




断路器Hystrix
应用容错三板斧
超时机制
超时机制你懂的,配置一下超时时间,例如1秒——每次请求在1秒内必须返回,否则到点就把线程掐死,释放资源!
思路:一旦超时,就释放资源。由于释放资源速度较快,应用就不会那么容易被拖死。
舱壁模式
有兴趣的可以先了解一下船舱构造——一般来说,现代的轮船都会分很多舱室,舱室之间用钢板焊死,彼此隔离。这样即使有某个/某些船舱进水,也不会影响其他舱室,浮力够,船不会沉。
软件世界里的仓壁模式可以这样理解:M类使用线程池1,N类使用线程池2,彼此的线程池不同,并且为每个类分配的线程池较小,例如coreSize=10。举个例子:M类调用B服务,N类调用C服务,如果M类和N类使用相同的线程池,那么如果B服务挂了,M类调用B服务的接口并发又很高,你又没有任何保护措施,你的服务就很可能被M类拖死。而如果M类有自己的线程池,N类也有自己的线程池,如果B服务挂了,M类顶多是将自己的线程池占满,不会影响N类的线程池——于是N类依然能正常工作,
思路:不把鸡蛋放在一个篮子里。你有你的线程池,我有我的线程池,你的线程池满了和我没关系,你挂了也和我没关系。
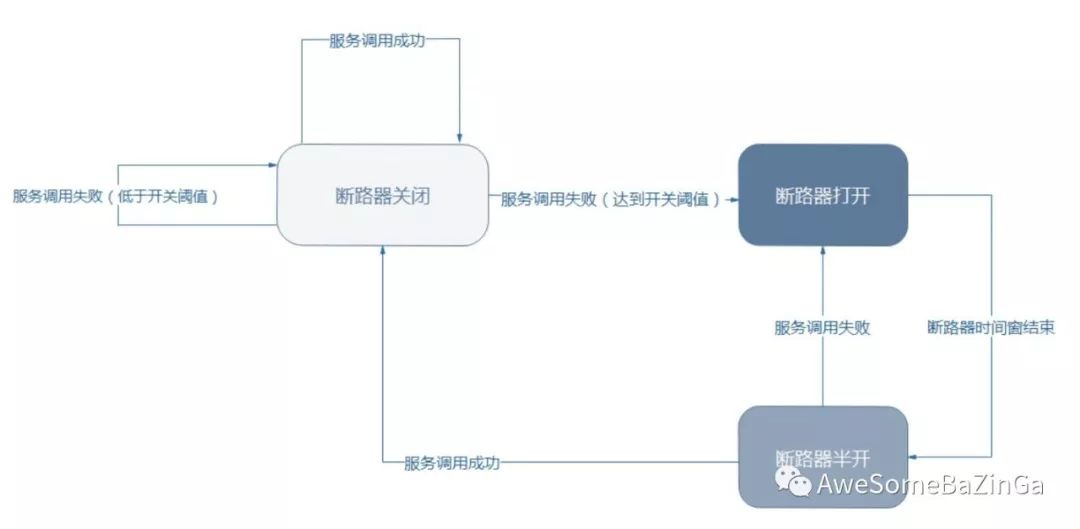
断路器
现实世界的断路器大家肯定都很了解,每个人家里都会有断路器。断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路被烧毁。
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。
跳闸一段时间后(例如15秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的“自我修复“。
1、简介
在货船中,为了防止漏水和火灾的扩散,一般会将货仓进行分割,避免了一个货仓出事导致整艘船沉没的悲剧。同样的,在Hystrix中,也采用了这样的舱壁模式,将系统中的服务提供者隔离起来,一个服务提供者延迟升高或者失败,并不会导致整个系统的失败,同时也能够控制调用这些服务的并发度。
在分布式环境中,许多服务依赖项中的一些必然会失败。Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
2、设计理念
•给依赖于第三方库的应用程序提供给保护•在复杂的分布式系统当中避免级联失败•快速失败并且快速恢复•在可能的情况下提供回退和优雅降级的能力•通过近乎实时的指标,监控和警报来优化发现故障的时间
3、解决什么问题
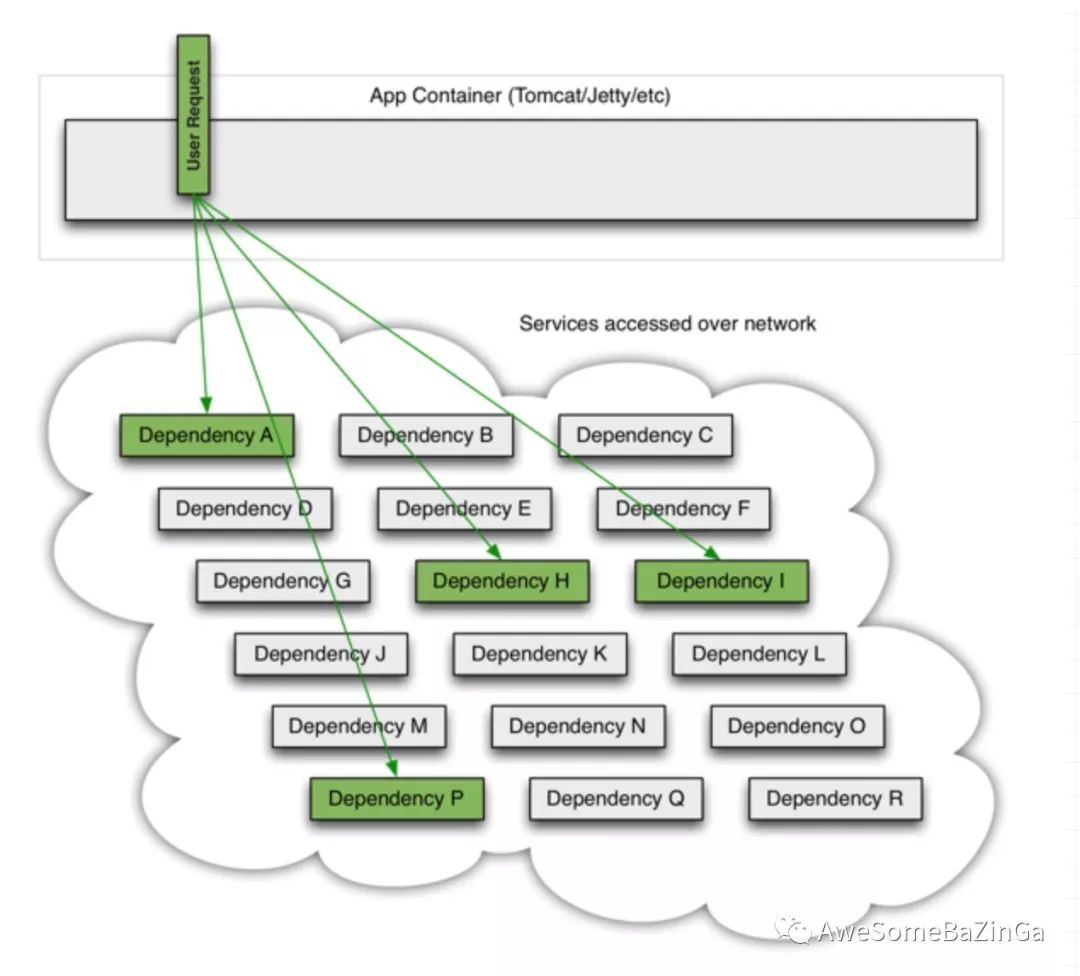
复杂分布式体系结构中的应用程序有许多依赖项,每个依赖项在某些时候都不可避免地会失败。如果主机应用程序没有与这些外部故障隔离,那么它有可能被他们拖垮。
