




👉openGauss SQL学习参考资料
https://opengauss.org/zh/docs/2.1.0/docs/Developerguide/SQL%E8%AF%AD%E6%B3%95.html
学习目标
学习openGauss收集统计信息、打印执行计划、垃圾收集和checkpoint
课程学习
连接数据库
#第一次进入等待15秒 #数据库启动中... su - omm gsql -r复制
1.准备数据
Create schema tpcds; CREATE TABLE tpcds.customer_address ( ca_address_sk integer NOT NULL , ca_address_id character(16), ca_street_number character(10) , ca_street_name character varying(60) , ca_street_type character(15) , ca_suite_number character(10) , ca_city character varying(60) , ca_county character varying(30) , ca_state character(2) , ca_zip character(10) , ca_country character varying(20) , ca_gmt_offset numeric(5,2) , ca_location_type character(20) ); insert into tpcds.customer_address values (1, 'AAAAAAAABAAAAAAA', '18', 'Jackson', 'Parkway', 'Suite 280', 'Fairfield', 'Maricopa County', 'AZ', '86192' ,'United States', -7.00, 'condo'), (2, 'AAAAAAAACAAAAAAA', '362', 'Washington 6th', 'RD', 'Suite 80', 'Fairview', 'Taos County', 'NM', '85709', 'United States', -7.00, 'condo'), (3, 'AAAAAAAADAAAAAAA', '585', 'Dogwood Washington', 'Circle', 'Suite Q', 'Pleasant Valley', 'York County', 'PA', '12477', 'United States', -5.00, 'single family');复制
–使用序列的generate_series(1,N)函数对表插入数据
insert into tpcds.customer_address values(generate_series(10, 10000));复制
2.收集统计信息
–查看系统表中表的统计信息
select relname, relpages, reltuples from pg_class where relname = 'customer_address';复制
