




1 备份恢复
1.1 备份恢复的方式
1.1.1 PG备份恢复方式主要分为两类
1.1.1.1 逻辑备份恢复
pg_dump 可以选择一个数据库或部分表进行备份
pg_dumpall 备份集簇服务所有数据库
copy 导入导出表数据
COPY 命令是SQL命令,\copy命令是元命令。
COPY 命令必须具有SUPERUSER超级权限(将数据通过stdin/stdout方式导入导出情况除外),而 \copy 元命令不需要SUPERUSER权限。
COPY 命令读取或写入数据库服务端主机上的文件,而 \copy 元命令是从psql客户端主机读取或写入文件。
从性能方面看, 大数据量导出文件或大文件数据导入数据库,COPY 比 \copy 性能高。
1、 将文件中的数据复制到表中:
COPY table_name [ ( column_name [, ...] ) ]
FROM { 'filename' | PROGRAM 'command' | STDIN }
[ [ WITH ] ( option [, ...] ) ]
2、将表中的数据复制到文件中:
COPY { table_name [ ( column_name [, ...] )] | ( query ) }
TO{ 'filename' |PROGRAM 'command' | STDOUT }
[[ WITH ] ( option [, ...] ) ]
1.1.1.2 物理备份恢复
冷备份及恢复(文件系统复制)
热备份及恢复(基于时间点的备份恢复)
1.2 逻辑备份与恢复
1.2.1 逻辑备份
1.2.1.1 pg_dump
可以选择一个数据库或部分表进行备份,恢复过程可以跨平台迁移
可以在数据库正在使用时进行完整一致的备份,并不阻塞其它用户对数据库的访问
只能备份单个数据库,不会导出角色和表空间相关的信息
pg_dump --help
-F c 备份为二进制格式, 压缩存储.并且可被pg_restore用于精细还原
-F p 备份为文本, 大库不推荐
示例:
pg_dump --table=tbl -d db
pg_dump --schema=scm -d db
pg_dump --file=postgres.sql --blobs--schema=public --dbname=postgres --host=127.0.0.1 --port=5432 --username=postgres
psql -h 127.0.0.1 -p 5433 -U postgres -dpostgres -f postgres.sql
pg_dump 把一个数据库转储为纯文本文件或者是其它格式.
用法:
pg_dump [选项]... [数据库名字]
一般选项:
-f,--file=FILENAME 输出文件或目录名
-F,--format=c|d|t|p 输出文件格式 (定制, 目录, tar)
明文 (默认值))
-j,--jobs=NUM 执行多个并行任务进行备份转储工作
-v,--verbose 详细模式
-V,--version 输出版本信息,然后退出
-Z,--compress=0-9 被压缩格式的压缩级别
--lock-wait-timeout=TIMEOUT 在等待表锁超时后操作失败
--no-sync donot wait for changes to be written s
-?,--help 显示此帮助, 然后退出
控制输出内容选项:
-a,--data-only 只转储数据,不包括模式
-b,--blobs 在转储中包括大对象
-B,--no-blobs exclude largeobjects in dump
-c,--clean 在重新创建之前,先清除(删除)数据库对象
-C,--create 在转储中包括命令,以便创建数据库
-E,--encoding=ENCODING 转储以ENCODING形式编码的数据
-n,--schema=SCHEMA 只转储指定名称的模式
-N,--exclude-schema=SCHEMA 不转储已命名的模式
-o,--oids 在转储中包括 OID
-O,--no-owner 在明文格式中, 忽略恢复对象所属者
-s,--schema-only 只转储模式, 不包括数据
-S,--superuser=NAME 在明文格式中使用指定的超级用户名
-t,--table=TABLE 只转储指定名称的表
-T,--exclude-table=TABLE 不转储指定名称的表
-x,--no-privileges 不要转储权限 (grant/revoke)
--binary-upgrade 只能由升级工具使用
--column-inserts 以带有列名的INSERT命令形式转储数据
--disable-dollar-quoting 取消美元 (符号) 引号, 使用 SQL 标准引号
