




Elasticsearch由一些Elasticsearch进程(Node)组成集群,用来存放索引(Index)。为了存放数据量很大的索引,Elasticsearch将Index切分成多个分片(Shard),在这些Shard里存放一个个的文档(document)。通过这一批shard组成一个完整的index。并且,每个Shard可以设置一定数量的副本(Replica),写入的文档同步给副本Shard,副本Shard可以提供查询功能,分摊系统的读负载。在主Shard所在Node(ES进程)挂掉后,可以提升一个副本Shard为主Shard,文档继续写在新的主Shard上,来提升系统的容灾能力。既然Shard和Replica有这样的好处,那么Elasticsearch是如何利用和管理这些Shard,让Shard在集群Node上合理的分配,比如,使副本Shard不和主Shard分配在一个Node上,避免容灾失效等。尽量把Shard分配给负载较轻的Node来均摊集群的压力,随着Shard分配,久而久之Shard在集群中会出现分配不均衡的情况,这又该如何才能做到均衡。这便是我们这次讨论的主题:Elasticsearch的分片分配和均衡机制。(这段话转自:https://cloud.tencent.com/developer/article/1361266)
关于AllocationDecider
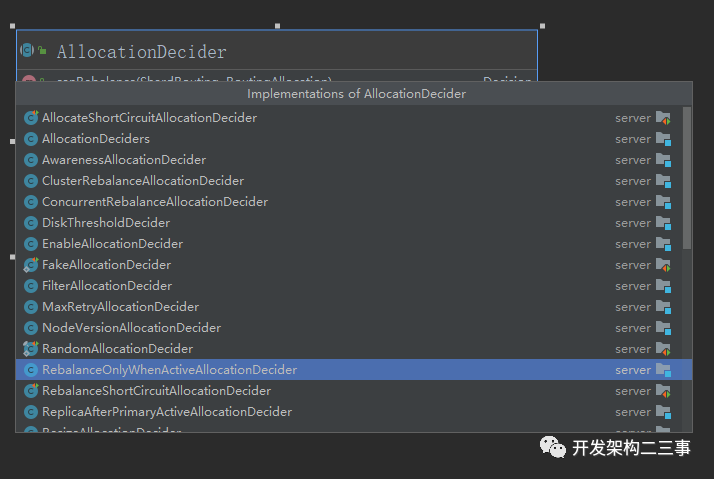
上面的图为类继承关系图的一部分,下面针对具体的配置进行分析。本文及本系列源码都是针对es的7.5.1版本。Shard Allocation,Shard Move,Shard Rebalance会利用这些Decider,再决定是否进行分片分配,分片迁移,分片均衡等操作。
ClusterModule中是集群相关的服务初始化的地方,在这里初始化的service会通过guice注入到ioc容器中,在其他地方使用。在添加Decider的地方在org.elasticsearch.cluster.ClusterModule#createAllocationDeciders,对应的代码如下:
public static Collection<AllocationDecider> createAllocationDeciders(Settings settings, ClusterSettings clusterSettings,
List<ClusterPlugin> clusterPlugins) {
// collect deciders by class so that we can detect duplicates
Map<Class, AllocationDecider> deciders = new LinkedHashMap<>();
addAllocationDecider(deciders, new MaxRetryAllocationDecider());
addAllocationDecider(deciders, new ResizeAllocationDecider());
addAllocationDecider(deciders, new ReplicaAfterPrimaryActiveAllocationDecider());
addAllocationDecider(deciders, new RebalanceOnlyWhenActiveAllocationDecider());
addAllocationDecider(deciders, new ClusterRebalanceAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new ConcurrentRebalanceAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new EnableAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new NodeVersionAllocationDecider());
addAllocationDecider(deciders, new SnapshotInProgressAllocationDecider());
addAllocationDecider(deciders, new RestoreInProgressAllocationDecider());
addAllocationDecider(deciders, new FilterAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new SameShardAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new DiskThresholdDecider(settings, clusterSettings));
addAllocationDecider(deciders, new ThrottlingAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new ShardsLimitAllocationDecider(settings, clusterSettings));
addAllocationDecider(deciders, new AwarenessAllocationDecider(settings, clusterSettings));
clusterPlugins.stream()
.flatMap(p -> p.createAllocationDeciders(settings, clusterSettings).stream())
.forEach(d -> addAllocationDecider(deciders, d));
return deciders.values();
}
其中org.elasticsearch.cluster.ClusterModule#addAllocationDecider方法:
/** Add the given allocation decider to the given deciders collection, erroring if the class name is already used. */