当一切正常时,请求看起来是这样的:
当其中有一个系统有延迟时,它可能阻塞整个用户请求:
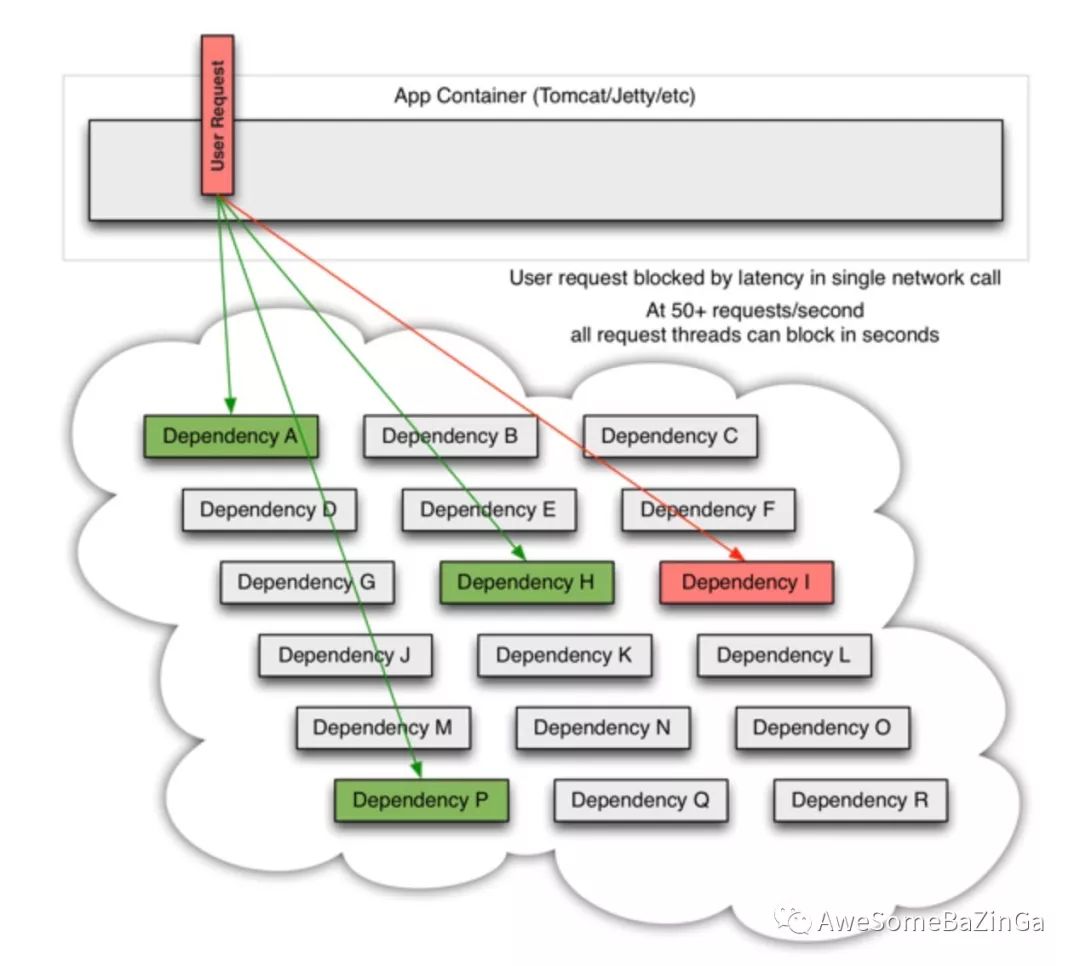
在高流量的情况下,一个后端依赖项的延迟可能导致所有服务器上的所有资源在数秒内饱和(PS:意味着后续再有请求将无法立即提供服务)
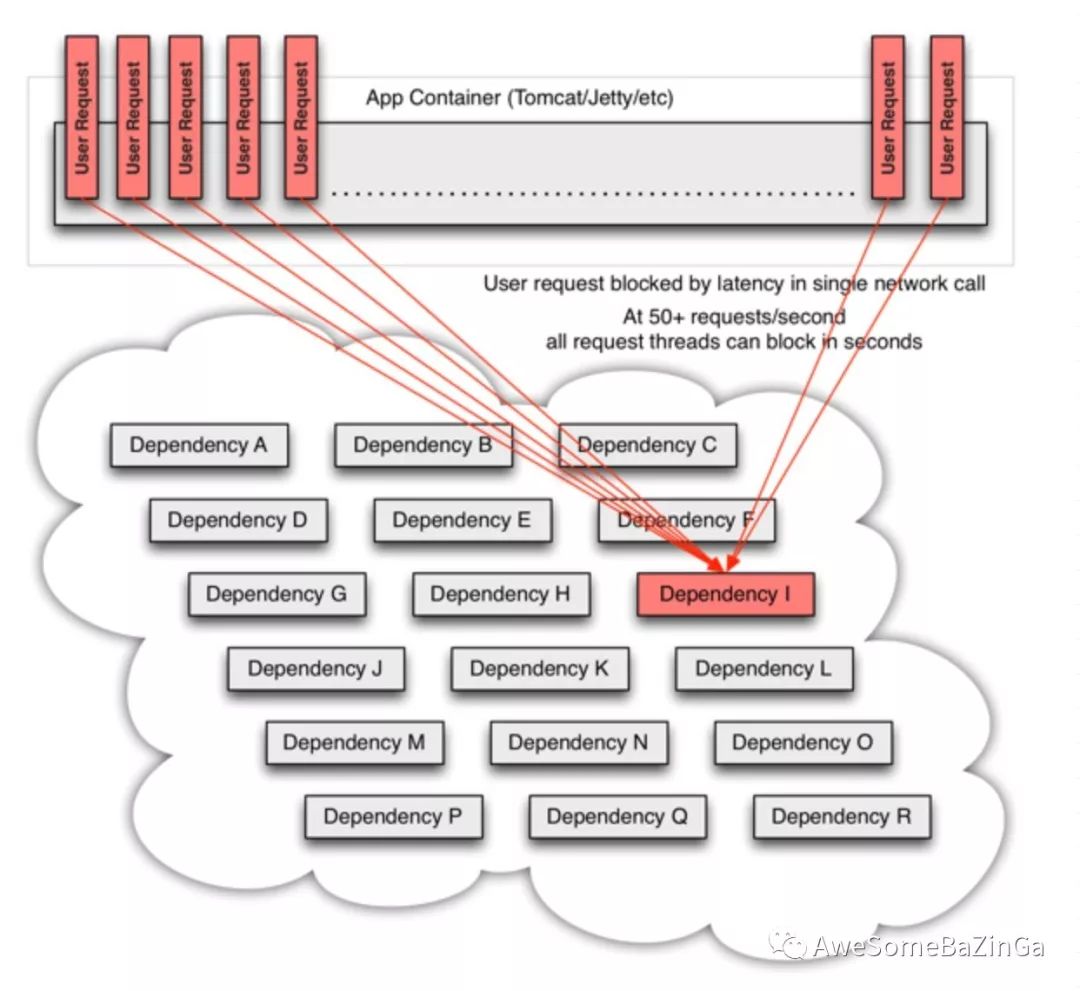
4、设计原则
•防止任何单个依赖项耗尽所有容器(如Tomcat)用户线程。•甩掉包袱,快速失败而不是排队。•在任何可行的地方提供回退,以保护用户不受失败的影响。•使用隔离技术(如隔离板、泳道和断路器模式)来限制任何一个依赖项的影响。•通过近实时的度量、监视和警报来优化发现时间。•通过配置的低延迟传播来优化恢复时间。•支持对Hystrix的大多数方面的动态属性更改,允许使用低延迟反馈循环进行实时操作修改。•避免在整个依赖客户端执行中出现故障,而不仅仅是在网络流量中。
5、规则原理
Hystrix的出现即为解决雪崩效应,它通过四个方面的机制来解决这个问题
•隔离(线程池隔离和信号量隔离):限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。•优雅的降级机制:超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。•熔断:当失败率达到阀值自动触发降级(如因网络故障/超时造成的失败率高),熔断器触发的快速失败会进行快速恢复。•缓存:提供了请求缓存、请求合并实现。•支持实时监控、报警、控制
5.1隔离
当你使用Hystrix来包装每个依赖项时,上图中所示的架构会发生变化,如下图所示,每个依赖项相互隔离,当延迟发生时,它会被限制在资源中,并包含回退逻辑,该逻辑决定在依赖项中发生任何类型的故障时应作出何种响应:
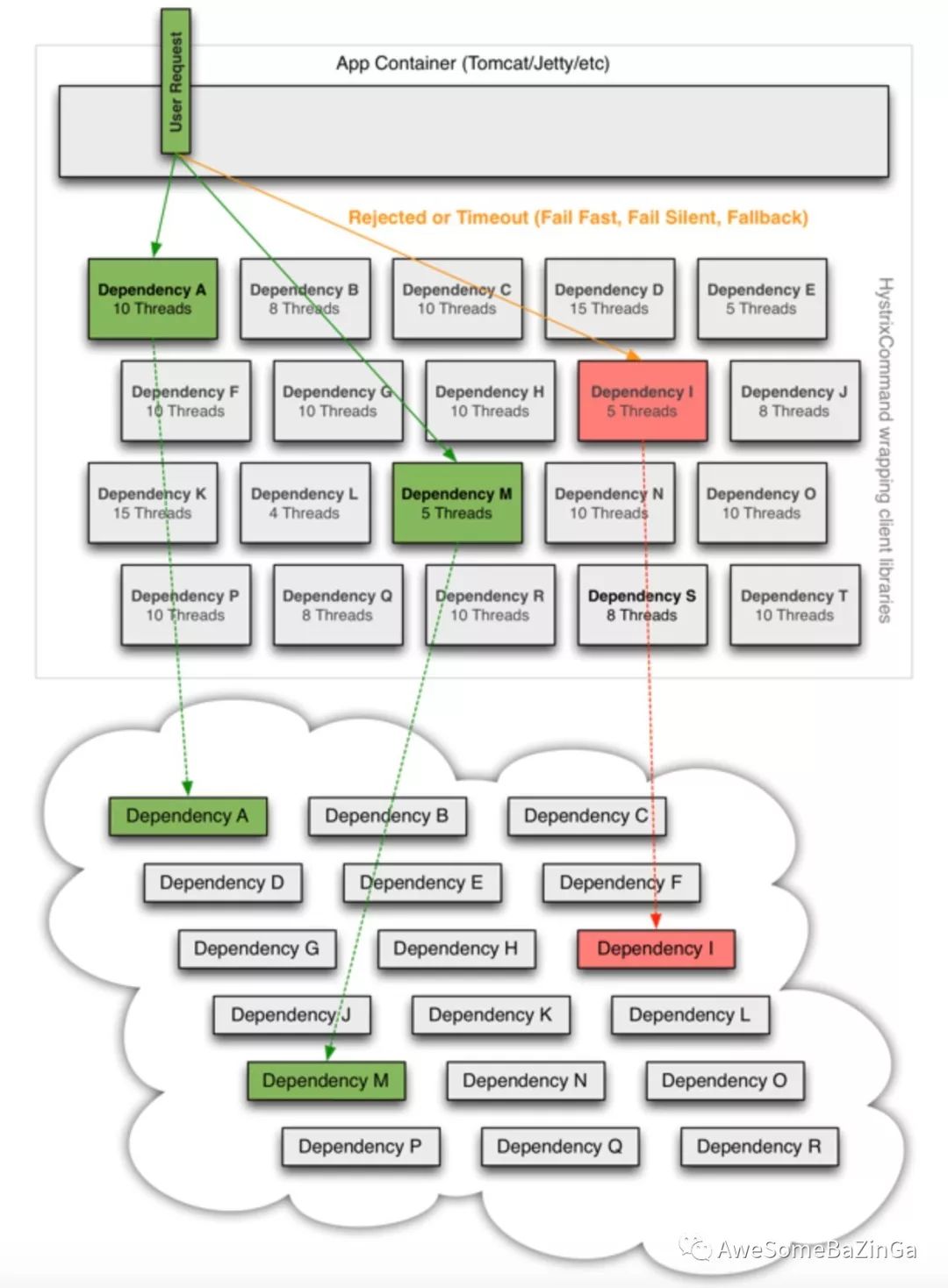
提供两种模式的隔离:
•线程池隔离模式:在Hystrix中使用独立的线程池对应每一个服务提供者,来隔离和限制这些服务,于是,某个服务提供者的高延迟或者饱和资源受限只会发生在该服务提供者对用的线程池中。如上图中,Dependency I
的调用失败或者高延迟仅会影响自身对应的线程池中的5个线程的阻塞并不会影响其他服务提供者的线程池状况。系统完全与服务提供者请求隔离开来,即使服务提供者对应的线程完全耗尽,并不会影响系统中的其他请求。注意在对应服务提供者的线程池被占满时,Hystrix会进入了fallback
