




前言
小y将通过一个数据库HANG住的实战案例,与大家分享数据库底层trace的分析技巧!
这些技巧,我们通常传内不传外!
今晚分享和直播,诚意十足,错过无回放!大家记得预约哦!
也希望大家在方便的情况下帮忙转发和分享给大家,您的支持是我们持续分享干货的动力!
1. 问题来了
企业微信响了,是公司服务台发过来的信息,需要协助二线同事进行一个疑难问题的分析。说到这里,大家可能知道了,小y在公司主要负责三线的工作,而所在公司中亦科技主要为各大型数据中心和开发中心提供数据库第三方专家支持服务。
给二线的同事打了个电话,他大概给我介绍了一下这个客户出现的故障:
“客户的一个Linux上2节点的19C的RAC数据库,大约在14:58-15:47,总计约50分钟,出现数据库HANG死的情况,期间无法登录数据库。通过重启数据库后恢复。遗憾的是,没有收集systemstate DUMP和hanganalyze信息。随后我会将TFA信息、AWR报告、ASH DUMP信息转你,客户需要分析故障的根本原因,预防问题再次发生。”
听到这里,皱了皱眉头,哎,又是没有收集systemstate DUMP和hanganalyze信息的情况。看起来,又是一场苦战了。
文章到这里,大家不妨停一下,思考一下,如果是你,接下来你打算分几步来分析,又需要哪些信息来帮助你找到问题的根本原因呢…
思考时间
……
什么时候往下翻,由你决定
……
2. 确认一下问题
2.1 节点1 ASH数据确认异常
小y将ASH DUMP导入自己的数据库后,发出下列查询获取DB活动会话的变化情况

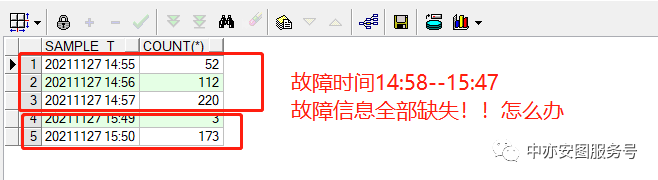
看到这里,可能有不少同学就茫然了!
ASH这么关键的数据,期间因为数据库异常没有采集到,而且数据库已经重启了。
接下来还怎么分析呀…
2.2 节点2 ASH数据显示节点2是受害者
节点2结果如下所示:
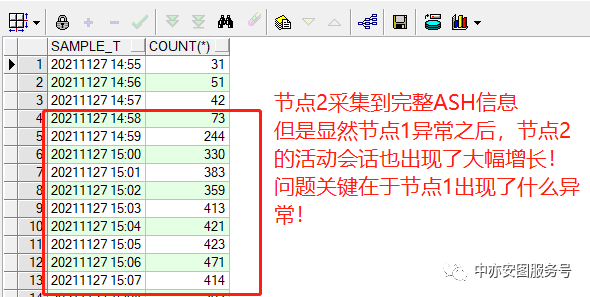
节点2在14:58开始,同时段也出现了活动会话的大幅增长。
显然,节点2是受害者!因此,接下来我们把分析重点放在节点1上!
