1.用tsvector @@ tsquery和tsquery @@ tsvector完成两个基本文本匹配
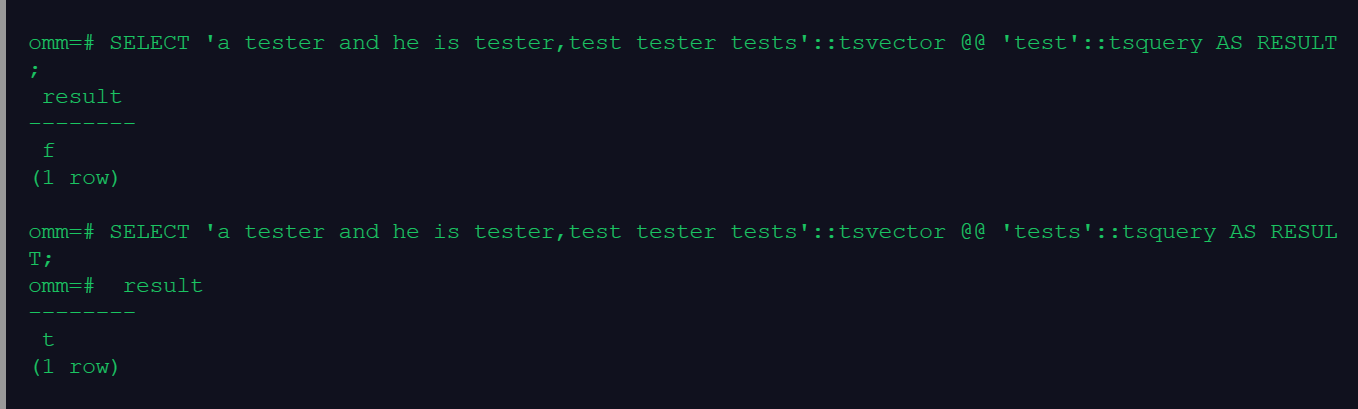
SELECT 'a tester and he is tester,test tester tests'::tsvector @@ 'test'::tsquery AS RESULT;
SELECT 'a tester and he is tester,test tester tests'::tsvector @@ 'tester,test'::tsquery AS RESULT;
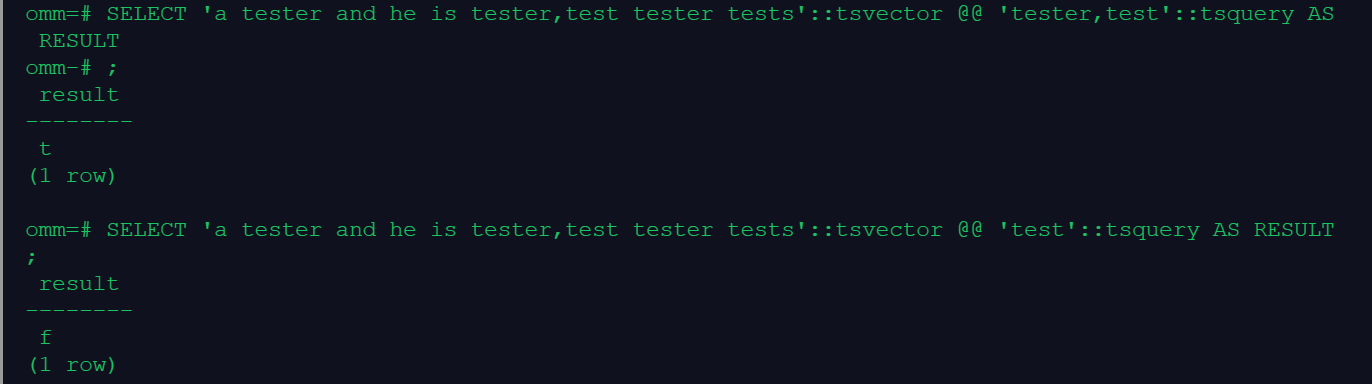
SELECT 'test & tester'::tsquery @@ 'a tester and he is tester,test tester tests'::tsvector AS RESULT;