逻辑,快速失败,保护服务调用者的资源稳定。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队列慢慢处理)•信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃该类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)。如果通过信号量来控制系统负载,将不再允许设置超时和异步化,这就表示在服务提供者出现高延迟,其调用线程将会被阻塞,直至服务提供者的网络请求超时,如果对服务提供者有足够的信息,可以通过信号量来控制系统的负载。
| 线程池隔离 | 信号量隔离 | |
| 线程 | 与调用线程不相同线程 | 与调用线程相同 |
| 开销 | 排队、调度、上下文开销等 | 无线程切换,开销低 |
| 异步 | 支持 | 不支持 |
| 并发支持 | 支持(最大线程池大小) | 支持(最大信号量上限) |
关于线程池和信号量的详细实现参考http://blueskykong.com/2018/03/19/hystrix-isolation/
5.2熔断器
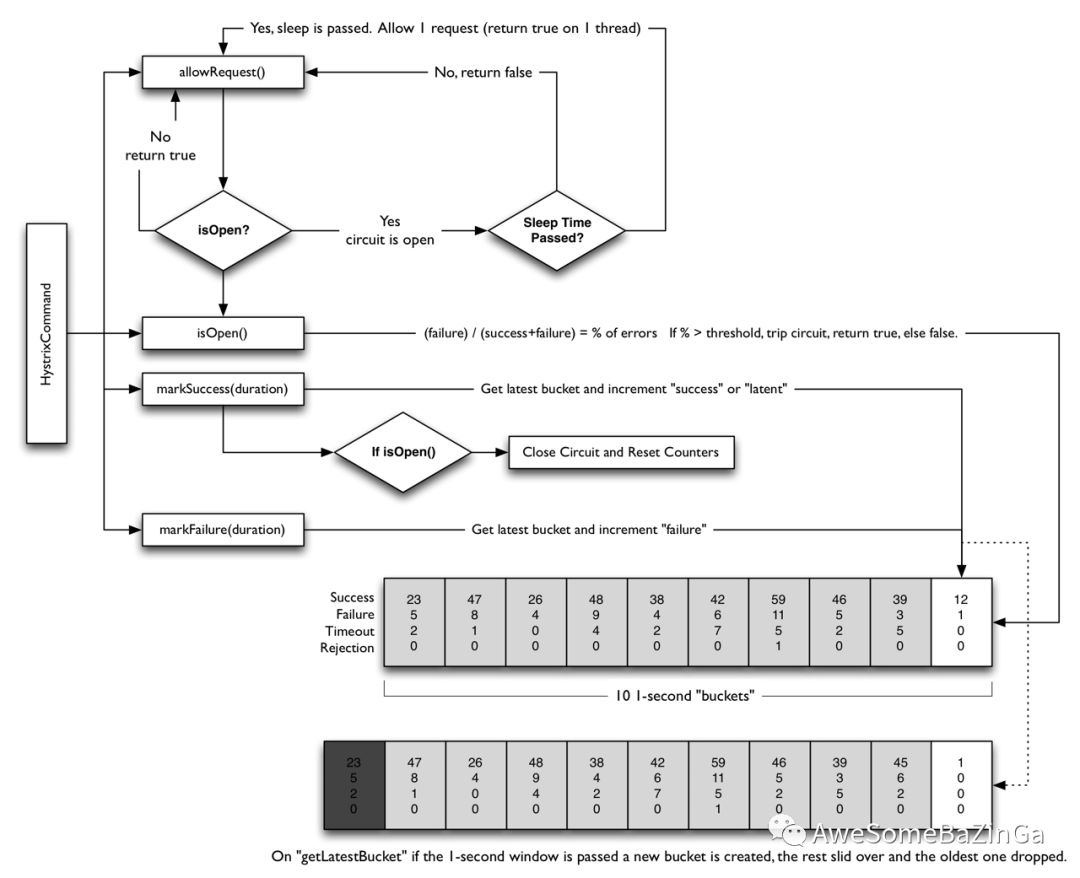
Hystrix的熔断器其实可以理解为就是一个统计中心,统计一定时间窗口内访问次数,成功次数,失败次数等数值判定是否发生熔断。发生电路熔断的过程如下:
1.假设电路上的音量达到一定阈值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold),默认是5秒20次。2.并假设错误百分比超过阈值错误百分比(HystrixCommandProperties.circuitBreakerErrorThresholdPercentage),默认是50%。3.然后断路器从CLOSED转换到OPEN。4.它是开放的,它使所有针对该断路器的请求短路。5.经过一段时间(HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds),下一个单个请求是通过(这是HALF-OPEN状态)。如果请求失败,断路器将在睡眠窗口持续时间内返回到OPEN状态。如果请求成功,断路器将转换到CLOSED,逻辑1.重新接管。
5.3工作流程
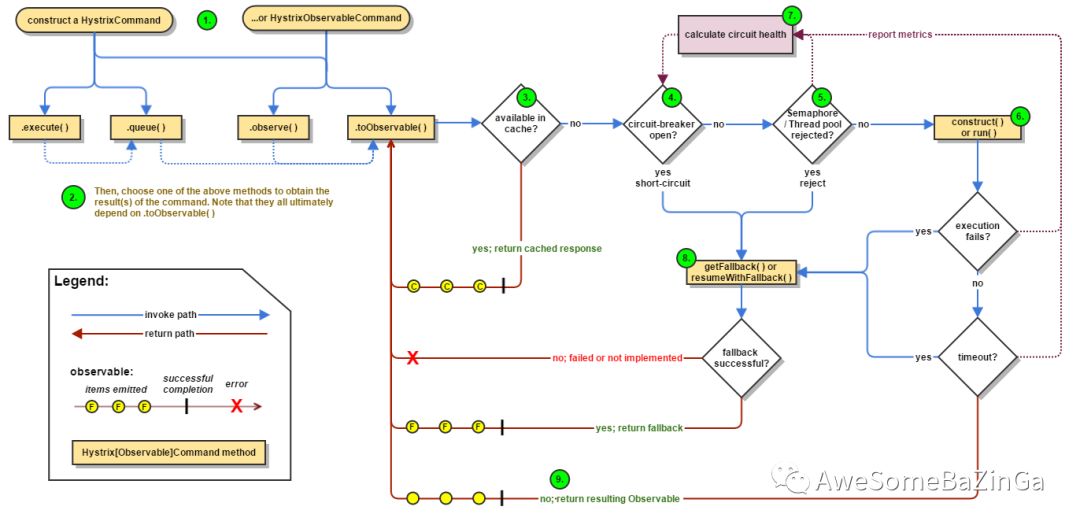
1.构建一个HystrixCommand或者HystrixObservableCommand 对象。2.执行Command3.响应是否有缓存?如果为该命令启用请求缓存,并且如果缓存中对该请求的响应可用,则此缓存响应将立即以“可观察”的形式返回。4.熔断器是否打开?如果电路打开(或“跳闸”),则Hystrix将不会执行该命令,但会将流程路由到(8)获取回退。如果电路关闭,则流程进行到(5)以检查是否有可用于运行命令的容量。5.线程池/队列/信号量是否已经满负载?