





不管你认不认同,当今数据架构的三大发展趋势是:结构化数据仓库(Data Warehouse)转非结构化数据湖(Data Lake);传统跑批处理(Batch Processing)转为实时流式数据处理(Streaming);本地化存储转为公有云存储。
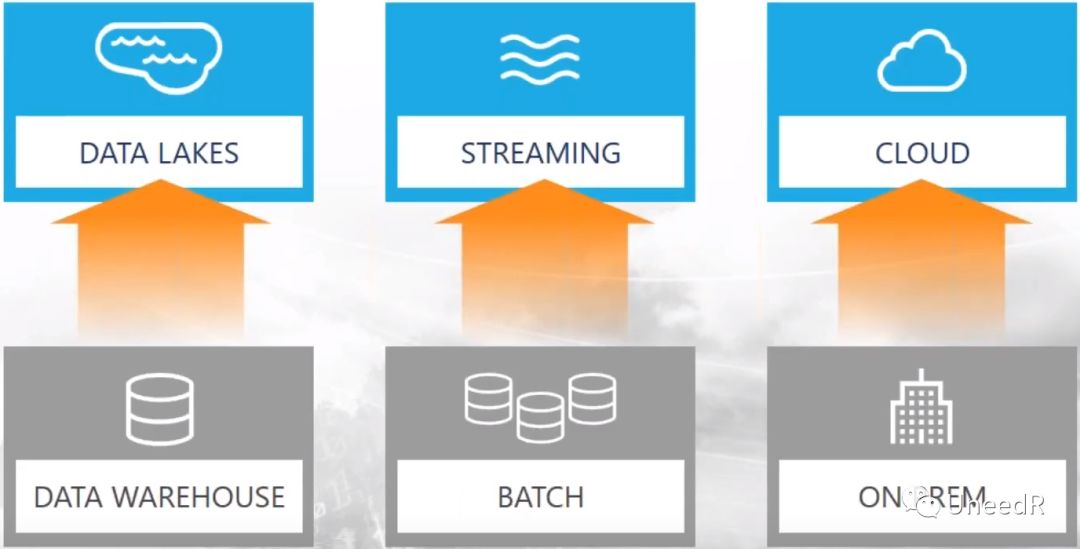
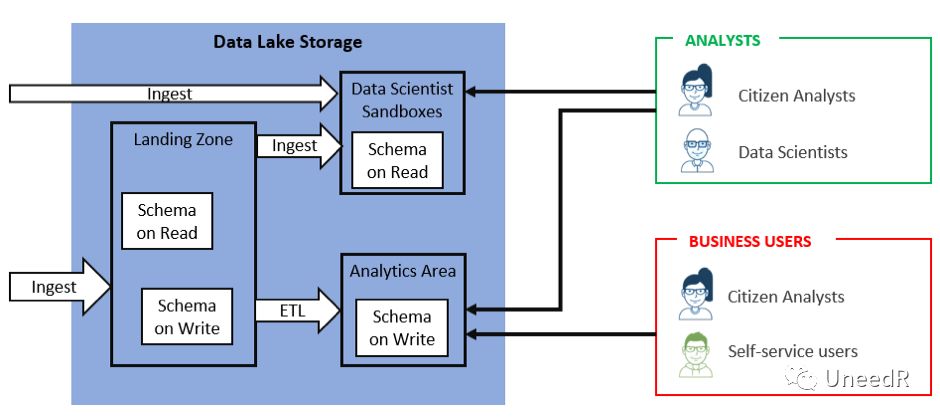
微软早在2016年11月开始了在Azure公有云上部署数据湖的战略,一举包含了上述三大趋势中的两项。数据湖的设计理念就跟传统的数据仓库不在一个层面上:随着数据大爆炸的时代来临,数据分析的时效性要求更高,吞吐量要求更大,分析工具的发展要求更快。然而对于数据持久化,根本等不上这些要素的齐备,因此就催生了“各式各样的数据先落地,后考虑对业务分析的帮助”这种真正以数据为主体的数据存储模型。技术上说在数据存储的时候,数据湖并不知道数据的个Schema是什么,只有当被确认调用的时候才会定义Schema。
