




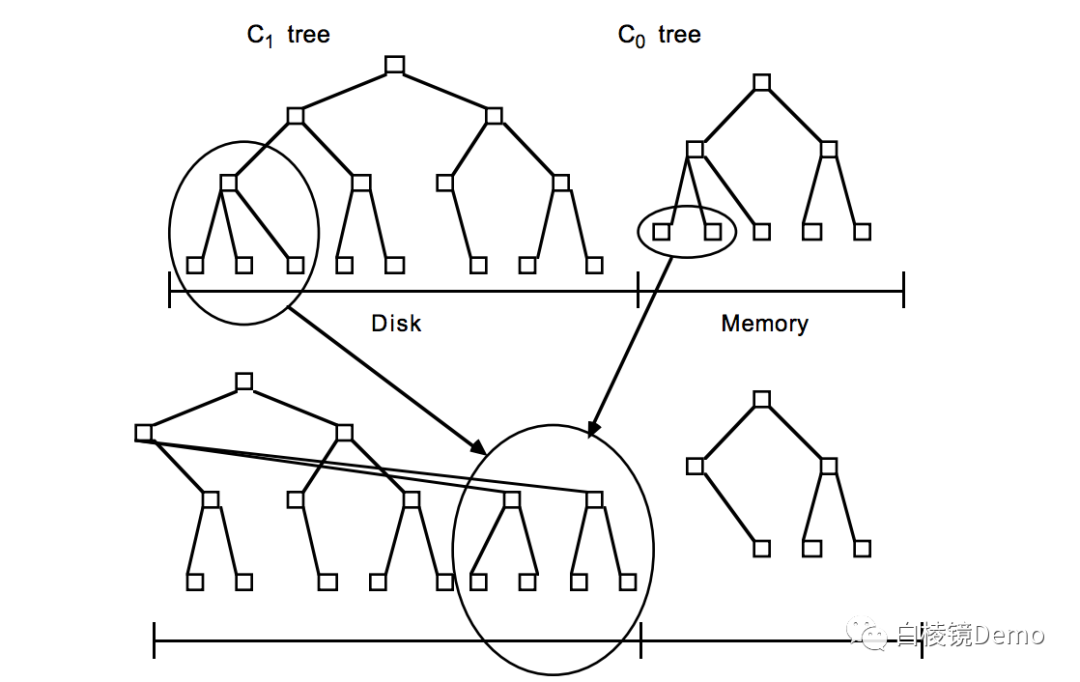
•作为一个KV存储引擎,读写数据和存储数据当然是最最基本和重要的的操作。我们通过对读写操作的熟悉,来了解leveldb内部的一些实现。•我们知道leveldb的数据是存储在磁盘上的,并且使用了LSM-Tree(Log-Structured Merge-Tree)结构来实现。和随机对磁盘的读写相比,顺序对磁盘的读写拥有更高的性能,而LSM-Tree正是将对磁盘的随机写转化为顺序写,大大的提升了写入的速度。为了达到这个目的,LSM-Tree将索引树分成了一大一小两棵树(见下图),比较小的的常驻内存,比较大的就保存在磁盘上。这样他们两个共同维护着一个有序的KV空间。写入的数据会直接写到内存中的树,等待内存中的空间膨胀到一定大小,就会触发他的Compaction操作,本质就是一个归并排序,所以我们这里先叫这个过程为归并,后面再解释Compaction操作。而且归并操作的本质也是顺序写。另一方面,随着数据的写入,磁盘中的数据也会不断膨胀,这里为了优化读取数据的速度和避免每次归并操作数据量太大,leveldb将磁盘上的数据分成了很多文件,并且规定了若干文件会构成一个层(每一层的数据比上一层数据成倍数关系增长)的概念,所以当某一层的文件(也就是数据量)达到一定数量之后,就会触发向下一层的归并操作。