如果与命令相关联的线程池和队列(或信号量,如果不在线程中运行)已满,则Hystrix将不会执行该命令,但将立即将流程路由到(8)获取回退。6.执行真正的命令部分,HystrixObservableCommand.construct() 或者 HystrixCommand.run(),在这里Hystrix通过您为此目的编写的方法调用对依赖关系的请求。如果run或construct方法超出了命令的超时值,则该线程将抛出一个TimeoutException, 在这种情况下,Hystrix将响应通过8进行路由。获取Fallback,如果该方法不取消/中断,它会丢弃最终返回值run()或construct()方法。7.计算Circuit 的健康,Hystrix向断路器报告成功,失败,拒绝和超时,该断路器维护了一系列的计算统计数据组。它使用这些统计信息来确定电路何时“跳闸”,此时短路任何后续请求直到恢复时间过去,在首次检查某些健康检查之后,它再次关闭电路。8.获取Fallback,当命令执行失败时,Hystrix试图恢复到你的回退:当construct或run抛出异常时[6],当命令由于电路断开而短路时[4],当命令的线程池和队列或信号量处于容量[5],或者当命令超过其超时长度时[6]。9.返回成功的响应,如果 Hystrix command成功,如果Hystrix命令成功,它将以Observable的形式返回对呼叫者的响应或响应。
6、使用
6.1引入依赖
<!-- hystrix support --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency>
6.2代码
当 断路器
打开或运行错误时,执行默认的代码,给@FeignClient
定义一个fallback
属性,设置它实现回退的,还需要将您的实现类声明为Spring Bean。
这里直接跳过Ribbon+Hystrix,进入Feign+Hystrix的使用,使用方式很简单,在FeignClient注解的参数中配置fallback或者fallbackFactory即可。
注意:如果我们FeignClient
服务都是内部的,在客户端抛出异常直接往最外层抛出(此时服务依然是健壮的),而只有服务挂掉才会进入fallback进行处理。
@FeignClient(name = "orghrservice", fallback = OrghrServiceInterfaceHystrix.class)public interface OrghrServiceInterface {@RequestMapping(value = "/orghr/user/findOaIdsByIds", method = RequestMethod.POST)Response