




点击上方蓝色字体关注“Dmall 技术”
Sentinel原理简介
Redis Sentinel(哨兵)是Redis官方实现的高可用监控及自动切换组件,具有以下特点:
组件由多个分布式节点组成集群,共同对目标Redis进行故障判断
探测到目标Redis故障时,通过Raft协议选举出Leader,执行切换动作,更新复制拓扑结构
支持自定义外部脚本调用,比如:VIP/DNS/配置中心等更新操作
一套Sentinel集群可以监控多套目标Redis
实现巧妙,Sentinel节点之间相互自动发现及同步信息,简单易用
redis-sentinel其实就是redis-server,main函数会判断进程名称,或者传入参数,决定是运行server模式,还是sentinel模式:
/* Returns 1 if there is --sentinel among the arguments or if argv[0] contains "redis-sentinel". */
int checkForSentinelMode(int argc, char **argv) {
int j;
if (strstr(argv[0],"redis-sentinel") != NULL) return 1;
for (j = 1; j < argc; j++)
if (!strcmp(argv[j],"--sentinel")) return 1;
return 0;
}
Sentinel实现源码剖析
源码分析是比较枯燥的,在开始之前,带着如下几个问题:
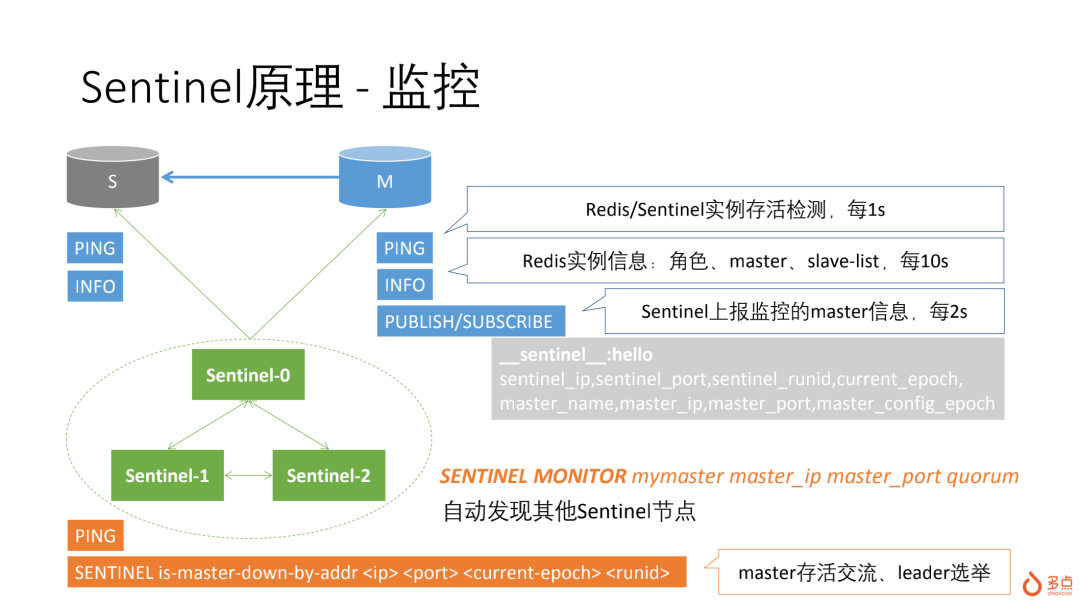
Redis是单线程模式,Sentinel它是如何实现监控多套Redis集群的?
Sentinel与Master、Slave、及其他Sentinel之间是如何交流信息的?
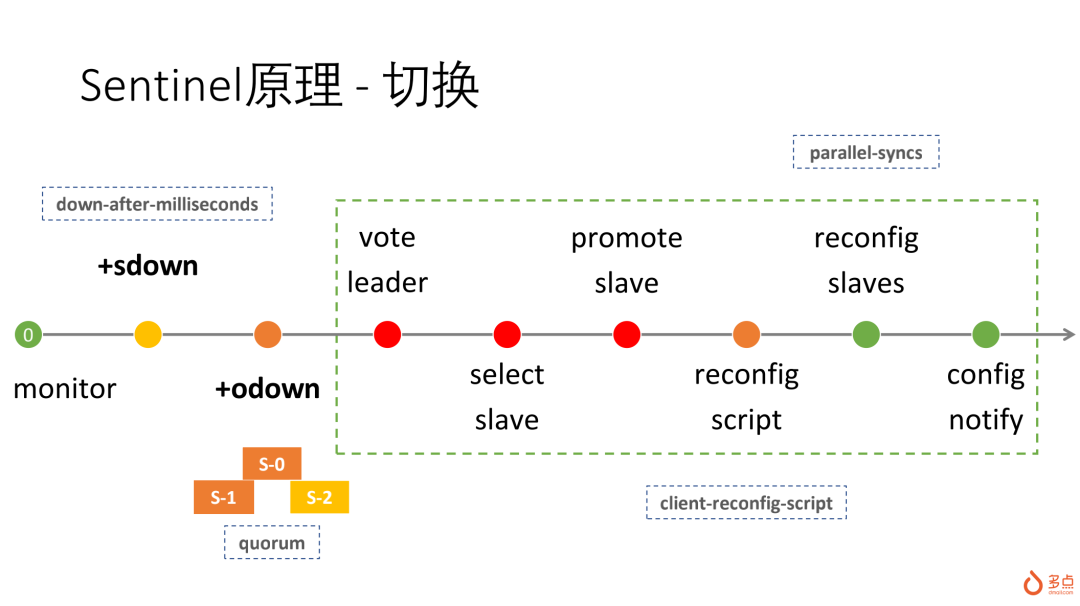
Raft选举在Sentinel中是如何实现的?
具体failover流程,是怎样执行的?
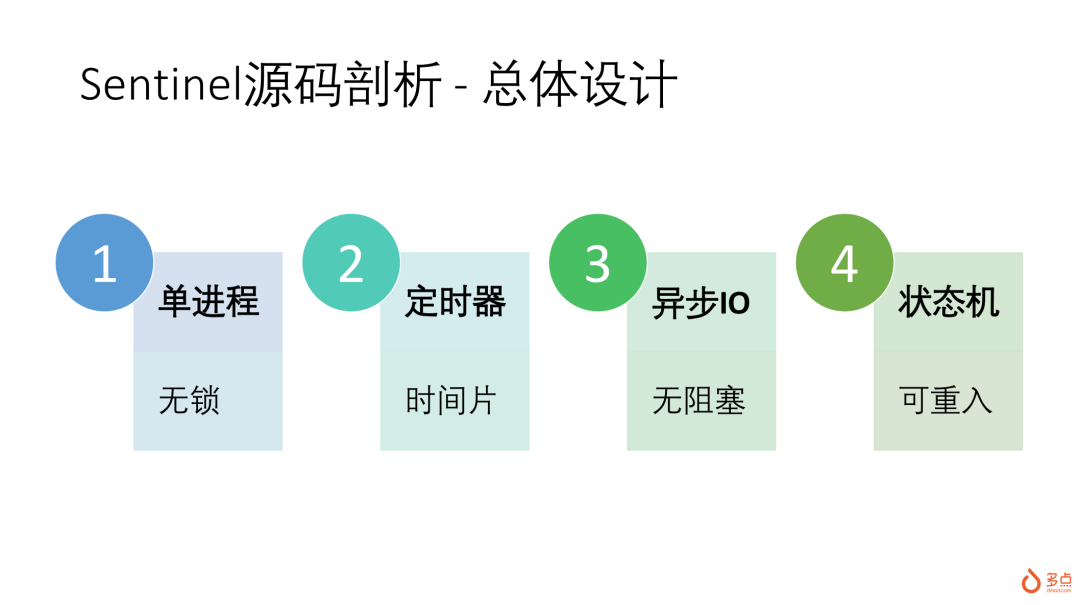
几个特点:
单进程单线程:无锁实现,没有多线程并发编程中非常复杂的lock/unlock,逻辑简单,不容易出错,也容易调试
定时器 + 时间片:将执行拆成一个一个的时间片(50ms ~ 100ms),每个时间片内串行检查监控的每套Redis集群,遇到异常,启动failover流程
异步IO:Sentinel到Master、Slave、及其他Sentinel之间的命令交互,都是异步非阻塞的,在Linux实现中通过epoll_wait方式实现IO多路复用,确保每个时间片内,可以执行完对所有目标Redis集群的操作
状态机:failover操作流程长,步骤多,通过状态机的方式实现可重入,耗时操作可拆解到多个时间片中完成
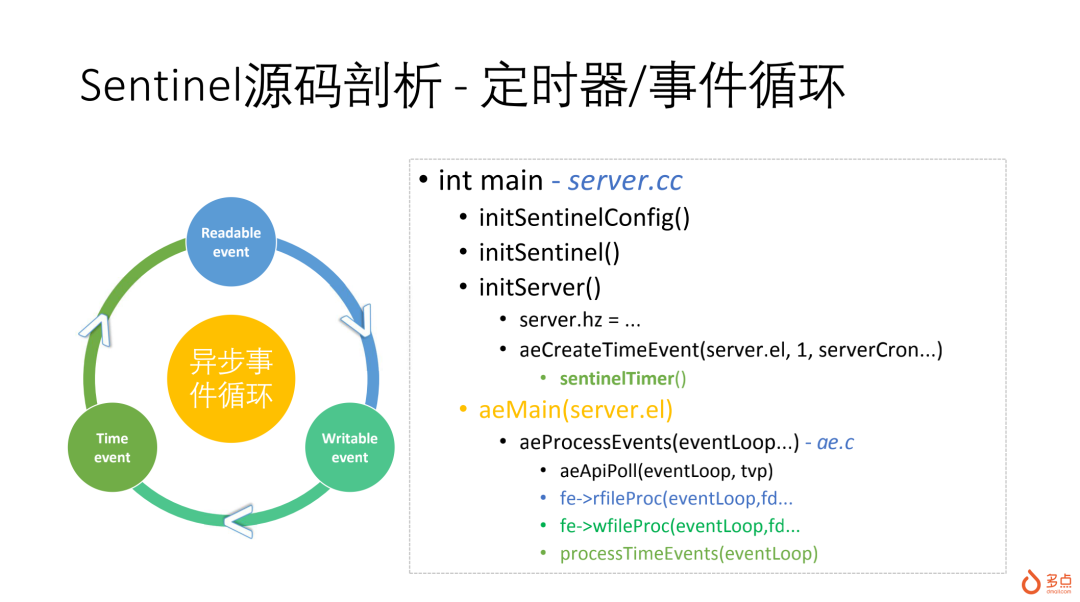

