




注意版本变迁,一些版本中是不可以降级的,比入Docker File、WAL实现、存储BUG等。
建议,尽量使用新版本,版本的升级和降级一定要谨慎。新功能的引入也同样会引入风险。
Prometheus 2.0.0
这是一个里程碑的改进
Prometheus 2.0.0的前一个版本是1.8.0,相距一个月。这次大版本的更新带来了重要的改进。
最大的变化是新的存储引擎,它被完全重写并且与检索系统的改变相结合,带来了可观的性能提升。Prometheus服务器每秒采集百万样本变得可以想象。这是由于文本展示格式相关的优化。如果你使用的是非常罕见的支持protobuf展示格式的exporters,则需要添加对文本格式的支持。这个新的存储引擎不向后兼容,但是有一种方法可以透明地访问仍存储在1.x中的旧数据。
新的存储引擎不需要通过标志进行调整。它通过mmaped文件工作,因此依赖于现代内核的页面缓存。这种设计还允许为希望进行备份的用户拍摄快照。
第二个最大的改变是PromQL中的新的陈旧语义。在通常情况下,当时间序列从服务发现中移除后,您不再需要等待整整5分钟才能使其失效,现在只需要一个刮擦间隔scrape interval即可。
规则文件 rules file 格式已更改为YAML,规则Rule按组groups组织,并按顺序执行。
PromQL进行了一些很小的修改,一个timestamp的功能加入了,同时count_scalar、drop_common_labels和keep_common已被删除。
出于安全原因,在默认情况下,已禁用admin和生命周期API。您可以使用 --web.enable-admin-api
和 --web.enable-lifecycle
标志重新启用它们。说到标记,Kingpin现在被使用,都以双而不是单连字符开头。用于指定Alertmanager的命令行标记已被删除,1.4版中重新添加的配置文件选项(config file options added back in 1.4)现在是指定要使用的Alertmanagers的唯一方法。
如果将远程读取与非远程存储一起使用,你需要启用新的 read_recent
