




教老婆学Linux(二)Linux常用命令指南
作者:姚毛毛的博客
Tips:本文约20000字,阅读时间较长,可先收藏再看。
手动目录


一、概述
1.1写在前面 & 学习指南
本文目的:主要是作为一张给初学者入门Linux的学习地图。
所以我只会讲一些我们生产过程中常用的命令及操作,对于命令的一些偏门用法本文会一带而过甚至不讲。
对于Linux命令详解可以参考网站 https://man.linuxde.net/。
实体书的话推荐《跟老男孩学linux运维-核心系统命令实战》。
1.2 常用命令概述
我将Linux下的常用命令分为几类:
1、文件及目录操作
2、文件查看及编辑
3、文件查找及统计
4、文件解压与压缩
5、用户与文件权限
6、资源监控与管理
为什么列的几个章节都是跟文件相关的?
因为在Linux中一切皆是文件,cpu、内存、磁盘、外设、驱动等等,都是以文件形式存在我们的Linux系统中。
1.3 常用快捷键
在Linux下有几个我操作命令的快捷键,基本上我们会在与Linux打交道时时时刻刻都用到,即:
enter 执行命令。输入命令后记得回车,命令才生效。
tab 自动补全。在写文件夹路径的时候,打出首字母直接将后续名称补全,遇到首字母相同的文件夹会展示出列表
↑ 使用方向键的up键,可以找回上个执行的命令,并且可以一直向上查找历史命令,想查看所有历史命令使用 history命令
ctrl + c 中断命令。在linux上执行命令遇到卡死、报错等执行不下去又无法退出的情况,请使用此命令。
ctrl + z 中断命令。一般ctrl + c 无法进行中断操作的时候可以尝试下此命令。
ctrl + insert 复制。复制选中内容。
shift + insert 粘贴。粘贴剪切板中内容。
ctrl + Backspace 向前删除。在输入命令时,有时退格键Backspace无法删除字符,它本身被当做一个字符输入了,使用此命令进行退格删除操作
delete 向后删除。
另外在查看滚动文件时有两个好用的命令,一般在查看日志文件时使用:
ctrl + s 停止滚屏
ctrl + q 恢复滚屏
1.4 帮助命令
man 全方位的帮助命令,使用方式为 man [命令],如
man ls复制
使用 :q 命令退出帮助界面
help 常用帮助命令,使用方式为 [命令] --help,如
ls --help复制
对于本文出现命令,还有一些其他用法,感兴趣可以自行探索。
1.5 历史命令查看
history
# 查看已经敲过的命令复制
可用方向键上下键翻页曾敲出的linux命令。
1.5 注意事项
1、本文使用Linux环境为centOs 7,其他发行版可能会有轻微不一致情况。Mac的命令行也同样如此。
2、在linux中所有命令都要使用空格隔开,如cd xx文件,在第二章节学习时需注意。
3、命令一般都有参数,可使用man或help查看其参数作用。参数写法一般为-开头。如ls -l查看当前目录下所有文件。rm -f xxx文件,删除xxx文件,-f参数含义为如果没有这个文件,也不提示。
二、常用命令
2.1 文件及目录操作
2.1.1 路径切换的好基友:cd、ls、ll、pwd
在linux中,cd命令是永远陪伴我们的小伙伴,也是所有基础操作的王者命令,不是“给你一张过去的cd”,而是路径切换,即Change Directory。
ls 、ll则是跟着 cd 的一对好伴侣,使用它们可以看看当前文件夹下有哪些文件和目录。为什么可以这么屌?因为他们是list嘛,了解下。
为啥ll也是list?因为它是ls -l的马甲呀。
如果cd来cd去的,已在云深不知处,不识庐山真面目,且用pwd来一窥迷径,看看自己的绝对路径,即Print Working Directory。
以下是命令简释:
cd /
# 进入主机根目录
cd ~
# 进入用户根目录
cd ..
# 返回爸爸(上级)目录
cd ../..
# 返回爷爷(上级的上级)目录,可以以此类推。
cd -
# 返回上次目录
cd /yaomaomao/wfy/123/456
# 使用绝对路径,从根目录开始,一层层找到456这个目录。/ 为根目录
ls
# 横向展示当前目录下所有文件及目录
ls -a
# 显示隐藏文件 + ls命令展示的内容
ls -l
# 等同于ll,一般直接用ll命令。
ll
# 纵向展示当前目录下所有文件及目录,及权限信息
ll -a
# 显示隐藏文件 + ll命令展示的内容
ll -h
# 将文件大小从单位bit转换为合适的单位展现,如kb、Mb、Gb,根据实际大小来。
# -h 这个参数在linux中很有用,基本所有需要统计大小的命令中都可以用它,如df -h, du -h,free -h。
pwd
# 查看当前所在路径复制
2.1.2 文件创建好伙伴:touch、mkdir
在linux中,创建文件有很多方法,但是touch是最简洁的一个,轻轻一碰,一个空文件产生了。
而想创建一个目录,则是mkdir,即make directory。
touch wfy.txt
# 在当前目录下创建一个wfy.txt空文件
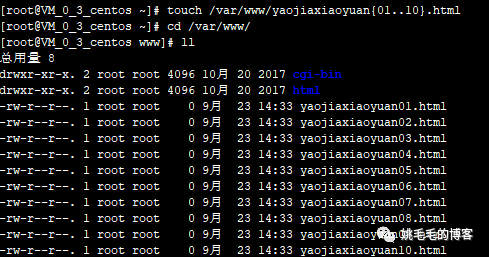
touch /var/www/yaojiaxiaoyuan{01..10}.html
# 批量创建空文件复制
mkdir [目录名]
# 在当前目录下创建一个空目录
mkdir yaomaomao wfy 123 456
# 多个目录同时创建,目录间以空格隔开,创建同级的多个目录
# 如果想要创建一个多级子目录怎么办,那就使用下面的mkdir -p。
mkdir -p /yaomaomao/wfy/123/456
# 多层目录同时创建,一次性在当前目录下创建yaomaomao目录,在yaomaomao目录下创建wfy目录,在wfy目录下创建123目录,在123目录下创建456目录。复制
使用 mkdir -p /yaomaomao/wfy/123/456 创建成功了,还记得上面的命令吗?cd进去看看。
cd yaomaomao/wfy/123/456复制
再pwd看下路径,然后touch个文件看下
touch yaomaomao.txt
ll
# 查看有没有创建成功复制
2.1.3 复制、移动和删除:cp、mv、rm
此cp非彼“CP”,因为我们不是大写的,饭圈女孩请走开,我们只是copy的缩写而已。
mv 即 move,这个很好理解吧。
rm顾名思义就是remove咯。当然,这个命令请谨慎使用。尤其不要用 rm -rf /*。如果你没忍住打了这个命令,ok,等着重装系统吧。
cp [待拷贝文件名] [拷贝后文件名]
# 将前者拷贝一份出来,变为后者。
cp [待拷贝目录] [目标目录]
# 将前者拷贝一份出来,变为后者。文件如此,目录也是如此。
# 但是有时候目录下还有子目录,这个命令就不好用了,得用下面这个命令,cp -r/R。
cp -r [待拷贝目录] [目标目录]
# -r/R 是什么意思?即递归。无限寻找当前目录下所有子目录。倾其所有,拷贝到目标路径下。
mv [待拷贝文件名] [拷贝后文件名]
# 将前者的文件名改为后者的文件名
mv [待移动目录] [目标目录]
# 将前者的文件名改为后者的文件名复制
好了,说完cp、mv,我们来看看rm。rm使用守则:
千万不要单独用星号符 “”,更不要用斜杠加星 “/”
千万不要单独用星号符 “”,更不要用斜杠加星 “/”
千万不要单独用星号符 “”,更不要用斜杠加星 “/”
重要的事说三遍。
常用命令如下
rm [文件名]
# 删除文件。文件不存在会有报错提示。
rm -f [文件名]
# 删除文件。-f,忽略信息,不提示。
rm -rf [目录名]
# 递归删除目录
rm -rf [文件1] [文件2] [目录1] [目录2]
# 删除多个文件和目录
rm -rf *.log
# 删除当前目录所有.log后缀结尾的文件
rm -i *.log
# 删除所有log文件时会一一询问,这个命令一般不会用到,但有些情况下可能会需要。
# 询问时,按 y 确认删除,n 不删除。复制
-r/R 参数,还记得上面的cp -r/R吗,也是递归删除。
2.2 文件查看与编辑
2.2.1 合并文件好帮手:cat
cat [文件名]
# 输出文件所有内容到屏幕上
cat [文件1] [文件2]
# 输出文件1、文件2所有内容到屏幕上
cat [文件1] [文件2] > [文件3]
# 将文件1、文件2合并,输出到文件3中,如果没有文件3会自动生成一个新的文件3
cat -n [文件名]
# 输出文件内容时加上行号
cat -A [文件名]
# 输出文件内容时显示所有隐藏字符复制
cat的特点就是一次性将所有内容输出到屏幕上,用得最频繁的一大功能就是合并文件,并输出到新文件中。因为如果只是查看的话,有很多其他工具都可以查看。
另外cat命令比较常用的还有和管道符“|”一起来用。用来作为管道符的输入内容,如 cat xxx.log | grep '我要找这个单词',这个后续说到文件查找时再说。
2.2.2 观察日志小能手:tail
tail 一般用来查看日志使用,显示文件最新追加的内容
tail -f xxx.log
# 不停地追加显示log文件的最后10行
tail -fn1000 xxx.log
# 加上-n参数,不停地追加显示log文件的最后1000行复制
tail也可以同时显示多个文件内容,但是不推荐使用,如
tail -fn1000 xxx.log xxx2.log复制
如果显示文件不止一个,则在显示的每个文件前面加一个文件名标题
复制
与tail 相对的还有个head,是从开头显示文件内容,一般用法为 head -n [文件名],用法与tail差不多。
2.2.3 编辑文件我拿手:vi/vim
要说在linux中最强大的编辑器是什么,10个人有10个人会说,是vim。
那么,我们这里说的vi跟vim啥区别,嗯,其实没啥区别,vim就是vi的增强版。喜欢黑白的用vi,喜欢彩色的用vim就行了。
vim用起来很逆天,但只是个工具而已,不必那么极客,会一些常用命令就好了。
好了,我们先用 vim [文件名] 进入文件吧。
vim有几种模式,即normal模式、编辑模式、命令模式。
哦,还有个visual模式,不常用,normal模式下按v可以进入,没啥用。
normal模式顾名思义是正常模式,我更愿意称呼为无状态模式,使用vi/vim [文件] 进入文件时,默认就是这个模式,在进入其他模式后,可以使用 Esc 键返回这个模式。
vim [文件名]
# 默认进入normal模式复制
normal模式下按下i、a、o、s,进入编辑模式,使用频度一般也是这个顺序。编辑模式下,输入内容就跟我们windows下打开写字板操作没什么区别。
i
# insert,光标当前字符前插入
a
# append, 光标当前字符后插入
o
# 下一行插入
s
# 不常用,删除当前字符并插入复制
此外,进入编辑模式还有这几个键的大写模式I、A、O、S,不常用,具体可以自行探索。
光标移动
←
# 向左移动
↓
# 向下移动
↑
# 向上移动
→
# 向右移动
ctrl + f
# 向下翻页
ctrl + b
# 向上翻页
0
# 行首
$
# 行尾
space
# 空格键,一直向下移动一个字符。跟左方向键(→)的区别是,左方向键(→)只能在本行移动。复制
如果觉得上下左右方向键不方便,还要移动手臂,可以在normal模式下,使用h、j、k、l键依次进行左、下、上、右操作。
退出、保存,在normal模式下使用冒号(:) 进入底线命令模式
:q
# 退出不保存
:q!
# 强制退出不保存
:wq
# 退出保存
:wq!
# 强制退出保存复制
你可能已经发现了,在vim中,感叹号(!)就是强制的意思。
最基本的文本操作说完了,如果vim仅仅是这样,那便当不上linux上最牛逼的文本编辑器这一称号了。那么下面说下提升咱们文本操作效率的一些快捷键。
normal模式下的一些快捷键
G
# 大写g,移动到文末。
nG
# n,数字,代表行号。100G则是移动到第100行。1G则是行首。
gg
# 移动到文首。同样效果还有1G。
H、M、L
# 分别代表high、middle、low,即移动当前屏幕页的最上方、中间、最下方。
dd
# 删除当前行,可连续按d删除。
ndd
# n,数字,代表行号。ndd,删除当前行及之后的多少行,如100dd,删除当前及之后的100行
u
# 撤销操作。如果上面使用dd删除错了,可按一下u进行撤销。编辑模式下撤销需要按Esc进入normal模式,按 u 撤销。
y
进入复制模式。
yy
# 复制当前行。
nyy
# n,数字,代表行号。聪明的你想必已经知道了,如16yy,即复制当前行至16行的内容。
p
# 粘贴当前vim剪切板中内容。
yyp
# 常用组合键,即在上面使用yy复制后,可立即使用p粘贴,或者移动到指定地点后按个 p,即把刚才的内容粘贴过来了。
ggyG
# 全选复制。看这个命令,到行首,按y进入复制模式,再移动光标到文末,然后可以按p粘贴了。当然,如果你的光标已经移动到相应位置,可以直接ggyGp。
# 这里有个缺陷,这样的复制内容只能在vim中进行粘贴,一旦退出vim,剪切板中则无此内容了。那怎么办呢?看下面这个命令。
gg"*yG、gg"+yG
# 这两个全选复制的命令,可以将内容带出到vim之外。当然,一般用不到,只有某些特殊情况下会用到。复制
说完移动、删除、复制、粘贴,再来说说查找。normal模式下输入 / 或 ? 。
/yaomaomao
# 即向下寻找yaomaomao这个字符串。按n会一直向下找。
?姚毛毛
# 即向上寻找 姚毛毛 这个字符串。按n会一直向上找。
n、N
# 配合/、?则会很有趣,/ + n,一直向下找,/ + N,一直向上找, ? + n,一直向上找, ? + N,一直向下找。复制
替换,则是要进入底线命令模式了,上面说过了,即在normal模式下使用冒号 : 进入此模式。
:%s/old/new/g
# 全局替换,将old字符替换成new复制
如果不想全局替换,而是指定行数,可以使用此命令:
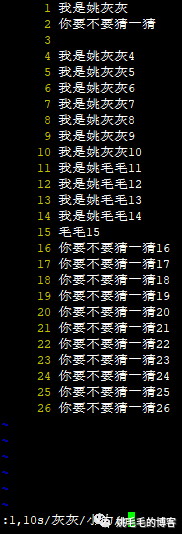
:[n1],[n2]s/old/new/g复制
如下图所示,将1到10行的灰灰替换成了小力。
从第N行到最后一行的替换怎么做?相信聪明的你应该已经想到了:
:[n1],%s/old/new/g复制
另外命令模式下还有些有趣的命令,如:
:set number
# 显示行号
:set nonumber
# 不显示行号
:set nu
:set nonu
# 同上,nu即是number的简写
:set ff
# 查看文件格式,可能会展示foramt=dos,在windows下编辑然后上传到linux下的文件可能会存在一些格式问题,所以需要转换下文本格式,即下面的命令:set ff=unix
:set ff=unix
# 设置文件格式,ff即format, 即文件设置为unix。可以设置后再用:set ff命令再看下复制
此外还有诸如分割窗口【:split】、重载文件【:e!】等命令。
底线命令当然不只这么几种,如果还想要了解更多的命令,可以参考。
菜鸟教程的linux-vim教程https://www.runoob.com/linux/linux-vim.html。
及我刚刚推荐的linux命令大全https://man.linuxde.net/vi。
最后,咱们总结下几种模式的切换:
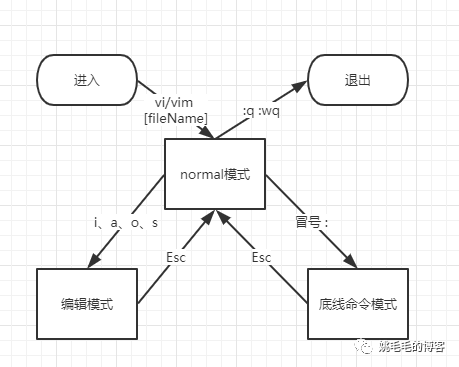
1、vi/vim [fileName] --> normal模式
2、normal 下 输入 i、a、o、s 键--> 编辑模式
3、normal 下 输入冒号 : --> 底线命令模式
4、Esc退出到normal模式
5、:q :wq :q! :wq! 退出不保存/保存文件复制
哦,还有个 normal 下 输入v 进入视图模式,这个在以后的进阶学习里可以说下,一般没啥用。
2.2.4 vim小兄弟:more、less
说完vim,再来看看more与less,这是基于vim的一对好基友。
这两个命令类似cat,不过是以一页一页的方式显示阅读。
more可以显示百分比,一般从头排查问题日志可以用more。
而less则在查看大文件时有奇效,据说是部分加载到内存中。
先看看more
more [文件名]
more -f [文件名]
# 加参数f,-f 参数的含义为计算行数时,以实际上行数为准(有些单行字数太长的会被认为两行或以上)复制