--disable-triggers 在只恢复数据的过程中禁用触发器
--enable-row-security 启用行安全性(只转储用户能够访问的内容)
--exclude-table-data=TABLE 不转储指定名称的表中的数据
--if-exists 当删除对象时使用IF EXISTS
--inserts 以INSERT命令,而不是COPY命令的形式转储数
--no-publications donot dump publications
--no-security-labels 不转储安全标签的分配
--no-subscriptions do not dump subscriptions
--no-synchronized-snapshots 在并行工作集中不使用同步快照
--no-tablespaces 不转储表空间分配信息
--no-unlogged-table-data 不转储没有日志的表数据
--quote-all-identifiers 所有标识符加引号,即使不是关键字
--section=SECTION 备份命名的节 (数据前, 数据, 及 数据后)
--serializable-deferrable 等到备份可以无异常运行
--snapshot=SNAPSHOT 为转储使用给定的快照
--strict-names 要求每个表和/或schema包括模式以匹配至少
--use-set-session-authorization
使用 SESSION AUTHORIZATION 命令代替
ALTER OWNER 命令来设置所有权
联接选项:
-d,--dbname=DBNAME 对数据库 DBNAME备份
-h,--host=主机名 数据库服务器的主机名或套接字目录
-p,--port=端口号 数据库服务器的端口号
-U,--username=名字 以指定的数据库用户联接
-w,--no-password 永远不提示输入口令
-W,--password 强制口令提示 (自动)
--role=ROLENAME 在转储前运行SET ROLE
pg_dump仅导出数据库结构:
pg_dump -U TestRole1 -s -f TestDb1.sqlTestDb1
备份某个database,备份结果以自定义压缩格式输出:
pg_dump -h localhost -p 5432 -U someuser -Fc -b -v -f mydb.backup mydb
备份某个database,备份结果以SQL文本方式输出,输出结果中需包括CREATEDATABASE语句:
pg_dump -h localhost -p 5432 -U someuser -C-F p -b -v -f mydb.backup mydb
备份某个database中所有名称以“pay”开头的表,备份结果以自定义压缩个数输出:
pg_dump -h localhost -p 5432 -U someuser -Fc -b -v -t *.pay* -f pay.backup mydb
备份某个database中hr和payroll这两个schema中的所有数据,备份结果以自定义压缩格式输出:
pg_dump -h localhost -p 5432 -U someuser -Fc -b -v -n hr -n payroll -f hr_payroll.backupmydb
备份某个database中除了public schema中的数据以外的所有数据,备份结果以自定义压缩格式输出:
pg_dump -h localhost -p 5432 -U someuser -Fc -b -v -N public -f all_sch_except_pub.backupmydb
1.2.1.2 pg_dumpall
由超级用户执行备份整个集簇、数据库,包括角色和表空间
生成psql脚本,pg_dumpall 只支持文本格式
它在内部调用pg_dump
pg_dumpall -f dump
pg_dumpall --help
参数选项
-data-only 提供没有对象定义的数据转储
-globals-only 备份转储角色和表空间
-clean 包括删除数据库,角色和表空间
建议每天对角色和表空间定义等全局对象进行备份,但不建议每天使用pg_dumpall来备份全库数据,因为pg_dumpall仅支持导出为SQL文本格式,而使用这种庞大的SQL文本备份来进行全库级别的数据库恢复时及其耗时的,所以一般只建议使用pg_dumpall来备份全局对象而非全库数据。
pg_dumpall可实现仅备份角色和表空间定义:
pg_dumpall -h localhost -U postgres --port=5432-f myglobals.sql --globals-only 如果仅需备份角色定义而无需备份表空间,那么可以加上--roles-only选项:
pg_dumpall -h localhost -U postgres --port=5432-f myroles.sql --roles-only
1.2.2 逻辑恢复
文本格式的备份文件, 直接使用用户连接到对应的数据库执行备份文本;
psql dbname -f filename
psql dbname -U username < filename
二进制格式的备份文件只能使用pg_restore来还原;可以指定还原的表, 编辑TOC文件, 定制还原的顺序, 表, 索引等;
pg_restore [option] ... [filename]
pg_restore -d dbname bakfile
pg_dump--host=127.0.0.1 --port=5432 --dbname=postgres --schema=public--username=postgres --format=c --encoding=UTF8 --file= file.backup --password--blobs --inserts --column-inserts --table=
pg_restore -U user -d database file.backup>a.txt 2>&1
psql -d database-h IP -p 5432 -U user -f file.sql
1.2.2.1 逻辑备份恢复示例
pg_dump备份恢复示例
1)创建数据库
createdb testdb
2)连入数据库testdb
psql testdb1
3)创建测试表,插入数据
testdb=# create table tt(a int) tablespacetbls_t;
testdb=# insert into tt(a) values(1);
testdb=# insert into tt(a) values(2);
4)查看数据
testdb=# select * from tt;
5)备份
pg_dump testdb1>/dbbak/testdb.sql #简单语法,可结合选项灵活备份
6)删除数据库testdb
dropdb testdb
7)创建新数据库(恢复之前需创建数据库)
createdb testdb1
8)恢复数据
psql testdb1 </dbbak/testdb.sql
9)查看数据是否回复
psql testdb
testdb=# select * from tt;
1.2.3 pg_dump扩展练习
备份选项控制备份
#二进制格式备份文件
pg_dump -F c -f db1.dmp -C -E UTF8 -h127.0.0.1 -U postgres db1
#文本格式备份文件
pg_dump -F p -f /dbbak/p.dmp -C -E UTF8 -h 127.0.0.1 -Upostgres testdb
-F c 备份为二进制格式, 压缩存储. 并且可被pg_restore用于精细还原
-F p 备份为文本, 大库不推荐.
-C include commands to create database in dump
不同格式的恢复
pg_restore /dbbak/testdb.dmp|less # 可以解析二进制格式的备份文件
pg_restore -l /dbbak/testdb.dmp #生成二进制备份集合的TOC列表
pg_restore -d testdb1 /dbbak/testdb.dmp #需要先创建目标库
psql -d testdb2 < /dbbak/p.dmp
1.2.4 pg_dump扩展示例
1.生成toc文件进行选择性恢复
1)根据二进制备份文件生成toc文件
pg_restore -l -f /dbbak/toc1/dbbak/testdb.dmp
2)修改 toc文件,以首行加分号“;”的方式注释掉不用还原的内容
3)以toc文件列表做恢复
pg_restore -Fc -L /dbbak/toc -d testdb/dbbak/testdb.dmp
-l --list
列出归档的内容的表格。这个操作的输出能被用作-L选项的输入。注意如果把-n或-t这样的过滤开关与-l一起使用,它们将会限制列出的项。
-f filename
--file=filename
为生成的脚本指定输出文件,或在与-l选项一起使用时为列表指定输出文件。为 stdout用 -。
2.使用unix管道备份恢复
pg_dump testdb| gzip >/dbbak/testdbbak.sql.gz
gunzip -c /dbbak/testdbbak.sql.gz | psqltestdb2
pg_dump testdb | psql testdb1
3.并行处理
pg_dump -Fd -j4 -f /dbbak/db.dir testdb
pg_restore -d testdb3 -j4 /dbbak/db.dir
