




概述
全称:Click Stream Data Warehouse, Clickhouse=”Click” + “House”。从名字就可以看出这个数据库能解决的问题,是Click(事件)流的存储和查询问题。没有任何一种数据库能视为银弹,解决任何场景的问题。Clickhouse也不例外。每个引擎的提出都是为了解决当时面临的存储问题。Yande研发Clickhouse前,主要面临的业务场景是支持Yandex.Metrica统计分析服务,是典型的OLAP分析。
绝大多数是读请求。
读取时是范围读取,即读取多数行,但是较少的列。
已添加的数据不修改。
无须事务。
数据一致性要求低。
宽表,单表包含大量列。
列式存储和数据压缩。
支持DBMS,包括DDL及DML大部分SQL语句。
支持多种引擎。
支持索引。
变随机写磁盘为顺序写磁盘。
变无序为有序。
利用LSM-Tree树结构,对用户写入的数据线排序进行,再有序写入。核心优势:存储有序性可以加快数据查询,根据排序键的等值条件或者range条件,可以快速找到目标行所在的近似位置区域。
目前网上资料针对Clickhouse
的最新版本3.21.x
较少,或者信息有所缺漏,目前我搭了一套5个shard,1个replica的集群Clickhouse
,供大家参考。
适合场景
绝大多数请求都是用于读访问的
数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
数据只是添加到数据库,没有必要修改
读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
表很“宽”,即表中包含大量的列
查询频率相对较低(通常每台服务器每秒查询数百次或更少)
对于简单查询,允许大约50毫秒的延迟
列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
不需要事务
数据一致性要求较低
每次查询中只会查询一个大表。除了一个大表,其余都是小表
查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
不擅长领域:
不支持事务。
不擅长根据主键按行粒度查询(单条记录查询)。
不擅长按行删除数据。
不擅长更新数据。
SQL
创建表
分为本地表和分布式表。本地表为实际存储数据的表,分布式表为逻辑上的表,可理解为视图,查询一般用分布式表,由分布式表将查询请求路由到各个本地表进行查询,汇总数据。
注意:分布式表最好不要用于数据写入,主要是写入不可控,拆分成parts不可控。
集群中创建表(Distributed)
create table click_detail on cluster perftest_3shards_1replicas (`prd_code` String,`prd_track_code` String,`account_id` FixedString(32),`unified_account_id` UInt32,`event_time` datetime,`server_time` datetime,`params` Nested(`key` String,`val` String))ENGINE = MergeTree()PARTITION BY toYYYYMMDD(`server_time`)ORDER BY tuple()
创建本地表
create table click_detail_t (`prd_code` String,`prd_track_code` String,`account_id` FixedString(32),`unified_account_id` UInt32,`event_time` datetime,`server_time` datetime,`params` Nested(`key` String,`val` String))ENGINE = MergeTree()PARTITION BY toYYYYMMDD(`server_time`)ORDER BY tuple()
集群中删除表
drop table click_detail on cluster perftest_3shards_1replicas
创建分布式表(用于查询)
分布式(Distributed)引擎,本身不存储数据,但可以在多个服务器上进行分布式查询。读是自动并行的。读取时,远程服务器表的索引(如果存在)会被使用。
-- 创建分区表用于查询(视图)create table click_detail_all (`prd_code` String,`prd_track_code` String,`account_id` FixedString(32),`unified_account_id` UInt32,`event_time` datetime,`server_time` datetime,`params` Nested(`key` String,`val` String)) engine=Distributed(perftest_3shards_1replicas, default, click_detail, toYYYYMMDD(`server_time`))