3. 进入问题分析之旅
3.1 ALERT日志分析
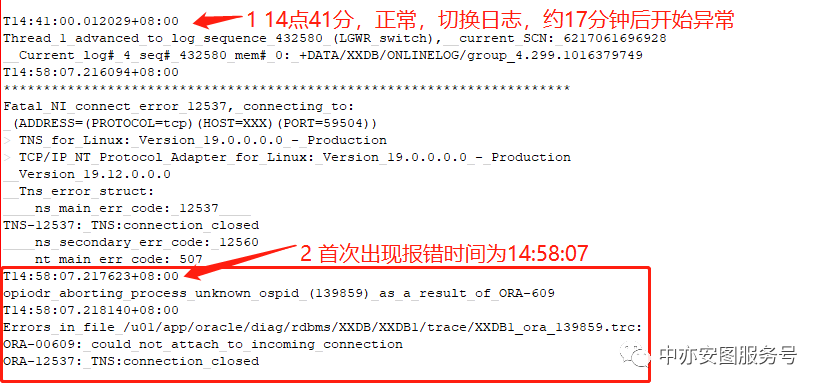
可以看到:
▪ 14点41分,还在正常切换日志
▪ 14:58分,开始出现ORA-609和ORA-12537的报错,这些报错通常表示建立连接超时后退出,因此是TNS:connection closed和could not attach to incoming connection的报错。
这和客户的现象就基本对应上了,故障期间无法连接到数据库。
继续往下分析alert日志,如下图所示:
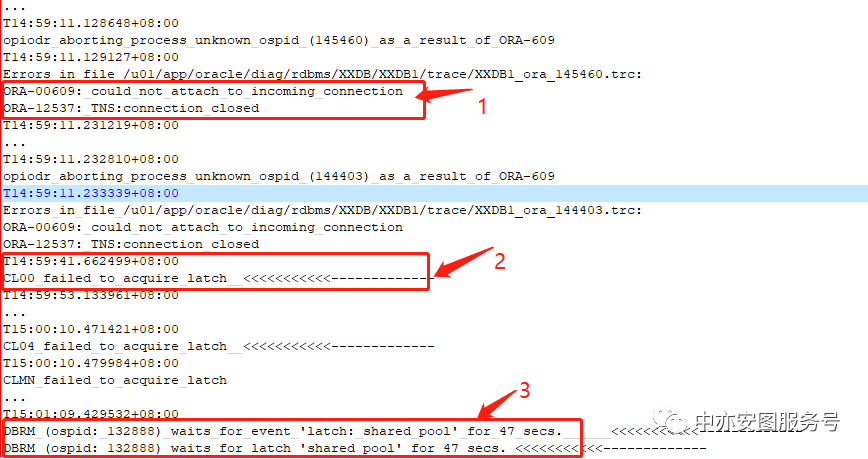
可以看到:
▪ 频繁出现TNS:connection closed和could not attach to incoming connection的报错
▪ 后台的slave进程CL00/CLMN无法获取latch,报failed to acquire latch。Latch是轻量级的资源,正常无争用状态都在毫秒级以下获取到,显然,数据库出现了异常,latch持有者出现了异常,拿到latch后的工作没有那么顺利,导致latch长时间不释放,影响到了其他会话无法获取latch。但这里没有显示是什么latch
▪ 信息显示DBRM后台进程已经超过47秒都申请不到shared pool的latch了!正常无争用状态都在毫秒级以下获取到latch.有争用的情况下,几十毫秒几百毫秒也该获取到了。47秒,实在是太久了!
继续往下翻alert日志,如下图所示:
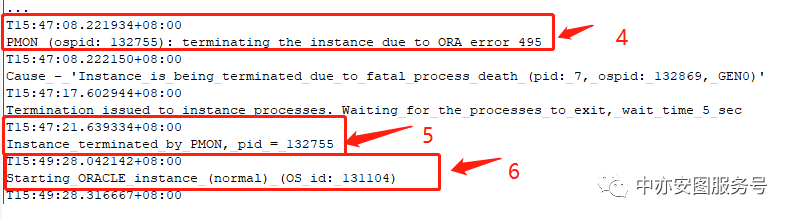

可以看到:
▪ 15点47分,在故障开始后的50分钟后,PMON因为ORA-405错误主动终止了实例!
▪ ORA-405错误表示GEN0后台进程异常终止,PMON发现GEN0后台进程异常终止,主动终止了实例。
3.2 典型的受害者-会话信息


可以看到:
▪ 会话12952等待latch: shared pool等了47802毫秒=47秒。
▪ 以10秒为间隔,该会话被连续采样到多次!其他会话类似。
▪ 但是ASH信息中显然BLOCKING_SESSION即BSID是空的,不知道阻塞者是谁!