选项。默认情况下,远程读取不再请求本地应具有的数据。
Prometheus 2.1.0
有一些改进让administration管理更容易。新的服务发现状态页面使你更容易了解哪些元数据可用于重新标记。规则状态页面现在包含每条规则的最后一次评估需要多长时间。便于找出哪些可能需要一些调整。每个规则组的最后计算持续时间现在也可以作为rule_group_last_duration_seconds
metric度量使用。File SD有一个新的 prometheus_sd_file_timestamp
metric度量标准,可帮助您检测文件是否陈旧。
新改进的存储引擎已修复了许多错误,现在可以处理大于4GiB的索引。联邦端点更快,表达式浏览器具有可选的查询历史记录。v1 HTTP API现在包括用于快照,删除和强制压缩的管理端点。
read_recent
选项是2.0.0中添加的,该选项具有错误的默认值,在2.1.0版本中现在它是false。
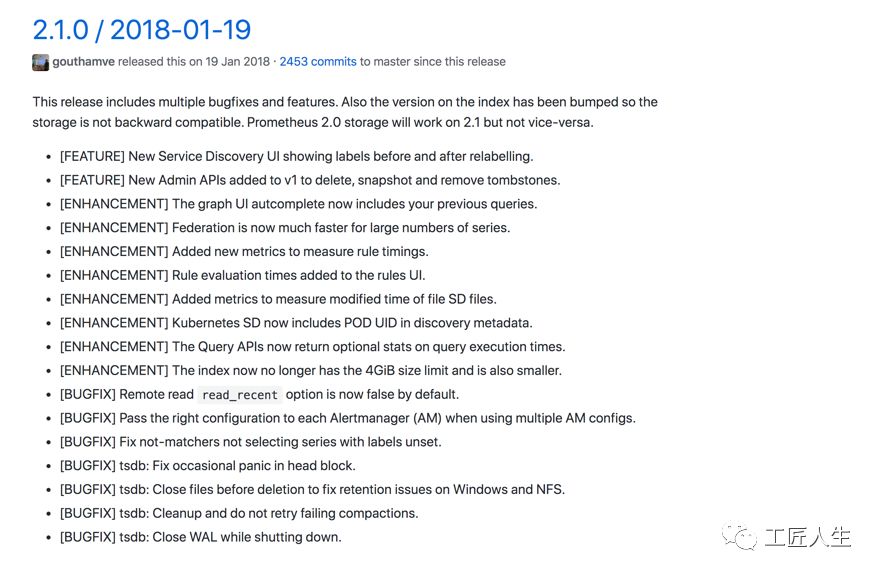
Prometheus 2.2.0
从2018年1月份开始,2.2.0版本在2.1.0版本的基础上进行了一些修复和改进。
此版本中的存储格式有所更改,因此一旦升级到2.2.0,将无法降级。因为存储中的一个BUG,2.2.0版本不建议使用。
有各种改进使管理变得更容易。警报状态页面可以显示注释,规则的格式更好,运行时页面包含更多的信息,并且现在可以从API获得标志,已删除目标和已删除警报。
联邦和服务发现的性能有所提高。承载令牌中的更改不再需要重新加载配置文件。在2.1.0 新增的prometheus_sd_file_timestamp
metric,现在具有改进的名称 prometheus_sd_file_mtime_seconds
。新增的元数据已添加到Azure SD。
Prometheus 2.3.0
2.3.0在3月份的2.2.0的基础上,进行了一些修复和改进。
这个版本中最大的改变是性能相关的。PromQL的评估方式进行了重大改变,这可以使常见仪表板查询的CPU数量减少31-64%,内存分配减少55-99%。编码响应的the JSON library也做了修改,节省了40%的CPU。
