





温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
在前面的博文里,我已经介绍了
原创 | 大数据入门基础系列之浅谈Hive和HBase的区别
原创 | 大数据入门基础系列之详谈Hive的数据定义语言(DDL)
原创 | 大数据入门基础系列之详谈Hive的数据操作语言(DML)
原创 | 大数据躺过的坑内部收徒201801期(目前仅面向在校学生)(少量名额)
原创 | 大数据入门基础系列之Hive的驱动器(包括解释器、编译器、优化器、执行器)
原创 | 大数据入门基础系列之Hive驱动器Driver之解释器Parser
原创 | 大数据入门基础系列之Hive驱动器Driver之编译器Compiler
原创 | 大数据入门基础系列之Hive驱动器Driver之优化器optimizer
请回答,90后 | 大数据躺过的坑(九月哥)也是90后的一员...
原创 | 大数据入门基础系列之Hive驱动器Driver之执行器executer
原创 | 大数据入门基础系列之再谈Hive内置的数据类型(另一个角度分析)
敲黑板,划重点
在前面的博文里,我首先详细撰写分享了
Hive复杂类型包括ARRAY, MAP, STRUCT, UNION,这些复杂类型是由基础类型组成的。
见官网
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
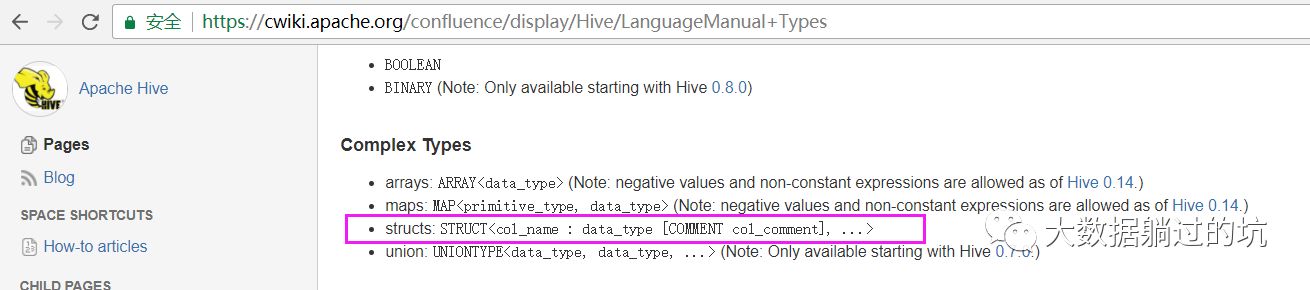
Complex Types
arrays:
ARRAY<data_type>
(Note: negative values and non-constant expressions are allowed as of Hive 0.14.)maps:
MAP<primitive_type, data_type>
(Note: negative values and non-constant expressions are allowed as of Hive 0.14.)structs:
STRUCT<col_name : data_type [COMMENT col_comment], ...>union:
UNIONTYPE<data_type, data_type, ...>
(Note: Only available starting with Hive 0.7.0.)
Hive提供了4种复合数据类型:
在Hive中可以使用复合数据类型,有三种常用的类型:Array 数组,Map 字典,Struct结构。
Structs: structs内部的数据可以通过DOT(.)来存取,例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a。
Maps(K-V对):访问指定域可以通过["指定域名称"]进行,例如,一个Map M包含了一个group-》gid的kv对,gid的值可以通过M['group']来获取。
Arrays:array中的数据为相同类型,例如,假如array A中元素['a','b','c'],则A[1]的值为'b' 。
Unions:UNION将多个SELECT语句的结果集合并为一个独立的结果集。当前只能支持UNION ALL(bag union)。不消除重复行。每个select语句返回的列的数量和名字必须一样,否则,一个语法错误会被抛出。
Struct使用
1) 建表
Hive> create table student_test(id INT, info struct< name:STRING, age:INT>) > ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' > COLLECTION ITEMS TERMINATED BY ':';复制
'FIELDS TERMINATED BY' :字段与字段之间的分隔符。'COLLECTION ITEMS TERMINATED BY' :一个字段各个item的分隔符。
2) 导入数据