DML
-- 聚合查询,查询参数key的点击数SELECT `params.key` as key, COUNT(`params.val`) as value FROM default.click_detailarray join paramsgroup by keyorder by value desc limit 10-- 功能点日明细,记录最后一次更新时间SELECTaccount_id ,prd_track_code,MAX(server_time)FROMclick_detailwhereserver_time > '2021-04-20'AND server_time < '2021-04-21'GROUP BYaccount_id ,prd_track_code
数据类型
-- 嵌套类型查询select * FROM click_detail array join params where `params.key` ='from' and `params.val`='910000000001'SELECT * FROM click_detail array join params where `params.val` = '200215.IB' AND server_time > '2021-04-13'
分区和索引
clickhouse为什么那么快,就是因为数据分区和索引。首先,数据是按照分区键分区,分区是物理分区,不同的分区数据单独存放。可以看具体的数据文件。
#创建表CREATE TABLE test_merge_tree(`Id` UInt64,`Birthday` Date,`Name` String)ENGINE = MergeTree()PARTITION BY toYYYYMM(Birthday)ORDER BY (Id, Name)SETTINGS index_granularity = 2#插入数据INSERT INTO test_merge_tree VALUES(1, '2000-02-01', 'Fly li')
数据目录结构
MergeTree
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
MergeTree磁盘文件
步骤一:创建表,并插入数据
CREATE TABLE default.mt(`a` Int32,`b` Int32,`c` Int32,INDEX `idx_c` (c) TYPE minmax GRANULARITY 1)ENGINE = MergeTreePARTITION BY aORDER BY bSETTINGS index_granularity=3insert into default.mt(a,b,c) values(1,1,1);insert into default.mt(a,b,c) values(5,2,2),(5,3,3);insert into default.mt(a,b,c) values(3,10,4),(3,9,5),(3,8,6),(3,7,7),(3,6,8),(3,5,9),(3,4,10);
步骤二:查看磁盘文件
ls ckdatas/data/default/mt/1_4_4_0 3_6_6_0 5_5_5_0 detached format_version.txt
步骤三:查看分区3
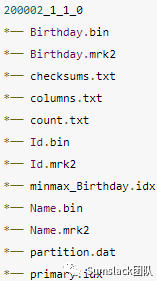
ls ckdatas/data/default/mt/3_6_6_0/a.bin a.mrk2 b.bin b.mrk2 c.bin checksums.txt c.mrk2 columns.txt count.txt minmax_a.idx partition.dat primary.idx skp_idx_idx_c.idx skp_idx_idx_c.mrk2*.bin 是列数据文件,按主键排序(ORDER BY),这里是按照字段 b 进行排序*.mrk2 mark 文件,目的是快速定位 bin 文件数据位置minmax_a.idx 分区键 min-max 索引文件,目的是加速分区键 a 查找primay.idx 主键索引文件,目的是加速主键 b 查找skp_idx_idx_c.* 字段 c 索引文件,目的是加速 c 的查找
在磁盘上,MergeTree 只有一种物理排序,就是 ORDER BY 的主键序,其他文件(比如 .mrk/.idx)是一种逻辑加速,围绕仅有的一份物理排序,要解决的问题是:
在以字段 b 物理排序上,如何实现字段 a、字段 c 的快速查找?