如果您使用带有不记名令牌的商业Marathon产品,请注意字段名称已更改。从好的方面来说,Marathon SD目前已经支持所有常用的HTTP选项。EC2和Consul SD允许使用这些技术的内置过滤,这对于重新标记是无法做到的,但是对性能很有用。Kubernetes 和 GCE SD 获得了更多的元数据。在可以指定基本验证密码的任何地方,都可以从文件中读取该密码。

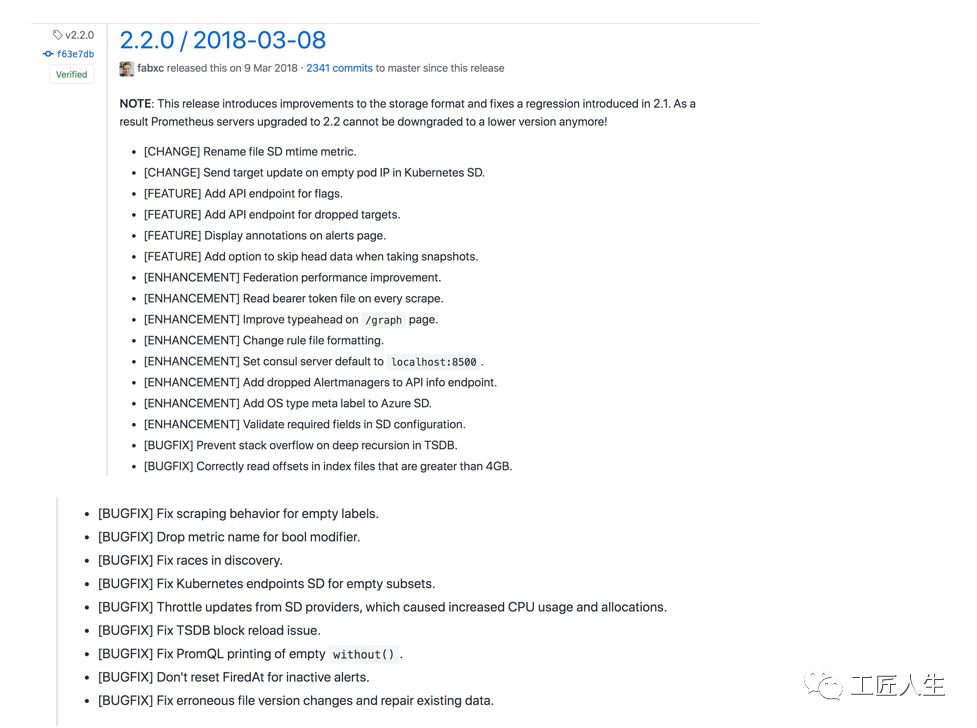
Prometheus 2.4.0
继2018年6月份以后,Prometheus 2.4.0进行了许多修复和改进。
第一个大的变化是警报中的for
状态现在在重新启动时持续存在,所以简短的重新启动将不再需要pending alerts从头再来。现在向Alertmanager发送警报时也有限制,所以现在不是在每个评估重发时都发送现有警报,而是每分钟最多发送一次,这减少了Alertmanager的负载。
该版本有一个新的WAL实现,这意味着不可能从2.4.0降级。有新的API可以从目标targets访问规则rules,警报alerts和指标元数据metrics metadata。
服务发现方面也有一些改进。如果存在相同的SD配置,则它们将仅实例化一次,而不是针对它们的每个实例进行实例化-对于节流的 集成更加有效和有用。还提供了Consul,EC2和GCE的元数据字段,并且Azure获得了VMSS支持。
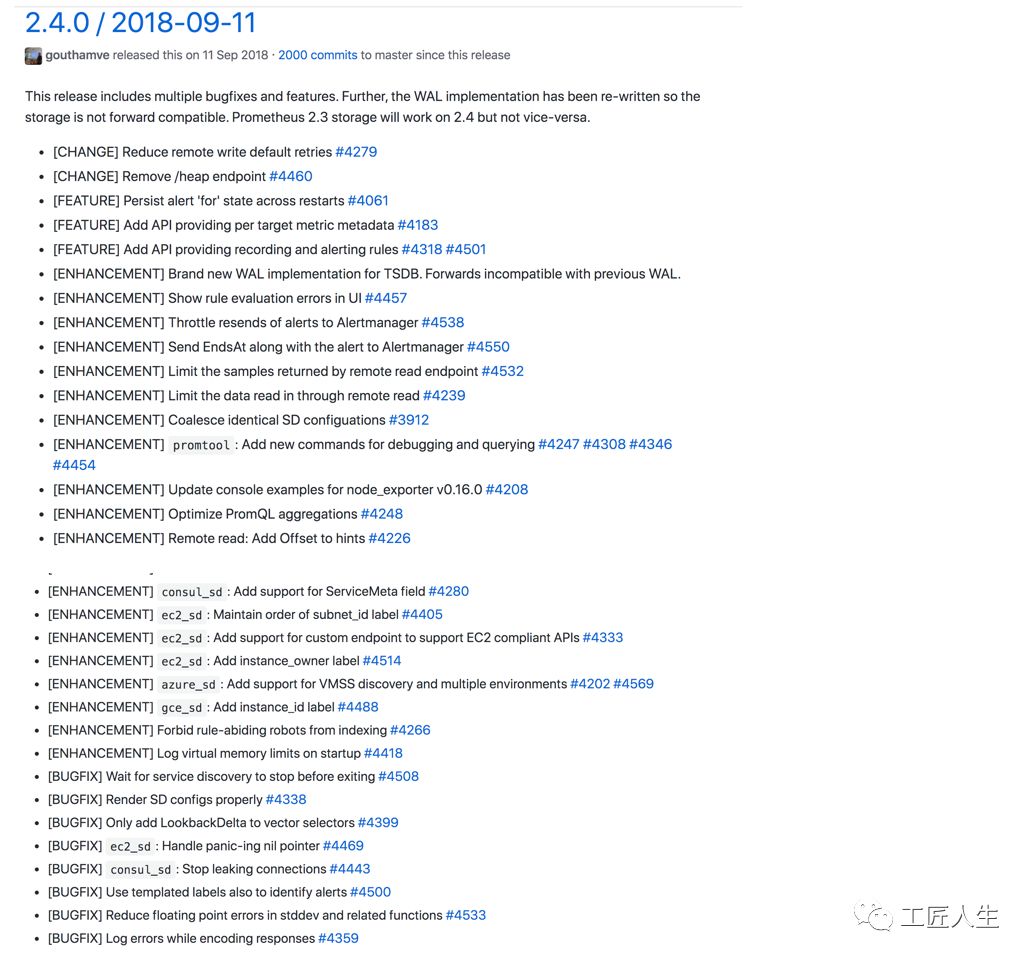
Prometheus 2.5.0
继2018年9月份的2.4.0以后,2.5.0版本进行了许多修复和改进。
这是新的6周时间表中的第二个版本。第一个主要功能是,基于内部用于单元测试PromQL本身的语法,对promtool中的规则rules和警报alerts进行单元测试。现在,Prometheus还将在加载配置文件时(而不是在评估模板时)捕获一些警报模板错误。