-j参数指定同时几个进程来同时执行,每个进程同时只处理一个表的数据。
使用pg_dump的directory-format 对应选项 -Fd
使用pg_dump的custom-format
-j参数指定并发的数量(job),pg_restore恢复custom-format格式也可以使用此参数,并非只适用directory-format
file toc.dat
cat toc.dat
cat 2866.dat.gz |gunzip
一个表对应一个标号文件
select oid from pg_class whererelname='pitr_test';
1.2.5 COPY命令
copy 命令用于表与文件(和标准输出,标准输入)之间的相互拷贝;
copy to由表至文件,copy from由文件至表;
copy 命令是到数据库服务端找文件,以超级用户执行导入导出权限,适合数据库管理员操作;
\copy 命令在客户端执行导入客户端的数据文件,权限要求没那么高,适合开发,测试人员使用;
copy与\copy 命令都能实现数据文件与表的数据传递,两者都在psql环境下执行
1.3 物理备份与恢复
1.3.1 冷备份恢复
使用操作系统支持的各种拷贝命令,把整个 PGDATA备份。
冷备份前,建议干净的关闭数据库(pg_ctlstop -m fast)。
在同架构同平台同数据库版本的迁移需求中,使用该方式,且极大节省迁移时间,且操作简单,安全性高。
备份示例:tar -jcv -f /home/postgres/bak/dbbak0817.tar.bz2$PGDATA
恢复示例:tar -jxv -f/home/postgres/bak/dbbak0817.tar.bz2 -C /
1.3.2 在线热备份恢复原理
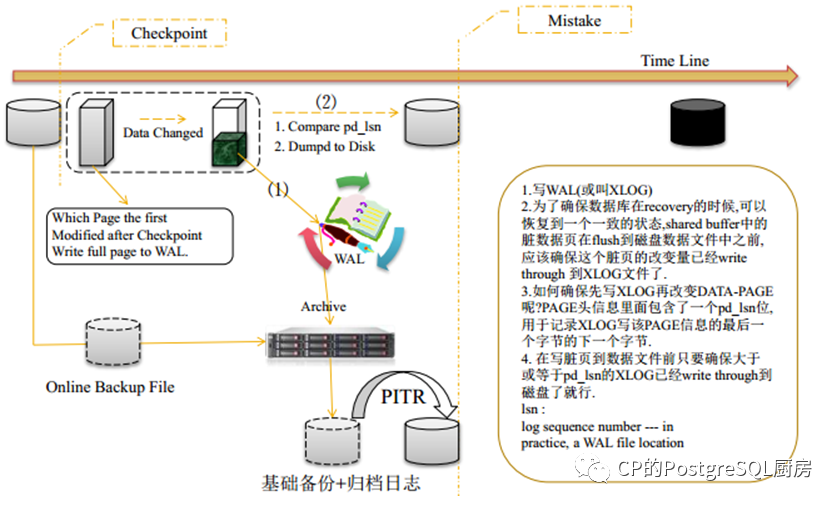
运用在线备份以及即时恢复(PITR)原理,利用Postgresql 数据库的WAL(Write Ahead Logging )预写日志和基础备份( $PGDATA目录文件tar包 ),恢复到数据库崩溃前时间点,保证数据量最少丢失或者不丢失.
如果数据库崩溃,我们就可以通过热备产生的备份文件data_bak.tar包 ($PGDATA目录文件tar包)和archive_command产生的WAL及我们自己备份的WAL(pg_xlog)来进行数据库的 recovery 。
1.3.3 在线热备份的三种实现方式
1.3.3.1 pg_basebackup
pg_basebackup 简介
是从postgresql 9.1版本开始提供的一个方便基础备份的工具
它会把整个数据库实例的数据都拷贝出来,而不只是把实例中的部分(如某个数据库或表)单独备份。
注意:归档日志需要单独备份
pg_basebackup工作原理
1)创建检查点,打开FPW,创建备份标签(存储检查点位置,时间等信息)
2)通过流复制协议与数据库建立连接,WAL Sender进程向pg_basebackup发送数据库物理文件。
3)pg_basebackup接收到文件后写入目标位置(压缩或不压缩)。
pg_basebackup 参数说明
可以通过pg_basebackup --help 详细查看
-h 指定连接的数据库的主机名或IP地址,这里就是主库的ip。
-U 指定连接的用户名,此处是我们刚才创建的专门负责流复制的repl用户。
-F 指定了输出的格式,支持p(原样输出)或者t(tar格式输出)。
-x 表示备份开始后,启动另一个流复制连接从主库接收WAL日志。
-P 表示允许在备份过程中实时的打印备份的进度。
-R 表示会在备份结束后自动生成recovery.conf文件,这样也就避免了手动创建。
-D 指定把备份写到哪个目录,这里尤其要注意一点就是做基础备份之前从库的数据目录($PGDATA)目录需要手动清空。
-l 表示指定一个备份的标识
1.3.3.2 pg_basebackup实验
pg_basebackup 备份过程:
1)开启归档
创建归档目录
mkdir -p /opt/arch
chown -R postgres:postgres /opt/arch
配置归档命令
vi $PGDATA/postgresql.conf
archive_mode = on
archive_command = 'DATE=`date +%Y%m%d`;DIR="/opt/arch/$DATE"; (test -d $DIR || mkdir -p $DIR) && cp%p $DIR/%f'
wal_level = replica
wal_level决定多少信息写入到 WAL 中。默认值是replica,它会写入足够的数据以支持WAL归档和复制,包括在后备服务器上运行只读查询。minimal会去掉除从崩溃或者立即关机中进行恢复所需的信息之外的所有记录。minimal, replica, orlogical
