




简述
上一篇文章介绍了使用 CloudCanal 进行 MySQL 到 ElasticSearch 的宽表构建, 有蛮多朋友关注和尝试使用,我们也在不断迭代升级这个能力。
作为产品的通用功能,今天我们介绍下 MySQL -> ClickHouse 的宽表构建案例。
技术点
ClickHouse 表关联之觞
ClickHouse 作为标准的列存数据库,其特点相当鲜明,对于多维度数据聚合、筛选特别高效,对于列存面向计算的特点,用得相当不错,包括但不限于以下特点
io 效率高
列压缩
少数列数据存取io放大效应较小
极致计算优化
向量化
利用 SSE 等 SIMD 指令集加速
未来可选 AVX 512 等指令集优化
未来对于计算卸载到 FPGA、GPU 较便利
但是 ClickHouse 对于数据关联(join), 相比于其 多维聚合、筛选 能力要弱一些。对于这个问题,我们觉得有必要通过 CloudCanal 的宽表能力,让其适用性得到进一步提升。大宽表 + 突出的数据 多维聚合、筛选 能力,几乎等于交互式分析的杀手锏。
操作示例
前置条件:
CloudCanal 社区版部署,参见社区版安装文档(https://doc-cloudcanal.clougence.com/operation/install_linux)
准备好 MySQL 数据库(本例使用 5.7 版本)和 ClickHouse 数据库(本例使用 21.8.X 版本)
MySQL 上创建 1 张事实表(my_order)和 2 张维表 (user 、product)
CREATE TABLE `my_order` (
`id` bigint(19) NOT NULL AUTO_INCREMENT,
`gmt_create` datetime NOT NULL,
`gmt_modified` datetime NOT NULL,
`product_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1460 DEFAULT CHARSET=utf8;
CREATE TABLE `product` (
`id` bigint(19) NOT NULL AUTO_INCREMENT,
`gmt_create` datetime NOT NULL,
`gmt_modified` datetime NOT NULL,
`name` varchar(255) NOT NULL,
`price` decimal(20,2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2719 DEFAULT CHARSET=utf8;
CREATE TABLE `user` (
`id` bigint(19) NOT NULL AUTO_INCREMENT,
`gmt_create` datetime NOT NULL,
`gmt_modified` datetime NOT NULL,
`name` varchar(255) NOT NULL,
`level` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2224 DEFAULT CHARSET=utf8复制ClickHouse 上创建 1 张宽表 my_order , 并额外包含两张维表相关数据
CREATE TABLE trade.my_order
(
`id` Int64,
`gmt_create` DateTime,
`gmt_modified` DateTime,
`product_id` Int64,
`user_id` Int64,
`user_name` Nullable(String),
`product_name` Nullable(String),
`product_price` Nullable(Decimal(20, 2))
)
ENGINE = ReplacingMergeTree
ORDER BY id
SETTINGS index_granularity = 8192复制user_id (关联user.id), user_name(对应user.name)
product_id(关联product.id) ,product_name(对应product.name),product_price (对应product.price)
开发宽表代码
打开代码工程cloudcanal-data-process
(https://gitee.com/clougence/cloudcanal-data-process) ,并找到代码类 MySqlToChOnlyFact_one_fact_two_dim.java
修改必要信息

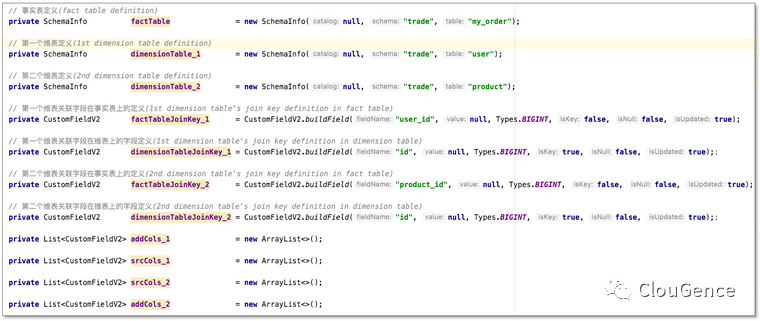

打包
进入工程目录,使用命令进行打包
% pwd
/Users/zylicfc/source/product/cloudcanal/cloudcanal-data-process
% mvn -Dtest -DfailIfNoTests=false -Dmaven.javadoc.skip=true -Dmaven.compile.fork=true clean package复制
自定义代码包
打包命令后,代码包位于工程目录下的 wide-table/target 目录