第二个特性是,现在查询一次可以在内存中存储的样本数量受到限制,这让停止大规模的查询(占用过多RAM、威胁到Prometheus OOM)成为可能。可以使用--query.max-samples
标记flag来调整。每个样本使用16个字节的内存,但是请记住,对于一个查询来说,内存中不仅仅是活动的样本。
第三个值得注意的特性是,这是第一个支持抓取OpenMetrics格式的版本。该格式仍在草案中,因此在Prometheus中仍处于试验阶段。目前只有Prometheus Python客户端可以生成这种格式,但是如果您使用的是这两种格式的最新版本,那么将使用OpenMetrics而不是Prometheus文本格式。
远程读取有一些改进,减少了内存使用量,增加了新metrics,并发限制。在服务发现方面,OpenStack现在可以从所有项目中发现,发现所有网络接口并使用TLS。Triton SD可以按组过滤,并关联新的元数据。Kubernetes SD和SD都增加了一些新指标metrics。
最后,还有一个BUG修复,它主要影响用户在度量名称上误用匹配器。如果您正在执行 rate({__name__=~"som.*thing"}[5m])
,现在将失败,因为一旦删除度量名称metric name,该速率将产生两个具有相同标签的时间序列,这是没有意义的,并会导致问题。
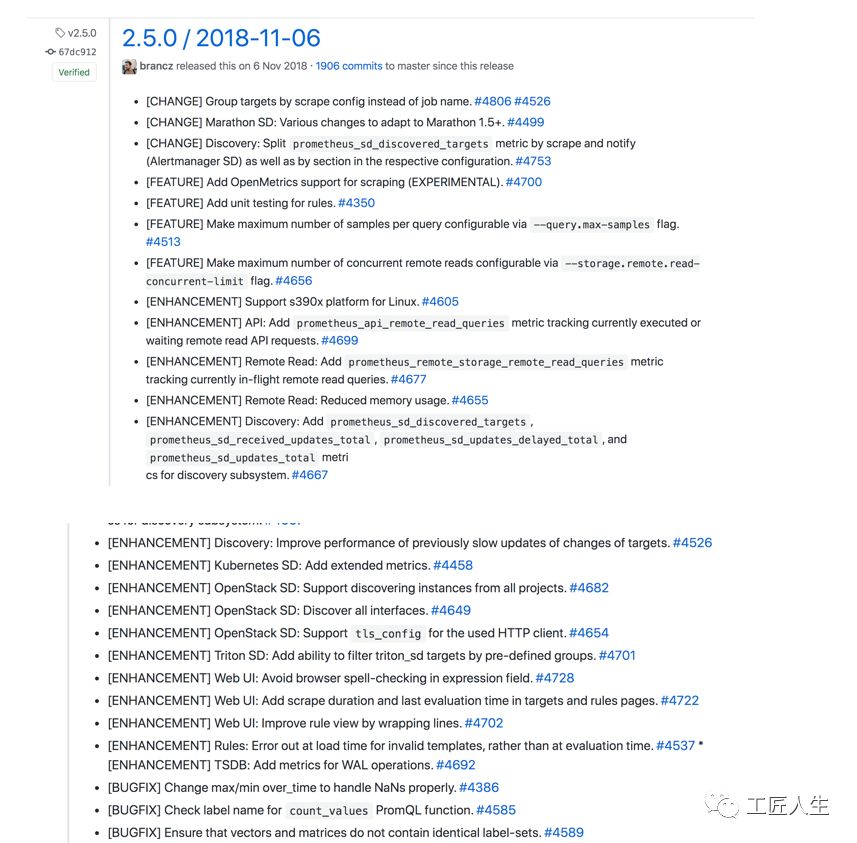
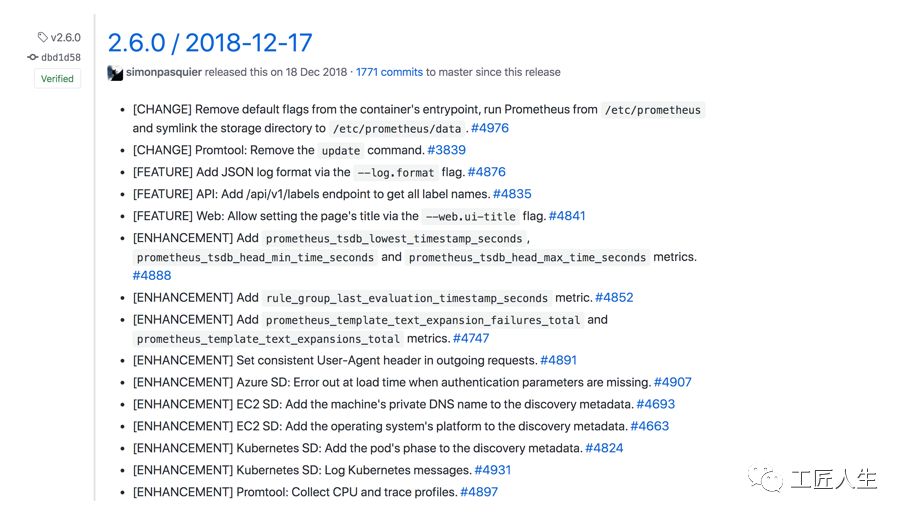
Prometheus 2.6.0
Prometheus 2.6.0进行了许多性能改进。WAL阅读现在快了大约四倍,带来了更快的启动时间。压缩,索引,内存中的序列和低摄取速率服务器使用的RAM数量均已显着减少。远程写入性能已得到改善,现在您可以指定最少数量的分片。现在,远程读取对于后端故障具有弹性。
在服务发现方面,Azure,EC2和Kubernetes获得了新的元数据metadata。对于TSDB、模板和规则,Prometheus本身有一些新指标metrics。相关的,promtool更新已经被删除,所以如果你想转换1.x记录规则到2.x的格式,您将需要使用早期版本的promtool。Prometheus现在在向外的(outbound)HTTP请求的用户代理(user agent)中标识自己,UI中的console选项卡支持选择即时查询的evaluation时间。

