




1. ES 基础知识
ElasticSearch 是基于 Lucene构建的分布式搜索与分析引擎,实时搜索、稳定可靠、安装使用方便。
1.1 索引、type、document
先看一张 MySQL 和 ElasticSearch 的概念对比图:
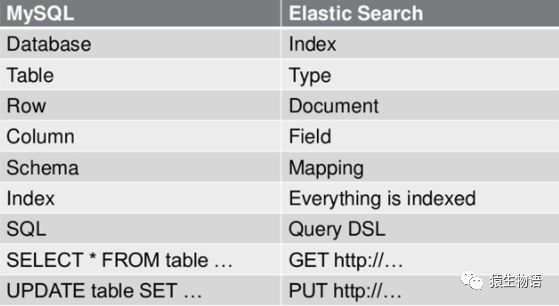
Index: 索引,可以理解为 MySQL 中的数据库。不同的是在 ES 7.0 之后,一个 Index 中只有一张表(一个 type)
Type: 对索引中 document 的分组。在 ES 6.x 中只允许每个 Index 中包含一个 Type。在 7.x 版本中将彻底移除 Type
Document: 即数据
1.2 分片、节点、集群
分片-Shard
同一个 Index 会分成多个 shard 存到不同的节点(服务器)去。每个 shard 有自己的一个或多个备份(replica shard)。前者叫 primary shard,负责处理写入数据,之后再同步到它的 replica shard。
为什么要对索引分片呢?
一是可以支持横向扩展,把不同的 shard 放到不同的节点上,就可以实现单索引容量的扩展。
二是提高了并行访问速度。
注:这里的 primary shard 和 replica shard 的概念与 Redis 中的主从有一些相似。虽然是不同的技术,但是在底层的一些设计思想上总是有一些相似之处。
节点-Node
服务器,分为 master 节点和其他节点;master 节点负责管理工作,比如维护索引元数据、负责切换 primary shard 和 replica shard 等。primary shard 所在节点宕机后,由 master 节点负责其选举并切换。
集群-Cluster
node 集群,由实际物理机,通过同一 cluster name 组成的
1.3 数据类型-type
字符串类型
string 类型,从 ES 5.x 开始不再支持。
keyword 类型:用于精确比对的数据。
text 类型:用于需要进行全文检索的字段。text 类型的数据会被分词器解析成倒排索引。
整数类型
包括 byte, short, integer, long 四种有符号整数。
浮点数
float、double、half_double、scaled_float
date
默认是毫秒时间戳,也可以是日期格式的字符串、秒级数据
日期格式字符串, 如: "2015-01-01"
or"2015/01/01 12:10:30"
.*milliseconds-since-the-epoch:*毫秒级时间戳(从 epoch,即1970年1月1日0点开始计算) *seconds-since-the-epoch:*秒级时间戳
boolean
接受真、假的字符串或数字:
真:true, "true", "on", "yes", "1", ...
假:false, "false", "off", "no", "0", ""(空字符串), 0.0, 0
binary
二进制,以 base64 格式保存。如存储图片。默认情况下,binary 类型的数据默认不存储、不可搜索。
该 field 接收 2 个参数:
doc_values:是否要存储到磁盘上,方便以后用来排序、聚合或脚本查询。默认 false store:是否要与 _source 分开存储、检索。默认 false
array
ES 没有提供数组类型。任何 filed都可以包括 0或多个值,也就是形成数组。但数组中数据必须是同一类型。
Object
A JSON Object
ip
存储 ipv4 或 ipv6 地址。
还有一些不常用的数据类型,具体参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
1.4 分词器-analyzer
分词器用于添加文本到索引中,或检索 text 类型数据时进行文本分析使用。
注意:仅有 text 类型的 field 才支持分词。
如没有重写分析器映射参数,那么这个分词器会被同时用于索引和文本检索。
文本分析 text analyze 发生在两个地方:
Index time:把一个文档添加到索引时,所有的 text 类型属性都会被分词。 Search time: 使用全文检索某个 text 类型的属性,查询参数会被分析。
一般,Index 和 Search 用的分词器是相同的。这样可以保证对属性的分词结果一致。
关于分词器的具体内容参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html
1.5 REST API
ES 通过 REST API 提供了一系列查询、更新、删除等操作的功能接口。
关于 REST PAI 的内容将在另一节进行整理。
可以参考:
https://blog.csdn.net/fujiakai/article/details/91971969 https://github.com/h2pl/Java-Tutorial
2. ES 底层原理
2.1 写数据流程