▪ 那么ASH信息对于我们找到问题的真相,就帮助不大了!
3.3 复习一下什么是latch:shared pool等待
举一个简单场景的例子,很容易就说明白了。
当一个会话首次执行某个SQL,就需要做硬解析,那么就需要申请一片空闲的SGA共享内存用来存储SQL语句、SQL执行计划等信息
系统在有一核CPU的时候,这个时候问题不大,但是多核CPU ,SMP架构下,多进程情况下,问题就来了,多个进程可能需要同时申请内存空间!
多个进程可以在不同的CPU核上运行,因此为了避免不同进程同时分配到一片共享内存的空间,就需要一个并发的控制机制,即只能在某片空间内串行申请!
没有并发控制,不同进程同时分配到一片内存空间,就出现memory corruption了!
latch:shared pool简而言之就是这样的一个内存并发访问的串行控制机制!
当需要分配shared pool空间的时间,必须先拿到latch,才能去申请内存!
在此期间,其他无法获得latch的就需要发生等待!
需要注意的是,申请latch:shared pool的场景很多很多。
前文所举例的硬解析只是其中一种常见场景。
那么latch:shared pool等待和我们无法登录数据库有什么关系呢?
登录数据库,也需要执行一些内部SQL的,这些SQL如果发生硬解析,此时无法获取latch:shared pool,则SQL在解析阶段卡住,那么登录数据库也就HANG住了
进程要分配内存,需要获得process的内存修改的控制权,需要分配内存空间存储新建连接的相关信息,也需要申请latch:shared pool
......
4. 思考时间
好的,阶段性的信息已经有了,接下来你会用什么方法论来分析这个问题呢?
……
什么时候往下翻,由你决定
……
5. 用方法论分析问题
5.1 方法论是什么
阻塞链的分析,是我们处理该类问题的分析方法论。
我们需要找到是谁持有了latch:shared pool,他又在等什么,如果没有在等什么,而是ON CPU,我们需要知道他的call stack是什么,通过阻塞源头的等待事件或ON CPU的CALL STACK来判断为什么长时间持有latch了,从而找到问题的根因!
在此方法论下,ASH/DIAG/HANG ANALYZE/SYSTEMSTATE DUMP等都只是实现根因分析的工具而已。你需要掌握的是底层trace的分析技巧,再结合原理,给出结论即可。
当然存在不同类型问题的不同方法论!
通常,这些方法论和技巧我们通常传内不传外。
如果你想全面的技术提升以及获得良好的发展空间,欢迎加入小y所在的中亦科技!
在这里,你可以挑战不同客户超大并发超大数据量的各种数据库疑难杂症!
//当前,我们开放如下地区和职位:
(1)Oracle DBA职位:
北京、上海、深圳、广州、呼和浩特、昆明
(2)MySQL DBA职位:
北京、上海、长春、杭州

5.2 DIAG trace分析
在发现数据库出现异常等待时(非应用控制的等待),数据库将会侦测并生成相关trace用来做原因分析。
DIAG进程就是负责生产trace的后台进程。这个可诊断可回溯的功能,Oracle数据库做的很强,也是相比其他数据库强很多的地方。
不过,也还存在很多不完美的地方。继续往下阅读,你就会发现我说的不完美是什么了…
接下来请大家跟随小y一起来阅读下diag的trace…
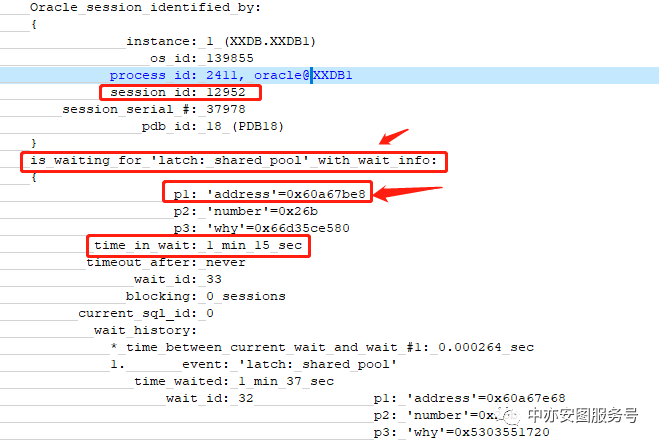
可以看到:
Diag生成了hanganalyze的信息。
其中记录了SID=12592的会话在等待latch:shared pool,但是不知道阻塞者是谁。
出现问题的时候,并没有自动生成 systemstate dump的信息。也就无法找到阻塞者以及阻塞者在等什么,call stack是什么…
按照方法论,我们无法知道阻塞者,是无法继续分析的。
到这里,不完美的第一个地方就出现了,虽然生成信息,但是只生成了简单的hanganalyze信息,目前为止diag的trace对我们进一步的分析,帮助不大。
那么接下来该如何分析呢…...