private static void addAllocationDecider(Map<Class, AllocationDecider> deciders, AllocationDecider decider) {
if (deciders.put(decider.getClass(), decider) != null) {
throw new IllegalArgumentException("Cannot specify allocation decider [" + decider.getClass().getName() + "] twice");
}
}
调用流程
从org.elasticsearch.action.support.TransportAction#execute(org.elasticsearch.tasks.Task, Request, org.elasticsearch.action.ActionListener
public final void execute(Task task, Request request, ActionListener<Response> listener) {
ActionRequestValidationException validationException = request.validate();
if (validationException != null) {
listener.onFailure(validationException);
return;
}
if (task != null && request.getShouldStoreResult()) {
listener = new TaskResultStoringActionListener<>(taskManager, task, listener);
}
RequestFilterChain<Request, Response> requestFilterChain = new RequestFilterChain<>(this, logger);
requestFilterChain.proceed(task, actionName, request, listener);
}
org.elasticsearch.action.support.TransportAction.RequestFilterChain#proceed方法:
@Override
public void proceed(Task task, String actionName, Request request, ActionListener<Response> listener) {
int i = index.getAndIncrement();
try {
if (i < this.action.filters.length) {
this.action.filters[i].apply(task, actionName, request, listener, this);
} else if (i == this.action.filters.length) {
this.action.doExecute(task, request, listener);
} else {
listener.onFailure(new IllegalStateException("proceed was called too many times"));
}
} catch(Exception e) {
logger.trace("Error during transport action execution.", e);
listener.onFailure(e);
}
}
org.elasticsearch.action.support.master.TransportMasterNodeAction#doExecute:
@Override
protected void doExecute(Task task, final Request request, ActionListener<Response> listener) {
new AsyncSingleAction(task, request, listener).start();
}
org.elasticsearch.action.support.master.TransportMasterNodeAction.AsyncSingleAction#start:
public void start() {
ClusterState state = clusterService.state();
this.observer
= new ClusterStateObserver(state, clusterService, request.masterNodeTimeout(), logger, threadPool.getThreadContext());
doStart(state);
}
org.elasticsearch.action.support.master.TransportMasterNodeAction.AsyncSingleAction#doStart:
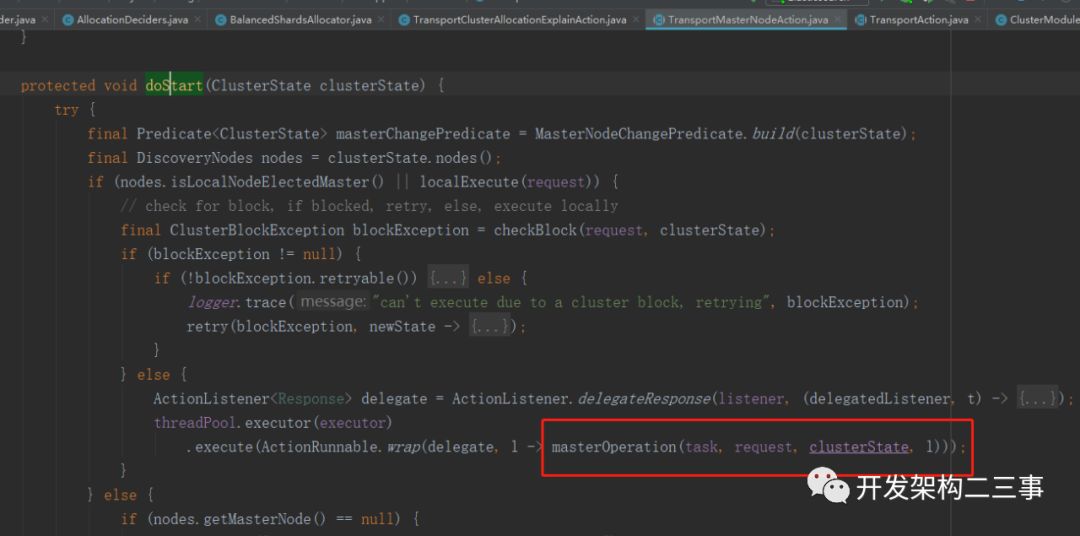
org.elasticsearch.action.support.master.TransportMasterNodeAction#masterOperation(org.elasticsearch.tasks.Task, Request, org.elasticsearch.cluster.ClusterState, org.elasticsearch.action.ActionListener
protected void masterOperation(Task task, Request request, ClusterState state, ActionListener<Response> listener) throws Exception {