SELECT 'tester & tests'::tsquery @@ 'a tester and he is tester,test tester tests'::tsvector AS RESULT;
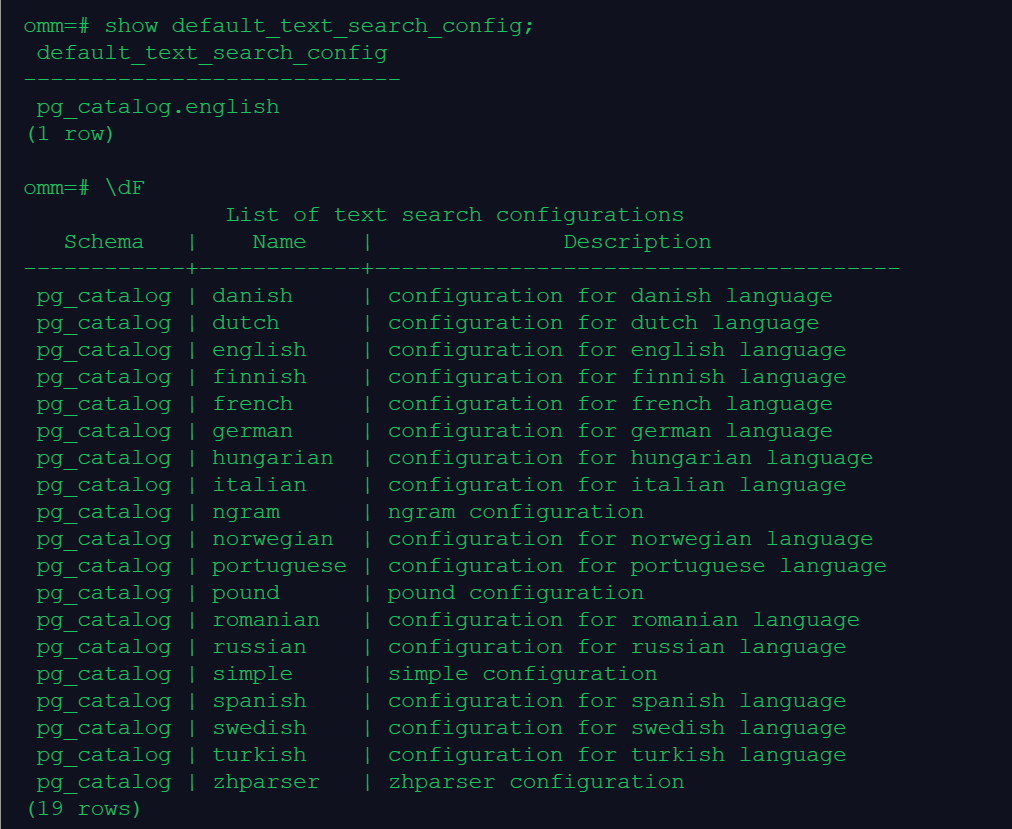
--查看所有分词器
\dF
--查看默认分词器
show default_text_search_config;
2.创建表且至少有两个字段的类型为 text类型,在创建索引前进行全文检索
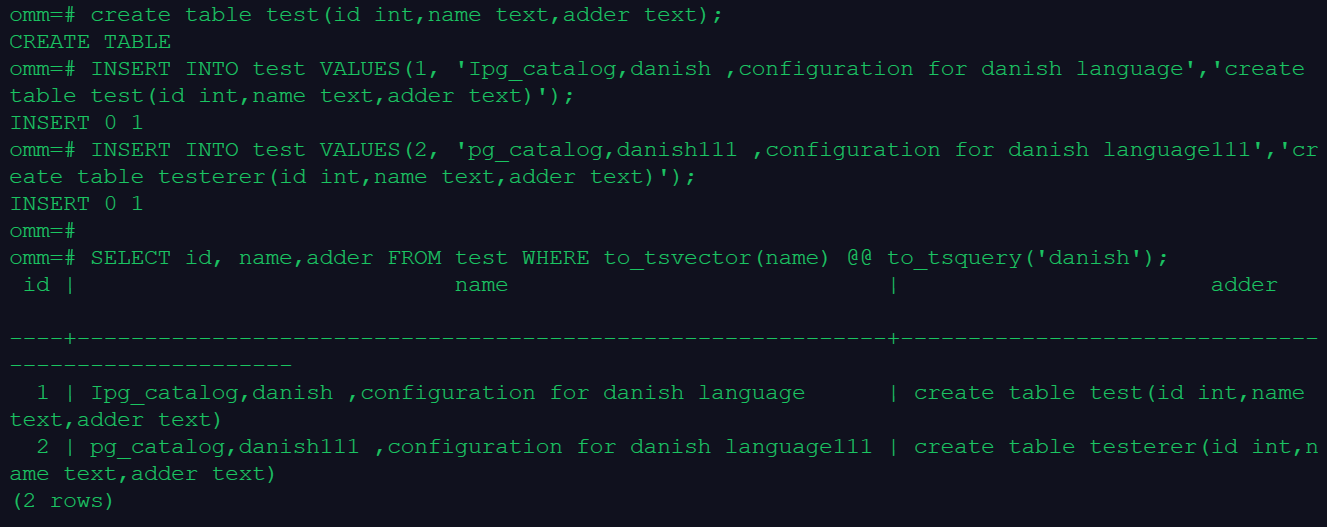
create table test(id int,name text,adder text);
INSERT INTO test VALUES(1, 'Ipg_catalog,danish ,configuration for danish language','create table test(id int,name text,adder text)');
