




今天学习全文检索。
分词:
tsvector
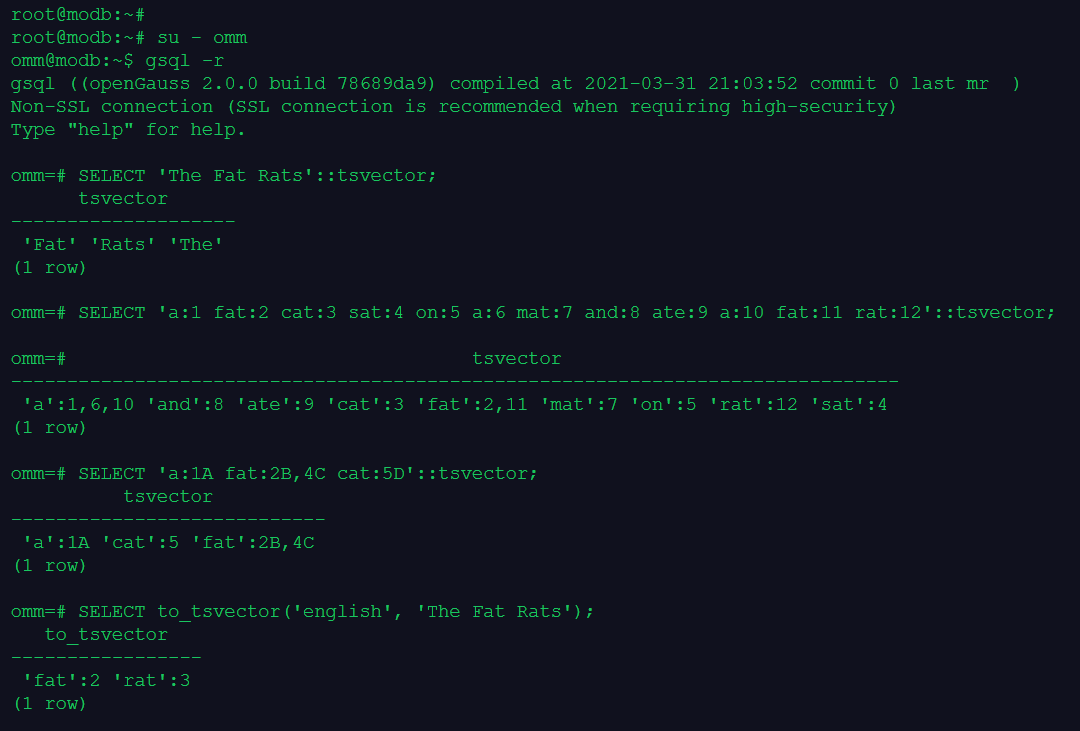
tsquery

SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector @@ 'cat & rat'::tsquery AS RESULT;
SELECT 'fat & cow'::tsquery @@ 'a fat cat sat on a mat and ate a fat rat'::tsvector AS RESULT;
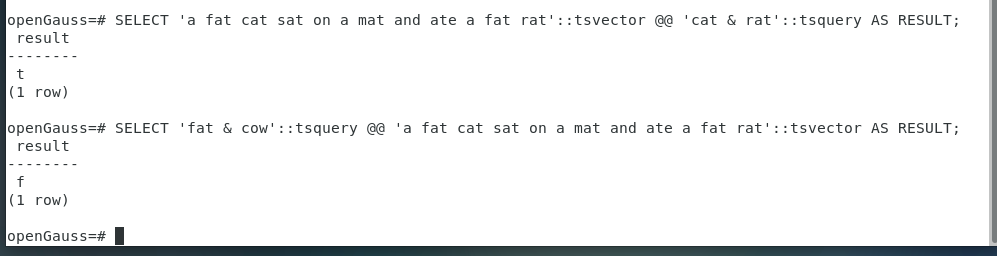
匹配到和没有匹配到。
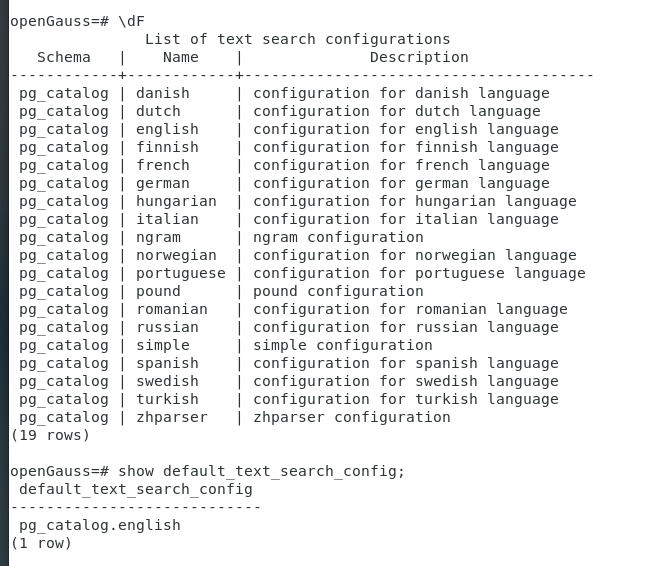
所有的分词器和默认的分词器:
查找body包含america的行

