今天正式进入第20天,倒数第二天的学习中,今天我学习到了openGauss的两种数据类型用来支持全文检索。tsvector类型表示为文本搜索优化的文件格式,tsquery类型表示文本查询。
以下是我今天的作业打卡情况,请老师批阅:
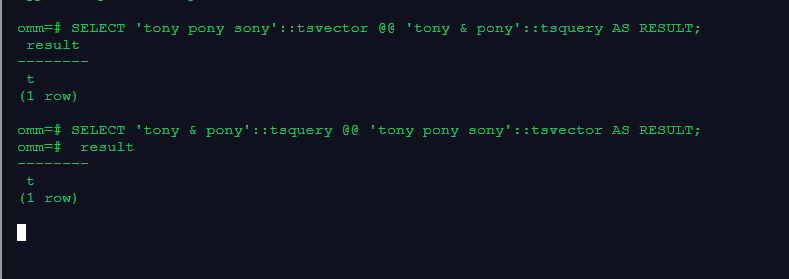
1.用tsvector @@ tsquery和tsquery @@ tsvector完成两个基本文本匹配
su - omm
gsql -r
SELECT 'tony pony sony'::tsvector @@ 'tony & pony'::tsquery AS RESULT;
SELECT 'tony & pony'::tsquery @@ 'tony pony sony'::tsvector AS RESULT;
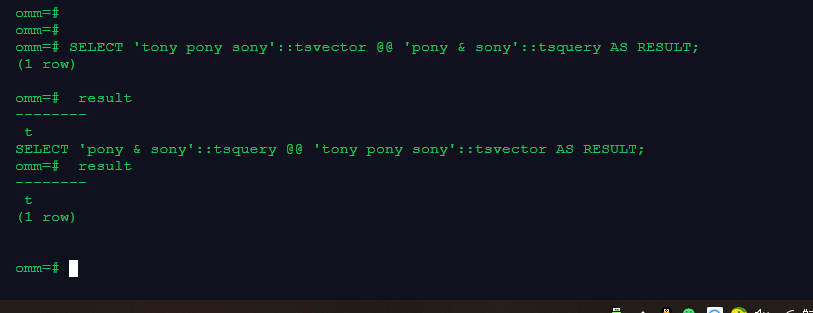
SELECT 'tony pony sony'::tsvector @@ 'pony & sony'::tsquery AS RESULT;
SELECT 'pony & sony'::tsquery @@ 'tony pony sony'::tsvector AS RESULT;
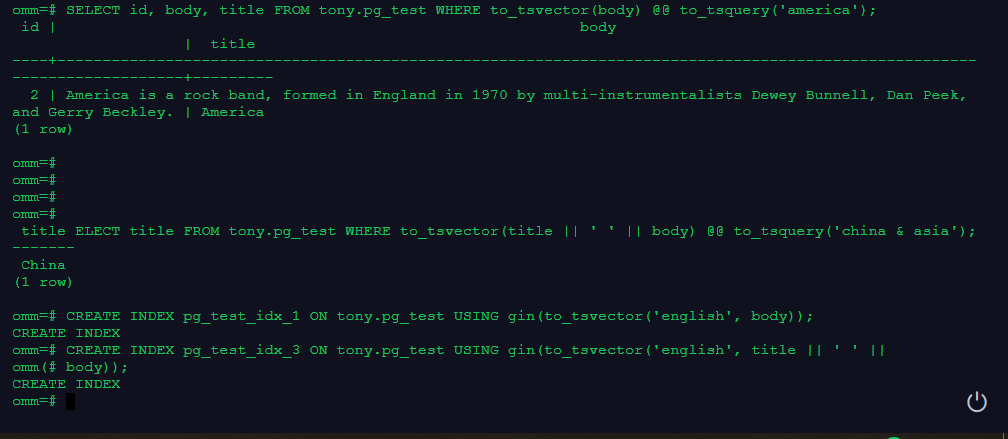
2.创建表且至少有两个字段的类型为 text类型,在创建索引前进行全文检索
CREATE SCHEMA tony;
CREATE TABLE tony.pg_test(id int, body text, title text, last_mod_date date);

INSERT INTO tony.pg_test VALUES(1, 'China, officially the People''s Republic of China(PRC), located in Asia, is the world''s most populous state.', 'China', '2010-1-1');
INSERT INTO tony.pg_test VALUES(2, 'America is a rock band, formed in England in 1970 by multi-instrumentalists Dewey Bunnell, Dan Peek, and Gerry Beckley.', 'America', '2010-1-1');
INSERT INTO tony.pg_test VALUES(3, 'England is a country that is part of the United Kingdom. It shares land borders with Scotland to the north and Wales to the west.', 'England','2010-1-1');

SELECT id, body, title FROM tony.pg_test WHERE to_tsvector(body) @@ to_tsquery('america');

3.创建GIN索引
SELECT title FROM tony.pg_test WHERE to_tsvector(title || ' ' || body) @@ to_tsquery('china & asia');
CREATE INDEX pg_test_idx_1 ON tony.pg_test USING gin(to_tsvector('english', body));
CREATE INDEX pg_test_idx_3 ON tony.pg_test USING gin(to_tsvector('english', title || ' ' ||
body));
\d+ tony.pg_test

4.清理数据
drop schema tony cascade;