可以看到,more打开文件是能看到你当前查看文件的百分比的。
使用more查看文件或日志,有些快捷命令可以提高我们的效率:
空格键
# 向下滚动一屏,f键效果一样,但一般使用空格键,比较方便
b
# 向上滚动一屏
=
# 查看当前行号
:f
# 输出当前文件名 及 行号
q
# 退出more命令, ctrl + c也可以退出复制
如果不用 -f 参数查看命令,可以试试来回用b、空格上下翻页,会发现来回查看的内容可能不一样。因为不用-f强制显示行数,有些单行字数太长的会被认为两行或以上。
more 还有个命令叫做指定行查看,即:
more +[num] [文件名]
# 查看指定行号以后的内容
more -[num] [文件名]
# 查看指定行号以前的内容,这个命令一般不用,主要用+num。这个命令如果用的话一般会作为导出使用。复制
示例为
more +1000 放学后.txt
more -1000 放学后.txt复制
less的好处是查看文件之前不会加载整个文件,所以在查看大文件时有奇效。如果文件特别大,例如超过1G,可以使用less,提高效率。
less [文件名]
# 基本查看命令
less -m [文件名]
# 类似more命令,显示百分比
less -N [文件名]
# 显示行号复制
与more 命令相似,less也有相同的快捷键,只是不能用ctrl + c退出
q
# 退出less命令
d
# 向下移动半屏
u
# 向上移动半屏
j
# 向下移动一行
k
# 向上移动一行
空格键
# 向下滚动一屏,f键效果一样,但一般使用空格键,比较方便
b
# 向上滚动一屏
=
# 输出当前文件名 及 行号、百分比
: f
# 输出当前文件名 及 行号、百分比复制
并且less不只是more可以查看,还可以用使用vi编辑器的查找命令
/[查找字符]
# 配合n键,从上往下查所有
?[查找字符]
# 配合n键,从下往下查所有复制
还记得vim的n和N吗,一样的效果。
2.2.5 我是外挂我骄傲,不打开文件也编辑:sed
文件查看与编辑终于到了最后一节了,这次来说说大杀器sed。
使用vim需要在文件内部编辑,有时只是想在文件底部添加一句话或一个参数,需要经历
vim [文件] ->
G (移动到底部)->
o 下一行添加 ->
shift + insert(插入剪切板中内容)或自行编辑
这一整套步骤,比较繁琐。
那有没有轻便一点的方法呢?
sed (Stream Editor),你值得拥有。
Ps.其实还有个echo命令也有这个功能。
echo “追加内容” >> [文件名]复制
案例:
sed -i '$a 我是姚毛毛' 放学后utf-8.txt复制
在文件末尾追加了“我是姚毛毛”这串字符串。
如图:
那么,想在指定行或者每行前面或者后面都追加字符呢?
sed -i '20a 哦,我是姚毛毛20 append' 放学后utf-8.txt
# 追加“哦,我是姚毛毛20 append”,在文件【放学后utf-8.txt】第20行字符下一行复制
如图: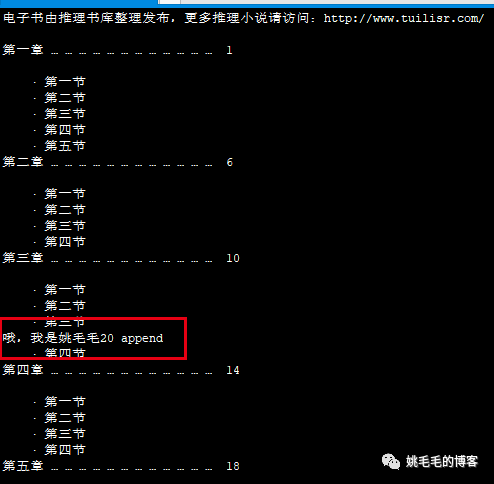
sed -i '20i 哦,我是姚毛毛20 insert' 放学后utf-8.txt
# 插入“哦,我是姚毛毛20 insert”,在文件【放学后utf-8.txt】第20行字符上一行
sed -i 'a 我是姚毛毛 append' 放学后utf-8.txt
# 追加“我是姚毛毛 append”,在文件【放学后utf-8.txt】每行字符下一行
sed -i 'i 我是妖生 insert' 放学后utf-8.txt
# 插入“我是妖生 insert”,在文件【放学后utf-8.txt】每行字符上一行复制
所以,还有种简单的追加字符法
sed -i '1i 哦,我是姚毛毛,在开头 insert' 放学后utf-8.txt
# 意思是第一行前插入字符
sed -i '9999a 哦,我是姚毛毛,在结尾 append' 放学后utf-8.txt
# 意思是第9999行后追加字符复制
上面说的都是增。那增删改查四兄弟的删、改、查呢,sed也可以做吗?
看了上面的内容,我们先小结下sed的基本格式:
sed [参数选项] [sed内置命令字符 更新内容] [输入文件]复制
改,内置命令字符s:
sed 's/book/books/' file
# 替换文本中的字符串
sed -n 's/test/TEST/p' file
# -n选项和p命令一起使用表示只打印那些发生替换的行
sed -i 's/book/books/g' file
# 直接编辑文件选项-i,会匹配file文件中每一行的第一个book替换为books复制
这里特别注意的是参数-i,这个意思是直接修改文件内容。如果不用-i,可以试试,验证下是不是只输出到终端,而没有实际修改文件内容。
如图: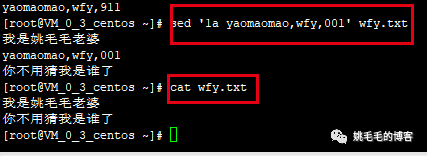
使用sed命令在第一行数据后添加了部分内容后,再用cat查看文件,文件内容并没有改变。
删,内置命令字符d:
sed '2d' wfy.txt
# 删除第2行。d为sed内置命令,2为行数复制
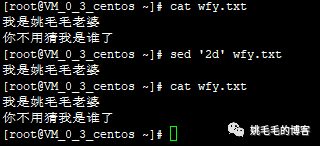
正如上面说的,如果不加-i,只是将删除后内容输出到终端,而没有实际改变文件。那么,加上-i试试呢?
sed -i '2d' wfy.txt复制
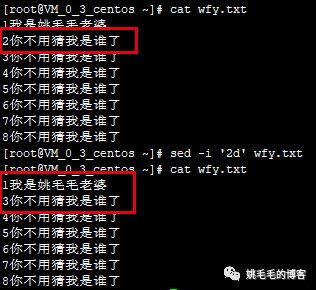
看,第2行是不是已经被删掉了。
如果要删除多行怎么办?
sed -i '1,3d' 放学后utf-8.txt
# 删除1到3行
sed -i '/\/sbin\/nologin/d' passwd
# 删除不能登录的用户,千万不要在我机器上执行,我的ftp用户就是这个
sed -i '/^姚毛毛/,/$2019/d' passwd
# 删除以 “姚毛毛” 开头一直到以 2019结尾的行复制
现在我们总结下sed常用的参数跟内置命令字符:
无参数,只显示修改后内容在终端,不修改真实文件内容,一般可与管道符“|”一同使用作为输入源。
参数 -i,必须品,加上此参数才能真正修改文件。
参数 -n,一般与内置命令字符p共用,显示修改行。
内置命令字符 i、a,插入、追加。
内置命令字符 s、d,替换、删除。
$代表文件末尾,^代表文件开头。
作为shell三剑客之一(另外两个是grep、awk),sed还有很强大的正则表达式功能,但是我列举的是在一般运维中最常用的几个功能。对sed感兴趣,想深入研究的可以自行探索。
2.3 文件查找及统计
2.3.1 文件大小统计与排序:du、sort
2.3.1.1 du常用命令
du -sh
# 统计当前文件夹内容总大小
du -sh [文件夹1] [文件1]
# 统计当前目录下的文件夹或文件大小
du -sh /usr/local
# 显示指定目录大小
du -a
# 显示当前目录下所有文件所占空间(含隐藏文件)
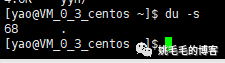
du -s
# 显示当前目录总大小
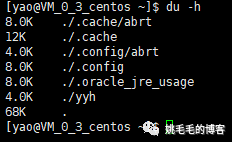
du -h
# 展示当前目录下所有文件及目录(包含子目录下内容)大小,-h会换算成K、M、G等人类易读结果
du -h *
# 统计当前目录下,非隐藏文件及目录的大小
du -h --max-depth=1 [目录]
# 只显示指定目录下第一层目录的大小
du -h --max-depth=2 [目录]
# 只显示指定目录第一、二层目录的大小复制
图示:
du -sh
统计当前文件夹内容总大小
du -sh
统计当前目录下的文件夹或文件大小
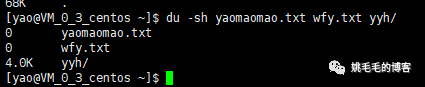
du -sh /usr/local
显示指定目录大小
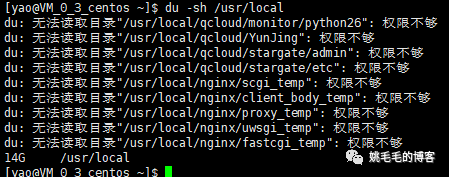
du -s
显示当前目录总大小
du -h
-h会换算成K、M、G等人类易读结果
du -a
显示当前目录下所有文件所占空间(含隐藏文件)
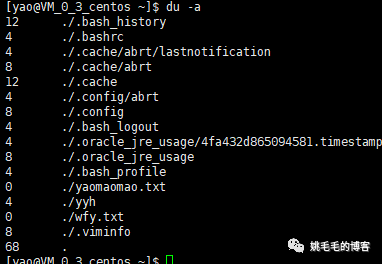
du -h --max-depth=1 /home/yao
只显示指定目录下第一层目录的大小
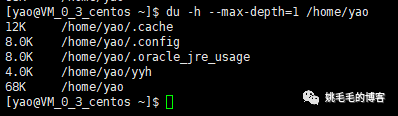
du -h --max-depth=2 /home/yao
只显示指定目录第一、二层目录的大小
du 常用参数总结:
-a或-all 显示目录中个别文件的大小。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-s或--summarize 仅显示总计,只列出最后加总的值。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。复制
此外,还有些参数用以参考,一般用于区分软硬链接才适用:
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-L<符号链接>或--dereference<符号链接> 显示选项中所指定符号链接的源文件大小。
-S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
--exclude=<目录或文件> 略过指定的目录或文件。
-D或--dereference-args 显示指定符号链接的源文件大小。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-l或--count-links 重复计算硬件链接的文件。复制
2.3.1.2 文件排序:du + sort + head 常用命令
du -a /home/yao | sort -n -r
# 按照文件大小倒序排序(含隐藏文件)复制
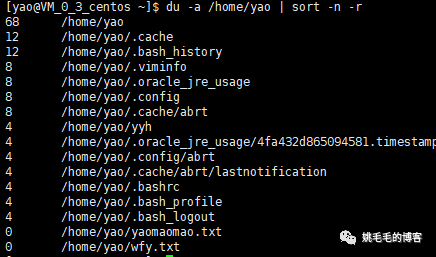
du -h /home/yao | sort -n -r | head -n 10
# 非隐藏文件,筛选前10,可读方式展现文件大小;
# sort -n -r 也可以写作 sort -rn;
# -n:依照数值的大小排序;
# -r:以相反的顺序来排序;复制
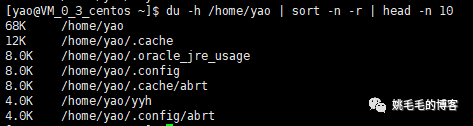
du -h --max-depth=1 /home/yao | sort -n -r | head -n 10
# 指定目录第一层,筛选前10,可读方式展现文件大小复制

