




学习心得:
EXPLAIN显示SQL语句的执行计划。执行计划将显示SQL语句所引用的表会采用什么样的扫描方式,如:简单的顺序扫描、索引扫描等。如果引用了多个表,执行计划还会显示用到的JOIN算法。执行计划的最关键的部分是语句的预计执行开销,这是计划生成器估算执行该语句将花费多长的时间。若指定了ANALYZE选项,则该语句会被执行,然后根据实际的运行结果显示统计数据,包括每个计划节点内时间总开销(毫秒为单位)和实际返回的总行数。这对于判断计划生成器的估计是否接近现实非常有用。
课后作业:
1.创建分区表,并用generate_series(1,N)函数对表插入数据
回答:
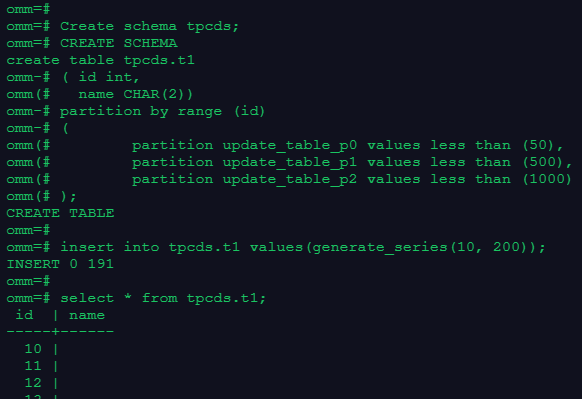
-- 创建分区表
Create schema tpcds;
create table tpcds.t1
( id int,
name CHAR(2))
partition by range (id)
(
partition update_table_p0 values less than (50),
partition update_table_p1 values less than (500),
partition update_table_p2 values less than (1000)
);
-- 使用generate_series(1,N)函数对表插入数据
insert into tpcds.t1 values(generate_series(10, 200));
-- 查看数据
select * from tpcds.t1;复制截图:
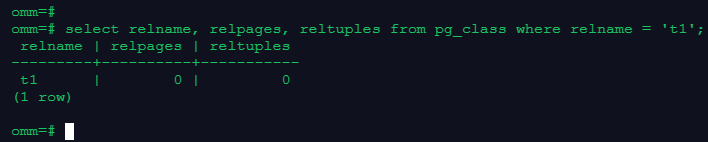
2.收集表统计信息
回答:
select relname, relpages, reltuples from pg_class where relname = 't1';复制截图:
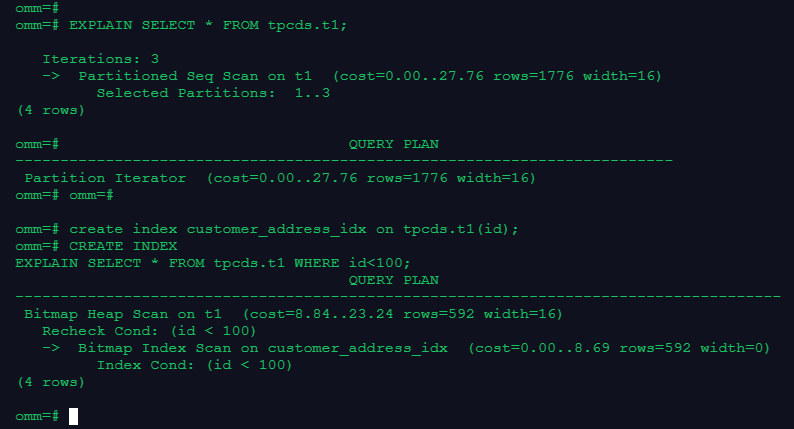
3.显示简单查询的执行计划;建立索引并显示有索引条件的执行计划
回答:
EXPLAIN SELECT * FROM tpcds.t1;
-- 建立索引并显示有索引条件的执行计划
create index customer_address_idx on tpcds.t1(id);
EXPLAIN SELECT * FROM tpcds.t1 WHERE id<100;复制截图:
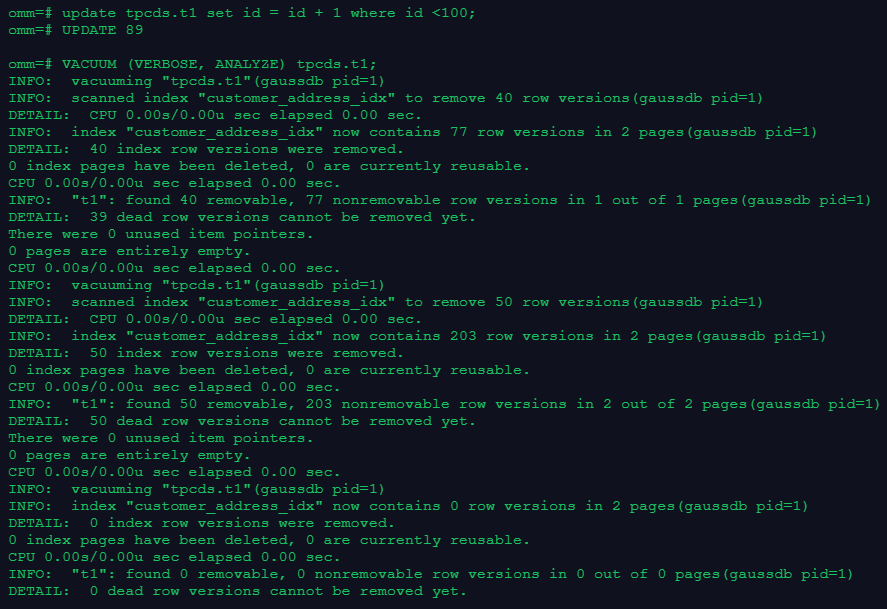
4.更新表数据,并做垃圾收集
回答:
update tpcds.t1 set id = id + 1 where id <100;
VACUUM (VERBOSE, ANALYZE) tpcds.t1;复制截图:
5.清理数据
回答:
drop schema tpcds cascade;复制截图:
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年3月国产数据库大事记
墨天轮编辑部
877次阅读
2025-04-03 15:21:16
MogDB 发布更新,解决 openGauss 数据库在长事务情况下Ustore表膨胀问题
MogDB
287次阅读
2025-04-17 10:41:41
openGauss 7.0.0-RC1 版本正式发布!
Gauss松鼠会
205次阅读
2025-04-01 12:27:03
MogDB 发布更新,解决 openGauss 数据库在长事务情况下Ustore表膨胀问题
云和恩墨
186次阅读
2025-04-16 09:52:02
openGauss 7.0.0-RC1 版本体验:一主一备快速安装指南
孙莹
180次阅读
2025-04-01 10:30:07
鲲鹏RAG一体机解决方案正式发布 openGauss DataVec向量数据库助力DeepSeek行业应用
Gauss松鼠会
124次阅读
2025-03-31 10:00:29
荣誉时刻!openGauss认证证书快递已发,快来看看谁榜上有名!
墨天轮小教习
113次阅读
2025-04-23 17:39:13
openGauss6.0.0适配操作系统自带的软件,不依赖三方库
来杯拿铁
75次阅读
2025-04-18 10:49:53
opengauss使用gs_probackup进行增量备份恢复
进击的CJR
70次阅读
2025-04-09 16:11:58
Postgresql数据库单个Page最多存储多少行数据
maozicb
60次阅读
2025-04-23 16:02:19
