




1、引言
在某些场景下客户可能会有数据(库)迁移的需求,即需要在集群之间迁移数据的场景。数据迁移一般用于满足灾备冗余、系统环境变更,甚至是机房规划建设等要求。本文将讨论在VERTICA集群之间复制数据的不同方法和区别。
2、要求
在进行企业级数据仓库集群迁移时,一般需要满足数据安全性、数据一致性、现有生产集群不受影响、停机时间最短和迁移后业务正确性的硬性要求。因此在迁移过程中我们一般遵守以下原则:
确保数据安全性: 在技术允许的条件下,要绝对保证数据的安全性,要绝对避免数据损失、丢失等风险。
确保停机时间最短: 在数据库迁移过程中,业务系统停机是不可避免的,但是应该尽量缩短停机时间。
分步骤实施: 企业级VERTICA数据仓库集群一般节点多、数据量大,所以数据库迁移过程中必须能够分阶段实施、阶段把控。
3、策略
结合以往的VERTICA数据库迁移经验,列举了下列几种常用的VERTICA同步数据的方法,并梳理了各类方法的功能差异:
| 方法 | EXPORT TO VERTICA | COPY FROM VERTICA | EXPORT© FROM | COPYCLUSTER | REPLICATE |
|---|---|---|---|---|---|
| 同步数据 | Yes | Yes | Yes | Yes | Yes |
| 同步表结构 | No | No | No | Yes | Yes |
| 指定列数据同步(Columns) | Yes | Yes | Yes | No | No |
| 指定数据集同步(Select) | Yes | No | Yes | No | No |
| 连接源库 | Yes | Yes | Yes | - | - |
| 节点数一致性限制 | - | - | - | Yes | Yes(Enterprise) |
| 库名称一致性限制 | - | - | - | Yes | - |
通常会根据迁移数据的实际要求(全量同步、对象级同步、差异同步等),从上述提到的方法中选择最优的方式。针对不同的场景,上述的某种方法可能比其他方法更适合,应仔细选择适合的解决方案。有些方法可能具有更大的灵活性,但也会存在其他限制。譬如:在vbr中使用copycluster选项,则要求停止目标数据库;COPY和EXPORT语句允许使用SQL命令执行数据移动任务,但需提前创建表对象。
此外,如果可以接受额外的CPU开销,那么COPY FROM VERTICA或 EXPORT TO VERTICA方法可以从网络压缩中获益,启用CompressNetworkData参数即可通过网络传输压缩后的数据,从而解决由于网络性能限制数据同步效率的问题。
3.1、EXPORT TO VERTICA
允许将整个表、表中的特定列或SELECT语句的结果导出到另一个数据库。
=> CONNECT TO VERTICA testdb USER dbadmin PASSWORD '' ON 'VertTest01', 5433;
CONNECT
=> EXPORT TO VERTICA testdb.customer_dimension FROM customer_dimension;
Rows Exported
---------------
23416
(1 row)
=> DISCONNECT testdb;
DISCONNECT
3.2、COPY FROM VERTICA