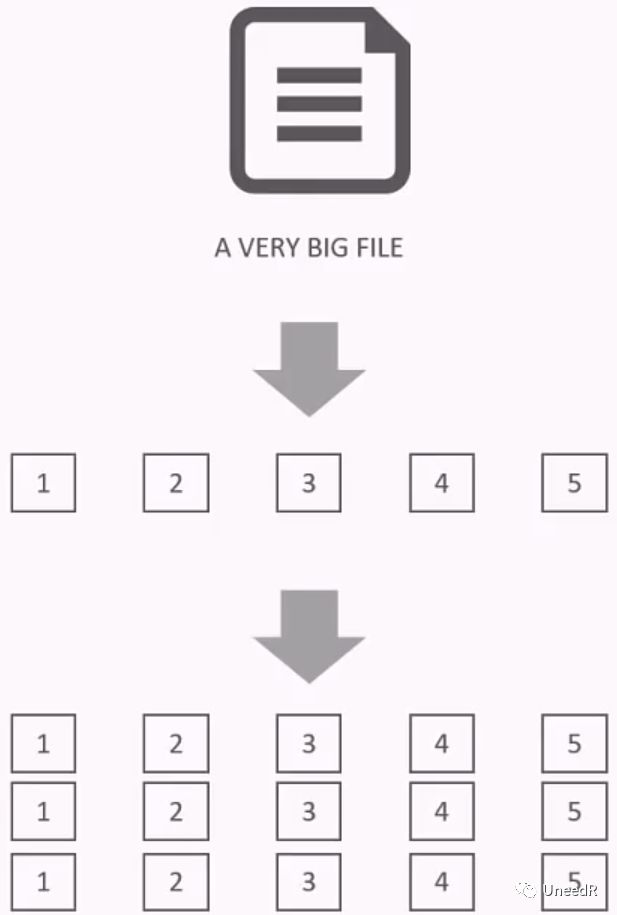
由于对源数据没有结构化的要求,因此数据湖一般采用Hadoop作为存储平台,它的特点就是可以将大文件分块(基于块的存储),每个数据块默认情况下有三个副本,并且支持并行读写。
公有云上的Hadoop由于物理存储都是分布式的,因此高可用级别无疑又进了一步。同时Azure上的Hadoop可以直接当作IaaS(或叫Big Data as a Service)调用,用户只需关注如何建询查询来获得想要的数据,Azure数据湖会自动调配计算资源完成数据展现。
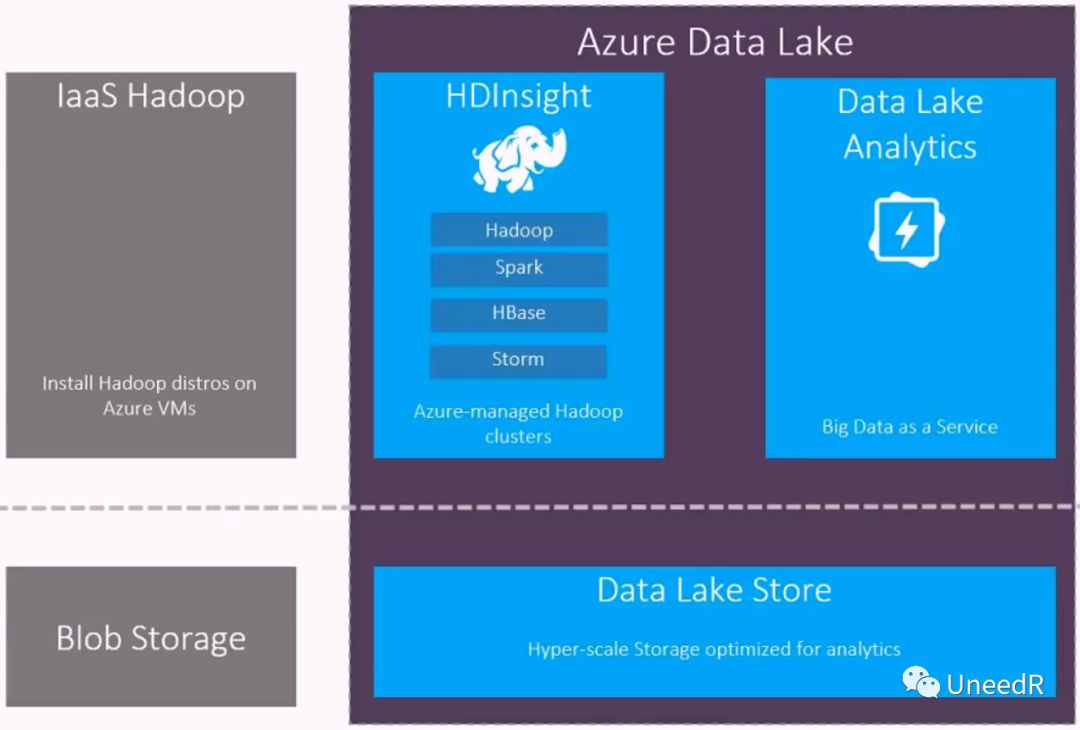