这就是leveldb名字的由来。
0.一些基本概念
•开始之前,先介绍一些leveldb的重要文件。
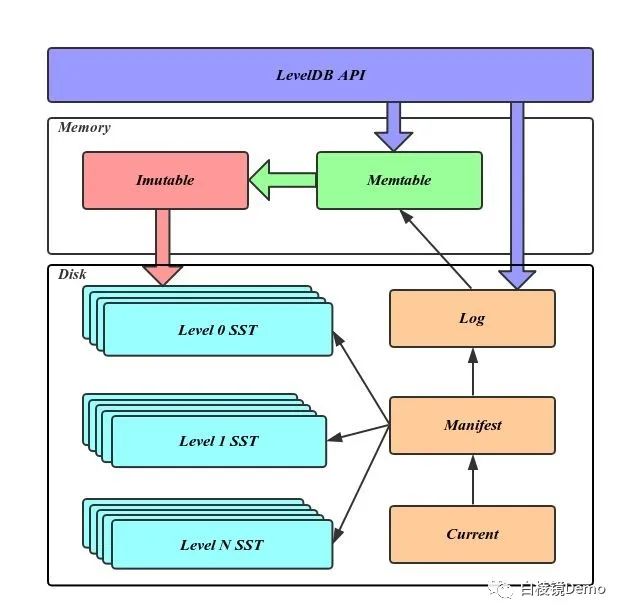
0.1 memtable
•内存中的数据结构,最新的数据会写到这里,底层通过跳表实现。
0.2 log文件
•写入memtable之前会先写入磁盘的log文件,log是顺序追加的方式写入(append),log存在的目的是用于宕机后数据的恢复。
0.3 immutable memtable
•顾名思义,不变的memtable。用于当memtable的写入量到达阈值后,memtable就会变成immutable memtable,此时他只能读取,不能在接受数据写入,这个时候会有新的memtable生成用于接受新的写入请求。•后边做compaction的时候,会dump immutable到磁盘上变成sst文件。
0.4 sst文件:
•全称:Sorted String Table,就如名字所言,它是一个内部包含了任意长度、排好序的键值对<key,value>集合的文件。•在磁盘上用于存储数据的文件。•分为level 0到level n的若干层,每一层都包含了多个sst文件。•单层的sst文件总量随着层次的增加而成倍增加。•level 0层的sst文件由immutable 直接 dump 而成,其他层的sst文件都是由上一层的文件和本层的文件进程归并操作而产生。•sst文件在归并操作过程中通过顺序写入产生,生成后只读,仅仅在之后的归并操作中删除。
0.5 manifest文件
•manifest 文件中记录着sst文件处于的不同 level 信息,还记录着单个sst文件最大、最下key,以及一些其他的 leveldb 的元信息。•可以有多个。
0.6 current文件
•由于 manifest 文件可以有多个,每当 leveldb 启动的时候要找到具体的 manifest 文件,所以 current 文件就记录了当前的 manifest 文件,使得这个过程变的很简单。
1.读写流程
1.1写流程
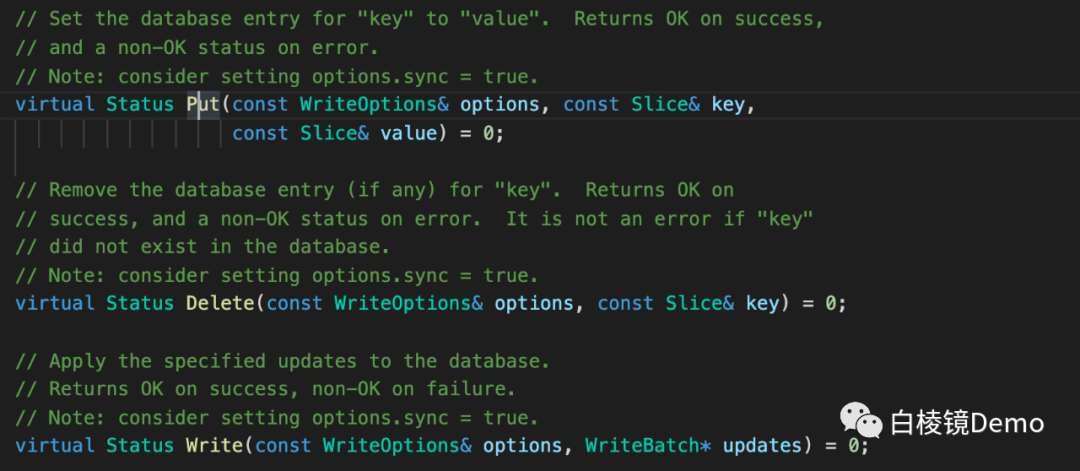