首先选择一个节点,该节点成为协调节点 coordinating node 协调节点对 document 进行路由,将请求转发给有 primary shard 的 node primary node 处理请求,将数据同步至 replica shard 协调节点 发现 primary shard 和 replica shard 都完成了操作,就返回响应给客户端
2.2 读数据流程
根据 doc 的 id 来读数据,会根据 id 进行 hash,找到该 id 分配的 shard,然后再查询该 shard
首先选择一个节点(任意),成为 coordinating node 协调节点 根据 id 进行 hash,将请求转发至对应的 node;此时会使用 round-robin 随机轮询 算法,在 primary shard 和 replica shard 中随机选择一个,使读请求负载均衡 实际处理请求的 node 返回 document 给协调节点 协调节点返回 document 给客户端
所以,写操作由 primary shard 执行,而读操作则在 primary shard 和 replica shard 之间负载均衡。
2.3 搜索数据流程
先通过 query phase 得到 doc_id 的数据,然后 fetch phase 用 doc_id 读取 document
具体步骤:
客户端将请求随机发给某个节点,该节点成为协调节点 协调节点将搜索请求转发给 Index 的所有 shard 对应的 primary shard 或 replica shard(同一个 shard 随机取一个即可) query phase:每个 shard 将自己的搜索结果 (一些 doc_id) 返回给协调节点;协调节点进行数据的合并、排序、分页等操作,产出最终结果 fetch phase:接着,协调节点根据 doc_id 去对应的 shard 拉取实际的 document 数据,返回给客户端
2.4 es 写入数据底层原理
当 primary shard 处理数据写入请求时,是按照如下步骤进行的:
数据写入 buffer,记录到 translog refresh: 达到 index.refresh_interval (默认1s),或 buffer 快满时,会触发 refresh 操作 ——> buffer 数据写入 os cache(生成一个 segment 缓存文件),同时清空 buffer;refresh 执行完成后,这个 document 已经可以被搜索到了 flush: 当 translog 足够大或达到 30 min,触发 commit,首先会将 buffer 中当前的数据 refresh 到 os cache。然后强制将 os cache中的所有 segment 写入到硬盘,清空 translog,重建 tranlogs。这个 commit 就叫 flush
总结:
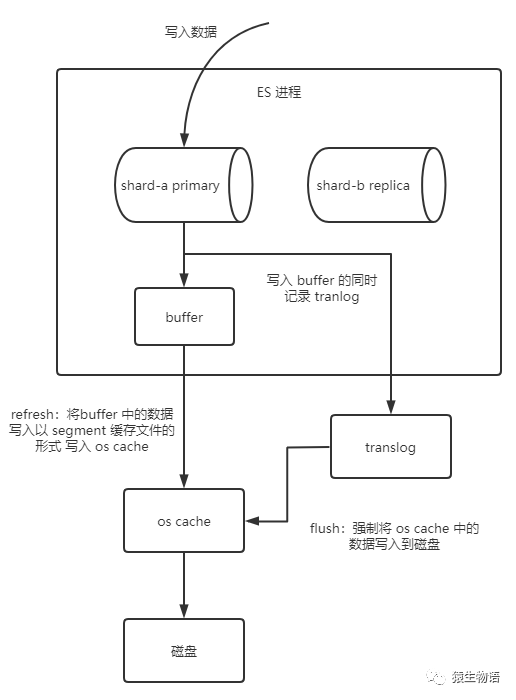
segment: 一个 index 是由多个 segment (段文件,也就是倒排索引)组成。
translog 文件的作用:机器宕机后重启,es 会自动读取 translog 日志文件,恢复数据到 buffer 和 os cache;translog 也是先写入 os cache,默认 5s 一次刷到磁盘上。所以,最多会丢失 5s 的数据。
commit point 文件中记录了所有的 segment 的信息。
当 segment 足够多时,可以使用 merge 操作合并段文件。
2.5 es 删除/更新数据原理
删除数据时,会生成一个 .del 文件,标记某个 doc 为 deleted 状态。搜索的时候根据 .del 判定该 doc 被删除了;
更新数据时,将原来的 doc 标记为 deleted 状态,然后新写入一条数据;
在上面我们提到,每 1s 会 refresh 一次,这样就生成一个 segment file。会定期执行 merge 操作来合并 segment file,此时,会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘,写一个 commit point 来表示所有新的 segment file,同时删除旧的 segment file.
2.6 倒排索引
倒排索引就是记录词在哪些 doc 中出现,包括出现的次数、位置等信息。这样可以直接根据分词来查找命中的文章。
wordA -> doc1
wordB -> doc1, doc2
...
使用倒排索引,不仅可以快速定位到关键词存在的文档。还可以根据次数等相关度信息对检索结果进行排序。
实际的倒排索引比这要复杂一些,大师兄对倒排索引的解释写的很好:https://www.cnblogs.com/cjsblog/p/10327673.html
最近在系统地学习 Redis、RabbitMQ、ES 等技术的知识,着重关注原理、底层、并发等问题,关于相关技术分享后续会逐渐发布出来。欢迎关注公众号:猿生物语(ID:JavaApes)
