




学习目标
学习openGauss存储模型-行存和列存
行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。
行、列存储模型各有优劣,通常用于TP场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的AP场景时,才使用列存储
课程作业
1.创建行存表和列存表,并批量插入10万条数据(行存表和列存表数据相同)
CREATE TABLE doom_t1
(
col1 CHAR(2),
col2 VARCHAR2(40),
col3 NUMBER
);
insert into doom_t1 select col1, col2, col3 from (select generate_series(1, 100000) as key, repeat(chr(int4(random() * 26) + 65), 2) as col1, repeat(chr(int4(random() * 26) + 65), 30) as col2, (random() * (10^4))::integer as col3);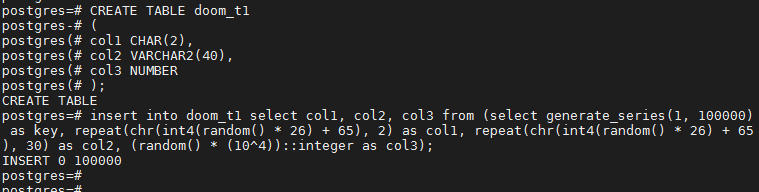
CREATE TABLE doom_t2
(
col1 CHAR(2),
col2 VARCHAR2(40),
col3 NUMBER
)
WITH (ORIENTATION = COLUMN);
insert into doom_t2 select * from doom_t1;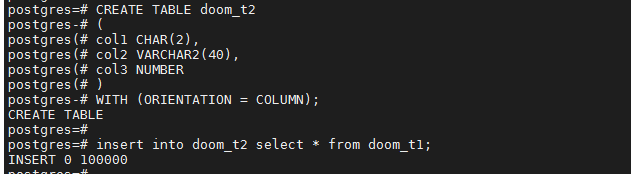
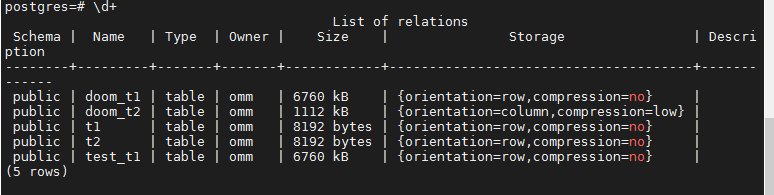
2.对比行存表和列存表空间大小
\d+
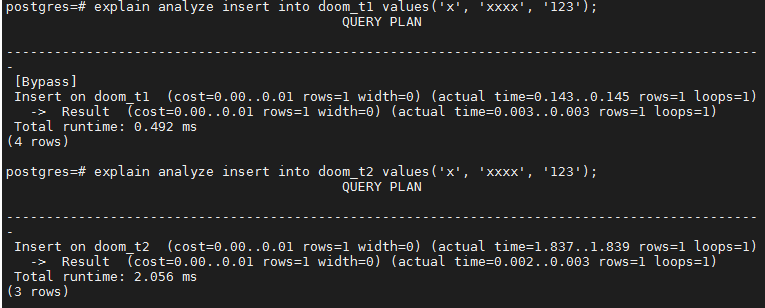
3.对比查询一列和插入一行的速度
explain analyze insert into doom_t1 values('x', 'xxxx', '123');
explain analyze insert into doom_t2 values('x', 'xxxx', '123');
4.清理数据
drop table doom_t1;
drop table doom_t2;

心得体会
19年起开始接触Postgresql 数据库。从去年6月份Opengauss 开源一直
在关注其发展,之前参加了8小时玩转oengauss 的一期跟二期的活动,也通过
了OGCA认证考试。此次参加21天打卡活动,在行业大佬的指导下学习了
Opengauss 的架构特性,使用场景,以及一些实用的实战技能,对以后的深入
学习奠定了很好的基础,收获很多。再次感谢各位专家的辛苦付出。
数据库行业目前发展是百花齐放。加之各行各业目前都在探索信创可控。学
习过后为将来的数据库选型提供了很好的技术支撑。Opengauss 是在PG 基础上做了
特别多特别多的技术革新,可谓青出于蓝。尤其在 MOT内存表引擎、高可用机
构、多线程,增量checkpoint,以及多核处理上有了很大的改进和性能提升。
加之在 AI方面的探索及规划,让我们对他的将来充满期待。作为一个传统行业
的DBA,为国产OpenGauss数据库这些功能深深的感到自豪。并为将来基础软件
国产化充满信心。
通过这次21天训练营的学习,对数据库架构体系,搭建安装,高可用部署,AI
特性,MOT内存表,以及一些容易出现问题的避坑指南的学习,对opengauss的
特性、使用场景、以及将来的发展规划全方位的了解,并对它的发展充满信心。
感谢enmo提供的这次和各位专家学习的机会,让自己在以后的国产化选型中更加
系统全局的了解Opengauss,少走弯路。愿其发展越来越好。