在 9.6 之前的版本中,这个参数也允许值archive和hot_standby。现在仍然接受这些值,但是它们会被映射到replica。
注释:
%p 表示wal文件名$PGDATA的相对路径, 如pg_wal/00000001000000190000007D
%f 表示wal文件名, 如00000001000000190000007D
2)重启数据库使参数生效,验证归档。
checkpoint; #备注1
select pg_switch_wal();
[root@pg01 20211124]# pwd
/opt/arch/20211124
[root@hgdb01 20211124]# ls
000000020000000000000003 000000020000000000000004
3)创建replication权限的角色, 或者超级用户的角色。
create role repl nosuperuser replicationlogin connection limit 32 encrypted password '111111';
4)配置pg_hba.conf,添加以下内容
------
host replication repl 0.0.0.0/0 md5
------
5)执行备份(因为使用流复制协议, 所以支持异地备份)
pg_ctl reload #执行加载配置的命令
mkdir `date +%F` ;
pg_basebackup -Ft -v -P -D/home/postgres/bak/`date +%F` -h IP地址 -p 5432 -U repl
6)备份完毕,查看备份文件
[postgres@hgdb01 ~]$ cd/home/postgres/bak/2021-11-24
postgres@pg01-> ll
total 115M
-rw-rw-r-- 1 postgres postgres 99M Nov 2403:04 base.tar
-rw------- 1 postgres postgres 17M Nov 2403:04 pg_wal.tar
[postgres@hgdb01 2021-11-24]$ tar -tvf base.tar |less #查看备份包内容
backup_label
pg_start_backup,会生成 backup_label文件。pg_stop_backup,会删除backup_label文件。
而如果StartupXLOG函数运行时,发现了backup_label文件,那么意味着它处正在从onlinebackup中恢复的过程中。
pg_start_backup执行下列4个操作:
强制进入整页写入模式。
切换到当前的WAL段文件(8.4或更高版本)。
执行检查点。
创建backup_label文件—— 该文件创建于基本目录顶层中,包含有关该基本备份本身的关键信息,如检查点的检查点位置。
第3个和第4个操作是该命令的核心。第1和第2个操作是为了更可靠地恢复数据库集簇。
备份标签backup_label文件包含以下7个项目:
1.检查点位置 ——该命令所创建检查点的LSN位置。
2.WAL开始位置——这不是给PITR用的,流复制用的。它被命名为START WALLOCATION,因为复制模式下的备用服务器在初始启动时只读取一次该值。
3.备份方法——这是用于进行此基本备份的方法,如pg_start_backup或pg_basebackup。
4.备份来源 ——说明此备份是从主库还是备库拉取。
5.开始时间 ——这是执行pg_start_backup时的时间戳。
6.备份标签 ——这是pg_start_backup中指定的标签。
7.开始时间线 ——这是备份开始的时间线,为了进行正常的检查,在版本11.0中被引入。
1)停止数据库并删除数据目录,将pg_basebackup生成的备份包分别解压到相应目录
[root@pg012021-11-24]# tar -xvf base.tar -C /opt/pg_root
[root@pg012021-11-24]# tar -xvf pg_wal.tar -C /opt/pg_root/pg_wal
2)recovery.conf文件配置还原参数
$cp $PGHOME/share/recovery.conf.sample$PGDATA/recovery.conf
vi $PGDATA/recovery.conf #备注
restore_command = 'cp /opt/arch/20211124/%f%p'
recovery_target_timeline = 'latest'
3)启动数据库并做数据查看验证是否恢复完成
pg_ctl start
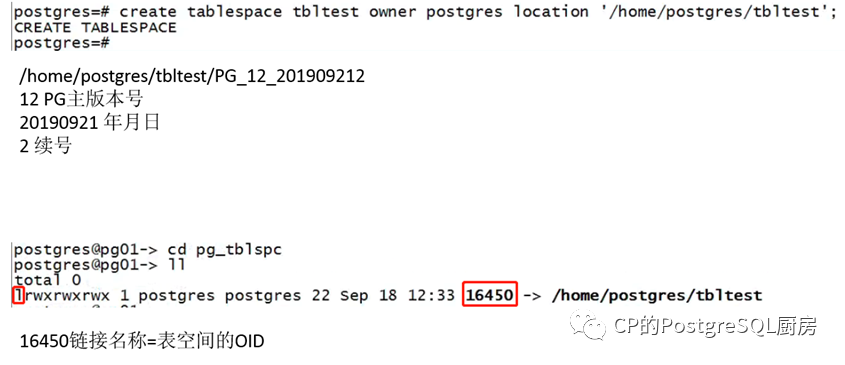