与EXPORT语句类似,但不允许导出SELECT语句结果集。
=> CONNECT TO VERTICA vmart USER dbadmin PASSWORD '' ON 'VertTest01',5433;
CONNECT
=> COPY customer_dimension FROM VERTICA vmart.customer_dimension;
Rows Loaded
-------------
500000
(1 row)
=> DISCONNECT vmart;
DISCONNECT
3.3、EXPORT TO PARQUET
先使用EXPORT TO PARQUET将库内数据导出至库外进行落地存储,然后通过COPY FROM将数据加载至目标库。
vsql -h sourceDB <<-EOF
EXPORT TO PARQUET(directory = 'hdfs:///user1/data') AS
SELECT * FROM public.T1;
<<-EOF
wait
vsql -h targetDB <<-EOF
COPY public.T1 FROM 'hdfs:///user1/data/*.parquet' PARQUET;
<<-EOF
3.1至3.3小节中涉及的数据同步方案的主要限制有:
- 目标库中的表必须已存在。
- 目标库关闭自增列(建议)。
- 目标库中的列与源列必须具有相同或兼容的数据类型。
- CONNECT to VERTICA打开与目标(源端)数据库的连接。
3.4、COPY CLUSTER
集群复制(COPY CLUSTER)是VERTICA备份恢复工具vbr的一个功能选项,可将数据库复制到另一个集群,实际上是一个Backup + Restore操作。虽然该方案存在很多限制:譬如两个集群中应具有相同的数据库版本、相同的节点数量、相同的数据库名称和相同的节点名称,另外需停掉目标数据库。但作为官方支持的备份恢复工具,它的灵活性高一些,并允许在单个操作中进行备份和恢复。
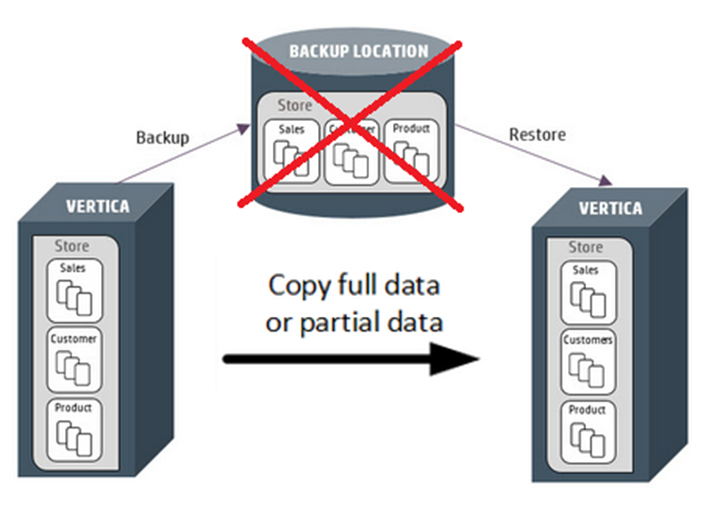
另外,得益于VBR的备份机制,如果copy cluster任务被迫需要中断,再次启动(同一个配置文件)时无需重新发送已同步过的数据文件,可实现“断点续传”的功能。
# 1.Stop targetDB
$ /opt/vertica/bin/admintools -t stop_db -d targetDB
# 2.Create vbr.ini
$ /opt/vertica/bin/vbr --setupconfig
$ cat copycluster.ini
[Misc]
snapshotName = CopyVmart
tempDir = /tmp/vbr
[Database]
dbName = vmart
dbUser = dbadmin
dbPassword = password
dbPromptForPassword = False
[Transmission]
encrypt = False
port_rsync = 50000
[Mapping]
; backupDir is not used for cluster copy
v_vmart_node0001= test-host01
v_vmart_node0002= test-host02