du -h --max-depth=1 /home/yao | sort -rn -o 'sort.txt' | head -n 10
# 使用sort -o 参数将排序结果存入指定文件
另外,sort还有些其他参数,例如根据文件名排序而不是大小。复制
# sort基本参数如下
-n:依照数值的大小排序;
-r:以相反的顺序来排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-f:排序时,将小写字母视为大写字母;
-m:将几个排序号的文件进行合并;
# 以下几个参数与 -n 排序方式互斥
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-M:将前面3个字母依照月份的缩写进行排序;复制
2.3.2 查找文件我最强:find
2.3.2.1 find查找常用命令示例
find / -name 'wfy.txt'
# 从根目录下开始查找文件wfy.txt
find . -name '*fy.txt'
# 当前目录下,查找fy.txt后缀的文件
# “.”表示当前目录,"*"表示任意长度字符
find / -type f -size +500M
# 从根目录开始查找,500M以上文件
# / :根目录
# . : 当前目录
# -type f: f为普通文件类型,f改为d则是目录文件,l则是符号链接文件,-type 还有其他参数,不在这里一一列举
# -size +500M :500MB以上
# 一般磁盘空间不够,删除垃圾文件时会使用到此命令
find . -type f -size +1k
# 查找当前文件夹下超过1k的文件,注意k是小写。
find . -type f -mtime -30
# 查找当前目录下30天之内修改过的文件
# -mtime:代表修改时间,最常用,类似参数有-atime、-ctime
# -atime:代表访问时间,查看过就算
# -ctime:文件状态改变时间
# -30:代表30天以内,30为n,数字自己填写
# +30:30天以前
# 30:距今第30天
find /var/log/ -mtime +30 -name '*.log'
# 查找指定目录/var/log/ 下30天以前的log文件
find /etc ! -type f
# 查找 /etc 目录下不是普通文件的 文件
# "!":感叹号,取反
find /etc ! -type l -mtime -30
# 查找/etc 目录下不是符号链接文件,并在30天内被修改过的文件
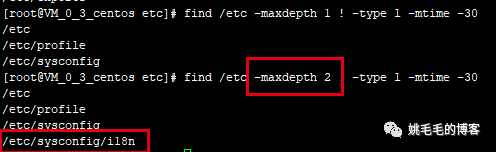
find /etc -maxdepth 1 ! -type l -mtime -30
# 查找/etc 第一层目录下不是符号链接文件的文件,并在30天内被修改过
# -maxdepth : 前面du学过,指定目录层级,-maxdepth 1代表第1层,-maxdepth 2代表延伸到第二层复制
-maxdepth 可能有点不好理解,所以截了个示例图
2.3.2.2 使用find 组合命令:统计与删除
基本常用的find命令都已经讲完了,再说下运维中可能常用的一个组合命令,利用find删除N天以前的文件或日志。
先用wc -l来统计下log数量,再删除看看
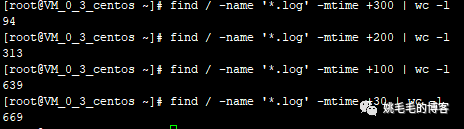
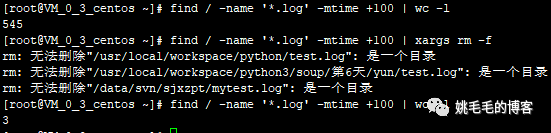
find / -name '*.log' -mtime +300 | wc -l
# 从根目录下开始搜索300天之前的log文件,并统计数量
# “|”:管道符,将前面查到的数据作为输入源给后面的命令复制
第一种删除方式:-exec
find / -name '*.log' -mtime +300 -exec rm {} \;
# 查找30天以前的log文件,使用-exec加rm将其删除
# 再使用上面的命令重新查看一次
find / -name '*.log' -mtime +300 | wc -l复制