$ cat test5.txt 1,zhou:30 2,yan:30 3,chen:20 4,li:80 Hive> LOAD DATA LOCAL INPATH '/home/hadoop/djt/test5.txt' INTO TABLE student_test;复制
3)查询数据
Hive> select info.age from student_test;复制
STRUCT:STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
操作实例
1、创建表
create table student_test(id int,infostruct<name:string,age:int>)
row format delimited fields terminated by ","
collection items terminated by ":";
2、准备文件内容
[root@hello110 data]# vi student_test
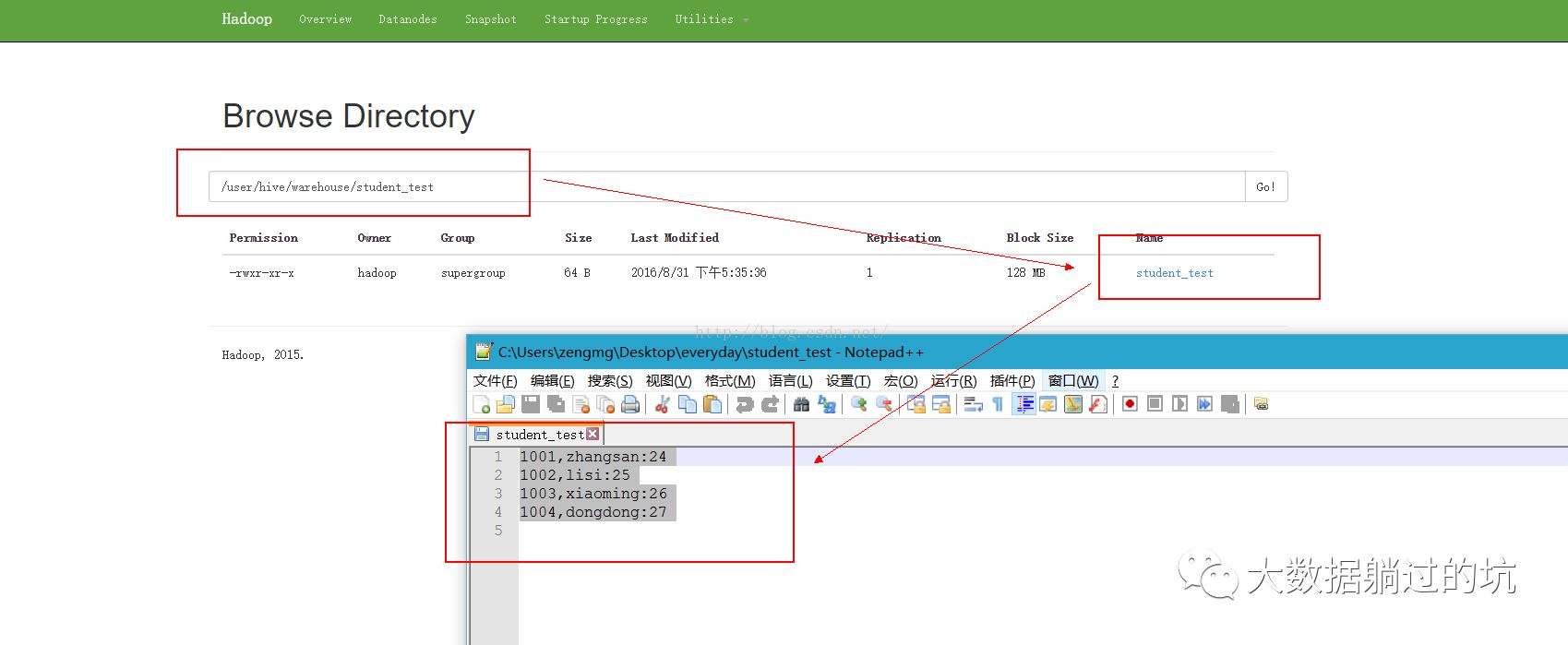
1001,zhangsan:24
1002,lisi:25
1003,xiaoming:26
1004,dongdong:27
3、文件导入表
load data local inpath "/data/student_test" into table student_test;
4、查看表内容
hive (default)> select * from student_test;
OK
student_test.id student_test.info
1001 {"name":"zhangsan","age":24}
1002 {"name":"lisi","age":25}
1003 {"name":"xiaoming","age":26}
1004 {"name":"dongdong","age":27}
Time taken: 2.76 seconds, Fetched: 4 row(s)
---------------------------
hive (default)> select info.name,info.age from student_test;
OK
name age
zhangsan 24
lisi 25
xiaoming 26
dongdong 27
Time taken: 0.294 seconds, Fetched: 4 row(s)
5、hadoop中的文件内容

下一篇是
见明天的
原创 | 大数据入门基础系列之详谈Hive 复合数据类型之映射Maps
同时,大可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
http://www.cnblogs.com/sunnyDream/
以及对应本平台的QQ群:161156071(大数据躺过的坑)

本文版权归(大数据躺过的坑)作者和微信公众平台共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。 如果您认为这篇文章还不错或者有所收获,您可以通过下边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【点赞】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
看完本文有收获?请转发分享给更多人
关注「大数据躺过的坑」,提升大神技能
觉得不错,请点赞和留言↓↓↓