v_vmart_node0003= test-host03
# 3.Run vbr copycluster
/opt/vertica/bin/vbr --config-file copycluster.ini --task copycluster
# 4.Start targetDB
$ /opt/vertica/bin/admintools -t start_db -d targetDB
注意:copycluster选项会覆盖目标集群中的所有现有数据。
3.5、REPLICATE OBJECTS
对象复制(Replicating objects)能够将特定表从一个数据库复制到另一个数据库。与copycluster一样,均为VBR的一个功能项,不同之处在于replicate更加灵活,比如:
replicate可以双向同步数据,可以灵活指定特定表进行同步。replicate不再强制要求节点个数(企业模式仍需)、库名称必须一致。replicate比完全备份要快,可以节省备份位置的磁盘空间。
$ cat object_replication.ini
[Misc]
snapshotName = backup_snapshot
dest_verticaBinDir = /opt/vertica/bin
restorePointLimit = 3
objects = mytable, myschema, myothertable
objectRestoreMode = coexist
[Database]
dbName = mydatabase
dbUser = dbadmin
dbPromptForPassword = True
[Mapping]
v_exampledb_node0001 = destination_host0001
v_exampledb_node0002 = destination_host0002
v_exampledb_node0003 = destination_host0003
v_exampledb_node0004 = destination_host0004
$ vbr -t replicate -c object_replication.ini
4、案例
4.1、基于VBR异地迁移PB级数仓集群
为满足自身业务发展和机房建设规划要求,制定了对某平台VERTICA仓库进行异地迁移的目标。迁移之初,源端数据库已有2万多张表模型,共计约1.3PB的业务数据(压缩比约1.9)。经过多方调研最终决定采用VBR copy cluster方式进行迁移。
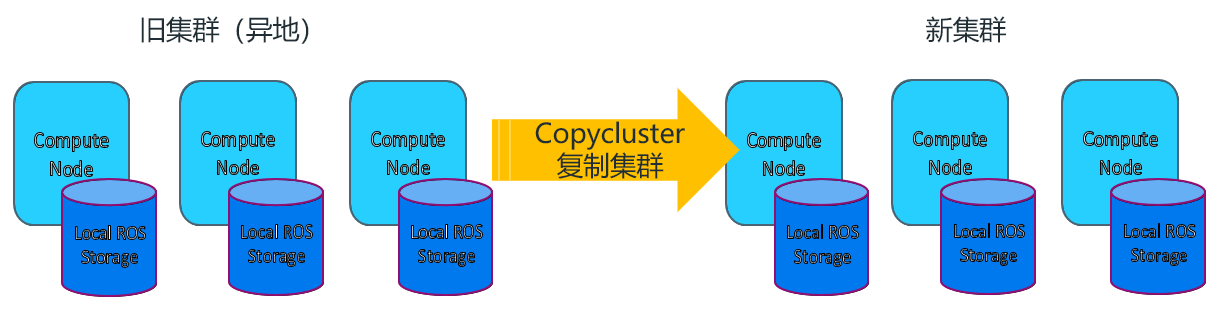
完成本案例迁移历时5天(操作窗口7个小时/日),实际操作时长共36.5小时,速率约17.3TB/h。通过事后复盘及经验总结,使用该方式的主要优势有:
生产不受影响: 使用VBR进行数据迁移期间,可同时对源数据库进行数据装载、处理和查询操作,不影响源数据库的业务运行,对业务性能影响小。由于迁移效率高、停服时间短,迁移期间及割接当日均未影响业务运行。
安全可靠: VERTICA事务处理机制能够保证已提交的数据文件不再修改,vbr基于文件进行同步,因此能够避免迁移后数据不一致的风险。
节约成本: 属于VERTICA自有功能,使用方式简洁,无需采购其它第三方服务,节约迁移成本。
4.2、使用EXPORT TO VERTICA迁移异构模式集群