•leveldb 写操作分为插入kv和删除 key 两种。而删除操作是插入了一条标记类型为删除状态的的数据。这样看来,插入和删除操作的本质是一样的。因为他将随写转变为顺序写:一个写入操作首先顺序在 log 文件中写入操作记录,然后写入 memtable 就可以返回了,这也就造就了他写入速度快的有点。•leveldb 提供了 Put、Delete、Write 接口用于写入操作。我们看下函数原型:
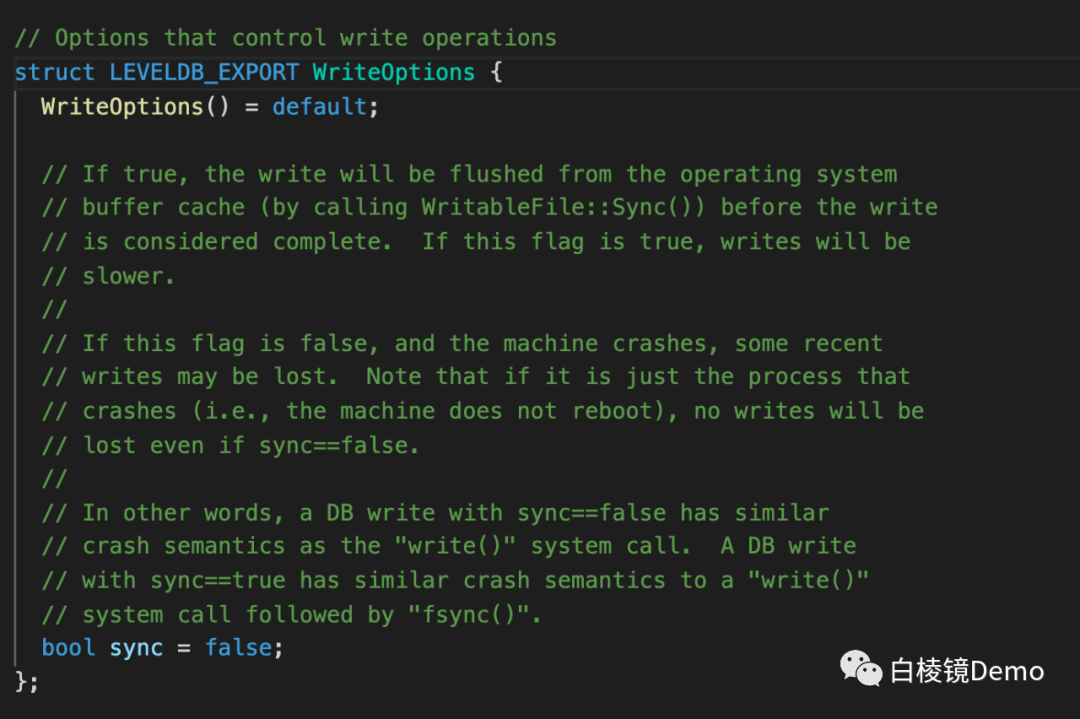
•这里要说下 WriteOptions 这个结构,可以看到只有一个选项就是 sync,用于控制写 log 的时候是直接刷盘还是交给操作系统异步完成刷盘操作。
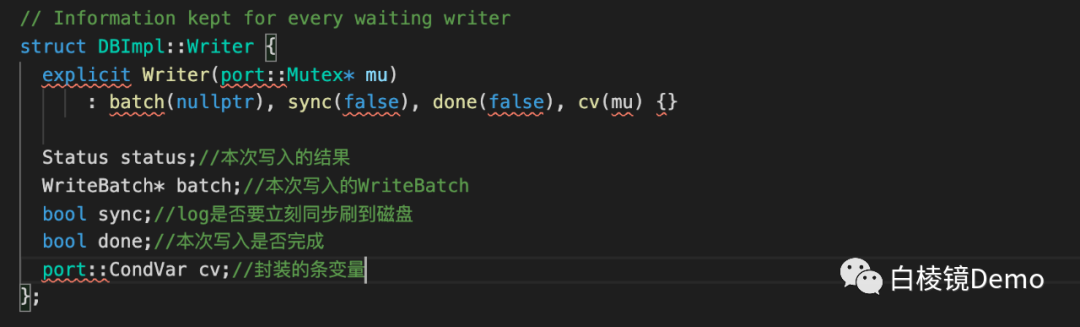
•其中Write需要WriteBatch作为参数,而Put和Delete首先就是将当前的操作封装到一个WriteBatch对象,并调用Write接口。这里的WriteBatch是一批写操作的集合,其存在的意义在于提高写入效率,并提供Batch内所有写入的原子性。•WriteBatch的实现也不难,前8个字节是一个sequence