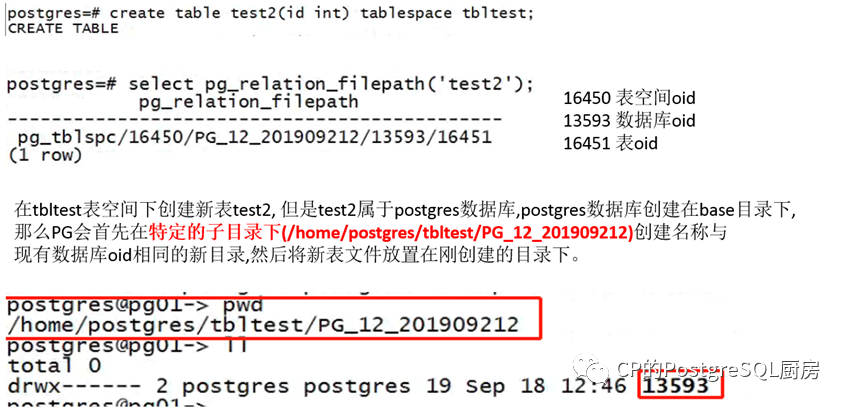
简单讲述表空间的软连接
1.3.3.3 pg_start_backup()和 pg_stop_backup()
物理备份恢复实验
pg_start_backup()和 pg_stop_backup() 备份过程
1)开启归档(方法参考前面章节)
2)超级用户连接数据库,执行命令:
select pg_start_backup(now()::text);
backup_label
pg_start_backup,会生成 backup_label文件。pg_stop_backup,会删除backup_label文件。
而如果StartupXLOG函数运行时,发现了backup_label文件,那么意味着它处正在从onlinebackup中恢复的过程中。
------
pg_start_backup
-----------------
0/E000028
(1 row)
3)可通过函数pg_is_in_backup();查看到备份状态
select pg_is_in_backup();
pg_is_in_backup
-----------------
t
(1 row)
也可以通过$PGDATA目录下生成的标签文件查看备份信息
cat $PGDATA/backup_label
------
START WAL LOCATION: 0/E000028 (file00000002000000000000000E)
CHECKPOINT LOCATION: 0/E000060
BACKUP METHOD: pg_start_backup
BACKUP FROM: master
START TIME: 2018-01-17 11:17:18 CST
LABEL: 2018-01-17 11:17:18.151543+08
4)执行备份
使用操作系统工具比如 tar 或 cp -ra 等,或直接把数据目录复制到备份位置。过程中既不需要关闭数据库,也不需要停止数据库的任何操作。
tar -jcv -f ~/bak/pgdata.tar.bz2 $PGDATA
注意手动备份表空间路径,即目录的pg_tblspc软连接指向目录。
tar -jcv -f ~/bak/dbbak/tbls.tar.bz2/pgtbls/tbls01
5)再次以数据库超级用户身份连接数据库,然后发出命令:
select pg_stop_backup();
这将终止备份模式并自动切换到下一个 WAL 段。
6)最后拷贝强制检查点之间的所有归档日志文件, 确保备份有效性。
1.4 基于时间点的恢复(PITR)
基于时间点的恢复(PITR)简介
数据库的PITR是一般数据库都必须满足的技术;
其原理是依据之前的物理备份文件加上wal的预写日志模式备份做的恢复;
该技术支持8.*及以上版本。
开启归档,确认归档路径
配置归档命令
vi $PGDATA/postgresql.conf
archive_mode = on
archive_command = 'DATE=`date +%Y%m%d`;DIR="/opt/arch/$DATE"; (test -d $DIR || mkdir -p $DIR) && cp%p $DIR/%f'
wal_level = replica
使用pg_basebackup备份数据库
pg_basebackup -D /home/postgres/bak/ -Ft -P-R -Upostgres
更新数据,模拟宕机
create table t_rec (id int,time timestamp);
insert into t_rec values (1,now());
insert into t_rec values (2,now());
insert into t_rec values (3,now());
insert into t_rec values (4,now());
insert into t_rec values (5,now());
select pg_switch_wal();
checkpoint;
select * from t_rec;
基于时间点恢复
将备份的数据文件解压到$PGDATA目录,wal日志解压放到$PGDATA/pg_wal目录
tar -xvf base.tar -C /opt/pg_root
tar -xvf pg_wal.tar -C /opt/pg_root/pg_wal
[root@pg01 opt]# chmod 0700 /opt/pg_root
拷贝recovery.conf文件到$PGDATA目录(如备份时加-R参数,则自动生成recovery.conf文件)
cp /opt/pgsql/share/recovery.conf.sample/opt/pg_root/recovery.conf