第二种删除方式:-ok
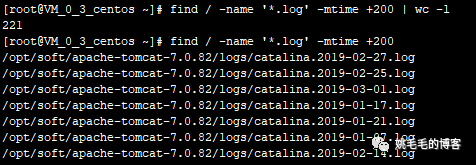
find / -name '*.log' -mtime +200 -ok rm {} \;
# -ok : 询问删除,y删除,n不删除,回车默认不删除复制

第三种删除方式:xargs
依次执行查看结果
find / -name '*.log' -mtime +100 | wc -l
find / -name '*.log' -mtime +100 | xargs rm -f
# xargs : 命令传递参数过滤器,与管道符“|”一同使用,将前面的命令传递给后面的命令使用
find / -name '*.log' -mtime +100 | wc -l复制
2.3.2.3 find与xargs的组合使用
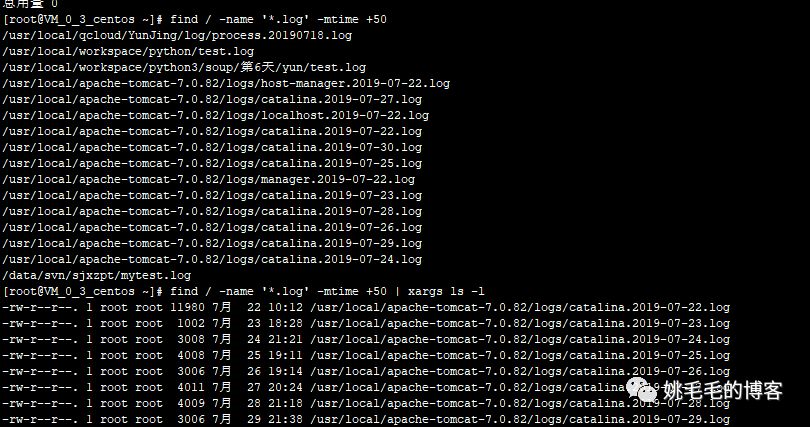
对于50天前的log文件进行详情查看
find / -name '*.log' -mtime +50 | xargs ls -l
# 利用xargs + ls -l 命令来进行文件的详细属性查看复制
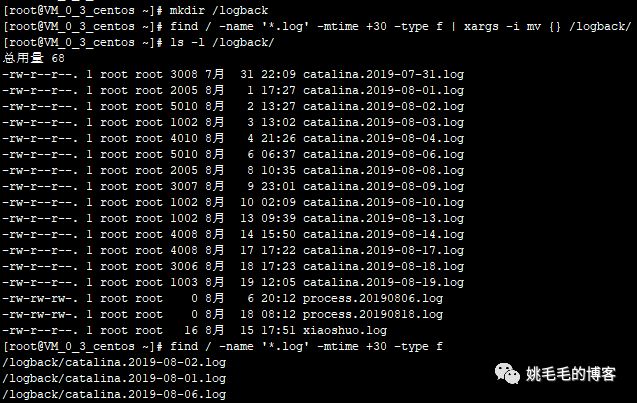
移除50天前的文件
mkdir /logback
# 创建根目录下的 /logback文件夹
find / -name '*.log' -mtime +50 | xargs -i mv {} /logback
# 将50天前的所有log文件移动到 /logback 文件夹下
# xargs -i + {},将前面查找到的文件都作为参数给mv命令执行
ls -l /logback
# 查看 /logback 下所有文件详情复制
2.3.2.4 find下xargs与exec的区别
区别一:
-exec,是将查找到的结果文件名逐个传递给后面的命令执行,文件多会导致效率低;
xargs,则是一次性传递,效率较高,并可使用-n参数控制传递文件个数。
区别二:
-exec,文件名有空格等特殊字符也照常处理;
xargs,处理特殊的文件名(例如文件名有空格)需要采用特殊的处理方式(find . -name "*edu" -pringt0| xargs -0 ls -l)
验证区别一,示例如下:
find /logback -name '*.log' -exec echo yaomaomao {} \;
find /logback -name '*.log' | xargs echo yaomaomao复制

可以看到使用-exec每次获得一个文件输出一次,xargs则只输出了一行。
xargs还可以用-n参数控制每次输出的文件个数
find /logback -name '*.log' | xargs -n5 echo yaomaomao复制

可以看到,每行输出5个参数(文件名),不足的行输出剩下的。
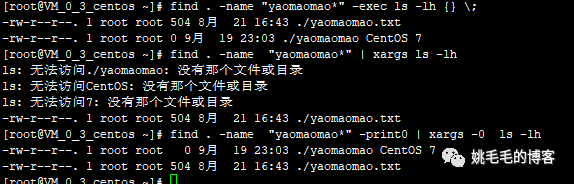
验证区别二,示例如下:
touch yaomaomao.txt;touch "yaomaomao centOS 7";ll yaomaomao*
# 小技巧:使用“;”分号可以一次性执行多个命令
# 注意:查看和创建带有空格的文件时,使用引号括起来复制

find . -name "yaomaomao*" -exec ls -lh {} \;
# 正常查找出来
find . -name "yaomaomao*" | xargs ls -lh
# 可以看到使用此命令报找不到那个文件或目录
find . -name "yaomaomao*" -print0 | xargs -0 ls -lh
# 正常查找复制
其实find还有很多强大的功能,截两张图大家就知道了

这本书就是我开头推荐的《核心系统命令实战》。
2.3.3 shell三剑客之二:grep,字符查找有一手
2.3.3.1 grep 常用命令示例:
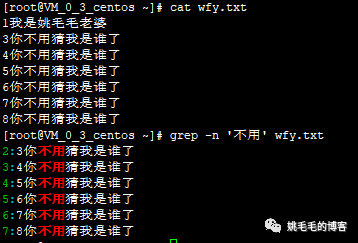
grep -n '不用' wfy.txt
# 查找wfy.txt文件中含有“不用”的字符行
# -n 显示行号
# -i 不区分大小写
# -v 反向过滤
# -c 统计匹配行复制
grep -c '不用' wfy.txt
# 统计包含“不用”字符行的行数
grep -v '不用' wfy.txt
# 查找不包含“不用”的字符行复制

2.3.3.2 grep同时查找多个文件
# 先来准备数据
cp wfy.txt wfy2.txt
# 复制一份文件
sed -i '1i 我是复制的wfy2' wfy2.txt
# 使用sed在第一行前加上一行标题区分
cat wfy2.txt
# 查看刚才复制的文件
grep -n '不用' wfy.txt wfy2.txt
# 查询多个文件中包含“不用”字符的文件内容,并显示行号
# 直接在末尾跟上多个参数复制
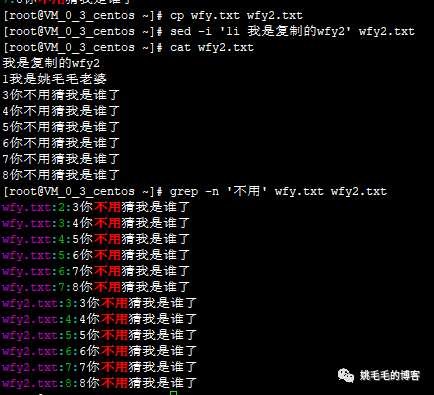
grep -n '不用' *
# 查询当前目录下所有文件中包含“不用”的文件,并显示对应行号复制

2.3.3.3 grep递归查找
# 我们来先准备下数据
mkdir dirwfy ; cp wfy.txt dirwfy/wfy3.txt;sed -i '1i 我是wfy3,注意看' dirwfy/wfy3.txt;cat dirwfy/wfy3.txt
# 创建目录dirwfy,在dirwfy目录下创建wfy3.txt文件,并修改标题复制

# 使用上面的grep -n 看下效果
grep -n '不用' *
# 查不到dirwfy下文件
grep -rn '不用' *
# 如图,可以查到dirwfy下文件复制

2.3.3.4 grep查找对应字符前后n行
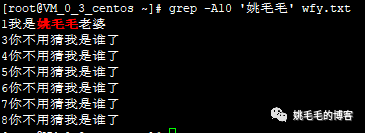
grep -A10 '姚毛毛' wfy.txt
# 查看“姚毛毛”字符行后10行数据
# -A : after复制
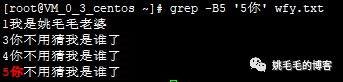
grep -B5 '5你' wfy.txt
# 查看“5你”字符行前5行
# -B:before复制
grep -A1 -B1 '7你' wfy.txt
# 查看"7你"字符前后各1行数据复制

2.3.3.5 grep组合命令
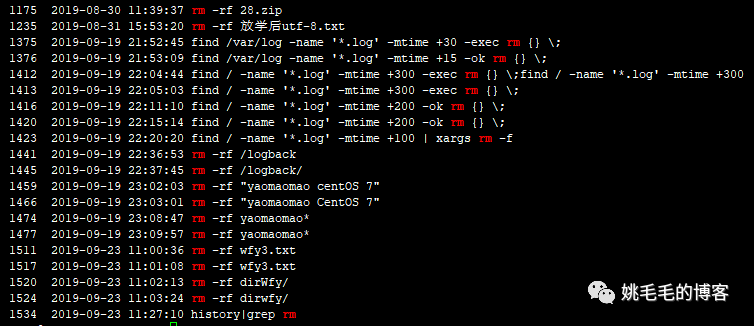
history|grep rm
# 查找历史命令中执行了哪些删除命令复制
rpm -qa |grep yum
# 查询linux下是否有安装过此rpm包
ps -ef|grep java
# 此命令为一般运维中最常用命令,查询linux进程中是否运行了此程序
pgrep -java
# 查找java进程,与上面查找功能相同,但是只显示进程号
pgrep -l java
# 查找java进程,与上面查找功能相同,但是显示进程号及进程名
kill –9 'pgrep java'
# 批量关闭java进程
# pgrep:查找正在运行的程序;pgrep是grep的扩展功能,同样的还有egrep、fgrep,用的不多了解下就行
# egrep:扩展正则表达式
# fgrep:不识别正则表达式
ps -ef |grep $ORACLE_SID|grep -v grep|awk '{print $2}' | xargs kill -9
# 得到所有oracle进程并关闭复制
2.3.4 wc
wc最常用命令一般为组合命令,如:
ls | wc -l
# 统计当前文件夹下有多少文件
ls *.txt | wc -l
find . -maxdepth 1 -name '*.txt' | wc -l
# 统计当前文件夹、第一层目录下所有的txt文件数量
# 上面两个命令都可以复制

wc基本命令:
wc -l /etc/inittab
# 统计文件内容行数
# -l :统计行数
# -w :统计单词数
# -m :统计字符数
# -c : 统计字节数
# -L : 打印最长行的长度
# 全部执行下看看
wc -l /etc/inittab;wc -c /etc/inittab; wc -m /etc/inittab;wc -w /etc/inittab; wc -L /etc/inittab
wc /etc/inittab
# 不加参数则默认输出行数、单词数、字节数
# 等同参数为-lwc
# 字节数跟字符数怎么一样的?因为都是英文,我们加个中文字进去看看
sed -i '1a #中' /etc/inittab
wc -lcmwL /etc/inittab
# 注意:输出内容并不是按照我们敲出的命令行中参数来排序的,它有其固定顺序--> lwmcL
# 按照lwmcl的顺序排列后,可以看到字节数比字符数多了两位,因为一个#符号1字节,一个英文字符代表2字节,一个中文字符4字节,我们添加了#中,所以是添加了5字节,但是只增加了2字符。复制