既然说到了计算资源,Azure数据湖的计算资源是以ADLAU(Azure Data Lake Analytics Unit,分析单元)为单位的,可以把一个ADLAU理解为一个YARN的容器,大致相当于2核的虚拟CPU和6GB的内存。当有一个查询任务提交到IaaS(或叫Big Data as a Service)的REST API接口时会被拆分为细小的子任务(Vertex),对于每个子任务Scheduler进程会为其分配YARN容器,如果YARN容器不够了,Scheduler会将子任务排队处理,最后由Manager监管每一个子任务的运行情况。
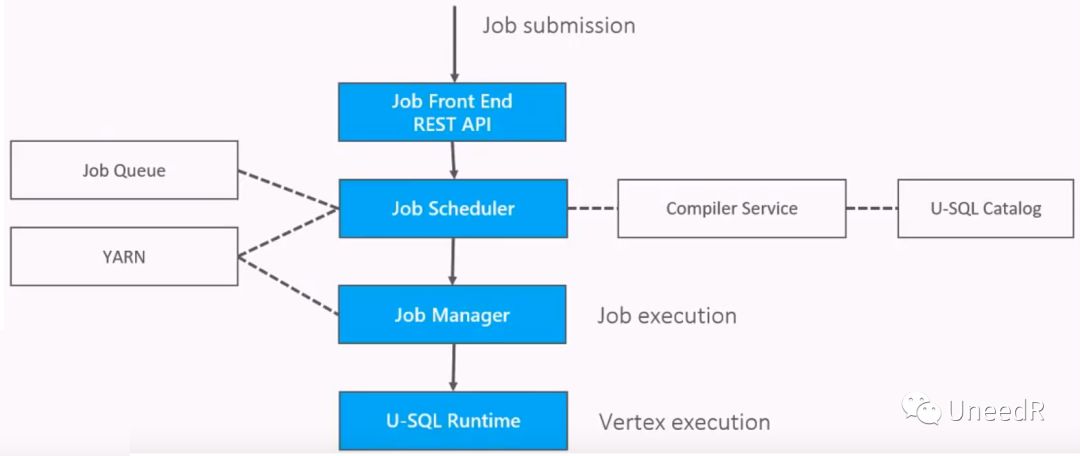
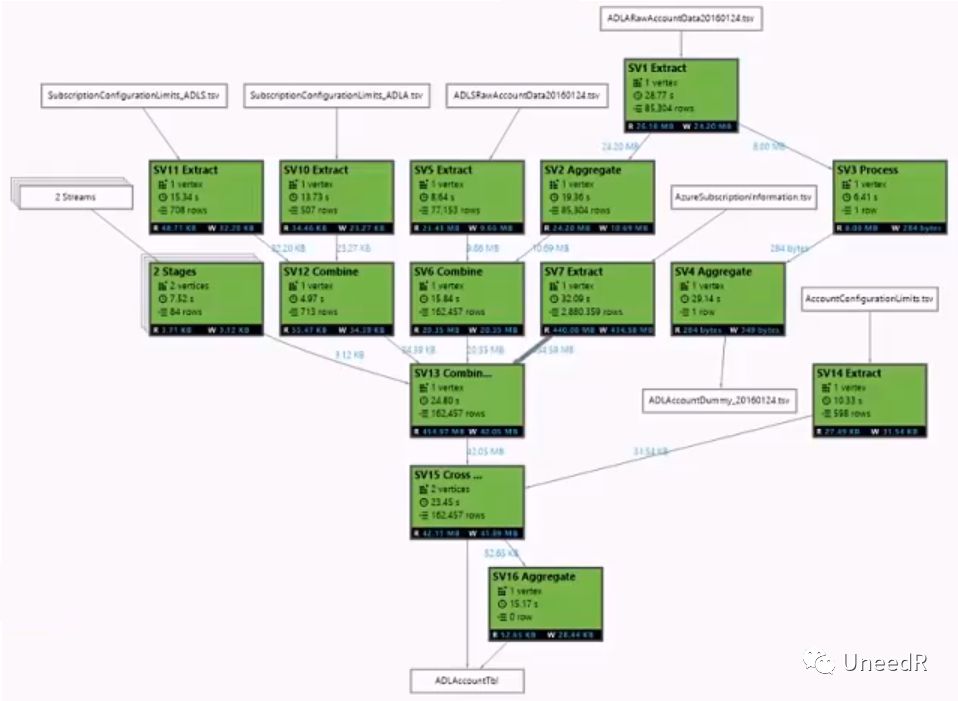
举个例子,一个津树BDaaS的任务被Scheduler拆分成了15个Vertex,并定义了运行顺序,每个Vertex分配有不同的ADLAU,可以多线程运行,这种调度机制最大程度地优化了一个查询任务。


长按,识别二维码,加关注