......
5.3 CL00/PMON进程(无法获得latch)trace分析
按照之前的 alert日志,我们知道包括CL00/CLMN/PMON在内的后台进程,出现了无法获得latch的报错信息。
那么数据库这个时候,做的好的话,应该会将相关信息打印出来。
我们是不是从这些报错进程的trace里可以找到问题的真相呢。
我们往下分析,相关进程trace如下图所示:
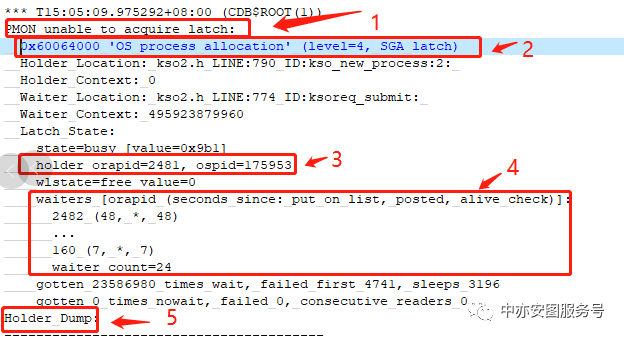
可以看到:
▪标记1和2显示PMON无法获得latch:OS process allocation,即无法获得分配操作系统进程的latch/控制权
▪ 标记3显示阻塞者是orapid=2481的会话
▪ 标记4显示同样无法获得该latch的会话一共有24个!
▪ 看到标记5,大家是否有点兴奋了,是的,Oracle会将latch: OS process allocation的持有者的相关信息进一步做dump动作!
接下来我们继续阅读trace,获得latch: OS process allocation的持有者的相关信息,如下所示:
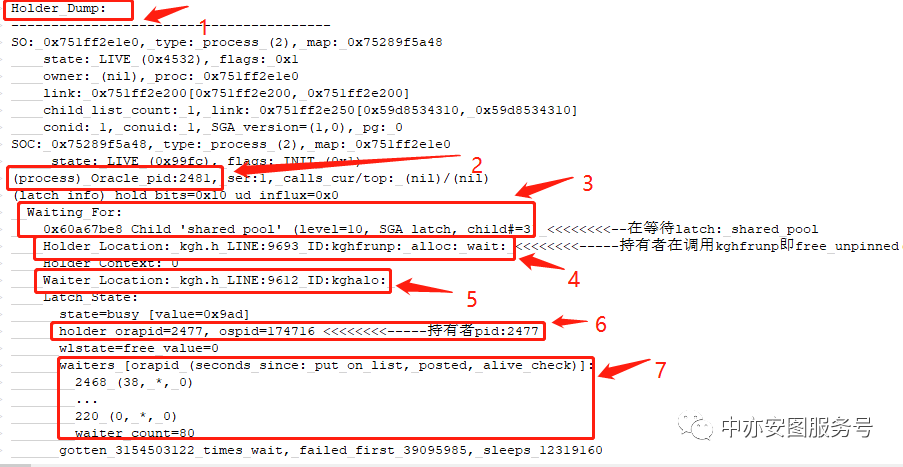
可以看到:
▪ 标记2显示该进程就是pid=2481的阻塞者
▪ 标记3显示该进程在持有latch: OS process allocation的情况下,转而申请latch:shared pool,但是申请不到!因此进程无法分配,无法新创建连接。
▪标记5显示pid=2481的会话,通过kghalo申请了latch:shared pool,kgh是内存管理的模块,alo就是allocate的简称,分配的意思
▪ 标记6显示latch:shared pool的持有者是orapid=2477 !