2.4 文件解压缩
2.4.1 官宣的linux压缩工具:tar
tar的基本命令格式为
tar [参数选项] [文件或目录]复制
我们前面学的命令凡是参数选项都要加-,tar命令有点特殊,加不加都可以,如 tar -z 可以写成 tar z。
tar常用命令:
tar -zcvf [压缩包名] [待打包文件或目录]
# [压缩包名] 一般为 tar.gz 后缀
# z :通过gzip压缩或解压
# c :创建新的tar包
# v :显示命令执行过程
# f :指定压缩文件的名字
# t : 不解压查看tar包内容
tar tvf [压缩包]
# 不解压查看压缩包内容
tar zxvf [压缩包] -C [解压路径]
# 将压缩参数的c换成x,便是解压
# -C:指定解压路径,不加-C解压到当前目录复制
常用命令示例:
# 先来准备点数据
cd ~
# 返回用户根目录
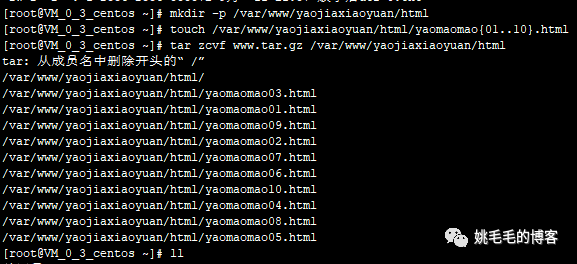
mkdir -p /var/www/yaojiaxiaoyuan/html
# 创建多级目录
touch /var/www/yaojiaxiaoyuan/html/yaomaomao{01..10}.html
# 在上面的目录中批量创建多个文件
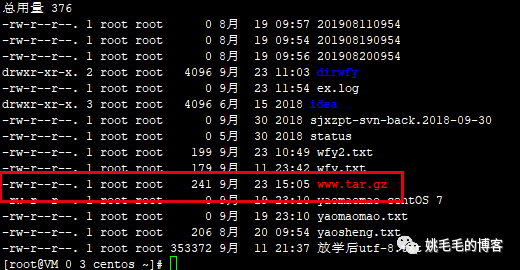
tar zcvf www.tar.gz /var/www/yaojiaxiaoyuan/html
# 将目录/var/www/yaojiaxiaoyuan/html打包为www的tar包复制
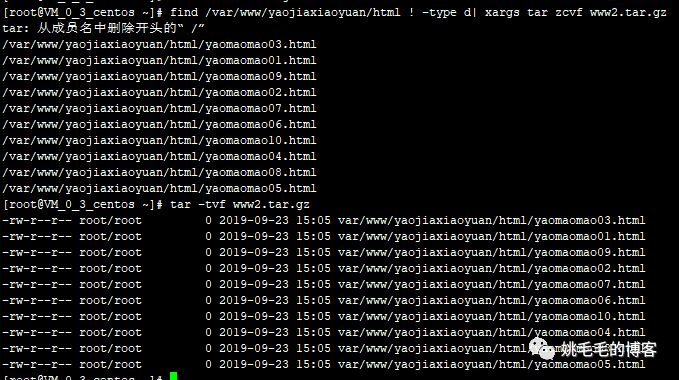
mkdir /var/www/yaojiaxiaoyuan/html/test
find /var/www/yaojiaxiaoyuan/html ! -type d| xargs tar zcvf www2.tar.gz
# 查找/var/www/yaojiaxiaoyuan/html下不是目录的文件,将其打包为www2.tar.gz
# 根据之前find学到的命令,组合打包
# tar命令的--exclude参数也有排除打包的功能,自行研究,不再赘述。
tar -tvf www2.tar.gz
# 不解压查看压缩包www2.tar.gz中文件复制
mkdir ./yao/ yao2
tar zxvf www.tar.gz -C ./yao/
# 解压www.tar.gz 到yao目录下
# 可以看到连var这个目录打打包进来了复制
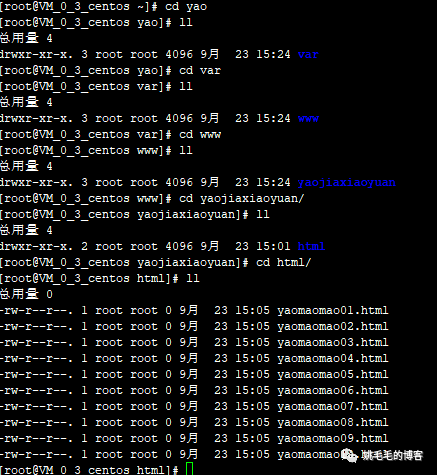
如果不想打包那么多层级怎么办,直接cd到需要打包的目录进行打包。
2.4.2 gzip
gzip只能打包文件,不能打包目录。
gzip打包文件后会将源文件删除。
gzip参数:
gzip 【参数选项】 【待压缩文件或压缩包】
# -d :解压
# -v :显示解压过程
# -l : 列出压缩文件内容信息
# -c : 不改变原始文件
# -r :递归压缩目录下所有文件
# -t :检查压缩文件完整性
# -数字<1-9> :指定压缩率,值越大压缩率越高,默认为6复制
gzip常用命令示例:
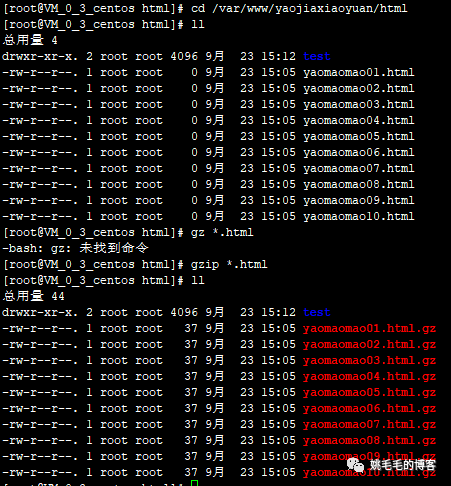
cd /var/www/yaojiaxiaoyuan/html
gzip *.html
# 打包所有html文件,可以看到html压缩成gz文件后不见了。复制
gzip -l *.gz
# 不解压展示压缩包内信息
gzip -dv *.gz
# 解压gz文件复制
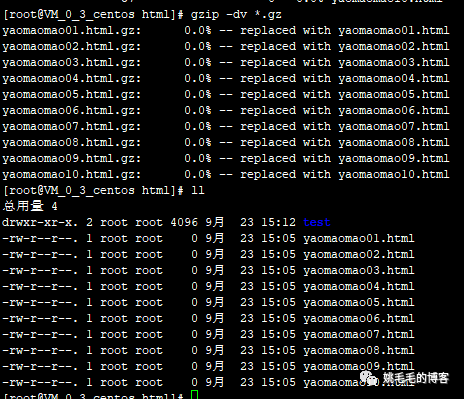
可以发现,解压后gz包也不见了。那怎么保留源文件?
echo '试试' >> yaomaomao01.html
# 先在yaomaomao01.html文件中添加点内容,echo在这里的作用与sed类似
gzip -c yaomaomao01.html > 01.gz
# 使用-c + 重定向符号,将yaomaomao01.html压缩为01.gz,并且不删除源文件,解压也是一样的操作复制
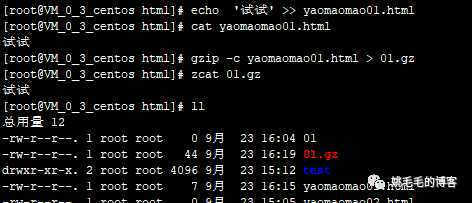
gzip -dc 01.gz > 01.html
# 将01.gz解压为01.html,可以看到源文件01.gz还存在复制
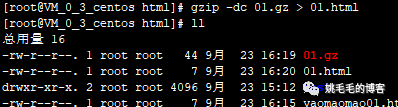
扩展:可以使用zcat、zgrep、zless、zdiff等扩展组件查看压缩文件,与cat、grep、less和diff等命令一样,如图:
zcat 01.gz复制

gz不能压缩目录,这个开头说了,报错如下:
gzip test
# ==>> gzip: test is a directory -- ignored复制

2.4.3 zip/unzip
2.4.3.1 zip
zip压缩格式,windows、linux、mac上都是通用的压缩格式,并且跟tar一样,可以压缩目录。
zip yao.zip *
# 压缩当前目录下所有文件复制
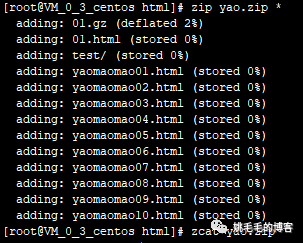
但是这样打包并不能压缩子目录下文件,只能压缩子目录本身,如图:
cd test
touch test01.txt
cd ../
zip yao2.zip *复制
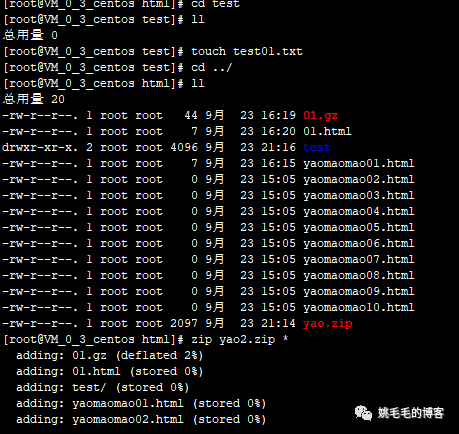
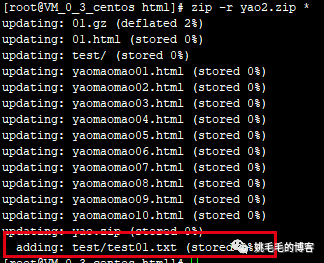
如同其他命令样,zip也有个-r参数,可以递归压缩
zip -r yao2.zip *
# ==>> adding: test/test01.txt (stored 0%)复制
当前目录下已经有压缩包,想打包本目录的时候不将上个压缩包打进去,排除掉,怎么打包?使用-x参数:
zip -r yao3.zip * -x yao2.zip复制