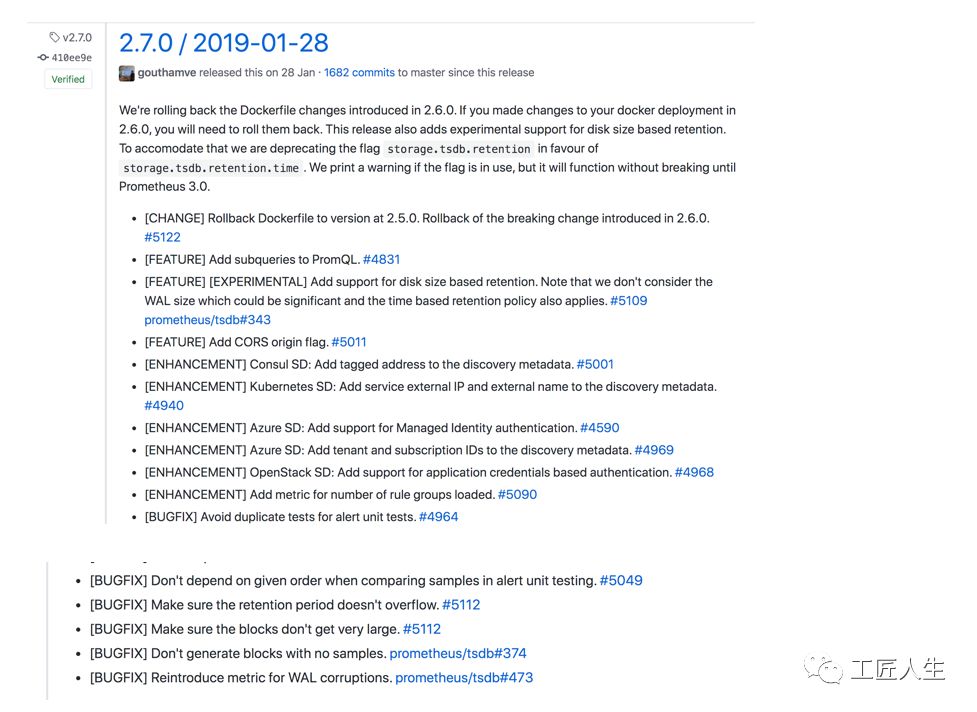
Prometheus 2.7.0
首先,在2.6.0中进行的Docker文件更改将恢复为2.5.0中的设置,因为它产生了意外的影响。如果您已经对你的设置更新到2.6.0版本,就需要在2.7.0版本中恢复。
TSDB为块添加了基于大小的实验性保留,基于时间的保留仍然适用。某些选择器也进行了性能改进,尽管从技术上讲不是Prometheus的更改,tsdbutil
现在有一个 analyze
子命令来帮助弄清是什么在占用空间和搅动。
PromQL增加了子查询支持,因此对于临时查询,不再需要遵循 PromQL中的组合范围向量函数。
现在除了每个规则组的其他指标外,还有一个rule_group_rules_loaded
指标。
对于服务发现,Azure现在可以进行托管身份验证,并且还获得了租户和订阅ID元数据metadata。OpenStack现在支持应用程序凭据。Consul将服务标记的地址添加为元数据metadata,Consul获得了服务标记的地址元数据。
在API / UI方面,现在可以控制允许的CORS来源。
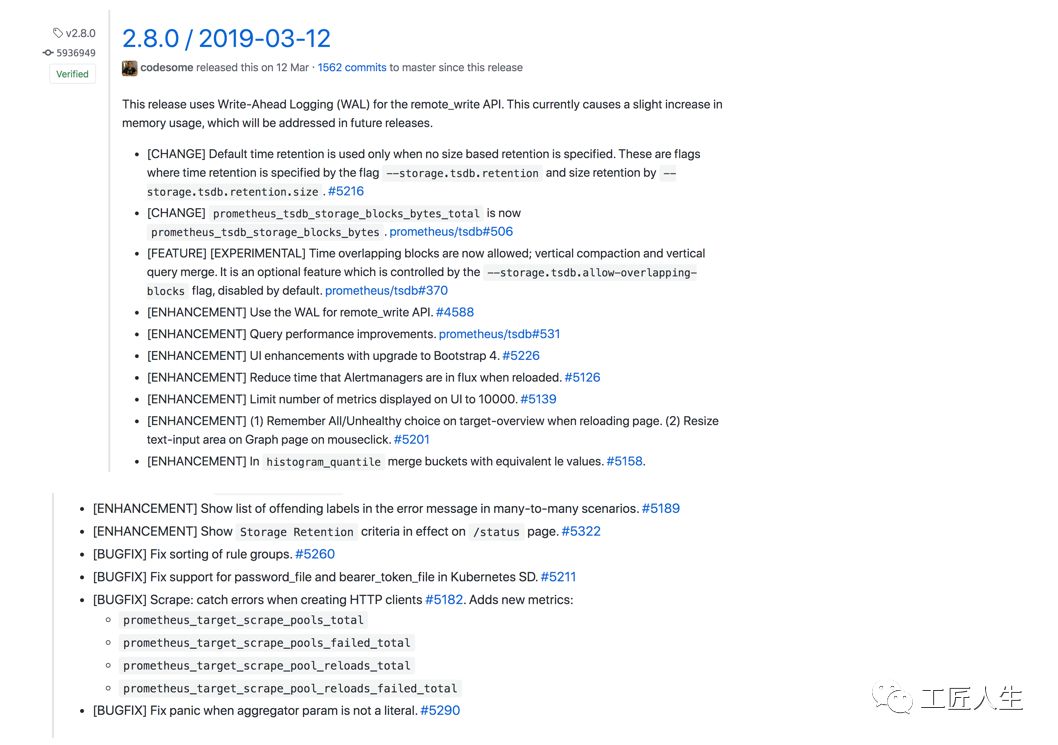
Prometheus 2.8.0
此版本中最大的变化是,远程写入现在可以通过WAL进行,从而使其更可靠并且资源使用更加可预测。另一个改进是,TSDB现在支持压缩重叠块,以后的功能将使用它们来实现批量导入。
要注意的一件事是,如果指定 --storage.tsdb.retention.size
,则默认时间保留将不适用。您仍然可以指定时间保留,在这种情况下两者都适用。
还有其他小的改进,包括PromQL多对多匹配错误现在显示出了问题标签,重新加载配置对警报的影响已经减少,表达式浏览器度量metric自动完成现在有一个10k的限制,以避免包含大量标记的度量名称metric names导致浏览器失效。
