-filter/
[3] https://github.com/AobingJava/JavaFamily/blob/master/docs/redis/%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8(BloomFilter).md
[4] https://xie.infoq.cn/article/db1fdba6462ed05c8adbd73ea
[5] https://brilliant.org/wiki/bloom-filter/
[6] https://www.jianshu.com/p/bef2ec1c361f
[7] https://github.com/google/guava/wiki/HashingExplained#bloomfilter
[8] http://llimllib.github.io/bloomfilter-tutorial/
[9] https://juejin.cn/post/6844903801908887566


点个

在看
你最好看