添加数据源
登录 CloudCanal 平台
数据源管理->新增数据源
将MySQL 和 ClickHouse 分别添加

任务创建
任务管理->任务创建
选择 源 和 目标 数据源
选择 数据同步,并勾选 全量数据初始化, 其他选项默认
选择需要迁移同步的表, 此处只要选择事实表即可,维表会通过自定义代码反查补充

选择列,默认全选,选择上传代码包(路径如上所示)

确认创建,并自动运行

校验数据
变更事实表数据
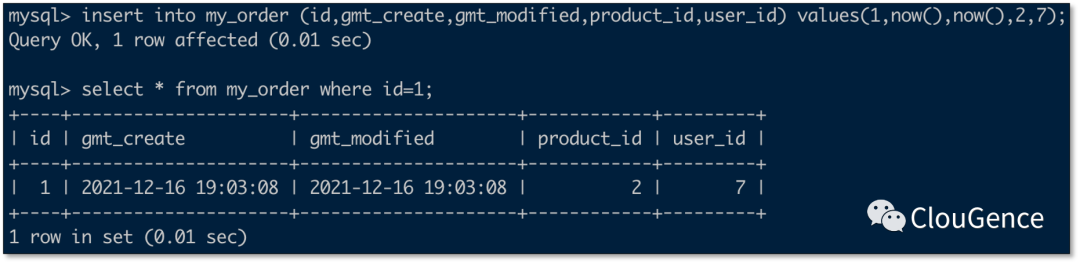

变更维表数据


数据变化规律
事实表插入,更新都会反查维表最新数据并写入对端
维表更新,需要触发事实表更新才能带上最新的维表变更数据写入对端
维表数据删除,如果触发事实表更新,默认将会把对应的维表数据(已删除)置为null
常见问题
维表变化后怎么办?
维表变化不会直接触发事实表更新。需要源端触发事实表更新(比如变更一个时间字段),带上最新的维表数据进行对端数据刷新。
另外对于维表数据的删除,如果触发事实表更新从而刷新对端数据,则默认置为null。
不会开发 java 代码怎么办?
如果能打包不会 java 开发在cloudcanal-data-process(https://gitee.com/clougence/cloudcanal-data-process) 可以寻找相应模版,修改配置即可。
如果不能打包也不会开发,找 CloudCanal 同学协助。
如果遇到出错或者问题怎么办?
如果会 java 开发,建议打开任务的 printCustomCodeDebugLog 观察输出的数据是否符合预期,如果不符合预期,可以打开任务的 debugMode 参数,对数据转换逻辑进行调试。
如果不会 java 开发, 找 CloudCanal 同学协助。
还支持其他数据源么?
这个是 CloudCanal 通用能力,只要源和目标之间实现了全量迁移和增量同步,即支持。
总结
本文简单介绍了如何使用 CloudCanal 进行 MySQL -> ClickHouse 的宽表构建,以最常见的单事实表多维表方式举例。各位读者朋友,如果你觉得还不错,请点赞、评论加转发吧。
更多精彩
加入社区
我们创建了 CloudCanal 微信交流群,在里面,您可以得到最新版本发布信息和资源链接,您能看到其他用户一手评测、使用情况,您更能得到热情的问题解答,当然您还可以给我们提需求和问题。扫描下方二维码,添加我们小助手微信拉您进群,备注: 加 CloudCanal 群。