Prometheus 2.9.0
该版本解决了在2.8.0中引入的从WAL进行远程写读取时缺少时间序列的问题。 这也将修复启动时的"unknown series references”警告。一个干净的WAL(或者等待所有时间序列的大量生产)是完全解决问题的必要条件。远程写操作还具有更高的内存效率,减少了不稳定目标对CPU的影响,并且连续第三个发行版对TSDB中的索引进行了改进。
有一个 honor_timestamps
选项可以处理行为异常的目标,从而产生不必要和有问题的时间戳。TLS证书现在会自动从磁盘重新加载,并且现在scrapes在Prometheus服务器之间交错(在此之前,它们仅在Prometheus服务器内交错分布)。在服务发现中,OpenStack和Kubernetes具有更多的元数据metadata,并且如果您使用 tag
(现在是tags
)配置字段来提高性能,Consul现在支持多个标签。
还有其他一些小的改进,包括日志输出的可读性更高,状态页具有更多信息以及其他端点通过POST可以工作。

Prometheus 2.10.0
TSDB postings又得到了一次改进,这意味着对很多系列的查询更快。一个新的特殊的metric scrape_series_added
被添加,这将有助于查找引起流失的目标。
Kubernetes服务发现会添加终结点节点和主机名,而Azure会添加公共IP。模板增加了新变量,警报alerts的UI也得到了改善。
有一个小小的重大更改,对于那些使用Alerts API的用户,该值现在是字符串,而不是浮点数(就像我们在查询API上所做的那样),以正确支持非真实值。

Prometheus 2.11.0
从TSDB开始,对发布逻辑进行了更多的性能改进。特别要注意的是,如果您有一个正则表达式 a|b
(例如Grafana为多选择变量生成的正则表达式),则现在将其评估为查找而不是正则表达式扫描,因此 x=~"a"
的效率与 x="a"
一样。对于WAL "unknown series references" 问题现在应该已完全修复(准确的说是上文2.9.0版本中处理的)。每次磁头压缩都会开始一个新的段,这对于减少小容量实例上的磁盘空间很有用,并且有一个选项-storage.tsdb.wal-compression