findOaUserIdsByIds(@RequestParam("ids") String ids);@RequestMapping(value = "/orghr/department/findOaIdsByIds", method = RequestMethod.POST)Response findOaDeptIdsByIds(@RequestParam("ids") String ids);@RequestMapping(value = "/orghr/user/findUserByLoginId", method = RequestMethod.GET)EntityResponse findUserByLoginId(@RequestParam("ids") String ids);}
实现Hystrix
@Componentpublic class OrghrServiceInterfaceHystrix implements OrghrServiceInterface{@Overridepublic Response findOaUserIdsByIds(String ids) {return new Response(ResultCodeEnum.SERVICE_DOWN, null);}@Overridepublic Response findOaDeptIdsByIds(String ids) {return new Response(ResultCodeEnum.SERVICE_DOWN, null);}@Overridepublic EntityResponse findUserByLoginId(String ids) {return new EntityResponse(ResultCodeEnum.SERVICE_DOWN, null);}}
如果将fallback = OrghrServiceInterfaceHystrix.class替换成fallbackFactory = OrghrServiceInterfaceFactory.class(fallbackFactory是fallback的增强版)
public class OrghrServiceInterfaceFactory implements FallbackFactory<OrghrServiceInterface> {private static final Logger logger = LoggerFactory.getLogger(OrghrServiceInterfaceFactory.class);@Overridepublic OrghrServiceInterface create(Throwable throwable) {logger.info("fallback