number(Memtable的每次写入都会带一个递增的序列号,用作实现snapshot和区分同一个key多次复写的先后顺序,WriteBatch里的所有写入带的是同样的序列号),紧跟着4个字节是count代表这个WriteBatch中打包了几条操作,然后便依次是每条操作的记录(Type, key, [value]),这个WriteBatch构造好之后,就传给DBImpl::Write函数来做真正的写入。
DBImpl::Put -> DB::Put -> DBImpl::Write
•Write的主要代码:
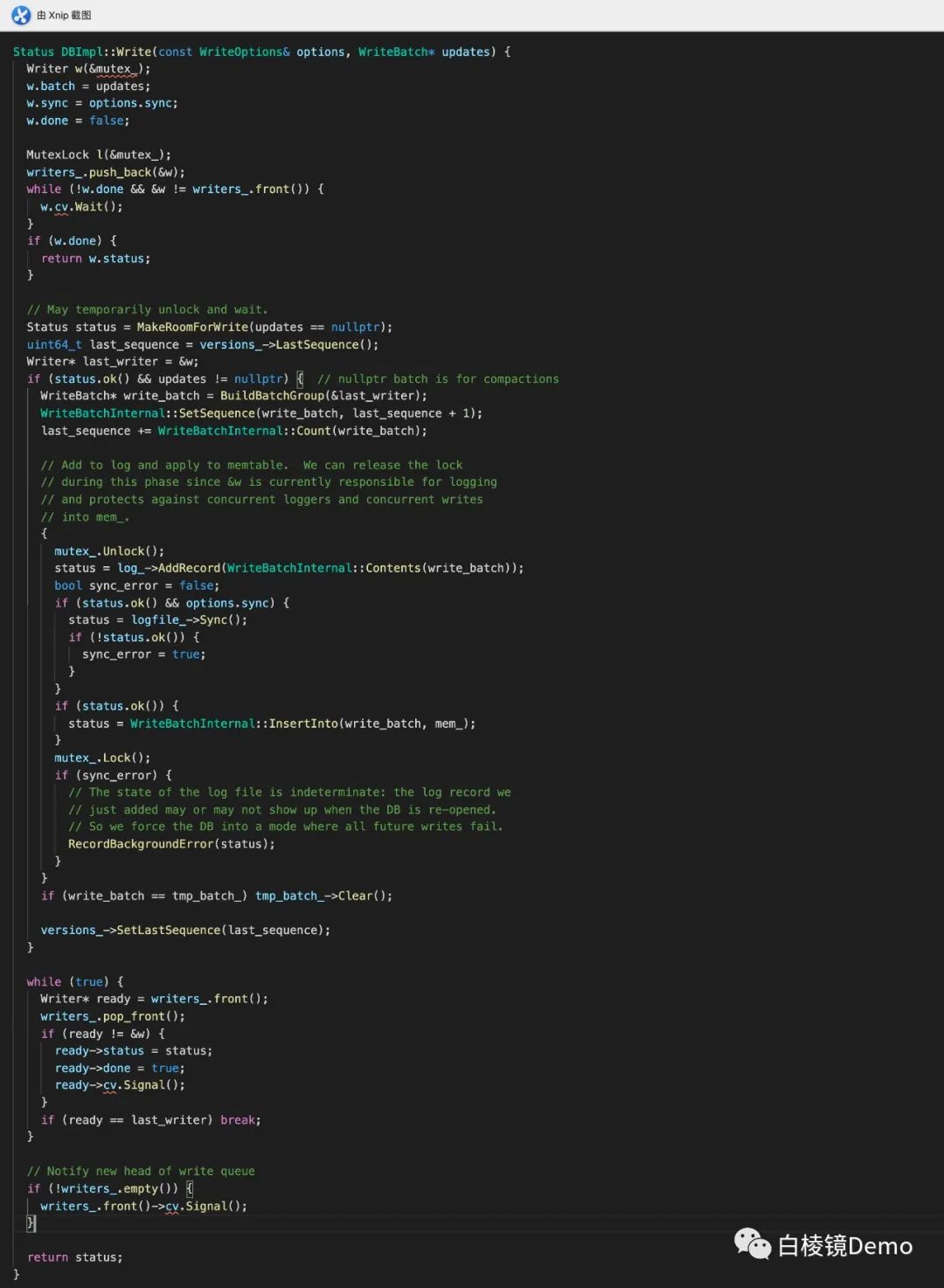
•结合上边的代码,我们详细分析系写入的过程:
•WriteBatch封装一个Writer
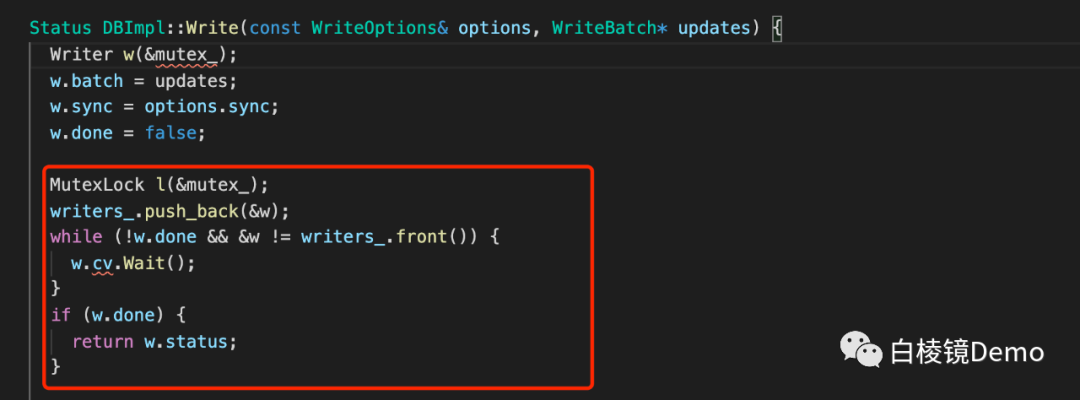
•接下来是一个很精彩的地方,这里一进来就先加了一个锁,多个线程的写入会在这个地方互斥阻塞,只有第一个获取到锁的线程继续前进。这个地方先记录一个小思考,为什么要判断write是否完成和是否是最前面的一个,以及为什么满足条件后悔被挂起。
•下边就是具体的一些写入操作:
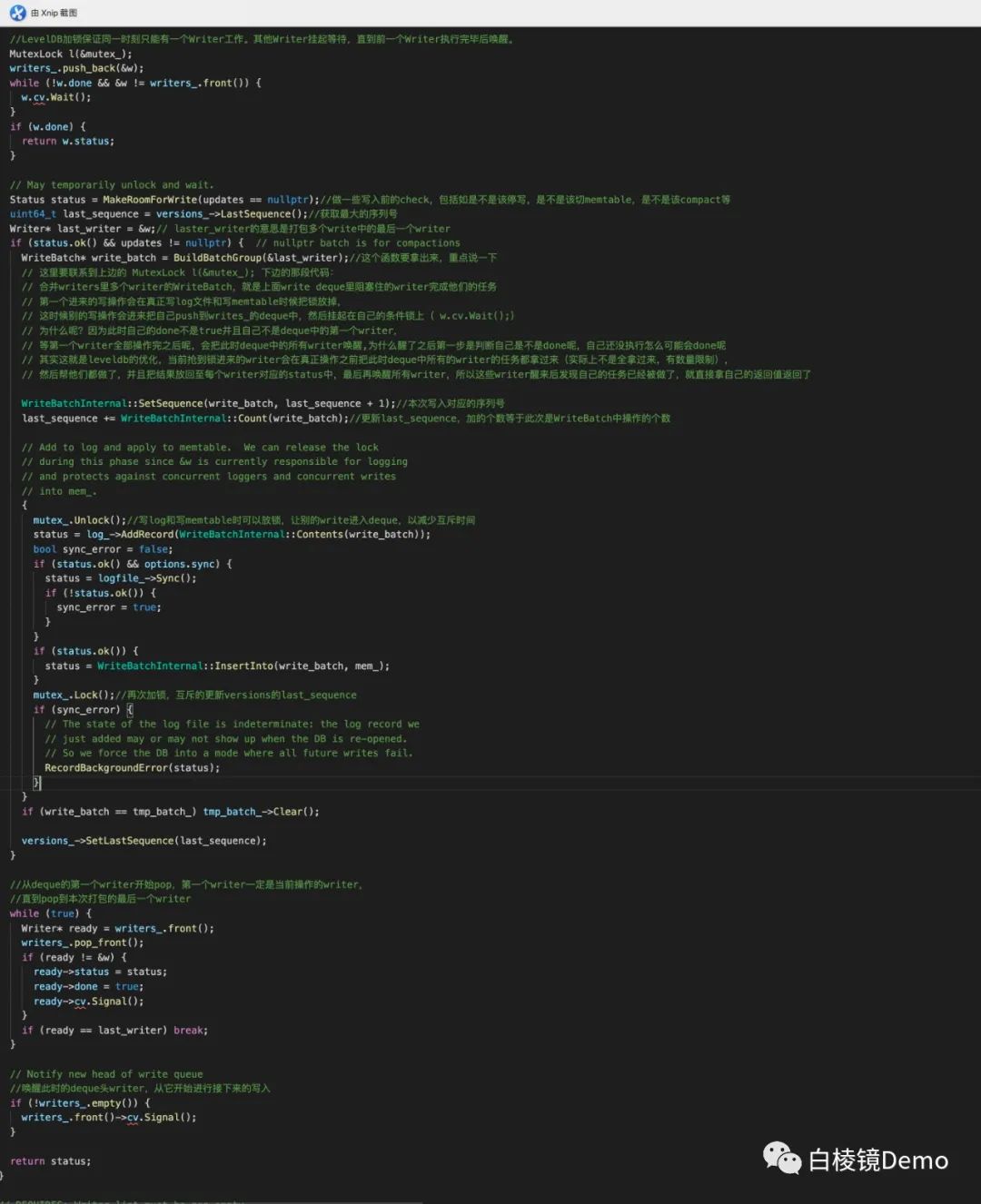
•注意更新lastSequence这行代码,在所有的值写入完成后才将Sequence真正更新,而leveldb的读请求又是基于Sequence的。这样就保证了在WriteBatch写入过程中,不会被读请求部分看到,从而提供了原子性。
1.2读流程
•首先,生成内部查询所用的key,这个key是由用户请求的UserKey拼接上Sequence生成的。其中Sequence可以用户提供或使用当前最新的Sequence,当然leveldb可以保证仅查询在这个Sequence之前的写入。•用上面生成的Key,依次尝试从 memtable,immtable以及sst文件中读取,直到找到。•从sst文件中查找需要依次尝试在每一层中读取,得益于manifest中记录的每个文件的key区间,我们可以很方便的知道某个key是否在文件中。Level0的文件由于直接由immutable Dump 产生,不可避免的会相互重叠,所以需要对每个文件依次查找。对于其他层次,由于归并过程保证了其互相不重叠且有序,二分查找的方式提供了更好的查询效率。•可以看出同一个key出现在上层的操作会屏蔽下层的。也因此删除key时只需要在memtable压入一条标记为删除的条目即可。被其屏蔽的所有条目会在之后的归并过程中清除。