—使用ANALYZE VERBOSE语句更新统计信息,并输出表的相关信息
analyze VERBOSE tpcds.customer_address;复制
–查看系统表中表的统计信息
select relname, relpages, reltuples from pg_class where relname = 'customer_address';复制
3.打印执行计划
–使用默认的打印格式
SET explain_perf_mode=normal;复制
–显示表简单查询的执行计划
EXPLAIN SELECT * FROM tpcds.customer_address;复制
–以JSON格式输出的执行计划(explain_perf_mode为normal时)
EXPLAIN(FORMAT JSON) SELECT * FROM tpcds.customer_address;复制
–禁止开销估计的执行计划
EXPLAIN(COSTS FALSE)SELECT * FROM tpcds.customer_address;复制
–带有聚集函数查询的执行计划
EXPLAIN SELECT SUM(ca_address_sk) FROM tpcds.customer_address WHERE ca_address_sk<100;复制
–有索引条件的执行计划
create index customer_address_idx on tpcds.customer_address(ca_address_sk); EXPLAIN SELECT * FROM tpcds.customer_address WHERE ca_address_sk<100;复制
4.垃圾收集
–VACUUM回收表或B-Tree索引中已经删除的行所占据的存储空间
update tpcds.customer_address set ca_address_sk = ca_address_sk + 1 where ca_address_sk <100; VACUUM (VERBOSE, ANALYZE) tpcds.customer_address;复制
5.事务日志检查点
–检查点(CHECKPOINT)是一个事务日志中的点,所有数据文件都在该点被更新以反映日志中的信息,所有数据文件都将被刷新到磁盘
CHECKPOINT;复制
6.清理数据
drop schema tpcds cascade;
课后作业
1.创建分区表,并用generate_series(1,N)函数对表插入数据
Create schema tpcds;
CREATE TABLE tpcds.partition_table
(
ca_address_sk integer NOT NULL ,
ca_address_id character(16),
ca_street_number character(10) ,
ca_street_name character varying(60) ,
ca_street_type character(15) ,
ca_suite_number character(10) ,
ca_city character varying(60) ,
ca_county character varying(30) ,
ca_state character(2) ,