reason was: {} " ,throwable.getMessage());return new OrghrServiceInterfaceWithFactory() {@Overridepublic Response findOaUserIdsByIds(String ids) {return null;}@Overridepublic Response findOaDeptIdsByIds(String ids) {return null;}@Overridepublic EntityResponse findUserByLoginId(String ids) {return null;}};}}
public interface OrghrServiceInterfaceWithFactory extends OrghrServiceInterface {}
6.3异常处理
服务端异常处理
@ControllerAdvicepublic class GlobalExceptionHandler extends ResponseEntityExceptionHandler {@ExceptionHandler(value = Exception.class)@ResponseBodypublic ErrorResponseEntity jsonErrorHandler(Exception e, HttpServletResponse rep) throws Exception {if (e instanceof BattcnException) {BattcnException exception = (BattcnException) e;return exception.toErrorResponseEntity();}logger.error("服务器未知异常", e);rep.setStatus(HttpStatus.INTERNAL_SERVER_ERROR.value());return new ErrorResponseEntity(HttpStatus.INTERNAL_SERVER_ERROR.value(), "服务器未知异常");}}
客户端异常处理
@ControllerAdvicepublic class GlobalExceptionHandler extends ResponseEntityExceptionHandler {@ExceptionHandler(value = Exception.class)@ResponseBodypublic ErrorResponseEntity jsonErrorHandler(Exception e, HttpServletResponse rep) throws