masterOperation(request, state, listener);
}
org.elasticsearch.action.admin.cluster.allocation.TransportClusterAllocationExplainAction#masterOperation:
@Override
protected void masterOperation(final ClusterAllocationExplainRequest request, final ClusterState state,
final ActionListener<ClusterAllocationExplainResponse> listener) {
final RoutingNodes routingNodes = state.getRoutingNodes();
final ClusterInfo clusterInfo = clusterInfoService.getClusterInfo();
final RoutingAllocation allocation = new RoutingAllocation(allocationDeciders, routingNodes, state,
clusterInfo, System.nanoTime());
ShardRouting shardRouting = findShardToExplain(request, allocation);
logger.debug("explaining the allocation for [{}], found shard [{}]", request, shardRouting);
ClusterAllocationExplanation cae = explainShard(shardRouting, allocation,
request.includeDiskInfo() ? clusterInfo : null, request.includeYesDecisions(), gatewayAllocator, shardAllocator);
listener.onResponse(new ClusterAllocationExplainResponse(cae));
}
org.elasticsearch.action.admin.cluster.allocation.TransportClusterAllocationExplainAction#explainShard:
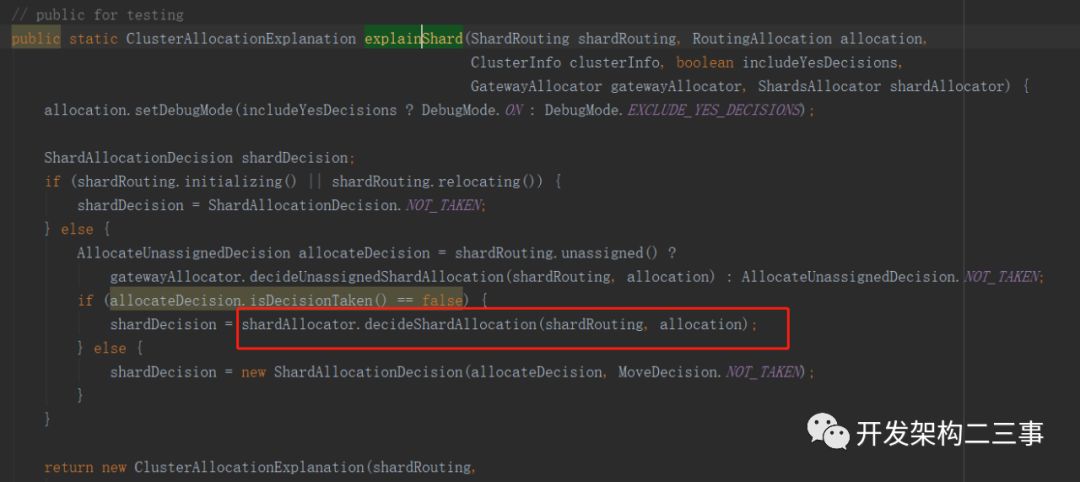
org.elasticsearch.cluster.routing.allocation.allocator.BalancedShardsAllocator#decideShardAllocation:
@Override
public ShardAllocationDecision decideShardAllocation(final ShardRouting shard, final RoutingAllocation allocation) {
Balancer balancer = new Balancer(logger, allocation, weightFunction, threshold);
AllocateUnassignedDecision allocateUnassignedDecision = AllocateUnassignedDecision.NOT_TAKEN;
MoveDecision moveDecision = MoveDecision.NOT_TAKEN;
if (shard.unassigned()) {
allocateUnassignedDecision = balancer.decideAllocateUnassigned(shard, Sets.newHashSet());
} else {
moveDecision = balancer.decideMove(shard);
if (moveDecision.isDecisionTaken() && moveDecision.canRemain()) {
MoveDecision rebalanceDecision = balancer.decideRebalance(shard);
moveDecision = rebalanceDecision.withRemainDecision(moveDecision.getCanRemainDecision());
}
}
return new ShardAllocationDecision(allocateUnassignedDecision, moveDecision);
}
org.elasticsearch.cluster.routing.allocation.allocator.BalancedShardsAllocator.Balancer#decideRebalance:
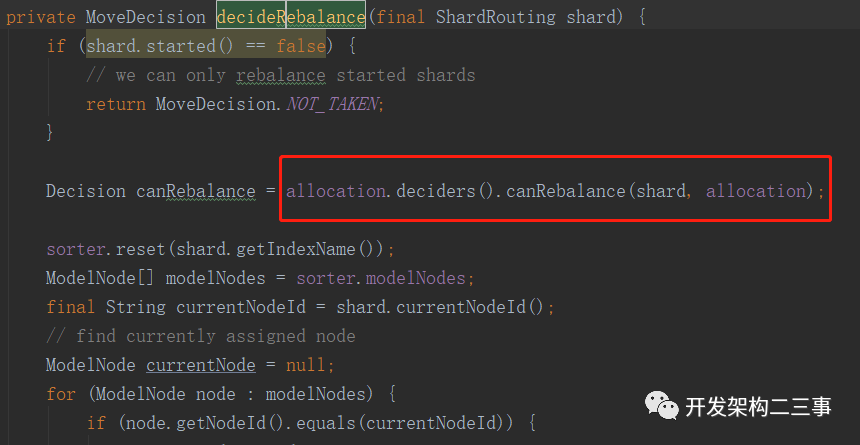
org.elasticsearch.cluster.routing.allocation.decider.AllocationDeciders#canRebalance(org.elasticsearch.cluster.routing.ShardRouting, org.elasticsearch.cluster.routing.allocation.RoutingAllocation):
@Override
public Decision canRebalance(ShardRouting shardRouting, RoutingAllocation allocation) {
Decision.Multi ret = new Decision.Multi();
for (AllocationDecider allocationDecider : allocations) {
Decision decision = allocationDecider.canRebalance(shardRouting, allocation);
// short track if a NO is returned.