MergeTree 引擎概括起来很简单:整个数据集通过分区字段被划分为多个物理分区,每个分区內又通过逻辑文件围绕仅有的一种物理排序进行加速查找。
MergeTree存储结构
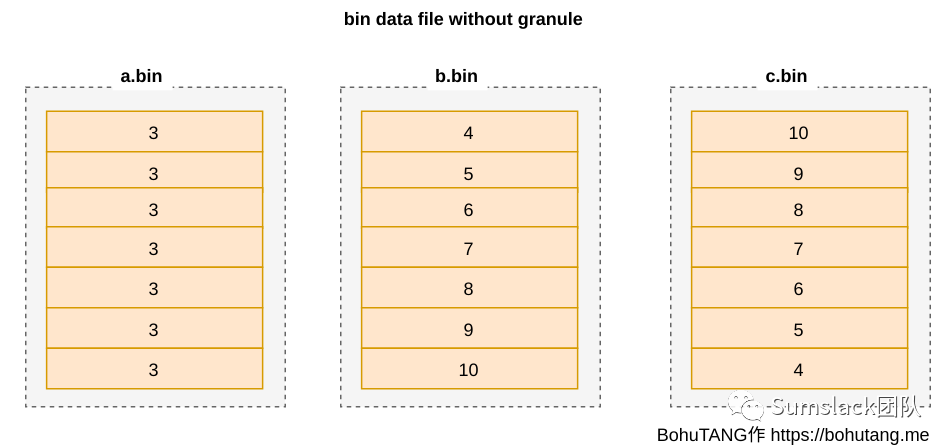
对于单个物理分区內的存储结构,首先要明确一点,MergeTree 的数据只有一份:*.bin。
a.bin 是字段 a 的数据,b.bin 是字段 b 的数据,c.bin 是字段 c 的数据,也就是大家熟悉的列存储。
各个 bin 文件以 b.bin排序对齐(b 是排序键),如图:
这样会有一个比较严重的问题:
如果 *.bin 文件较大,即使读取一行数据,也要加载整个 bin 文件,浪费了大量的 IO,没法忍。
Granule
MergeTree 把bin文件根据颗粒度(GRANULARITY)划分为多个颗粒(granule),每个granule单独压缩存储。
SETTINGS index_granularity=3 表示每 3 行数据为一个 granule,分区目前只有 7 条数据,所以被划分成 3 个 granule(三个色块):

为方便读取某个 granule,使用 *.mrk 文件记录每个 granule 的 offset,每个 granule 的 header 里会记录一些元信息,用于读取解析:
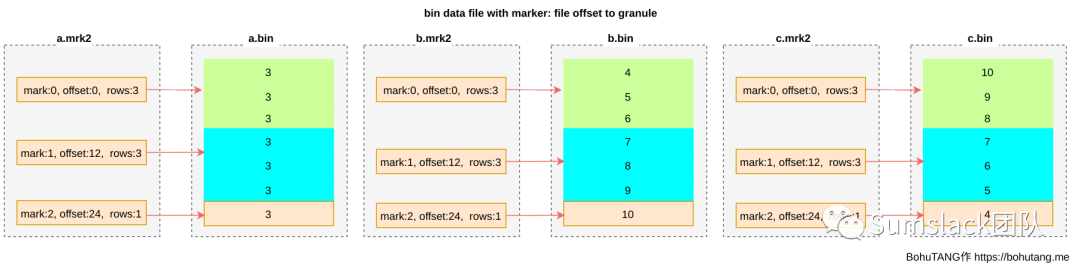
这样,我们就可以根据 mark 文件,直接定位到想要的 granule,然后对这个单独的 granule 进行读取、校验。
目前,我们还有缺少一种映射:每个 mark 与字段值之间的对应,哪些值区间落在 mark0,哪些落在 mark1 …?
有了这个映射,就可以实现最小化读取 granule 来加速查询:
根据查询条件确定需要哪些 mark
根据 mark 读取相应的 granule
稀疏索引
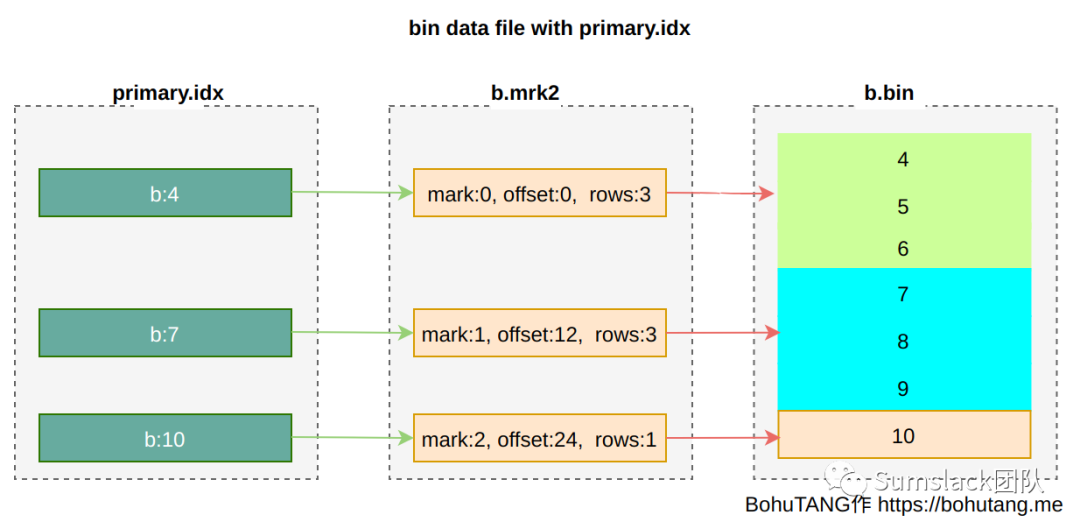
因为数据只有一份且只有一种物理排序,MergeTree在索引设计上选择了简单、高效的稀疏索引模式。什么是稀疏索引呢?就是从已经排序的全量数据里,间隔性的选取一些点,并记录这些点属于哪个mark。
primary index(主键索引)
主键索引,可通过[PRIMARY KEY expr]指定,默认是 ORDER BY 字段值。
注意 ClickHouse primary index 跟 MySQL primary key 不是一个概念。
在稀疏点的选择上,取每个 granule 最小值:
skipping index(普通索引)
