




skiplist查找效率很高,堪比优化过的二叉平衡树(红黑树),且比平衡树的实现简单,查找单个key,skiplist和平衡树的时间复杂度都为O(log n)。平衡树的插入和删除操作可能引发树的旋转调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
skiplist首先它是一个list。实际上,它是在有序链表的基础上发展起来的。先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

这样种链表中,如果要查找某个数据,需要从头开始逐个进行比较,直到找到等于 或 大于(没找到)给定数据为止,时间复杂度为O(n)。同样,当插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
有了上面出现的问题后进一步优化,假如我们这样来设计,在每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当查找数据的时候,可以先沿着这个新链表(第一层链表)进行查找。当碰到比待查数据大的节点时,再回到第二层链表进行查找。
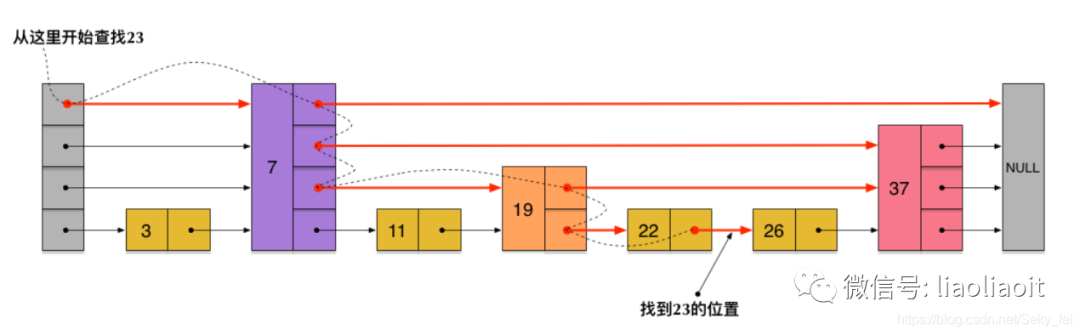
比如,要查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:整个查询路线如红色箭头。

先在第一层链表上查询,23首先和7比较,再和19比较,比它们都大,继续向后比较。但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
再在第二层链表上查询,23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,不再需要向原链表一样,每个节点都逐个进行比较。需要比较的节点数大概只有原来的一半。 利用同样的方式,可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的,实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如:一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。
skiplist中一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。而节点的层数(level)也不全是没有规则随机的,而是按照节点平均指针数目计算出来的。如下图各个节点层数(level)是随机出来的一个skiplist,我们依然查找23,查找路径如图:
skiplist与平衡树、哈希表的比较
skiplist 和 各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。
平衡树的插入 和 删除操作可能引发树的旋转调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。
从内存占用上来说,skiplist比平衡树更灵活一些。平衡树一般每个节点包含2个指针,而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于一个概率参数p。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