ca_zip character(10) ,
ca_country character varying(20) ,
ca_gmt_offset numeric(5,2) ,
ca_location_type character(20)
);
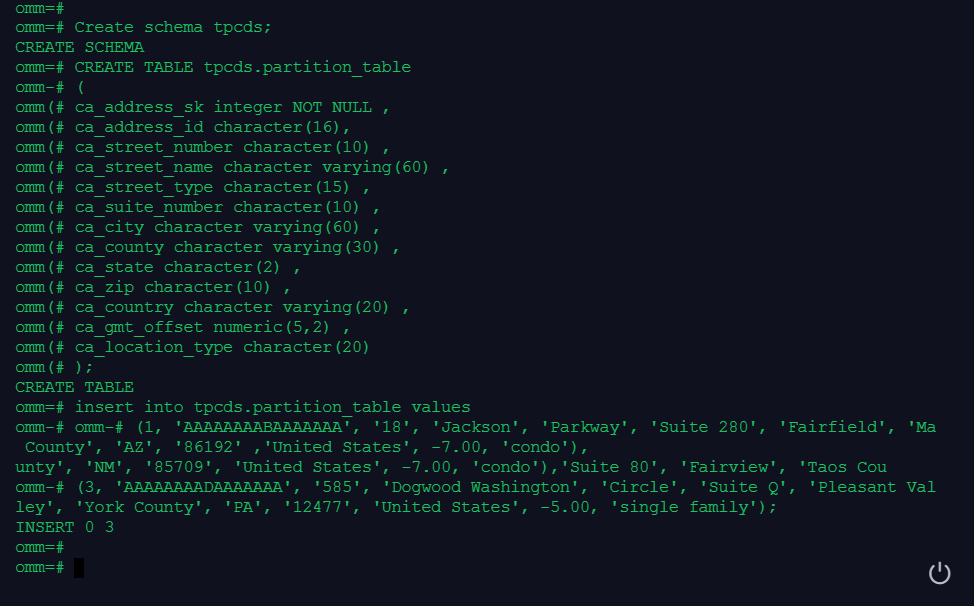
insert into tpcds.partition_table values
(1, 'AAAAAAAABAAAAAAA', '18', 'Jackson', 'Parkway', 'Suite 280', 'Fairfield', 'Maricopa County', 'AZ', '86192' ,'United States', -7.00, 'condo'),
(2, 'AAAAAAAACAAAAAAA', '362', 'Washington 6th', 'RD', 'Suite 80', 'Fairview', 'Taos County', 'NM', '85709', 'United States', -7.00, 'condo'),
(3, 'AAAAAAAADAAAAAAA', '585', 'Dogwood Washington', 'Circle', 'Suite Q', 'Pleasant Valley', 'York County', 'PA', '12477', 'United States', -5.00, 'single family');
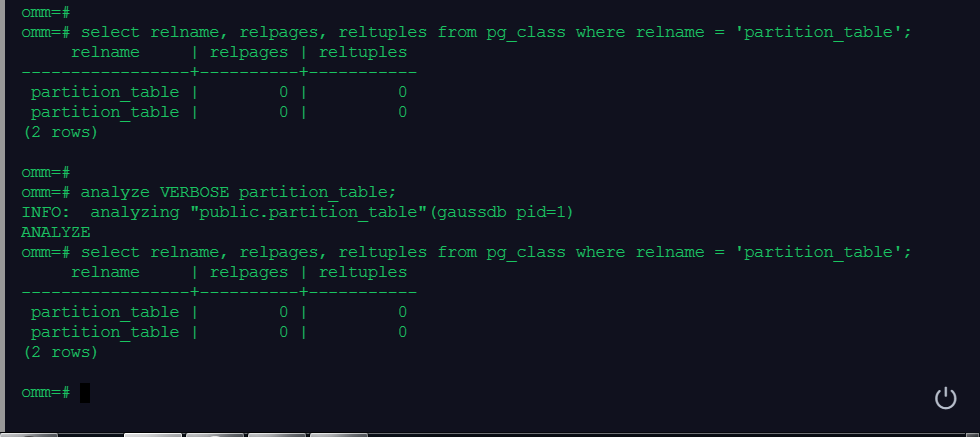
2.收集表统计信息
select relname, relpages, reltuples from pg_class where relname = 'partition_table';
analyze VERBOSE partition_table;
select relname, relpages, reltuples from pg_class where relname = 'partition_table';
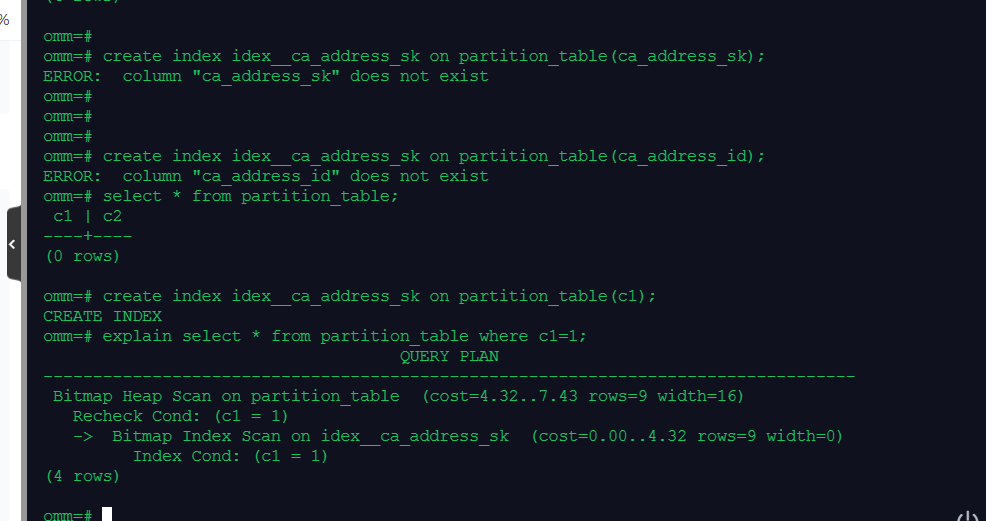
3.显示简单查询的执行计划;建立索引并显示有索引条件的执行计划
SET explain_perf_mode=normal;
EXPLAIN SELECT * FROM partition_table;
create index idex__ca_address_sk on partition_table(c1);
explain select * from partition_table where c1=1;
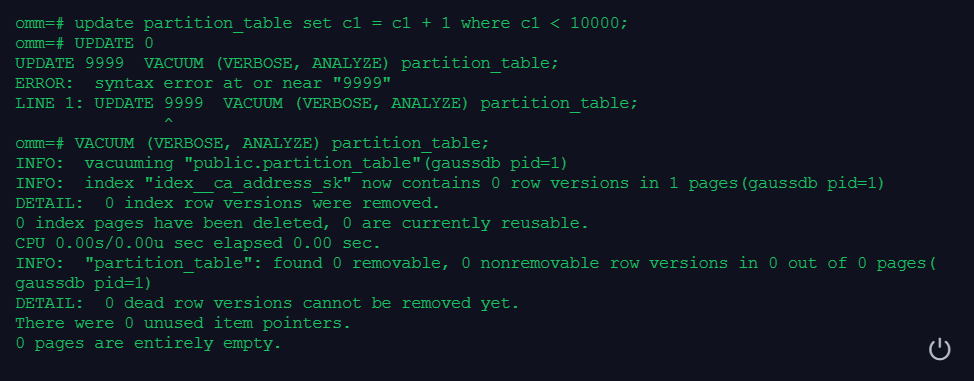
4.更新表数据,并做垃圾收集
update partition_table set c1 = c1 + 1 where c1 < 10000;
VACUUM (VERBOSE, ANALYZE) partition_table;
5.清理数据
drop table partition_table;
学习会了掌握了统计信息的收集方法,SQL执行计划的查看方法,垃圾的回收的方法和检查点简单的使用。