if (decision == Decision.NO) {
if (!allocation.debugDecision()) {
return decision;
} else {
ret.add(decision);
}
} else if (decision != Decision.ALWAYS
&& (allocation.getDebugMode() != EXCLUDE_YES_DECISIONS || decision.type() != Decision.Type.YES)) {
ret.add(decision);
}
}
return ret;
}
关于这个流程这里不做具体分析,本文主要分析下各种Decider和其作用。
各种Decider
1、org.elasticsearch.cluster.routing.allocation.decider.ClusterRebalanceAllocationDecider
配置属性为:cluster.routing.allocation.allow_rebalance ,我们先来分析一下它的源码部分,然后再对功能进行分析。
1.1 属性部分
public static final String NAME = "cluster_rebalance";
private static final String CLUSTER_ROUTING_ALLOCATION_ALLOW_REBALANCE = "cluster.routing.allocation.allow_rebalance";
public static final Setting<ClusterRebalanceType> CLUSTER_ROUTING_ALLOCATION_ALLOW_REBALANCE_SETTING =
new Setting<>(CLUSTER_ROUTING_ALLOCATION_ALLOW_REBALANCE, ClusterRebalanceType.INDICES_ALL_ACTIVE.toString(),
ClusterRebalanceType::parseString, Property.Dynamic, Property.NodeScope);
在这里的ClusterRebalanceType有以下三种:
public enum ClusterRebalanceType {
/**
* Re-balancing is allowed once a shard replication group is active
*/
ALWAYS,
/**
* Re-balancing is allowed only once all primary shards on all indices are active.
*/
INDICES_PRIMARIES_ACTIVE,
/**
* Re-balancing is allowed only once all shards on all indices are active.
*/
INDICES_ALL_ACTIVE;
ALWAYS:当一个分片副本集处于active状态时允许进行负载;
INDICESPRIMARIESACTIVE:只有在所有的主分片和主分片索索处于active状态时允许进行负载;
INDICESALLACTIVE:只有当所有的分片和索引处于active状态时允许进行负载。
1.2 方法
1.2.1 构造方法
public ClusterRebalanceAllocationDecider(Settings settings, ClusterSettings clusterSettings) {
type = CLUSTER_ROUTING_ALLOCATION_ALLOW_REBALANCE_SETTING.get(settings);
logger.debug("using [{}] with [{}]", CLUSTER_ROUTING_ALLOCATION_ALLOW_REBALANCE, type);
clusterSettings.addSettingsUpdateConsumer(CLUSTER_ROUTING_ALLOCATION_ALLOW_REBALANCE_SETTING, this::setType);
}
构造方法主要用于设置type属性,并给clusterSettings添加了一个配置更新的消费者。这个consumer会被添加到settingUpdaters列表中,它对应的代码为:
private final List<SettingUpdater<?>> settingUpdaters = new CopyOnWriteArrayList<>();
这个consumer的方法会在org.elasticsearch.common.settings.AbstractScopedSettings#validateUpdate和org.elasticsearch.common.settings.AbstractScopedSettings#applySettings方法中被回调。
lambda中的setType方法如下:
private void setType(ClusterRebalanceType type) {
this.type = type;
}
1.2.2 org.elasticsearch.cluster.routing.allocation.decider.ClusterRebalanceAllocationDecider#canRebalance方法
