在Oracle Data Science当中集成了我们做数据分析及机器学习经常使用的工具包,并提供如命令行工具等丰富的功能与插件,比大家目前使用的开源平台更加灵活稳定。
在上一篇文章中,为大家介绍了如何搭建Oracle Data Science环境。今天就与大家一起使用我们之前搭建好的环境对纽约民宿数据进行简要分析。
我们的分析目标如下:
了解数据情况
找出最受欢迎的10个房主
了解房屋价格在地区上的分布
了解房屋数量在地区上的分布
首先我们回顾一下上一篇文章(手把手教你:搭建Data Science环境)中的内容,我们创建好notebook,点击下方红色框所示的Open,进入notebook。
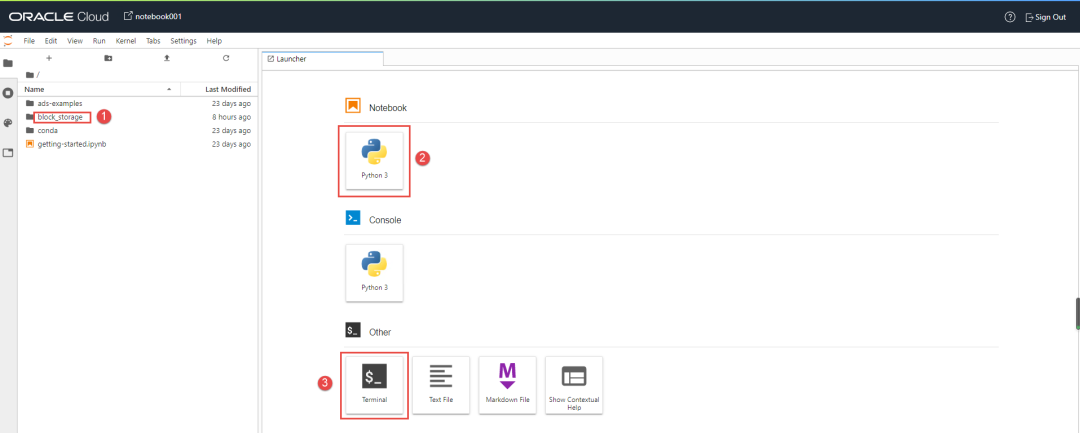
在下图中(1)所示是我们在创建notebook环境时指定的块存储,我们稍后使用的数据文件或者需要保存的ipynb都放在这里。因为我们现在所使用的notebook是运行在一台OCI的虚拟机上的,当我们不用的时候,可以在上图中点击Deactivate将虚拟机停掉,虚拟机停掉之后,计算资源的计费就会停止,在块存储以外的东西也将被删除,所以要将打算保留的文件放在下图(1)所示的block_storage当中。在下图(2)所示,就是我们编程的环境啦,而(3)所示的是命令行工具,在这里可以做常规的操作系统操作。
接下来我们就开始我们今天的数据探索之旅吧,首先将Python环境和命令行工具都打开,按上图中(2)图标开启记事本,如果不喜欢默认的名字,可以在记事本标题上用右键点击,在弹出菜单中选择修改名称。

然后点击上图中红色箭头所指的加号按钮,添加一个命令行环境。点击下图红色框所示区域。

为了防止我们的notebook由于实例关闭而丢失,将ipynb文件拖入block_storage。
现在开始我们的数据分析:
第一步:载入数据
来到block_storage,然后点击下图中(2)所示的上传按钮,将数据文件导入。请点击左下角“阅读原文”获取数据文件及程序下载链接,该链接将在2020年4月1日失效,请提早下载。

文件上传之后的效果如下:

来到命令行,观察文件位置与大小。

第二步:打开数据文件,并了解数据情况

上面是了解前3条记录的形态,接下来我们想知道该数据集内部有多少条记录,数据类型是怎样的,每个字段的空值情况,执行下面红色标记语句即可。
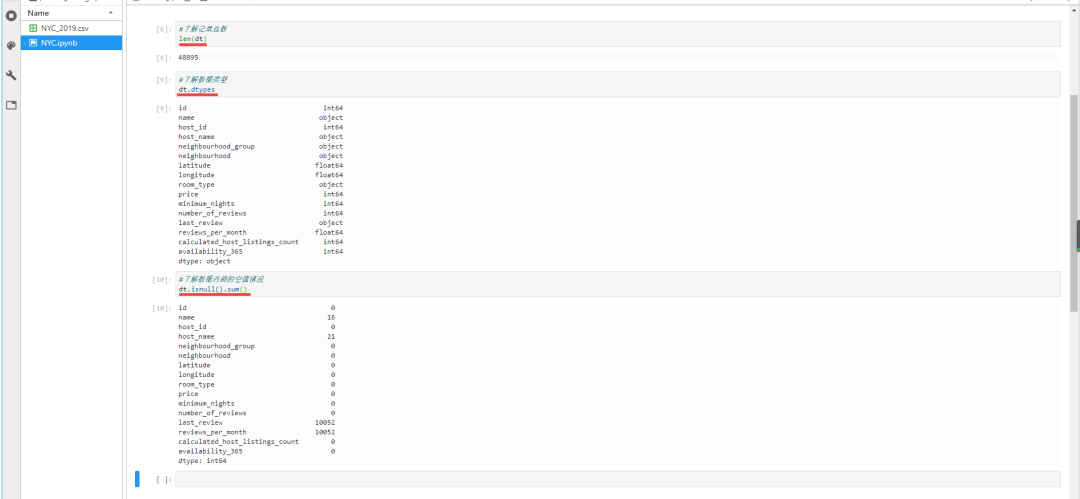
通过观察发现,last_review和reviews_per_month存在大量的空值,我们现在对这些空值做简单的处理,因为我们觉得last_review对我们的分析影响不大,可以直接删除。reviews_per_month的空值用0代替。同时,我们觉得数据中的id和host_name涉及隐私,所以也一并删除。

在我们之前观察数据中,发现这个数据集里面有两个和房屋区域相关的字段,一个是neighbourhood_group ,另一个是neighbourhood。我们现在来了解一下这两个字段中,有多少个唯一值。

第三步:了解出租最火爆的10个host_id
在众多的房主当中,我们现在想了解出租房屋次数最多的10个房主ID。

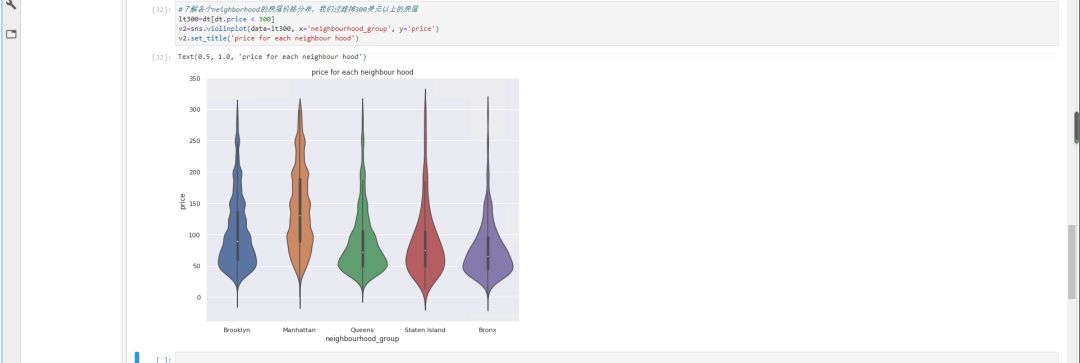
第四步:了解各个城区的房价分布
在上面的分析中,我们知道neighbourhood_group有若干个不同的值,代表房屋所在的区域,现在我们想了解这些区域的房屋价格分布,我们今天使用“小提琴图”来显示。并且,我们过滤掉价格超过300美元的房屋。
第五步:了解具体社区房屋分布情况情况
刚才我们看的是大的区域,现在我们看看各个社区房屋供给情况,我们显示有房屋出租的top 5社区。并且按照房屋类型进行分类显示。

第六步:在地图上显示房屋分布情况
我们事先下载好纽约的地图,并将该地图作为散点图的背景,之后限定地区显示区域,根据经纬度设定为主要城区,然后使用散点图显示房屋出租的情况,因为原始数据当中带有该房屋的经纬度,所以和背景地图能够准确地进行融合。通过观察下图,我们发现在纽约主城区沿海部分的房屋价格较高,而在城区内部靠近东南侧的房屋价格相对较低。

对于这份数据集的探索,先到这里,您可以在自己的环境中继续探索。通过今天的例子,主要向您展示通过Oracle Data Science进行数据分析的过程。
第七步:关闭notebook节省费用
notebook是构建在OCI的虚拟机上的,当您完成了数据分析,可以将notebook禁用,从而节省费用。
我们会在后面继续为大家提供相关的分析文章,期待您的关注,谢谢!
本文数据集来自网络,使用代码原型参考自网络。点击“阅读原文”下载相关文件,有效期至2020年4月1日。
扫描下方QR Code即刻预约ADW演示

编辑:殷海英