小结,zip几种打包方式,并有三个参数:
zip yao2.zip *
# 普通打包
zip -r yao3.zip *
# 递归打包
zip -r yao3.zip * -x yao2.zip
# 递归打包,排除某文件
zip -rq yao4.zip *
# 递归打包,不显示压缩信息
# 无参数,普通压缩
# -r :递归压缩
# -x :排除某个文件压缩
# -q :不显示压缩信息复制
2.4.3.2 unzip
unzip可以解压zip命令打包的或其他例如windows上的rar、360压缩等软件打包的zip格式文件。
不解压查看压缩文件:
unzip -l yao.zip
指定目录解压:
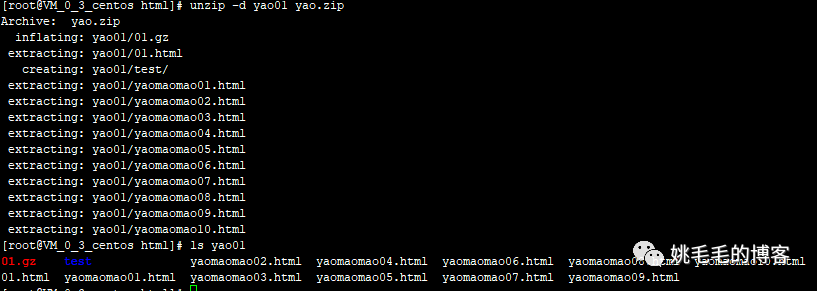
unzip -d yao01 yao.zip
# 解压到yao01文件夹下
# -d : 指定目录,无此目录则创建一个,解压的部分信息===>> creating: yao01/test/
# 没有-d参数则默认解压到当前文件夹
# -o : 解压时不提示是否覆盖文件;如果我们现在解压到当前目录就会提示是否覆盖,因为已经有此文件了,使用-o可以直接覆盖
# -v :展示解压时的详细信息复制
2.4.4 7za
7z也是一种高效率的压缩文件格式,7z常用命令如下。
压缩:
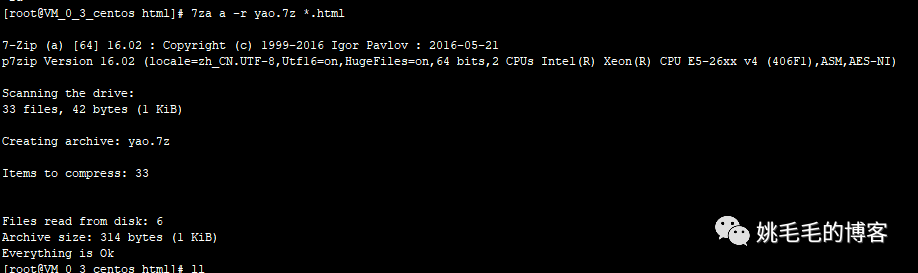
7za a -r yao.7z *.html
# 压缩所有html到yao.7z包中
# a :添加文件、目录
# -r :递归复制
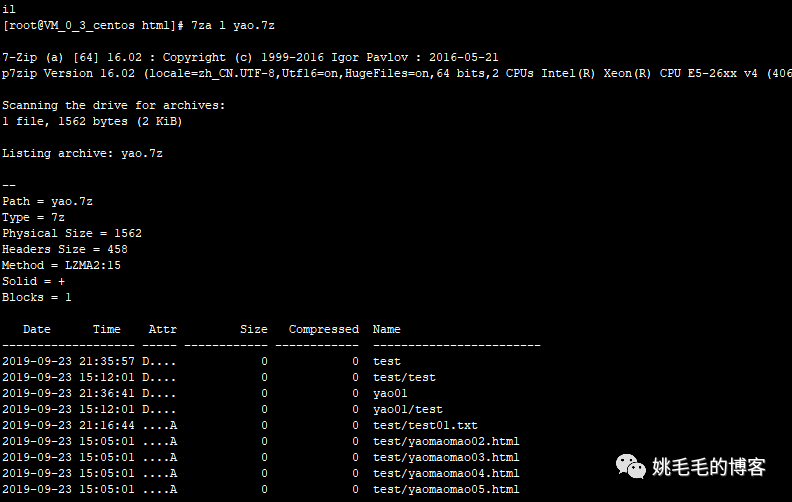
不解压查看文件内部信息:
7za l yao.7z
# l :不解压查看复制
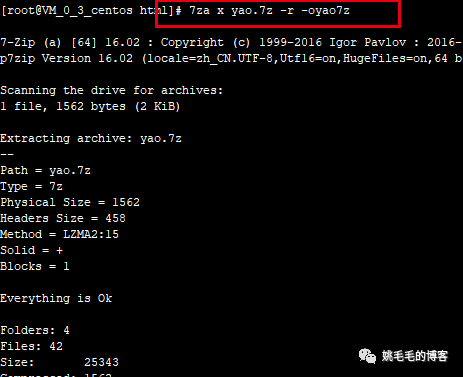
解压:
7za x yao.7z -r -oyao7z
# x : 解压,x换成e也可以解压;但是一般用x,x解压全路径,用e会将所有文件解压到一个目录中
# -r :递归解压子目录
# -o :指定解压目录,注意的是,-o参数与目录间没有空格,这是比较奇特的一点复制
2.5 用户、文件与权限
2.5.1 权限升级:su与sudo
提到用户与权限,则首先得说说一个不能避过的命令:su与sudo。
su与sudo的共同点是,都可以用另一个用户权限执行命令。
不同点是:su要切换成另一个用户,sudo不需要。
切换用户,su的常用命令:
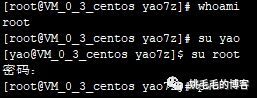
whoami
# 查看自己是哪个用户,我们这里可以看到是root登录的
su yao
# root用户切换为普通用户不需要输入密码
su root
# 普通用户切换回root用户需要输入密码
# 小知识: su root == su,su切换root不需要输入root用户名
# 注意:这种切换虽然可以成功,但是环境变量还是原用户的,所以要用下面的命令切换
su - yao
# su - [用户名],这种切换方式可以切换到相应用户,还能将登陆后的环境变量一并切换复制
其实su也可以不用切换过去就能执行命令,只需要加一个参数-c就行:
su - yao -c 'pwd'
# 使用yao执行pwd命令复制

可以看到,其实是执行成功了,正确返回了yao的home路径。
但是这种方式毕竟没有sudo来的方便,接下来看看不用切换用户的sudo:
su - yao
# 切换为普通用户登录
whoami
# 查看切换成功了没
ls /root
# 访问root文件夹复制
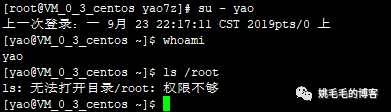
可以看到,没权限。怎么办?sudo呀。
sudo ls /root
# 访问root目录,输入yao用户的登录密码就行了复制

所有用户都可以使用sudo吗?当然不是了,我们可以查看下赋予sudo权限的用户:
sudo -l
# 查看当前用户被授权的sudo权限复制
怎么赋予sudo权限?
在/etc/sudoers文件中添加用户就行了
sudo cat /etc/sudoers复制
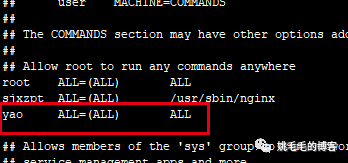
用vi还是sed都可以,但是最好使用visudo。
sudo visudo
# root用户不用sudo复制
visudo是专门来编辑/etc/sudoers文件的,它还有语法检查作用,赶快添加你的sudo用户吧。
2.5.2 用户增删改:useradd、usermod、userdel
2.5.2.1 用户新增:useradd、passwd
最常用,不带任何参数的添加用户:
useradd wfy
# 新增用户wfy
passwd wfy
# 设置密码,密码一般为大小写加数字和一个特殊字符复制
passwd 小技巧,一条命令设置用户密码:
echo "123456" | passwd --stdin wfy
# --stdin :可从标准输入获取密码
# 批量修改密码时,此命令比较有用
# 此外,还有个chpasswd命令也可以批量修改密码复制

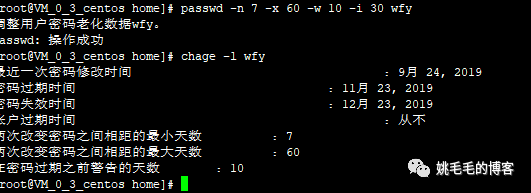
passwd 密码到期提醒策略:
passwd -n 7 -x 60 -w 10 -i 30 wfy
# 7天内不能修改密码,60天以后必须修改密码,过期前10天通知用户,过期后30天禁止用户登录
# -n : 7 表示不能修改密码天数
# -x :60 表示必须修改密码天数
# -w :10 表示过期前10天通知
# -i : 30 表示过期后30天禁止登录复制
useradd不带任何参数时,系统会先读取/etc/login.defs(用户定义)、/etc/deault/useradd(用户默认配置)文件,然后根据其中所设置的规则添加用户同时向/etc/passwd(密码文件)、/etc/group(用户组)文件添加新用户和新用户组记录。
建好了之后,可以到/home目录下看下,已经创建了属于此用户的家目录。
cd /home/wfy复制
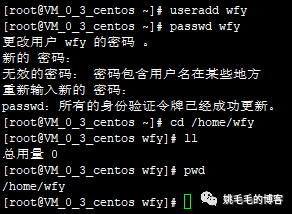
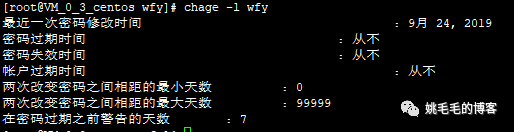
chage -l wfy
# 查看用户的有效期复制
查看用户所属信息:
id wfy
# 这个信息其实就在/etc/passwd中,可以用grep wfy /etc/passwd 查看比对下
# uid : 用户id
# gid :用户组id复制

