




「目录」
6.1 => Pandas的数据结构
-------->Series
-------->DataFrame
6.2 => 数据分析和处理
6.3 => 数学和统计方法

pandas是什么?具体的可以自己上网查资料,这里简单说一下吧。
pandas是基于Numpy为解决数据分析任务而创建的。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。 pandas含有使数据清洗(data clean)和分析⼯作变得更快更简单的数据结构和操作⼯具。
pandas会经常和其它⼯具⼀同使⽤,如数值计算⼯具NumPy和SciPy,分析库 Statsmodels和Scikit-learn,和数据可视化库Matplotlib。
你很快就会发现它有多强大和好用!
Pandas和Numpy的不同:Pandas是专门为处理表格和混杂数据设计的,NumPy更适合处理统⼀的数值数组数据。
一般以下面的方式导入pandas:
In [1]: import pandas as pd
Pandas的数据结构
Pandas的两个主要的数据结构:序列Series和数据框架DataFrame
Series
Series是类似于⼀维数组的对象,它由⼀组数据和数据的的标签(即索引)组成。
In [2]: obj = pd.Series([4, 7, -5, 3])
In [3]: obj
Out[3]:
0 4
1 7
2 -5
3 3
dtype: int64
Series中,索引Index在左边,值Value在右边。
若没有为数据指定索引,会自动创建一个整数索引。
我们可以通过Series的values属性获取数组的值:
In [4]: obj.values
Out[4]: array([ 4, 7, -5, 3], dtype=int64)
还可以通过Series的index属性获取数组的索引:
In [5]: obj.index
Out[5]: RangeIndex(start=0, stop=4, step=1)
我们当然可以自定义自己创建的Series的索引:
In [6]: obj2 = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
In [7]: obj2
Out[7]:
a 1
b 2
c 3
d 4
dtype: int64
通过索引的方式选取Series中单个值或一组值:
In [8]: obj2['a']
Out[8]: 1
In [9]: obj2[['c', 'a', 'd']]
Out[9]:
c 3
a 1
d 4
dtype: int64
或用布尔型数组过滤:
In [10]: obj2[obj2>2]
Out[10]:
c 3
d 4
dtype: int64
还有别的类似于对Numpy数组的操作,比如对整个Series值乘以2:
In [11]: obj2 * 2
Out[11]:
a 2
b 4
c 6
d 8
dtype: int64
当有一组数据放在字典里时,我们可以直接通过字典来创建Series。
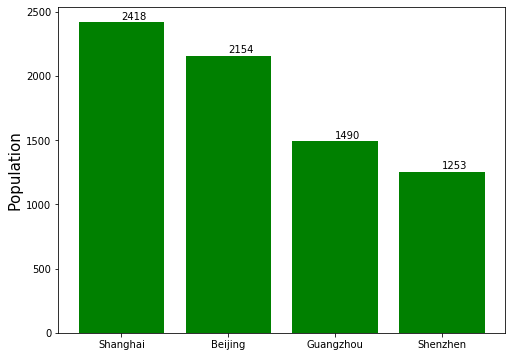
比如我们有四个一线城市及其人口(单位万)的数据{'Shanghai':2418, 'Beijing':2154, 'Guangzhou':1490, 'Shenzhen':1253}
In [15]: sdata = {'Shanghai':2418, 'Beijing':2154, 'Guangzhou':1490, 'Shenzhen':1253}
In [16]: obj3 = pd.Series(sdata, index=sdata)
In [17]: obj3
Out[17]:
Shanghai 2418
Beijing 2154
Guangzhou 1490
Shenzhen 1253
dtype: int64
也可以自己传入索引来改变顺序
In [18]: states =['Shenzhen', 'Guangzhou', 'Beijing', 'Shanghai']
In [19]: obj3 = pd.Series(sdata, index=states)
In [20]: obj3
Out[20]:
Shenzhen 1253
Guangzhou 1490
Beijing 2154
Shanghai 2418
dtype: int64
如果传入了没有的键,由于在sdata中找不到对应的值,所以结果为NaN(not a number)
In [21]: states =['Shenzhen', 'Guangzhou', 'Beijing', 'Shanghai', 'Chengdu']
In [22]: obj4 = pd.Series(sdata, index=states)
In [23]: obj4
Out[23]:
Shenzhen 1253.0
Guangzhou 1490.0
Beijing 2154.0
Shanghai 2418.0
Chengdu NaN
dtype: float64
Pandas的isnull和notnull可以检测缺失数据:
In [24]: pd.isnull(obj4)
Out[24]:
Shenzhen False
Guangzhou False
Beijing False
Shanghai False
Chengdu True
dtype: bool
In [25]: pd.notnull(obj4)
Out[25]:
Shenzhen True
Guangzhou True
Beijing True
Shanghai True
Chengdu False
dtype: bool
或者使用Series的实例方法:
In [26]: obj.isnull()
Out[26]:
0 False
1 False
2 False
3 False
dtype: bool
DataFrame
DataFrame是⼀个表格型的数据结构,它含有⼀组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共⽤同⼀个索引)。
最常用的建立DataFrame的方式是传入一个等长的列表或Numpy数组:
In [2]: data = {'state':['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],^M
...: 'year':[2000, 2001, 2002, 2001, 2002, 2003],^M
...: 'pop':[1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
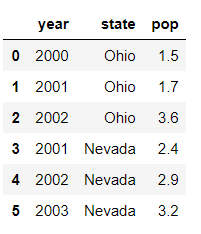
In [3]: frame = pd.DataFrame(data)
In [4]: frame
Out[4]:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
5 Nevada 2003 3.2
❝如果使用Jupyter Notebook,Pandas DataFrame对象会以对浏览器有好的HTML表格的方式呈现
❞
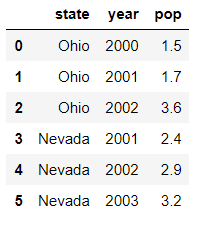
使用head方法可以显示前5行:
In [5]: frame.head()
Out[5]:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
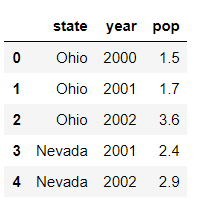
我们也可以指定列的排列顺序:
In [6]: pd.DataFrame(data, columns=['year', 'state', 'pop'])
Out[6]:
year state pop
0 2000 Ohio 1.5
1 2001 Ohio 1.7
2 2002 Ohio 3.6
3 2001 Nevada 2.4
4 2002 Nevada 2.9
5 2003 Nevada 3.2
如果要获取某一列可以像下面这么做:
In [7]: frame['state']
Out[7]:
0 Ohio
1 Ohio
2 Ohio
3 Nevada
4 Nevada
5 Nevada
Name: state, dtype: object
获取某一行的话可以用loc属性:
In [8]: frame.loc[2]
Out[8]:
state Ohio
year 2002
pop 3.6
Name: 2, dtype: object
如果想给这个DataFrame加一个新列,比如美国各个州的GDP:
In [11]: frame['GDP'] = np.arange(1,7)
In [12]: frame
Out[12]:
state year pop GDP
0 Ohio 2000 1.5 1
1 Ohio 2001 1.7 2
2 Ohio 2002 3.6 3
3 Nevada 2001 2.4 4
4 Nevada 2002 2.9 5
5 Nevada 2003 3.2 6
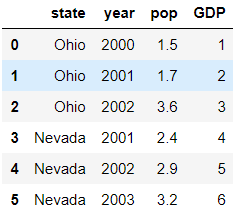
不想要了?可以使用del删除:
In [13]: del frame['GDP']
In [14]: frame
Out[14]:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
5 Nevada 2003 3.2
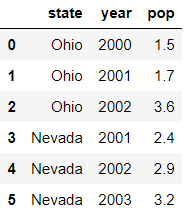
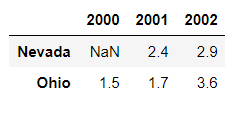
如果创建DataFrame时传入的是嵌套字典,则外层字典的键作为列索引,内层键则作为行索引:
In [15]: pop = {'Nevada':{2001:2.4, 2002:2.9}, 'Ohio':{2000:1.5, 2001:1.7, 2002:3.6}}
In [16]: frame2 = pd.DataFrame(pop)
In [17]: frame2
Out[17]:
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
❝因为键'Nevada'的字典中找不到2000这个键,所以这个位置就是NaN
❞
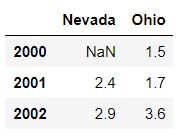
使用.T方法,可以调换DataFrame行索引和列索引的位置(就像Numpy数组的转置):
In [18]: frame2.T
Out[18]:
2000 2001 2002
Nevada NaN 2.4 2.9
Ohio 1.5 1.7 3.6
你可能想要在行索引(2000,2001,2002)上面写上年份year,可以设置DataFrame的index的name属性来实现:
In [19]: frame2.index.name = 'Year'
In [20]: frame2
Out[20]:
Nevada Ohio
Year
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
列索引('Nevada','Ohio')旁也可以设置columns的name属性:
In [21]: frame2.columns.name = 'State'
In [22]: frame2
Out[22]:
State Nevada Ohio
Year
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
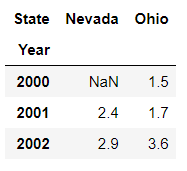
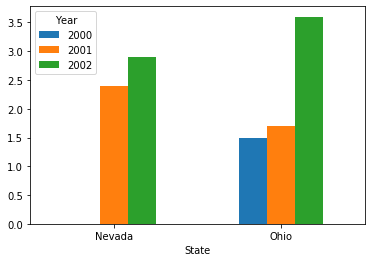
剧透一下(以后具体讲),一个很方便的可视化DataFrame的方法:
df.T.plot.bar(rot=0)
❝Note: rot(rotation)可以更改下面标签的倾斜度
❞
values属性会以二维数组ndarray的形式返回DataFrame中的数据:
In [23]: frame2.values
Out[23]:
array([[nan, 1.5],
[2.4, 1.7],
[2.9, 3.6]])
往期回顾



Stay hungry, stay foolish
快来,点在看啦