编辑recovery.conf文件
restore_command = 'cp /opt/arch/20211124/%f%p'
recovery_target_time = '2021-11-2404:28:27.860105'
启动数据库
%p 表示wal文件名$PGDATA的相对路径, 如pg_wal/00000001000000190000007D
%f 表示wal文件名, 如00000001000000190000007D
结束恢复操作
select pg_wal_replay_resume();
pg_wal_replay_resume() void 如果恢复被暂停,重启之(默认仅限于超级用户,但是可以授予其他用户 EXECUTE 特权来执行该函数)。
postgres=# show archive_mode ;
archive_mode
--------------
on
(1 row)
postgres=# show archive_command ;
archive_command
-----------------------------
cp %p /home/postgres/archive/%f
(1 row)
pg_basebackup -D /home/postgres/bak/ -Ft -P-R -Upostgres
postgres=# create table t_rec (id int,timetimestamp);
CREATE TABLE
postgres=# insert into t_rec values(1,now());
INSERT 0 1
postgres=# insert into t_rec values(2,now());
开启归档,确认归档路径
使用pg_basebackup备份数据库
postgres=# show archive_mode ;
archive_mode
--------------
on
(1 row)
postgres=# show archive_command ;
archive_command
-----------------------------
cp %p /home/postgres/archive/%f
(1 row)
pg_basebackup -D /home/postgres/bak/ -Ft -P-R -Upostgres
postgres=# create table t_rec (id int,timetimestamp);
CREATE TABLE
postgres=# insert into t_rec values(1,now());
INSERT 0 1
postgres=# insert into t_rec values(2,now());
基于时间点恢复
启动数据库
结束恢复操作
INSERT 0 1
postgres=# insert into t_rec values(3,now());
INSERT 0 1
postgres=# select pg_switch_wal();
pg_switch_wal
---------------
0/1E0141B8
(1 row)
postgres=# insert into t_rec values(4,now());
INSERT 0 1
postgres=# insert into t_rec values(5,now());
INSERT 0 1
postgres=# select * from t_rec ;
id | time
----+----------------------------
1 | 2020-05-29 17:28:03.347296
2 | 2020-05-29 17:28:07.951033
3 | 2020-05-29 17:28:14.955285
4 | 2020-05-29 17:29:12.431425
5 | 2020-05-29 17:29:22.629481
(5 rows)
备份数据目录,删除数据目录模拟宕机
将备份的数据文件解压到$PGDATA目录,wal日志解压放到$PGDATA/pg_wal目录
拷贝recovery.conf文件到$PGDATA目录(如备份时加-R参数,则自动生成recovery.conf文件)
cp/home/postgres/psql/share/recovery.conf.sample
/home/postgres/pgdata/recovery.conf
编辑recovery.conf文件
restore_command = 'cp/home/postgres/archive/%f %p'
recovery_target_time = '2020-05-2917:29:20.431425 +08'
启动数据库
select pg_wal_replay_resume();