为充分利用EON模式架构优势实现数据集市业务场景需求,计划将原有数据集市业务场景迁移至EON模式VERTICA集群。经过权衡后,决定放弃使用“将企业数据库迁移到Eon模式(Migrating an Enterprise Database to Eon Mode)”策略(集群规模不一致且shards需要与源节点数一致等限制),而采用EXPORT TO VERTICA方式进行数据迁移。
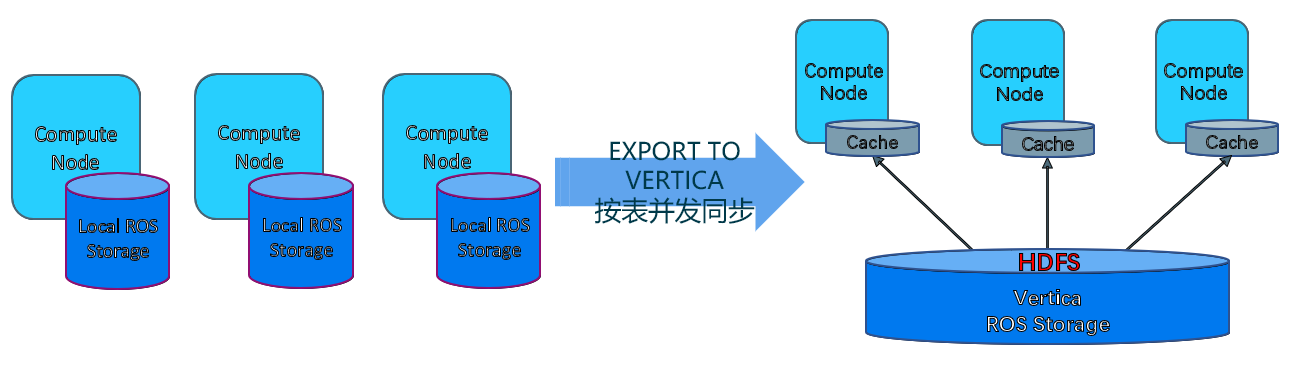
迁移时,源端数据库已有4万多张表模型,共计约140TB的业务数据。整体数据迁移流程如下:
1、部署EON模式VERTICA集群: 共享存储为HADOOP集群
2、迁移数据库对象: 如用户、角色、模式、表、projection、视图、权限等数据库对象
3、锁定源库: 关闭数据库会话,将源数据库置为readonly
4、数据同步: 按表进行并发数据同步
5、数据稽核: 记录数核对、列最大(小)值,行hash值核对
完成本案例数据迁移共用时8小时(操作窗口为割接当日12时至次日1点)。
4.3、统一数据存储,实现湖仓一体
数据文件标准化是数据管理的基础性工作,是数据资产管理的核心活动之一。对理清数据构成、打通数据孤岛、加快数据流通、提升数据价值有着至关重要的作用。因此为满足数据管理要求,实现各平台数据有效交互和共享,本案例通过使用EXPORT TO PARQUET方法,将VERTICA数据导出为parquet格式文件,用于大数据平台各系统间数据共享。
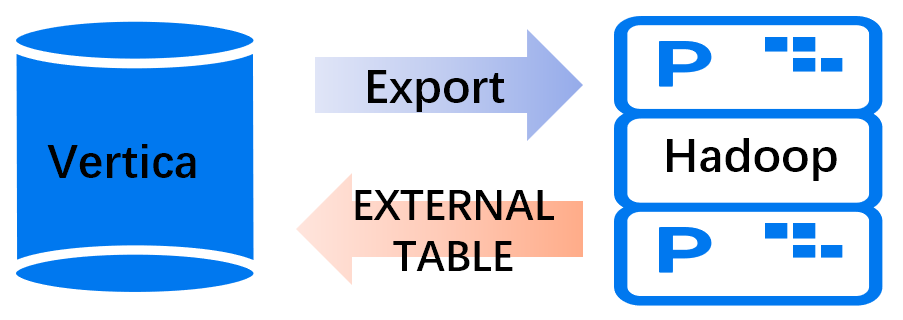
与TEXT、JSON、CSV等格式相比,Parquet格式是Hadoop生态圈主流的列式存储格式,非常适用于OLAP场景,其按列存储和扫描具有更高的压缩比、更小的IO操作。同时,VERTICA支持对其进行列裁剪、谓词下推,可以让QUERY计算离数据尽可能近。VERTICA官方说明如下:
When working with external tables in the Parquet and ORC columnar formats, Vertica tries to improve performance in the following ways:
- By pushing query execution closer to the data so less has to be read and transmitted. Vertica uses the following specific techniques: predicate pushdown, column selection, and partition pruning.
- By taking advantage of data locality in the query plan.
- By analyzing the row count to get the best join orders in the query plan.
5、参考
[1] Copying Data Between Vertica Databases
[2] Copying Data Between Similar Vertica Clusters
[3] Improving Query Performance