Exception {if (e instanceof HystrixBadRequestException) {HystrixBadRequestException exception = (HystrixBadRequestException) e;rep.setStatus(HttpStatus.BAD_REQUEST.value());logger.info("[HystrixBadRequestException] - [" + exception.getMessage() + "]");JSONObject obj = JSON.parseObject(exception.getMessage());return new ErrorResponseEntity(obj.getInteger("customCode"), obj.getString("message"));}logger.error("服务器未知异常", e);rep.setStatus(HttpStatus.INTERNAL_SERVER_ERROR.value());return new ErrorResponseEntity(HttpStatus.INTERNAL_SERVER_ERROR.value(), "服务器未知异常");}}
在Hystrix
中只有HystrixBadRequestException是不会被计数,也不会进入阻断器,所以我们定义一个自己的错误解码器来实现客户端抛出异常。
@Componentpublic class FeignServiceErrorDecoder implements feign.codec.ErrorDecoder {static Logger LOGGER = LoggerFactory.getLogger(FeignServiceErrorDecoder.class);@Overridepublic Exception decode(String methodKey, Response response) {try {if (response.status() >= 400 && response.status() <= 499) {String error = Util.toString(response.body().asReader());return new HystrixBadRequestException(error);}} catch (IOException e) {LOGGER.error("[Feign解析异常] - [{}]", e);}return feign.FeignException.errorStatus(methodKey, response);}}
综上:服务挂掉进入fallback,异常则直接被捕获后抛出。