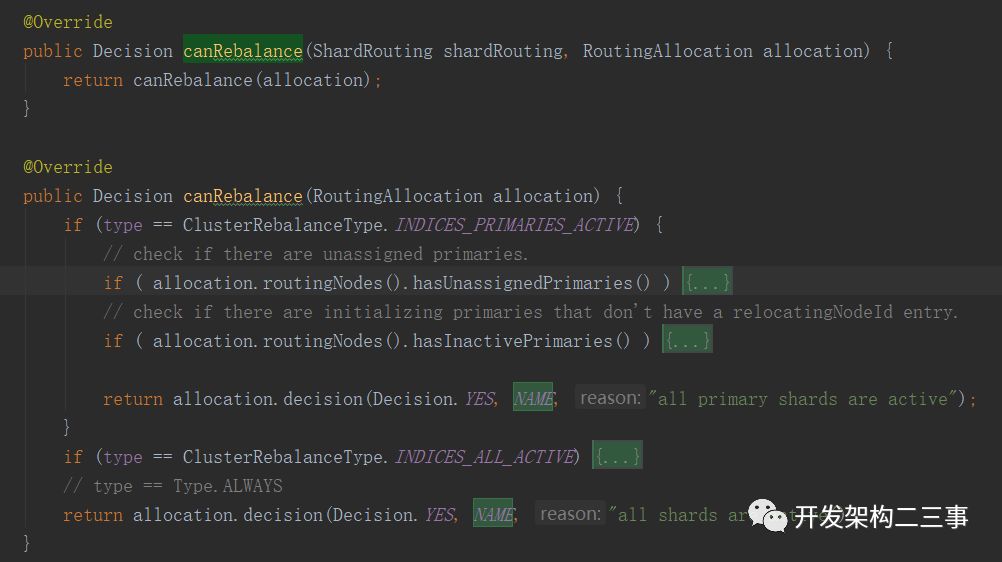
这个方法会先根据type类型进行相应处理,然后通过RoutingAllocation的decision方法返回路由Decision。默认是设置成indicesallactive来减少集群初始启动时机器之间的交互。
2、org.elasticsearch.cluster.routing.allocation.decider.ConcurrentRebalanceAllocationDecider
配置项为:cluster.routing.allocation.clusterconcurrentrebalance,这个配置的主要源码位于org.elasticsearch.cluster.routing.allocation.decider.ConcurrentRebalanceAllocationDecider中,它的属性和方法与上面的ClusterRebalanceAllocationDecider类似,这里就不详细分析了,这个配置的主要作用是设置在集群中最大允许同时进行分片分布的个数,默认为2,也就是说整个集群最多有两个分片在进行重新分布。
3、org.elasticsearch.cluster.routing.allocation.decider.ThrottlingAllocationDecider中的配置
定义了Allocate策略,避免过多的Recoving Allocation,结合系统的动态配置,避免过多的Recoving任务导致该Node的负载过高,这里面主要有三个配置:
cluster.routing.allocation.nodeconcurrentrecoveries :控制节点中能并行进行恢复的分片个数,默认为2
cluster.routing.allocation.nodeinitialprimaries_recoveries:控制在节点中初始化恢复中的分片数,默认为4
cluster.routing.allocation.nodeconcurrentincoming_recoveries:控制传入的需要当前节点并发恢复的分片数,默认为2 (主要是其他节点的主分片传入的需要当前节点并发恢复的副分片)
cluster.routing.allocation.nodeconcurrentoutgoing_recoveries:控制允许在一个节点上发生多少并发传出分片恢复,默认为2(主要用于控制主分片上传到其他节点上需要恢复的副分片数)
关于这些配置的方法代码如下:
@Override
public Decision canAllocate(ShardRouting shardRouting, RoutingNode node, RoutingAllocation allocation) {
// 节点为主节点而且没有分配过
if (shardRouting.primary() && shardRouting.unassigned()) {
// 进行节点的初始化
assert initializingShard(shardRouting, node.nodeId()).recoverySource().getType() != RecoverySource.Type.PEER;
// primary is unassigned, means we are going to do recovery from store, snapshot or local shards
// count *just the primaries* currently doing recovery on the node and check against primariesInitialRecoveries
// 统计在进行recovery的主节点数
int primariesInRecovery = 0;
// 遍历当前节点中的分片数
for (ShardRouting shard : node) {
// when a primary shard is INITIALIZING, it can be because of *initial recovery* or *relocation from another node*
// we only count initial recoveries here, so we need to make sure that relocating node is null
// 一个主节点的初始化,可能是因为initial recovery参数或者relocation from another node
// 我们仅仅在这里统计在进行recovery的主分片,所以我们需要确保正在进行relocating的节点为null
if (shard.initializing() && shard.primary() && shard.relocatingNodeId() == null) {
primariesInRecovery++;
}
}
// 当处于恢复中的主分片数量大于初始化加载的cluster.routing.allocation.node_initial_primaries_recoveries配置的数量时
if (primariesInRecovery >= primariesInitialRecoveries) {
// TODO: Should index creation not be throttled for primary shards?