hz是Redis中比较有特色的,它是服务器执行crontab的频率(每秒执行次数),主要处理一些异步后台任务,hz越高,执行越积极,两次调用之间间隔更短,比如:异步清理过期key。在sentinel中,hz在每个时间片后,都会被重新调整成10 ~ 20之间的一个随机数,结果:sentinel两个时间片之间的间隔为50ms ~ 100ms,主要作用是避免多个sentinel节点产生共振,在failover时容易发生脑裂。

sentinel集群对目标Redis进行监控和故障判定是多个节点进行,但在执行failover操作时,必须只能是1个节点,在sentinel发现某个master故障后,会判定为+sdown(subjectively down),然后在得到其他节点的确认后,如果满足大多数,并且达到了配置的quorum,会判定为+odown(objectively down),这时会启动failover流程,failover第一个操作就是raft选举,确定failover leader。

如果发生split vote,选举失败,接下来会在2倍的failover timeout之后重新发起选举,会大大增加故障恢复时间。

时间片1:执行①②,确认了+sdown,向其他节点请求确认
时间片2:执行③④⑤⑥,确认了+odown,启动failover流程,向其他节点发起Leader选举(异步)
时间片3:执行⑦,收集选票,执行failover状态机
时间片4:执行⑧,执行failover状态机
...