标志来压缩WAL。
PromQL和远程写入性能得到了改善。您现在可以使用globs作为单元测试的规则文件,就像使用 prometheus.yml
一样。还有一个配置选项,可通过其v2 API与Alertmanager通讯。

Prometheus 2.12.0
在当前的6周发布周期中,每个Prometheus版本都具有较少的功能,但会定期发布。此版本中最显着的功能是,如果Prometheus在启动时崩溃Crash,它将打印正在运行的PromQL Queries查询语句,这将有助于查找过于昂贵的查询。
还有许多TSDB的性能改进,很大程度上与内存有关的。
prometheus_tsdb_retention_limit_bytes
是本次新增指标。虽然与用户无关,但tsdb repository已经在GitHub上合并到主要的prometheus repository。这将使我们作为开发人员的生活轻松一些。

Prometheus 2.13.0
Prometheus 2.13.0这个版本紧随着2.12.0以后发布,进行了许多的修复和改进。
这个版本的改进相当少。tsdb使用程序已包含在此发行版中,然而需要注意的是,它将可能在2.14.0版本中归并入promtool中。
prometheus_sd_configs_failed_total
的counter指标被替换为了prometheus_sd_failed_configs
的gauge指标。
远程读和远程写的性能都有所改进。远程读改进主要用于thanos用户,已经可以允许拉取整个块而不是逐个样本;远程写入为队列管理器提供了一些新指标。
表达式浏览器现在可以显示从query API接收到的报警。Promtool度量标准增加了一些新的告警,并针对坏规则改进了error级消息。

数据库及数据库连接池领域的新书推荐,京东、淘宝、当当有售:

欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:
你点的每个“在看”,我都认真当成了喜欢