// 相当于达到阀值了
return allocation.decision(THROTTLE, NAME,
"reached the limit of ongoing initial primary recoveries [%d], cluster setting [%s=%d]",
primariesInRecovery, CLUSTER_ROUTING_ALLOCATION_NODE_INITIAL_PRIMARIES_RECOVERIES_SETTING.getKey(),
primariesInitialRecoveries);
} else {
return allocation.decision(YES, NAME, "below primary recovery limit of [%d]", primariesInitialRecoveries);
}
} else {
// Peer recovery
assert initializingShard(shardRouting, node.nodeId()).recoverySource().getType() == RecoverySource.Type.PEER;
// Allocating a shard to this node will increase the incoming recoveries
// 当前节点每多分配一个分片就会增加incoming recoveries的数量
int currentInRecoveries = allocation.routingNodes().getIncomingRecoveries(node.nodeId());
// 当前正在恢复中的节点数量大于当前配置的限制值时
if (currentInRecoveries >= concurrentIncomingRecoveries) {
return allocation.decision(THROTTLE, NAME,
"reached the limit of incoming shard recoveries [%d], cluster setting [%s=%d] (can also be set via [%s])",
currentInRecoveries, CLUSTER_ROUTING_ALLOCATION_NODE_CONCURRENT_INCOMING_RECOVERIES_SETTING.getKey(),
concurrentIncomingRecoveries,
CLUSTER_ROUTING_ALLOCATION_NODE_CONCURRENT_RECOVERIES_SETTING.getKey());
} else {
// search for corresponding recovery source (= primary shard) and check number of outgoing recoveries on that node
// 搜索相应的恢复源(也就是主节点) 并且检查该节点上传出的恢复数
ShardRouting primaryShard = allocation.routingNodes().activePrimary(shardRouting.shardId());
if (primaryShard == null) {
return allocation.decision(Decision.NO, NAME, "primary shard for this replica is not yet active");
}
int primaryNodeOutRecoveries = allocation.routingNodes().getOutgoingRecoveries(primaryShard.currentNodeId());
if (primaryNodeOutRecoveries >= concurrentOutgoingRecoveries) {
return allocation.decision(THROTTLE, NAME,
"reached the limit of outgoing shard recoveries [%d] on the node [%s] which holds the primary, " +
"cluster setting [%s=%d] (can also be set via [%s])",
primaryNodeOutRecoveries, primaryShard.currentNodeId(),
CLUSTER_ROUTING_ALLOCATION_NODE_CONCURRENT_OUTGOING_RECOVERIES_SETTING.getKey(),
concurrentOutgoingRecoveries,
CLUSTER_ROUTING_ALLOCATION_NODE_CONCURRENT_RECOVERIES_SETTING.getKey());
} else {
return allocation.decision(YES, NAME, "below shard recovery limit of outgoing: [%d < %d] incoming: [%d < %d]",
primaryNodeOutRecoveries,
concurrentOutgoingRecoveries,
currentInRecoveries,
concurrentIncomingRecoveries);
}
}
}
}
4、org.elasticsearch.cluster.routing.allocation.decider.MaxRetryAllocationDecider
配置项为index.allocation.maxretries,用于控制索引分配时的最大重试次数。定义了Shard维度的Allocation策略,防止Shard在失败次数达到上限后继续分配,当Shard分配失败一次后,失败次数会加1,当Shard分配次数超过配置的最大次数时,这个策略生效,返回Decision.NO;可以通过配置”index.allocation.maxretries”,来设置分配的最大失败重试次数,默认是5次,当然系统分配到达重试次数后,可以手动分配分片,在URL后带上“?retry_failed”请求参数,可以尝试再次分配分片。
5、org.elasticsearch.cluster.routing.allocation.decider.ResizeAllocationDecider
用于分片索引的大小的重新分配
6、org.elasticsearch.cluster.routing.allocation.decider.ReplicaAfterPrimaryActiveAllocationDecider
一种只有在主分片处于激活状态后副分片才能进行分配的分配策略
7、org.elasticsearch.cluster.routing.allocation.decider.RebalanceOnlyWhenActiveAllocationDecider
仅当分片副本组中的所有分片处于active状态时可以进行rebalance。
8、org.elasticsearch.cluster.routing.allocation.decider.EnableAllocationDecider
这个类维护的有三个配置,分别是:
cluster.routing.allocation.enable:集群的路由分配设置,默认为all,当index.routing.allocation.enable没有配置时生效
index.routing.allocation.enable: 索引的路由分配设置,默认为all
cluster.routing.rebalance.enable:集群路由rebalance设置,默认为all,当index.routing.rebalance.enable没有配置时生效。
index.routing.rebalance.enable:索引的路由rebalance配置,默认为all。
对于上面配置,还有两个值得一说的类型,org.elasticsearch.cluster.routing.allocation.decider.EnableAllocationDecider.Allocation:

org.elasticsearch.cluster.routing.allocation.decider.EnableAllocationDecider.Rebalance:
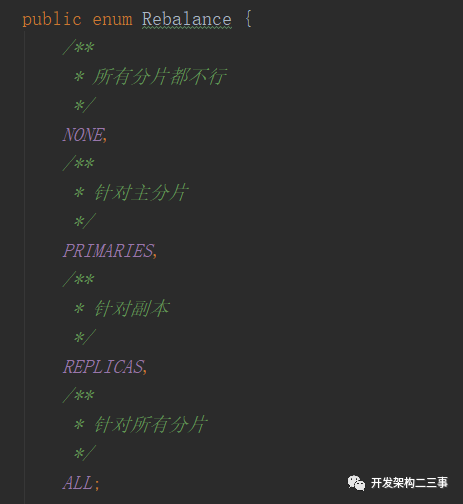
9、org.elasticsearch.cluster.routing.allocation.decider.NodeVersionAllocationDecider
其他的decider都没有做版本号的校验,如果我们把一个分片从一个新的版本的节点上迁移到一个老的版本的节点的分片上就会有问题,NodeVersionAllocationDecider就是用来处理这个问题的。定义了Allocate策略,检查分片所在Node的版本是否高于目标Node的ES版本,如果高于,不允许allocation,这种策略的目的是避免目标Node无法适配高版本lucencn格式的文件,一般集群ES都是一致的,当集群在进行ES版本滚动升级时,会出现版本不一致的情况。
10、org.elasticsearch.cluster.routing.allocation.decider.SnapshotInProgressAllocationDecider
主要用于阻止正在进行快照的分片向其他节点迁移。定义了Allocate策略,决定snapshot期间是否允许allocation,由于snapshot只发生在主分片,所以只会限制主分片的allocation。
11、org.elasticsearch.cluster.routing.allocation.decider.RestoreInProgressAllocationDecider
这个decider主要用于阻止那些从快照中还未成功恢复的节点被分配。
12、org.elasticsearch.cluster.routing.allocation.decider.FilterAllocationDecider
这个decider主要维护下面三个属性:
cluster.routing.allocation.require
cluster.routing.allocation.include
cluster.routing.allocation.exclude
require表示必须分配到指定node,include表示可以分配到指定node,exclude表示不允许分配到指定Node,cluster的配置会覆盖index级别的配置,比如index include某个node,cluster exclude某个node,最后的结果是exclude某个node,上面{attribute}表示node的匹配方式有:
_name和name 匹配node名称,多个node名称用逗号隔开
ip、publiship、host_ip 匹配node ip,多个ip用逗号隔开
_host 匹配node的host name 多个host name用逗号隔开
_id 匹配节点id
示例,示例来自:https://www.iteye.com/blog/rockelixir-1890855:
假如我们有四个节点,每个节点都有一个叫tag(可以是任何名字)的属性。每个节点都指定一个tag的值。如:节点一设置成node.tag: value1,节点二设置成node.tag: value2,如此类推。我们可以创建一个索引然后只把它分布到tag值为value1和value2的节点中,可以通过设置 index.routing.allocation.include.tag 为value1,value2达到这样的效果,如:
curl -XPUT localhost:9200/test/_settings -d '{
"index.routing.allocation.include.tag" : "value1,value2"
}'
与此相反,通过设置index.routing.allocation.exclude.tag为value3,我们也可以创建一个索引让其分布在除了tag设置为value3的所有节点中,如:
curl -XPUT localhost:9200/test/_settings -d '{
"index.routing.allocation.exclude.tag" : "value3"
}'
include或exclude过滤器的值都会使用通配符来匹配,如value*。一个特别的属性名是_ip,它可以用来匹配节点的ip地址。显然,一个节点可能拥有多个属性值,所有属性的名字和值都在配置文件中配置。如,下面是多个节点的配置:
node.group1: group1_value1
node.group2: group2_value4
同样的方法,include和exclude也可以设置多个值,如:
curl -XPUT localhost:9200/test/_settings -d '{
"index.routing.allocation.include.group1" : "xxx"
"index.routing.allocation.include.group2" : "yyy",
"index.routing.allocation.exclude.group3" : "zzz",
}'
上面的设置可以通过索引更新的api实时更新到索引上,允许实时移动索引分片。
集群范围的过滤器也可以定义,可以通过集群更新api实时更新到集群上。这些设置可以用来做让一些节点退出集群的操作。下面是通过ip地址去掉一个节点的操作:
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}'
13、org.elasticsearch.cluster.routing.allocation.decider.SameShardAllocationDecider
维护的配置为cluster.routing.allocation.same_shard.host,定义了Allocate策略,避免将shard的不同类型(主shard,副本shard)分配到同一个node上,先检查已分配shard的NodeId是否和目标Node相同,相同肯定是不能分配。除了检查NodeId,为了避免分配到同一台机器的不同Node,会检查已分配shard的Node ip和hostname是否和目标Node相同,相同的话也是不允许分配的。
14、org.elasticsearch.cluster.routing.allocation.decider.DiskThresholdDecider
定义了Allocate策略,Remind策略。策略根据Node的磁盘剩余量来决定是否分配到该Node,以及检查Shard是否可以继续停留在当前Node上,会检查系统的动态配置。主要配置的属性位于DiskThresholdSettings中,列举如下:
/**
* 是否开启磁盘分配域值校验
*/
public static final Setting<Boolean> CLUSTER_ROUTING_ALLOCATION_DISK_THRESHOLD_ENABLED_SETTING =
Setting.boolSetting("cluster.routing.allocation.disk.threshold_enabled", true,
Setting.Property.Dynamic, Setting.Property.NodeScope);
/**
* 磁盘分配的低水平线(下限)
*/
public static final Setting<String> CLUSTER_ROUTING_ALLOCATION_LOW_DISK_WATERMARK_SETTING =
new Setting<>("cluster.routing.allocation.disk.watermark.low", "85%",
(s) -> validWatermarkSetting(s, "cluster.routing.allocation.disk.watermark.low"),
new LowDiskWatermarkValidator(),
Setting.Property.Dynamic, Setting.Property.NodeScope);
/**