INDEX idx_c(c) TYPE minmax GRANULARITY 1 针对字段 c 创建一个 minmax 模式索引。
GRANULARITY 是稀疏点选择上的 granule 颗粒度,GRANULARITY 1 表示每 1 个 granule 选取一个。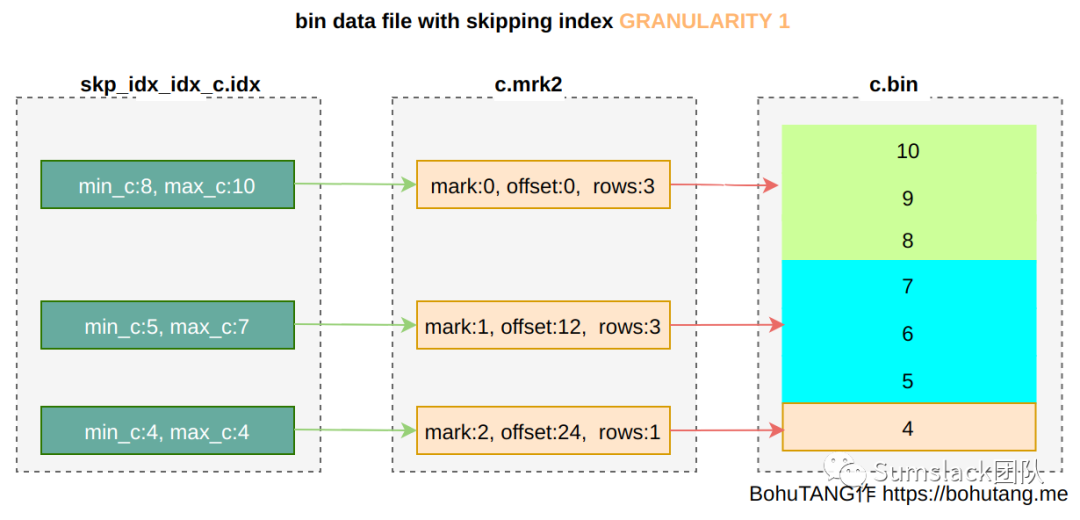
partition minmax index(分区索引)
针对分区键,MergeTree 还会创建一个 min/max 索引,来加速分区选择。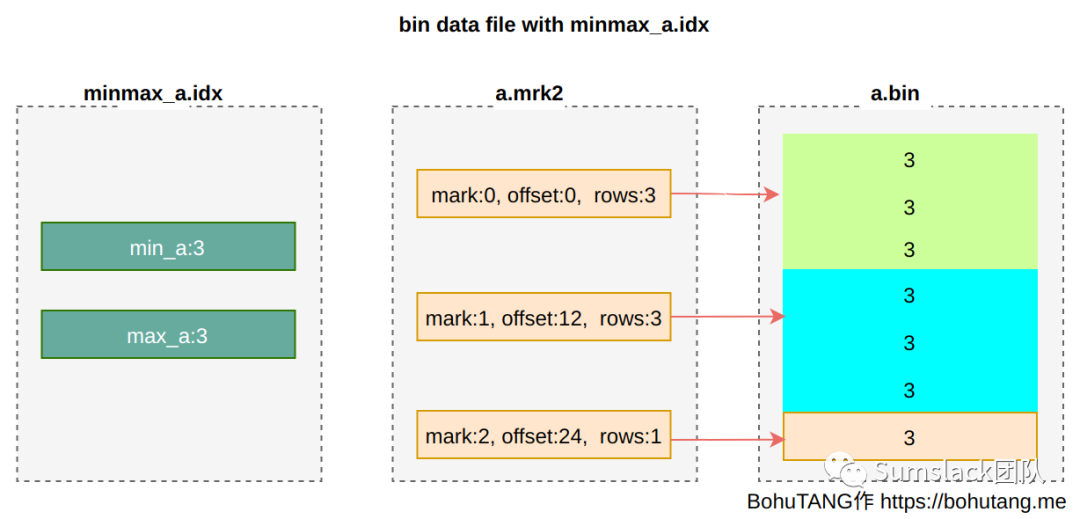
集群部署
•采用rpm安装方式,以为我服务器版本是CentOS7.5,这一块官网有详细介绍,安装步骤如下:
sudo yum install yum-utilssudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPGsudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
使用以下命令安装:
sudo yum install clickhouse-server clickhouse-client
如果你的服务器不通网络,请挪步这里下载离线安装包:https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
•服务器hosts文件配置 我这里使用5台服务器,所以在/etc/hosts
文件中加入配置:```
172.x.x.1 chs1 172.x.x.2 chs2 172.x.x.3 chs3 172.x.x.4 chs4 172.x.x.5 chs5
- 修改各个服务器的`Clickhouse`配置文件`/etc/clickhouse-server/config.xml`,修改处:
1. path是修改数据路径,这里一定要注意,要修改该目录的拥有者,否则无法启动:`chown -R clickhouse:clickhouse /opt/xxx/clickhouse/`1. remote_servers增加`incl="yyy"`,其中yyy是名称,在后续需要用到1. 打开listen注释- 新增各个服务器的`/etc/metrika.xml`文件```xml<yandex><clickhouse_remote_servers><yyy><shard><weight>10</weight><internal_replication>true</internal_replication><replica><host>chs1</host><port>9000</port></replica></shard><shard><weight>10</weight><replica><internal_replication>true</internal_replication><host>chs2</host><port>9000</port></replica></shard><shard><weight>1</weight><internal_replication>true</internal_replication><replica><host>chs3</host><port>9000</port></replica></shard><shard><weight>1</weight><internal_replication>true</internal_replication><replica><host>chs4</host><port>9000</port></replica></shard><shard><weight>1</weight><internal_replication>true</internal_replication><replica><host>chs5</host><port>9000</port></replica></shard></yyy></clickhouse_remote_servers><zookeeper-servers><node index="1"><host>192.168.x.x</host><port>2182</port></node></zookeeper-servers><macros><replica>chs1</replica></macros><networks><ip>::/0</ip></networks><clickhouse_compression><case><min_part_size>10000000000</min_part_size><min_part_size_ratio>0.01</min_part_size_ratio><method>lz4</method></case></clickhouse_compression></yandex>
•启动服务
在各个服务器上执行:sudo systemctl start clickhouse-server
,注意要使用这种启动方式,官网使用的sudo /etc/init.d/clickhouse-server start
会报错。
•验证集群
在服务器执行:clickhouse-client
,输入select * from system.clusters;
,可查看运行的集群情况,如下图:

