1 初识Vertica
笔者早在2012年之前主要参与运营商网优信令类项目,通过从BTS、BSC、MSC等网络设备侧进行信令数据采用,采用ETL工具对数据进行清洗、转换等,再将数据加载至数据库进行分析,为网管网优提供数据支撑,以优化网络性能、提升网络通话质量等为目标。当时主要采用的架构是Oracle+小型机+高端SAN存储,2G的信令数据相对来说还算比较小,通过在数十TB或百TB级规模,但数据库的处理能力已经可以明显看到瓶颈,如数据加载效率慢,多表关联查询效率低,特别是大表(单表数百亿条记录)的查询效率很低。
随着3、4G业务发展,需要对PS域进行数据分析,如GB,IUPS,GN,DPI等接口数据,每天有接近5TB数据需要入库并进行汇总分析,一个月明细数据达到81TB。数据量的增爆炸式增长也给传统事务型数据库带来了巨大的挑战,已经无法支撑如此大规模的数据加载和分析任务,必须寻求一种新的技术架构来应对这一问题。在对市场开源和商业多个数据库进行了比较后,我们选择了Greenplum和Vertica进行内部测试,在经过模拟实际生产环境的测试后,最终选择了Vertica数据库做为我们系统的核心数据库,于2012年上线了当时国内最大规模的Vertica集群(60节点),所带来的体验可以说是从一条拥堵的城市干道换到了高 速公路:-)。
2 迁移核心数仓
随着业务量及不同维度分析汇总数据的增加,并且随着分析深度、精度要求的进一步提高,中国移动对经分和互联网的大数据分析和处理能力就要求更高。以前基于小型机和高端存储的传统架构在大数据处理方面处理能力不足、横向扩展性差的问题越来越突出,已经无法满足数据分析及快速查询的新要求了。
2.1 背景
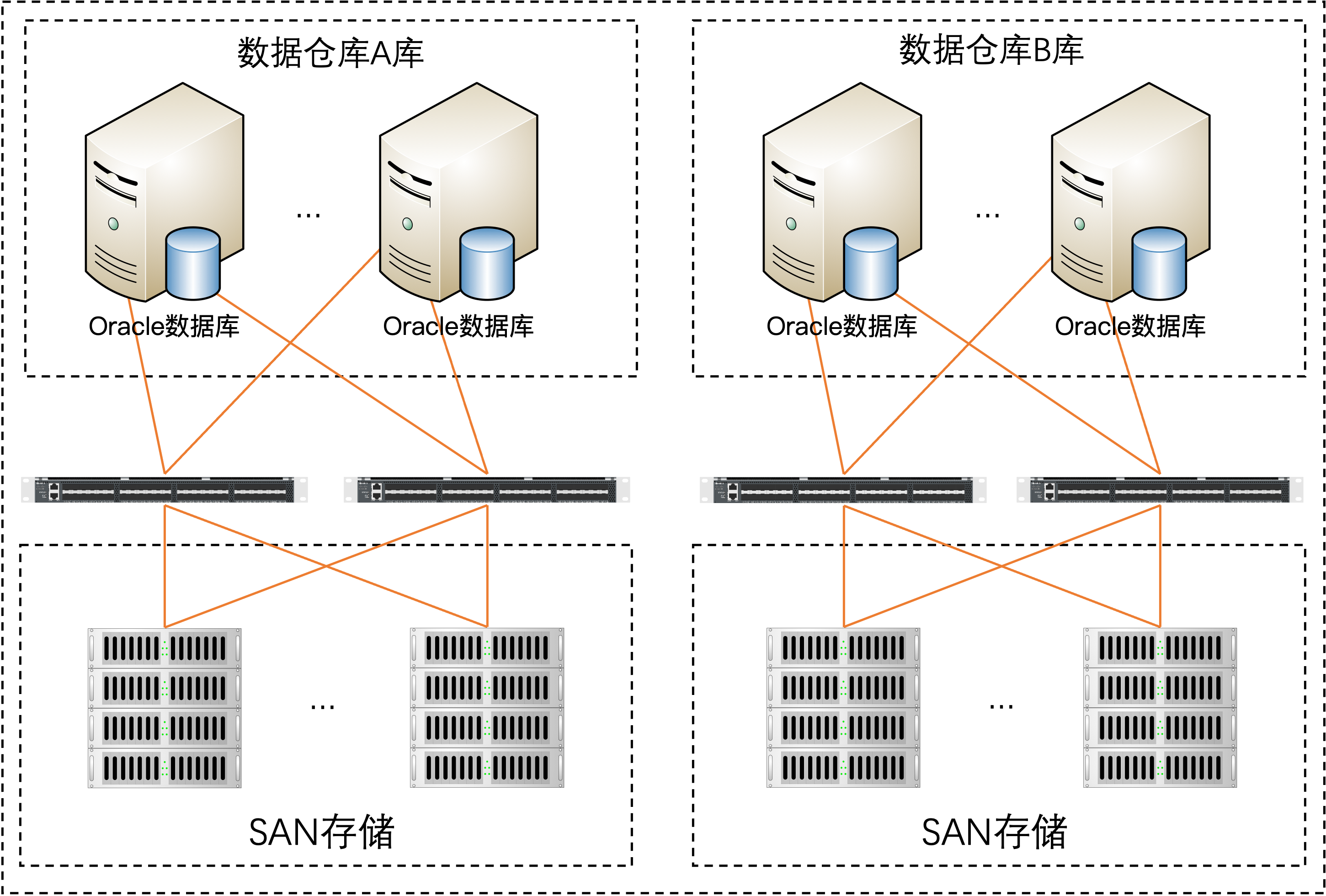
目前经分数据仓库共有小机12台部署Oracle RAC数据库,其中IBM Power780有4台,ia64 HP superdome SD32B有8台,峰时CPU使用率长时间100%。存储方面使用3台HP XP24000和2台HP P9500,经分数据仓库存储在高峰时期性能已经接入存储的理论最大值,常期处在高压力的运行状况下。
系统整体存在以下问题:
1、数据存储周期不够
现有的在线数据存储能力落后于市场精细化经营分析需求。分析历史数据需要采用磁带库恢复到数据库的模式, 在恢复时需要事先清理其他周期的数据,恢复一个历史周期的数据需要约一周时间,影响支撑效率。另外随着4G业务开展,用户业务使用量增长迅速,其中数据业务清单数据增速为36%。现有数据仓库的存储模式无法支撑快速增长的业务数据存储要求。
2、系统资源高位运行
现有系统CPU资源消耗忙时长时间接近100%,磁盘IO长时间100%,硬件资源的潜力已经挖尽。
3、现有架构无法扩容
目前数据仓库架构采用多台小型机RAC加共享存储模式,横向扩展能力不足,小型机相关端口已处于满配状态,无法扩容新存储;共享的RAC模式下主机节点间通讯流量随主机数量增多成指数上升,已经达到当前技术能力支持的上限而无法继续扩容主机。
4、现有架构维保费用高
数据仓库主机和存储均已过保,维保费用非常高
2.2 方案实现
Vertica数据库基于无共享的MPP架构,节点完全对等,所有节点均可响应查询和数据加载请求,支持在线添加数量X86工业标准服务器,可根据需求任意扩展解决方案;通过列式计算和强大的主动数据压缩,大幅降低磁盘I/O;支持关系数据库事务处理和ACID规范,支持SQL-92和SQL-99标准,提供ODBC、JDBC、ADO.NET接口规范驱动,完全兼容传统关系数据库的开发、使用和管理习惯;在查询性能方面,速度比传统数据库快50~1000倍,同时消耗的成本和占用的硬件仅有原来的几分之一;Vertica采用K-safety机制来保障集群的高可用,类似RAID功能,且具有数据复制、故障转移和恢复功能。针对大规模集群,Vertica原生支持容错组和机架感知,数据跨容错组分布,即使一个容错组发生故障,也可保证整个数据库的数据完整性,从而可以有效避免机柜掉电等大规模硬件故障对整个集群的可用性影响(虽然这种概率极低,但笔记在2017年一个银行项目中也碰到过,这也充分验证了Vertica的高可用性)。
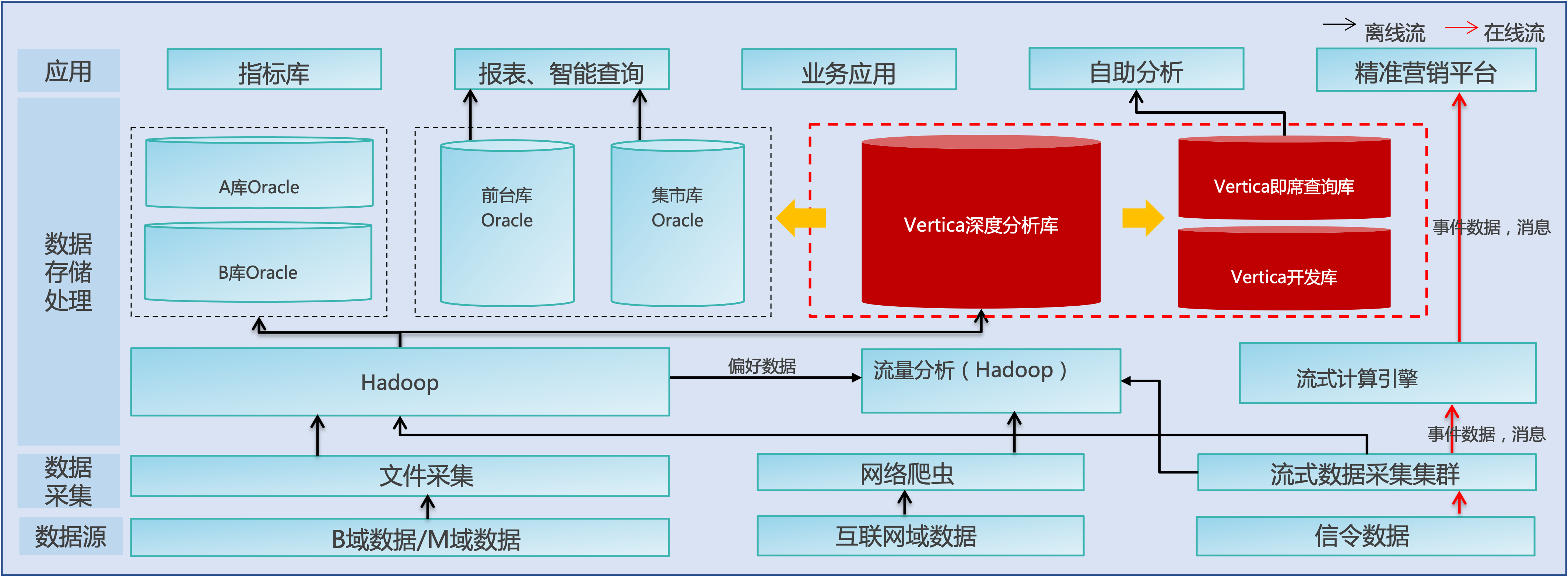