后续说道group的时候再来看看gid的作用。
禁止登陆用户创建:
useradd -s /sbin/nologin ftp_ymm
# -s :指定用户登录的shell,/sbin/nologin表示禁止登陆,部署ftp等中间件会经常用到
useradd -M -s /sbin/nologin nginx_wfy
# 部署nginx、mysql等中间件会经常用到
# -M : 不创建家目录复制
其他参数:
useradd -u 806 -s /bin/sh -c "这是测试用户" -G root -e "2019/12/21" -f 2 -d /tmp/wfy test_wfy
# -u :指定uid
# -c :用户说明
# -G :设置用户组
# -e : 设置过期时间
# -f :2表示过期两天停权
# -d :用户每次登录时的家目录
tail -1 /etc/passwd
# 查看passwd文件最后一行,可以看到刚才添加的用户信息
tail -1 /etc/shadow
# 查看/etc/shadow文件最后一行,可以看到刚才-f添加的参数2复制

拓展:使用useradd -D 参数就是修改用户的初始配置文件:/etc/deault/useradd,来看下这个文件有什么。
[root@VM_0_3_centos wfy]# cat /etc/default/useradd
# useradd defaults file
GROUP=100
# 依赖于/etc/login.defs的USERGROUPS_ENAB参数,如果为no,则此处控制
HOME=/home
# 把用户的家目录建在/home中
INACTIVE=-1
# 是否启用用户国企停权,-1表示不启用
EXPIRE=
# 用户终止日期,不设置表示不启用
SHELL=/bin/bash
# 新用户默认所用的shell类型
SKEL=/etc/skel
# 家目录默认文件存放路径,新增用户时,从这个配置目录拷贝过去
CREATE_MAIL_SPOOL=yes
# 创建mail文件复制
用useradd -D来修改下看看,当然,先做好备份:
cp /etc/default/useradd{,.bak}
# 做个备份
cd /etc/default
# 可以看到创建useradd.bak文件
useradd -D -s /bin/sh
# -D :改变/etc/default/useradd文件
# -s :改变默认shell
# -b : 定义家目录
# -e :设置用户过期日期
# -f :过期后几日停权
# -g :设置用户组
diff /etc/default/useradd{,.bak}复制
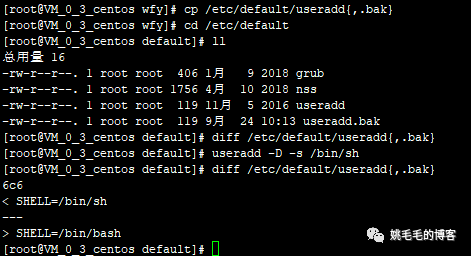
可以看到前后对比的效果复制
2.5.2.2 用户修改:usermod
usermod的参数大部分与useradd相同,无非一个新增一个修改而已。不同的参数如下:
usermod -l wfy2 wfy
# 将wfy这个用户的登录名改为wfy2
# -l :修改用户名称
# -L :lock,锁定用户密码
# -U :unlock,解除密码锁定
# -a :追加用户组,与-G参数连用复制
将useradd替换为usermod,其他参数不变,来修改下用户信息
usermod -u 806 -s /bin/sh -c "修改了测试用户" -G root -e "2019/12/21" -f 2 -d /tmp/wfy test_wfy
grep test_wfy /etc/passwd
grep test_wfy /etc/shadow复制

2.5.2.3 用户删除:userdel
userdel -r test_wfy
# -r : 删除用户及家目录
# -f : 强制删除用户,即使用户登录了
# 不加-r参数删除不会删除家目录复制
注意:实际工作中,一般不使用userdel,而是去/etc/passwd中将用户信息注释。
2.5.3 用户查看:id、w、who、whoami、last
id,查看用户id信息:
id wfy
# 显示wfy的uid及gid信息复制

w,最常用,查看已登录用户信息:
w
# 展示所有已登录用户信息
# 展示字段含义如下
# USER : 用户
# TTY : 用户tty名称
# FROM : 从哪登录的
# LOGIN : 登录时间
# IDLE :终端空闲时间
# JCPU :终端上所有进程及子进程使用系统的总时间
# PCPU :活动进程使用的系统时间
# WHAT :当前用户执行的进程复制
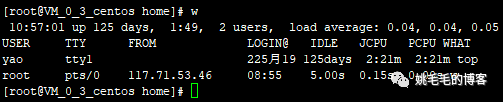
who 查看所有已登录用户信息:
who
# 显示已登录用户信息,与w略有不同复制
users 查看所有已登录用户名:
users
# 只显示用户复制
whoami 查看当前登录用户信息:
whoami
# 查看当前登录的用户名复制
last:
last
# 显示用户登录列表,读取/var/log/wtmp
last -10
# 显示最近10次的登录信息
last root -10
# 显示root用户的最近10次登录信息
lastb
# 展示用户登录失败信息,读取/var/log/btmp
lastb -10
# 展示最近10条用户登录失败信息
lastb root -10
# 展示root用户登录失败信息,最近10条
lastlog
# 展示所有用户最近一次登录记录,读取/var/log/lastlog复制
2.5.4 文件权限:chown 、chmod
2.5.4.1 改变文件用户组:chown
chown常用命令如下:
cd ~
# 返回root家目录
chown wfy wfy.txt
# 更改wfy.txt的所属用户为wfy复制
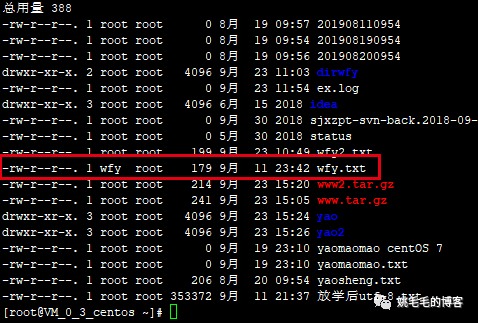
chown wfy:wfy wfy2.txt
# 将wfy2.txt的所属用户更改为wfy,用户组从root更改为wfy复制
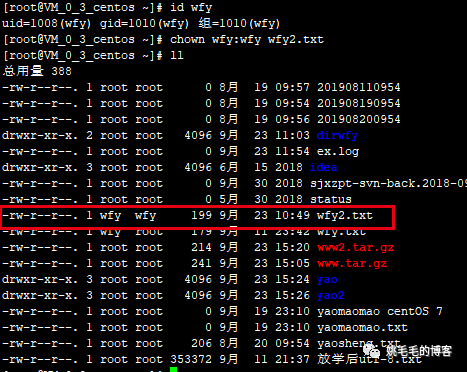
chown -R wfy:wfy yao
# 将yao这个目录及其子目录全都赋权给wfy
# 可以看到yao下的var目录页赋权给了wfy这个用户及用户组复制
2.5.4.2 改变文件权限范围:chmod
chmod可以改变文件及目录的权限范围,它有两种赋权模式:1)使用权限字母 + 操作符;2)使用数字。
常用命令示例:
chmod 777 wfy.txt
# 更改wfy.txt权限为所有人可访问复制
修改前: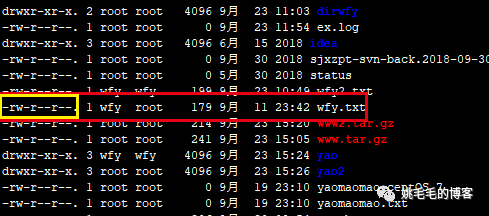
修改后: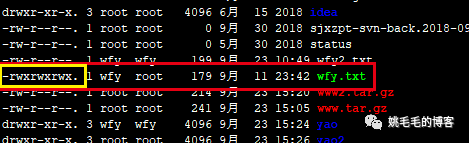
7代表rwx,777所代表的9位字符权限为rwxrwxrwx。
"r" = 4, 可读权限;目录、子目录及其文件都可被访问。
"w" = 2,可写权限;可修改文件内容、目录名称。
"x" = 1,可执行权限;目录没有x权限无法进入,sh脚本文件没有x无法执行。
"-" = 0,无权限。
赋予目录只读权限:
chmod -R 555 yao
# 5 = 4 + 0 +1,即r-x,可读与可执行权限,但是不能被修改。执行下看看效果,是否与预期一样。复制
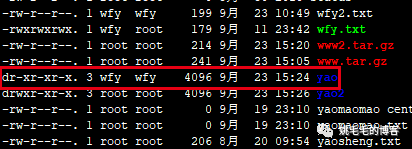
可以看到第一位字符是d,d代表目录,后续9位字符为r-x(属主权限位)、r-x(属组权限位)、r-x(其他用户权限位)。
此外还有一种常用的赋权模式,为+x,赋予文件可执行权限,一般用来执行shell脚本:
chmod +x [脚本名].sh复制
shell脚本一般有四种执行方式,最常用的为+x赋权后使用下面命令执行:
./脚本名.sh复制
其他三种方式:
. /脚本名.sh
# .后有空格
source 脚本名.sh
sh 脚本名.sh复制
当然,也可以用来执行txt文件,示例如下:
. wfy.txt
source
sh wfy.txt复制
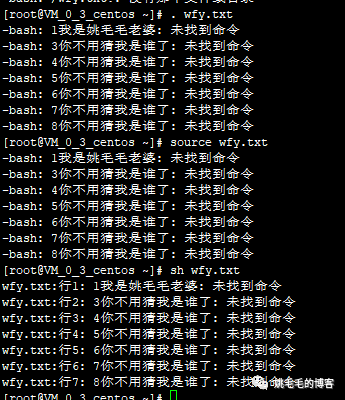
可以看到我们的wfy.txt文件并不是一个shell文件,没有找到响应的命令去执行,后续的shell入门会说下.sh的脚本文件是怎样编写的。
注意:普通用户还需有r权限才能执行,root则不需要。
2.6 资源监控与管理
2.6.1 虚拟文件管理系统:proc
说到资源管理这块,/proc文件夹是linux上不得不说的一个目录。