* 磁盘分配的高水平线(上限)
*/
public static final Setting<String> CLUSTER_ROUTING_ALLOCATION_HIGH_DISK_WATERMARK_SETTING =
new Setting<>("cluster.routing.allocation.disk.watermark.high", "90%",
(s) -> validWatermarkSetting(s, "cluster.routing.allocation.disk.watermark.high"),
new HighDiskWatermarkValidator(),
Setting.Property.Dynamic, Setting.Property.NodeScope);
/**
* 比高水平线还高一些的值
*/
public static final Setting<String> CLUSTER_ROUTING_ALLOCATION_DISK_FLOOD_STAGE_WATERMARK_SETTING =
new Setting<>("cluster.routing.allocation.disk.watermark.flood_stage", "95%",
(s) -> validWatermarkSetting(s, "cluster.routing.allocation.disk.watermark.flood_stage"),
new FloodStageValidator(),
Setting.Property.Dynamic, Setting.Property.NodeScope);
/**
* 磁盘不足时是否迁移
*/
public static final Setting<Boolean> CLUSTER_ROUTING_ALLOCATION_INCLUDE_RELOCATIONS_SETTING =
Setting.boolSetting("cluster.routing.allocation.disk.include_relocations", true,
Setting.Property.Dynamic, Setting.Property.NodeScope, Setting.Property.Deprecated);
/**
* 磁盘没法分配到重新磁盘分配路由的时间间隔
*/
public static final Setting<TimeValue> CLUSTER_ROUTING_ALLOCATION_REROUTE_INTERVAL_SETTING =
Setting.positiveTimeSetting("cluster.routing.allocation.disk.reroute_interval", TimeValue.timeValueSeconds(60),
Setting.Property.Dynamic, Setting.Property.NodeScope);
15、org.elasticsearch.cluster.routing.allocation.decider.ShardsLimitAllocationDecider#ShardsLimitAllocationDecider
定义了Allocate策略,根据系统的动态配置:
/**
* Controls the maximum number of shards per index on a single Elasticsearch
* node. Negative values are interpreted as unlimited.
* index级别的”index.routing.allocation.total_shards_per_node”,表示这个index每个node的总共允许存在多少个shard,默认值是-1表示无穷多个
*/
public static final Setting<Integer> INDEX_TOTAL_SHARDS_PER_NODE_SETTING =
Setting.intSetting("index.routing.allocation.total_shards_per_node", -1, -1,
Property.Dynamic, Property.IndexScope);
/**
* Controls the maximum number of shards per node on a global level.
* Negative values are interpreted as unlimited.
* cluster级别”cluster.routing.allocation.total_shards_per_node”,表示集群范围内每个Node允许存在有多少个shard。默认值是-1表示无穷多个
*/
public static final Setting<Integer> CLUSTER_TOTAL_SHARDS_PER_NODE_SETTING =
Setting.intSetting("cluster.routing.allocation.total_shards_per_node", -1, -1,
Property.Dynamic, Property.NodeScope);
如果目标Node的Shard数超过了配置的上限,则不允许分配Shard到该Node上。注意:index级别的配置会覆盖cluster级别的配置。
16、org.elasticsearch.cluster.routing.allocation.decider.AwarenessAllocationDecider
假设我们有几个机架。当我们启动一个节点,我们可以设置一个叫rack_id(其它名字也可以)的属性,例如下面设置:
node.rack_id: rack_one
上面这个例子设置了一个属性叫rackid,它的值为rackone。现在,我们要设置rack_id作为分片分布规则的一个属性(在所有节点都要设置)。
cluster.routing.allocation.awareness.attributes: rack_id
上面设置意味着rackid会用来作为分片分布的依据。例如:我们启动两个node.rackid设置rackone的节点,然后建立一个5个分片,一个副本的索引。这个索引就会完全分布在这两个节点上。如果再启动另外两个节点,node.rackid设置成racktwo,分片会重新分布,但是一个分片和它的副本不会分配到同样rackid值的节点上。可以为分片分布规则设置多个属性,例如:
cluster.routing.allocation.awareness.attributes: rack_id,zone
注意:当设置了分片分布属性时,如果集群中的节点没有设置其中任何一个属性,那么分片就不会分布到这个节点中。
还有一种强制分布规则 ,这是因为更多的时候,我们不想更多的副本被分布到相同分布规则属性值的一群节点上,那么我们可以强制分片规则为一个指定的值。例如,我们有一个分片规则属性叫zone,并且我们知道有两个zone,zone1和zone2.下面是设置:
1. cluster.routing.allocation.awareness.force.zone.values: zone1,zone2
2. cluster.routing.allocation.awareness.attributes: zone
现在我们启动两个node.zone设置成zone1的节点,然后创建一个5个分片,一个副本的索引。索引建立完成后只有5个分片(没有副本),只有当我们启动node.zone设置成zone2的节点时,副本才会分配到那节点上。这是因为cluster.routing.allocation.awareness.force.zone.values:配置的值为zone1,zone2。
参考
https://www.iteye.com/blog/rockelixir-1890855
https://cloud.tencent.com/developer/article/1361266
http://www.aiuxian.com/article/p-1792959.html
https://www.cnblogs.com/hyq0823/p/11569606.html