于2016年采用93台x86服务器搭 建Vertica数据库集群对经分核心数据仓库进行迁移,将6万+模型、1.8万+个程序、1.7万+存储过程、11万+应用程序适配至Vertica数据库,迁移过程中以HDFS为数据交互中转站,将外部系统数据先上传至HDFS,再通过调度工具将HDFS中的文件并行加载至Vertica数据库,在Vertica库进行汇总和分析生成基础汇总层数据,再进行高度汇总,生成相关报表数据。另分别采用32台x86服务器搭建Vertica即席查询库和开发库。
针对Oracle数据库中存在大量存储过程,通过将存储过程“翻译”成perl脚本,调度工具通过ODBC连接Vertica数据库进行作业调度。迁移后各数据源统一经过Hadoop,再通过并行加载方式直接写入Vertica数据库。
注:Vertica 11.0版本支持存储过程(PL/vSQL),在很大程度上与PostgreSQL PL/pgSQL 兼容,只有细微的语义差异。
2.3 迁移后收益
迁移后Vertica做为该省大数据平台B域数据计算中心,承担B域轻度汇总、高度汇总计算任务,按周期存储B域的汇总模型,并对其他各库进行数据分发。
- 投资降低
通过x86化部署Vertica数据库,逐步将Oracle小机+高端阵列的数据仓库给予下线,降低系统整体采购及维护成本约60%。
- 性能提升
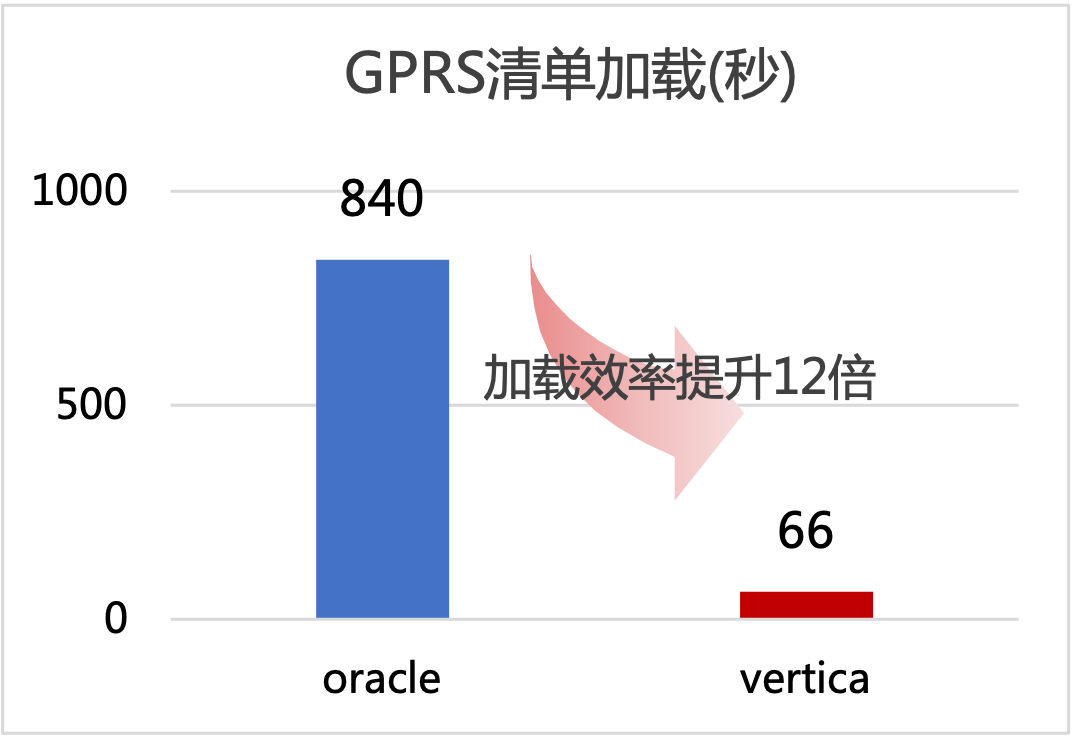
以加载某地市GPRS清单接口为例:加载到Oracle数据库,用时840秒;加载到Vertica数据库,用时66秒。数据加载效率提升12倍,大数据平台接口数据加载效率显著提升。
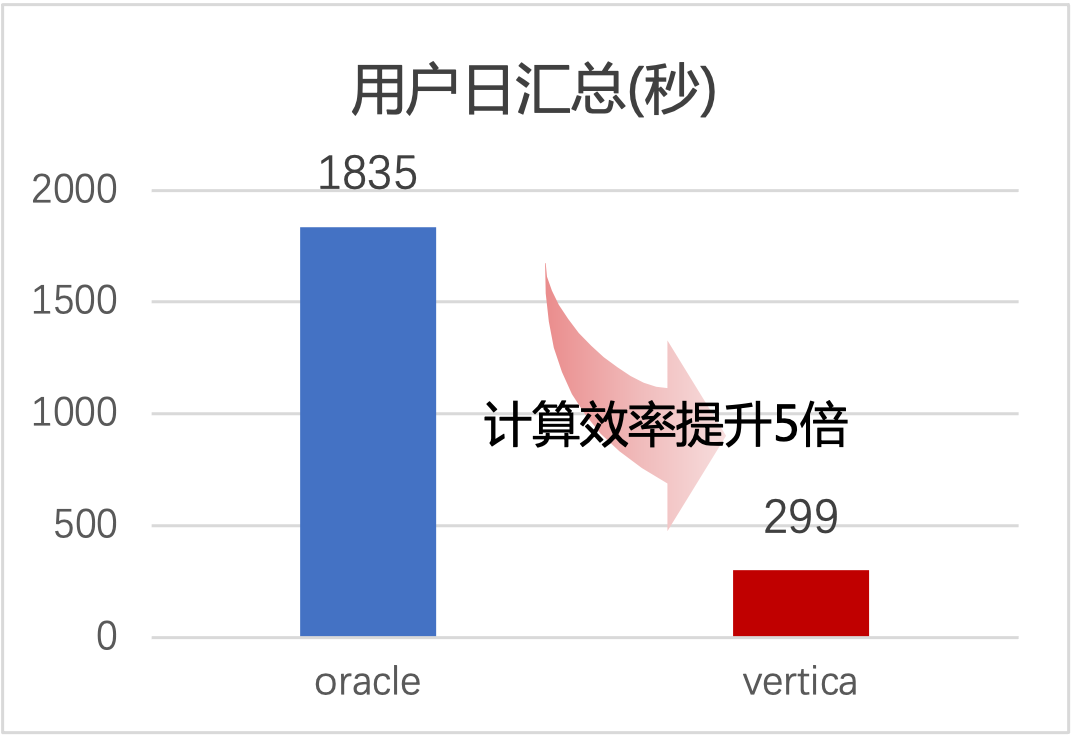
以用户日数据汇总分析为例:Oracle汇总分析用时1835秒;Vertica汇总分析用时299秒。汇总分析效率提升5倍,大数据平台数据分析能力得到很大提升。
3 展望:构建统一大数据分析平台
笔者在所参与过的项目中,经分核心数据仓库软件一般采用Oracle、DB2、Teradata,大多采用小型机+高端存储架构,也有部分采用一 体机案例,由于计算存储能力不足、横向扩展性差、维保费用高、跨代扩容兼容性等问题,各运营商正逐步开始往MPP数据库进行迁移。在对经分核心数仓等系统迁移至MPP数据库后,各业务场景需求不断增加、对多域数据融合计算的需求,以及系统扩容、故障恢复、高并发等需求,大数据平台的一些问题在逐渐突显出来:
-
多个系统采用多个数据库平台,如B域仓库、集市、自助分析,O域仓库等,如果需要跨域进行数据分析,则需要在不同库之间进行同步数据,同步所消耗的时间也带来数据分析时效性的降低。
-
各系统之间存在较多数据冗余,如B域集市、自助分析、标签库等数据均来源于B域数据仓库,一般冗余量约为30%左右。
-
需要接入更多的使用场景(如自助分析、模型探索、机器学习等),对高并发、资源隔离提出更高的要求。
-
传统MPP架构下硬件故障需要较长时间进行节点恢复,也带来了用户体验降低,特别是节点磁盘故障导致单节点数据丢失的情况。
