
csv会浪费您的时间、磁盘空间和金钱。是时候结束了。csv并不是唯一的数据存储格式,甚至可能是你最后才考虑使用的格式。如果你不打算手动编辑数据,使用csv是在浪费时间和金钱。想象一下——你收集了大量的数据并将它们存储在云端。你没有对文件格式做太多的研究,所以选择了csv。你的开销会爆炸!如果不追求更多,一个简单的调整可以减少一半开销。这个调整就是——你已经猜到了——选择一种不同的文件格式。简单地说,它是一种用于存储数据帧(DataFrame)的数据格式(想想Pandas)。它围绕一个简单的前提设计——尽可能高效地将数据帧输入和输出内存。它最初是为Python和R之间的快速通信而设计的,但您并不局限于这个用例。不过Feather并不只能用与Python和R,你可以通过任何一个主流编程语言使用Feather文件。这种数据格式不是为长期存储而设计的。最初的目的是R和Python程序之间的快速交换,以及一般的短期存储。没有人能阻止您将Feather文件转储到磁盘,并将它们保存多年,但有比Feather更有效的格式。在Python中,您可以通过Pandas或专用库使用Feather。本文将向您展示如何使用这两种方法。首先您将需要安装feather-format来继续。以下是代码:# Pip
pip install feather-format
# Anaconda
conda install -c conda-forge feather-format
有了这些你就可以开始使用Feather了。打开JupyterLab或任何其他数据科学IDE,下一节将涵盖Feather的基础知识。让我们从导入库和创建相对较大的数据集开始。你将用到Feature,Numpy和Pandas。该数据集有一千万*5个随机数:import feather
import numpy as np
import pandas as pd
np.random.seed=42
df_size = 10_000_000
df = pd.DataFrame ({
‘a’: np.random.rand (df_size),
‘b’: np.random.rand (df_size),
‘c’: np.random.rand (df_size),
‘d’: np.random.rand (df_size),
‘e’: np.random.rand (df_size)
})
df.head ()
接着把它保存到本地。你可以调用Pandas使用下面的命令来保存DataFrame到Feature格式:df.to_feather('1M.feather')
feather.write_dataframe(df, ‘1M.feather’)
差别不大。这两个文件现在都保存在本地。你可以在Pandas或专用库阅读它们。下面是Pandas的语法:df = pd.read_feather(‘1M.feather')
df = feather.read_dataframe('1M.feather')
以上涵盖了你需要知道的东西。下面的部分将介绍与CSV文件格式在文件大小、读取和写入时间上的比较。CSV vs. Feather -你应该使用哪一个?如果不需要动态更改数据,答案很简单——用Feather。不过,让我们先做一些测试。下面的图表显示了把上一节的DataFrame保存到本地所需的时间: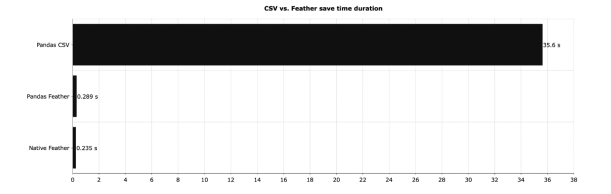
这是一个巨大的差异——原生Feather大约比CSV快150倍。使用Pandas来处理Feather文件并不会有太大的影响,但是与CSV相比,Feather在速度上的提高是显著的。接下来,让我们比较读取时间——读取相同数据集的不同格式需要多长时间: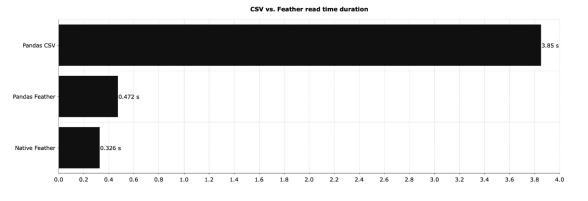
CSV又一次被完爆。和Feather相比,CSV的读取速度更慢,占用更多的磁盘空间,但具体是多少呢?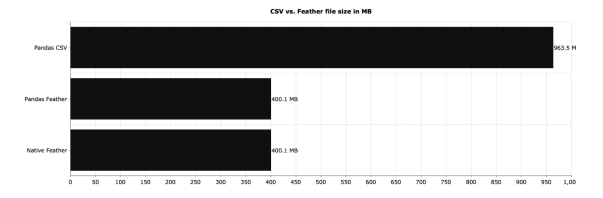
正如您所见,CSV文件占用的空间是Feather文件的两倍多。如果您每天存储几个G的数据, 选择正确的文件格式是至关重要的。Feature在这方面完胜了CSV。如果你需要更多的压缩,你应该尝试Parquet。我发现这是迄今为止最好的格式。总之,从to_csv()到to_feather(),从read_csv()到read_feather()可以节省大量时间和磁盘空间。考虑一下在下一个项目中试试Feather吧。Stop Using CSVs for Storage — This File Format Is 150 Times Fasterhttps://towardsdatascience.com/stop-using-csvs-for-storage-this-file-format-is-150-times-faster-158bd322074e
王可汗,清华大学机械工程系直博生在读。曾经有着物理专业的知识背景,研究生期间对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与机械工程、计算物理碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。