Sentinel实践建议

集群规模:推荐3个,quorum配置为2,更大的集群规模在failover Leader选举时,脑裂概率更大
failover-timeout:默认配置180s,在Leader选举发生脑裂时,会引起故障恢复过长,影响线上业务

自定义外部脚本,在两种情况下会被重试:1)执行耗时,超过了60s后被kill;2)脚本以exit 1的方式结束。
sentinel是以fork方式执行外部脚本,最多同时fork出16个子进程,其他的会被放入任务队列中,在接下来的时间片中被调度。
线上问题1:
描述:Redis master宕机后,sentinel正常切换了集群拓扑结构,新master产生了,但是自定义脚本reconfig-script没有被执行,导致dns没切,应用还是尝试连接到已经挂掉的老master节点。
通过info命令排查,发现当时Leader节点出现了脚本任务队列被填满(256),且正在运行的脚本任务数目达到最大(16),通过源码确认:在这种情况下,部分脚本任务会被丢弃,且不产生日志输出。

最终定位问题原因:DBA定义了notify-script,且脚本执行比较耗时,可能超过60s,这就导致任务会被重试,此时触发了sentinel的一个bug
https://github.com/redis/redis/pull/7113(fix(sentinel): sentinel.running_scripts not reset)
当脚本任务被重试时,running_scripts不会下降,所有的新任务不会被调度,而只是加到任务队列中等待被调度,最终导致了上述问题。
线上问题2:
描述:混合云三机房部署Redis集群和Sentinel集群,在1个机房与其他机房中断网络时,failover过程被延迟超过10分钟(+sdown未被及时检测出来)。
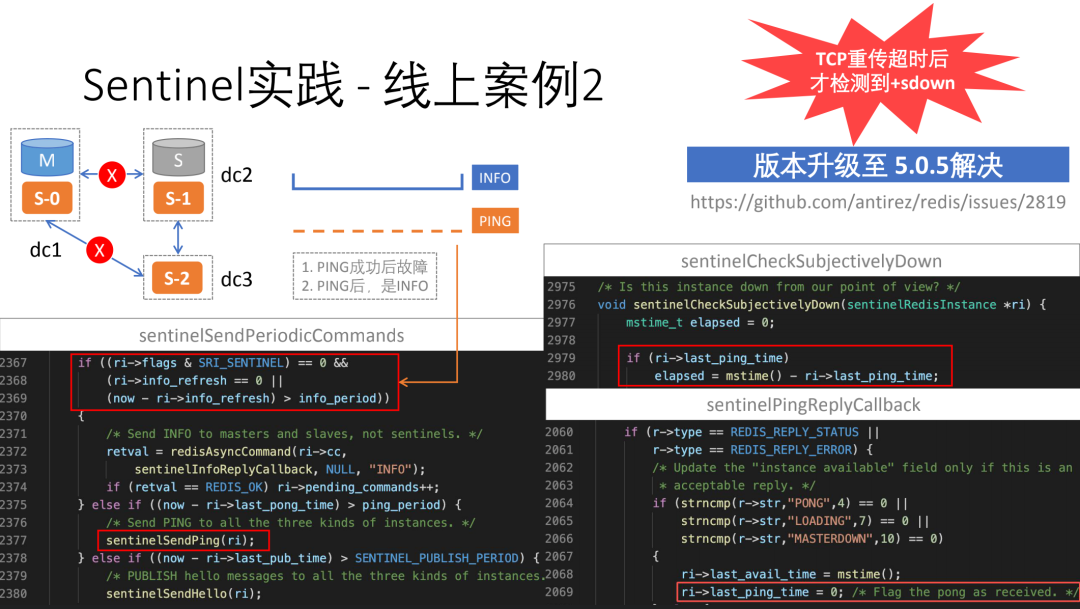
这个问题发生的概率比较小,需要同时满足如下条件:
使用的sentinel版本为3.0.1
sentinel每隔10s向Redis发送INFO命令,获取Redis集群最新拓扑结构,每隔1s向Redis发送PING命令,探测存活状态,上述问题发生在:PING命令成功接收回复,接下来发送的命令是INFO
PING命令成功后,Redis master节点失联
在3.0.1版本中,每轮时间片只会发送INFO/PING/PUBSCRIBE中的其中一种命令,并且对于+sdown的判定存在漏洞,最终,该问题通过升级sentinel版本至5.0.5解决。
亲爱的小伙伴 ,看完这篇文章你有什么收获呢?
,看完这篇文章你有什么收获呢?
欢迎留言
更多知识,扫描二维码
关注Dmall 技术
👇