-
数据、业务不断的增长将需要更多的计算和存储能力,系统需要更高的弹性伸缩能力。
-
计算能力、存储能力满足不了业务需求需要扩容,扩容设备配置往往会高于初期配置,导致新扩容设备存在一定资源浪费。
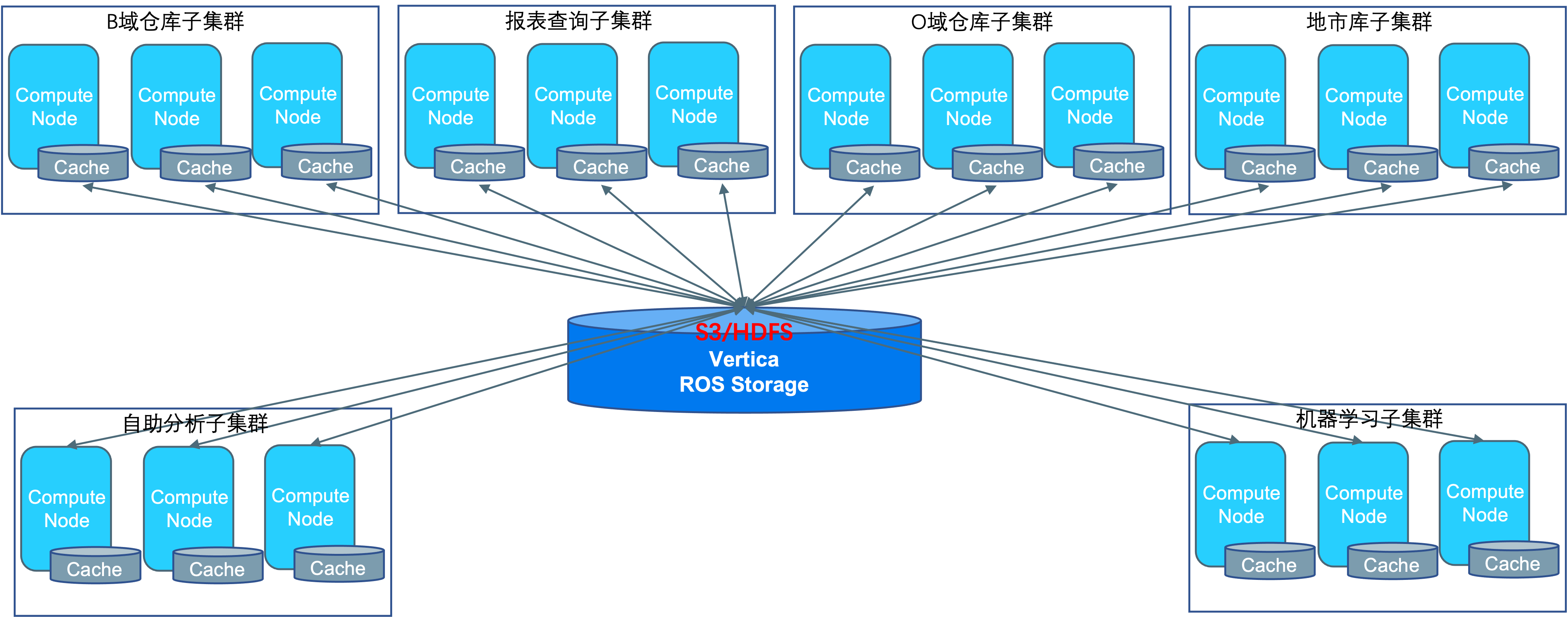
在Vertica 9.0版本之后,Vertica发布了新一代MPP存储计算分离架构(Eon),计算节点只缓存最近需要使用的数据,底层存储采用S3对象存储或HDFS,这将可以很好解决以上问题。
-
不同业务系统采用不同的计算子集群、数据集中存储在公共存储中,既可解决计算资源快速扩容、资源隔离、快速恢复等问题,在数据融合存储后也可以解决数据冗余冗余问题,
-
数据集中存储后,各业务系统可使用使用同一份数据,不需要进行数据同步。
-
对于O域这类高存储容量、相对较低计算需求的场景,可以采用高压缩算法,进一步压缩存储空间,节省硬件成本。
-
对于跨域融合数据分析需求,数据集中存储在公共存储后,不同业务系统访问跨域数据时,只需要对相应表进行赋权即可,同时Vertica的行列访问策略可以更精细的控制数据的访问权限。
-
通过对跨代硬件使用不同的子集群为不同业务场景提供计算服务,来提升硬件使用周期。
通过采用Vertica 新一代存储计算分离架构(Eon)对多域数据融合建设,软、硬件投资或将进一步降低,并为用户提供一个统一大数据分析平台。