ls /proc复制

可以看到红框/proc目录下红框圈的那一片数字文件夹,这其实就是我们linux系统中所有进程文件存放的地方。每生成一个进程,就会在这里有个对应的文件夹,也就是我们以后会经常打交道的pid。
有很多的inux命令都是调用此目录中的文件来显示系统相关信息。例如内存、cpu等信息。
为什么proc下面的文件能存放内存、进程、cpu这些跟磁盘文件没任何关系的东西呢?
因为proc实际是一个伪文件系统,或者说虚拟文件系统。我们在文章开头就说了,linux中的一切都是以文件形式存在的,就是proc做到的。
对于用户、应用程序,它们是从proc中得到系统的一些信息,甚至可以改变内核的某些参数。
而proc中的文件内容并不是全然不变的,它们会随着系统进程的变化而变化,当用户读取它们时,proc文件系统就动态地从系统内核中读出所需要的信息并提交。
一些我们常用的命令会用到下面的一些文件,如磁盘、cpu、内存相关的。
| --------------- | ------------- |
|---|---|
| /proc/cmdline | 内核命令行,核心启动参数 |
| /proc/cpuinfo | cpu的相关信息 |
| /proc/devices | 挂载设备 |
| /proc/Loadavg | 负载均衡 |
| /proc/meminfo | 内存信息 |
| /proc/mounts | 加载文件系统 |
| /proc/stat | 全面统计状态表 |
| /proc/swaps | 交换空间表 |
| /proc/version | 内核版本 |
| /proc/uptime | 系统正常运行时间 |
关于/proc目录的详解可以参考这篇文章https://www.cnblogs.com/aofo/p/6151266.html
关于proc也不用深究,知道这么个东西就行了。
接下来看看关于磁盘、网络、cpu、内存的一些基本命令。
2.6.2 磁盘空间监视器:df
df命令可以说linux上最常用的命令之一,因为一旦磁盘空间不够就会出现各种故障,数据库、应用都可能会处于瘫痪状态。
常用命令示例:
[root@VM_0_3_centos ~]# df -h
# 以适合人类阅读的方式展示磁盘空间大小
文件系统 容量 已用 可用 已用% 挂载点
/dev/vda1 50G 43G 4.3G 91% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 10G 666M 9.4G 7% /dev/shm
tmpfs 1.9G 324K 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 380M 0 380M 0% /run/user/1005
tmpfs 380M 0 380M 0% /run/user/0
[root@VM_0_3_centos ~]# df -i
# -i : 显示inode的使用情况
# linux文件有个inode的文件数量限制,一旦无可用inode,则无法再产生新的文件,会在磁盘空间未满的情况下报“No space left on device”,解决方案是删除无用(多天前)的小文件或者log文件
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/vda1 3276800 215486 3061314 7% /
devtmpfs 482932 308 482624 1% /dev
tmpfs 485254 258 484996 1% /dev/shm
tmpfs 485254 354 484900 1% /run
tmpfs 485254 16 485238 1% /sys/fs/cgroup
tmpfs 485254 1 485253 1% /run/user/1005
tmpfs 485254 1 485253 1% /run/user/0
[root@VM_0_3_centos ~]# df -Th
# -T:查看文件系统类型
# 本机展示的挂载盘/dev/vda1文件系统类型为ext3
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/vda1 ext3 50G 43G 4.3G 91% /
devtmpfs devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs tmpfs 10G 666M 9.4G 7% /dev/shm
tmpfs tmpfs 1.9G 324K 1.9G 1% /run
tmpfs tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs tmpfs 380M 0 380M 0% /run/user/1005
tmpfs tmpfs 380M 0 380M 0% /run/user/0复制
2.6.2 内存空间监视器:free
一台电脑、服务器,内存、存储(磁盘)、处理器(cpu)、操作系统是最基本的组成。
free就是用来监视linux系统使用内存的命令。
常用命令示例:
[root@VM_0_3_centos ~]# free -h
# 以人类可读方式展示内存使用情况,根据实际大小自动转换为KB、MB、GB
total used free shared buff/cache available
Mem: 3.7G 275M 144M 48M 3.3G 3.1G
Swap: 2.0G 658M 1.4G复制
Mem为物理内存使用情况,Swap为虚拟内存使用情况(一般是划分一部分磁盘空间作为虚拟内存)。
total :总内存;3.7G一般为4G内存机器。
used :已使用内存。
free :自由内存。
shared :共享内存。
buff/cache : 缓存,3.3G。
available :可用内存。
在以前没有available这个展示字段的时候,我们通常是将 free + buff/cache 的总量作为可用内存。
linux系统的特性就是将不用的物理内存缓存起来,因为千万以为free的144M内存就是真实的系统剩余内存了。所以当前可用内存为available:3.1G。
常用命令之二:定时查询内存
free -hs 5
# 每5秒显示内存使用情况,ctrl + c 终端
# -s:根据指定间隔显示内存使用情况,单位为秒
[root@localhost ca_ga]# free -hs 5
total used free shared buff/cache available
Mem: 62G 27G 359M 65M 34G 34G
Swap: 31G 6.7G 25G
total used free shared buff/cache available
Mem: 62G 27G 348M 65M 34G 34G
Swap: 31G 6.7G 25G
total used free shared buff/cache available
Mem: 62G 27G 354M 65M 34G 34G
Swap: 31G 6.7G 25G
^C复制
2.6.3 网络探测器:ping
ping命令与windows下用cmd打出的ping命令相似,都是用来探测主机之间网络是否通畅。
常用命令示例:
ping www.baidu.com
# ping域名或ip,会一直显示ping结果,ctrl + c 中断
# 不同于windows的是,windos上ping -t才会一直显示ping结果
[root@VM_0_3_centos ~]# ping www.baidu.com
PING www.a.shifen.com (14.215.177.39) 56(84) bytes of data.
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=54 time=3.97 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=54 time=4.01 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=3 ttl=54 time=3.97 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=4 ttl=54 time=4.03 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=5 ttl=54 time=3.97 ms
^C
--- www.a.shifen.com ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4004ms
rtt min/avg/max/mdev = 3.971/3.993/4.031/0.024 ms复制
从结果行第一行可以看到,baidu的域名被转换成了www.a.shifen.com,发送了56字节的数据。
而从第二行开始,是目标返回信息。目标受到的字节是64,icmp_seq就是受到包的序列号,ttl是数据包的生存周期,time是延时,3.97毫秒。
最后三行是统计结果信息,发送了5个包,接收了5个包,一个包没有丢失,总共用时4004毫秒。min/avg/max/mdev 为最小/平均/最大/平均偏差(Mean Deviation) 延时。
ttl为time to life,即icmp包在网络上的存活时间。
常用ping命令示例:
ping -c 3 -i 3 -s 1024 -t 255 www.csdn.com
# -c :固定ping次数,本次为3次
# -i :发送间隔,本次为3秒
# -s :数据包大小,单位字节,本次1024为1KB
# -t :255,ttl值
[root@VM_0_3_centos ~]# ping -c 3 -i 3 -s 1024 -t 255 www.csdn.com
PING www.csdn.com (47.95.164.112) 1024(1052) bytes of data.
1032 bytes from 47.95.164.112 (47.95.164.112): icmp_seq=1 ttl=250 time=38.4 ms
1032 bytes from 47.95.164.112 (47.95.164.112): icmp_seq=2 ttl=250 time=38.3 ms
1032 bytes from 47.95.164.112 (47.95.164.112): icmp_seq=3 ttl=250 time=38.4 ms
--- www.csdn.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 6006ms
rtt min/avg/max/mdev = 38.334/38.402/38.447/0.167 ms复制
ping失败案例:
ping -c 3 -i 3 -s 1024 -t 255 www.yaojiaxiaoyuan.com
PING www.yaojiaxiaoyuan.com.qiniudns.com (1.1.1.1) 1024(1052) bytes of data.
--- www.yaojiaxiaoyuan.com.qiniudns.com ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 5999ms复制
可以看到,因为我的网站www.yaojiaxiaoyuan.com备案过期了,所以探测的时候发送3个包都丢失了,丢失率100%。
ping只能探测ip及域名,但是没法探测端口,下期的进阶命令会说道telnet,可以远程探测端口。
2.6.4 cpu、进程及内存监视器:top
top命令可以用于实时监控cpu的状态,显示系统中各个进程的资源占用情况。
常用命令示例:
top
# 对,无参数的top命令是最长用的资源监控命令。
# 再往下会说些常用的交互命令。
[root@VM_0_3_centos ~]# top
top - 23:03:23 up 127 days, 13:56, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 79 total, 1 running, 78 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.7 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3882032 total, 145996 free, 283752 used, 3452284 buff/cache
KiB Swap: 2097148 total, 1422392 free, 674756 used. 3218052 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
964 redis 20 0 142960 7244 988 S 0.3 0.2 168:01.87 redis-server
15515 root 20 0 260068 123108 3988 S 0.3 3.2 20:12.97 YDService
30378 root 20 0 155536 2132 1540 R 0.3 0.1 0:00.06 top
…………
# 后面还有很多,省略了复制
因为域名已经被注销了,目前没法截图,所以只能复制文字出来了。
结果第一行,为uptime命令的执行结果。后面进阶命令会说道,大家感兴趣可以自行执行下。
23:03:23 # 当前系统时间
up 127 days, 13:56 # 系统已运行127天13小时56分复制
2 users # 两个用户在登录 load average: 0.00, 0.01, 0.05 # 最近1分钟、5分钟、15分钟的负载情况
第二行,进程信息。共79个进程,1个运行,78个睡眠,停止的0个,僵死的0个。
第三行,cpu状态信息。
0.2 us # 用户空间占比
0.0 sy # 内核空间占比
0.0 ni # 改变过优先级的进程占用比
99.7 id # 空闲CPU百分比
0.2 wa # I/O等待占用cpu百分比
0.0 hi # 硬中断占用cpu百分比
0.0 si # 软中断占用cpu百分比
0.0 st # 虚拟机占用比复制
第四行、第五行,分别是物理内存状态及虚拟内存状态。
total # 内存总量
free # 空闲内存
used # 已用内存
buff/cache # 缓存复制
第六行为空行,第七行以后就是系统中各进程的监控状态。
PID # 进程id
USER # 用户,进程所有者
PR # 优先级
NI # nice值,负值高优先
VIRT # 进程使用的虚拟内存总量,KB
RES # 所用物理内存大小,KB
SHR # 共享内存大小
S # 进程状态。S=睡眠sleep,R=运行running,D=不可终端的休眠状态,T=stopped,Z=zombie僵尸进程
%CPU # 占用CPU百分比
%MEM # 占用物理内存百分比
TIME+ # 进程使用CPU时间统计
COMMAND # 进程名复制
其他常用命令示例:
top -c
# 第七行后进程信息显示进程全路径
top -n 2
# -n :指定更新次数两次不再刷新,无参数会一直刷新复制
top的交互模式:
按1可以显示多核CPU的信息。
按b可以高亮选中某列,再使用符号"<"或“>”来向左或向右降序排序。
关于资源监控还有许多很实用的工具:如iostat、mpstat、iftop、vmstat、iotop、sar等工具,有兴趣可以自行研究,或者等下一篇linux进阶命令出来再看一看。
三、结束语
这篇文断断续续写了一个多月,终于在今天完结了,下一篇是linux核心命令进阶及shell入门。
本来在大纲里已经把shell入门放进这篇来了,但是想想,还是放到下篇吧。就这样吧,linux的命令实在太多了,但是常用的其实本篇大部分都囊括了。
可能还有些一些涉及文件上传、下载、安装的常用命令如curl、wget、yum、rpm、ssh、scp等等,还有系统管理、网络管理等等命令都放在下篇了。
最后,感谢老婆给了我这么大动力。感谢。
撒花,结束,退场。
喜欢就点个在看 or 转发朋友圈,这将是我最强的写作动力。
关注了我,你的生命中又多了个有趣的灵魂。
姚毛毛&妖生
一个只做原创的程序员

微信扫码关注他