INSERT INTO test VALUES(2, 'pg_catalog,danish111 ,configuration for danish language111','create table testerer(id int,name text,adder text)');
SELECT id, name,adder FROM test WHERE to_tsvector(name) @@ to_tsquery('danish');
3.创建GIN索引
--为了加速文本搜索,可以创建GIN索引(指定english配置来解析和规范化字符串)
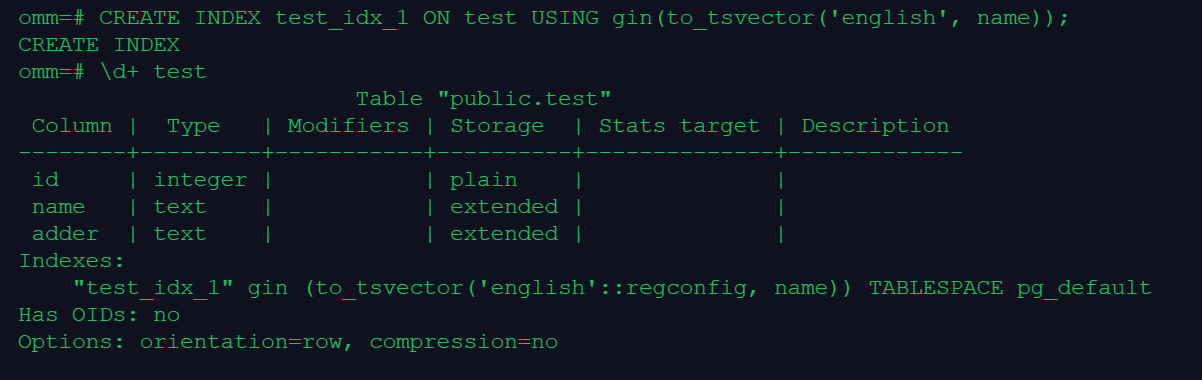
CREATE INDEX test_idx_1 ON test USING gin(to_tsvector('english', name));
\d+ test
4.清理数据
drop table test;