▪ 标记4显示持有者2477的会话通过kghfrunp持有了latch:shared pool
▪ 标记7显示同样无法获得latch:shared pool的会话一共有80个!
▪ 看到标记5,大家是否有点兴奋了,是的,Oracle会将latch: OS process allocation的持有者的相关信息进一步做dump动作!
那么我们只需要继续往下分析:
latch:shared pool的持有者是orapid=2477 又在等什么?
如果没有处于等待,而是ON CPU,那么call stack是什么?
6. 分析陷入僵局
可惜的是,Oracle数据库的第三个不完美的地方出现了。
Trace中没有再继续做holder dump了。
也就是说,他只做了一级的dump,只dump了直接持有者的相关信息,没有递归的继续做下去,因此虽然知道下一步的阻塞者是orapid=2477的会话,但实际上还是找到源头信息。
继续在diag trace中查找latch:shared pool持有者,搜索关键字pid:2477,结果如下所示
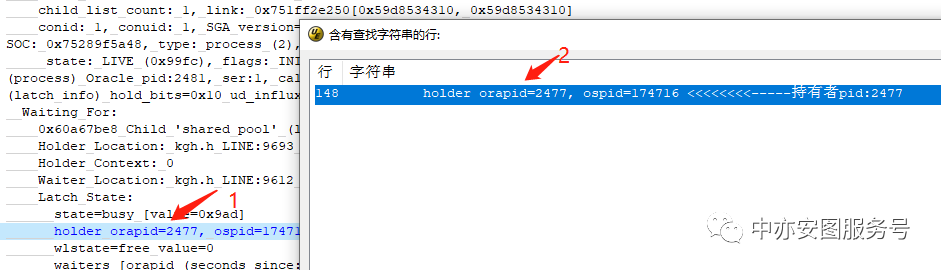
很可惜,diag trace没有打印持有者2477的信息。
Trace目录搜索所有trace,也没有打印持有者pid=2477的信息。
至此,问题陷入了僵局!
此时,你可能知道了,当出现问题时,收集SYSTEMSTATE DUMP是多么重要了!
巧妇难为无米之炊啊!
7. 头脑风暴
接下来怎么分析?
路要怎么往下走呢
接下来是思考时间…
……
不妨再思考思考…
什么时候往下翻,由你决定…
……
解决问题靠的是什么
解决问题,不仅存在术和道的问题,还需要…
8. 真相即将揭晓

请关注上图中的视频号,并预约直播, 12月23日(周四)即晚上八点,小y将用半个小时为大家揭晓真相!记得帮转发,喊上你的朋友一起来参加哦。
如果你也想加入我们,我们开放如下地区和职位:
//可添加公司HR同事的微信进行咨询
(1)Oracle DBA职位:
北京、上海、深圳、广州、呼和浩特、昆明
(2)MySQL DBA职位:
北京、上海、长春、杭州
更多实战分享和风险提示,请关注“中亦安图”公众号和小y视频号!
也可以加小y微信,shadow-huang-bj,进微信群探讨技术。
喜欢就转发吧,您的转发是我们持续分享的动力!