查找title或body中有china和asia的行:

为了加速文本搜索,可以创建GIN索引(指定english配置来解析和规范化字符串)

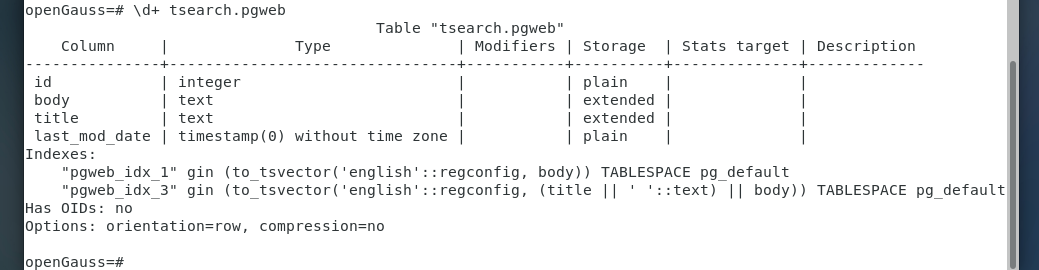
连接列的索引:
CREATE INDEX pgweb_idx_3 ON tsearch.pgweb USING gin(to_tsvector('english', title || ' ' ||
body));

查看索引定义:
drop schema tsearch cascade;

这节课貌似比较难。先去学一下概念:全文检索概述
如果不用全文检索,像satisfies和satisfy这种次不会找出来,派生词也不容易找对。搜索结果无法分类。这将允许通过搜索找到同一个词的不同形式。
全文索引可以对文档进行预处理,包含以下过程:
1.将文档解析成token;
2.将token转换为词素;词素像token一样是一个字符串,但它已经标准化处理,这样同一个词的不同形式是一样的。同时,这一步会删除停用词。
3.保存搜索优化后的预处理文档
tsvector用于存储预处理文档
tsquery用于存储查询条件
文档通常是一个数据库表中一行的文本字段,或者这些字段的可能组合(级联)。1个文档由被索引化的不同部分构成,因此无法存储为一个整体。
为了实现文本搜索目的,必须将每个文档减少至预处理后的tsvector格式。
搜索和相关性排序都是在tsvector形式的文档上执行的。
原始文档只有在被选中要呈现给用户时才会被检索。
全文检索基于匹配算子@@
当一个tsvector(document)匹配到一个tsquery(query)时,则返回true。其中,tsvector(document)和tsquery(query)两种数据类型可以任意排序。
tsquery不仅是文本,且比tsvector包含的要多。tsquery包含已经标注化为词条的搜索词,同时可能是使用AND、OR、或NOT操作符连接的多个术语
开始做作业:
1.用tsvector @@ tsquery和tsquery @@ tsvector完成两个基本文本匹配
SELECT to_tsvector( 'Man Always Remember Love, Becourse Of Romance Only') @@ to_tsquery('Remember & Love') AS RESULT;
SELECT to_tsquery('Remember & Love') @@ to_tsvector( 'Man Always Remember Love, Becourse Of Romance Only') AS RESULT;
2.创建表且至少有两个字段的类型为 text类型,在创建索引前进行全文检索
create schema zhanghui;
create table zhanghui.t1(id int, desc1 text, desc2 text);

insert into zhanghui.t1 values(1,'how many people are there in your family?','There are five people in my family.');
insert into zhanghui.t1 values(2,'how are you?','Fine,thank you. And you?');

select desc1 from zhanghui.t1 where to_tsvector(desc1) @@ to_tsquery('people');

select desc2 from zhanghui.t1 where to_tsvector(desc1) @@ to_tsquery('people');

3.创建GIN索引
create index t1_idx1 on zhanghui.t1 using gin(to_tsvector('english',desc1));
create index t1_idx2 on zhanghui.t1 using gin(to_tsvector('english',desc2));

select desc1 from zhanghui.t1 where to_tsvector(desc1) @@ to_tsquery('you');

select desc1 from zhanghui.t1 where to_tsvector(desc1) @@ to_tsquery('your & family');

4.清理数据
drop schema zhanghui cascade;