方案二
对于请求异常的解决方案就需要通过 HystrixBadRequestException
来解决了(不会触发熔断机制),根据返回响应创建对应异常并将异常封装进 HystrixBadRequestException
,业务系统调用中取出 HystrixBadRequestException
中的自定义异常进行处理,封装异常说明:
public class UserErrorDecoder implements ErrorDecoder{private Logger logger = LoggerFactory.getLogger(getClass());public Exception decode(String methodKey, Response response) {ObjectMapper om = new JiaJianJacksonObjectMapper();JiaJianResponse resEntity;Exception exception = null;try {resEntity = om.readValue(Util.toString(response.body().asReader()), JiaJianResponse.class);//为了说明我使用的 WebApplicationException 基类,去掉了封装exception = new WebApplicationException(javax.ws.rs.core.Response.status(response.status()).entity(resEntity).type(MediaType.APPLICATION_JSON).build());} catch (IOException ex) {logger.error(ex.getMessage(), ex);}// 这里只封装4开头的请求异常if (400 <= response.status() || response.status() < 500){exception = new HystrixBadRequestException("request exception wrapper", exception);}else{logger.error(exception.getMessage(), exception);}return exception;}}
为 Feign 配置 ErrorDecoder
@Configurationpublic class FeignConfiguration {@Beanpublic ErrorDecoder errorDecoder(){return new UserErrorDecoder();}}
7、Hystrix配置信息
7.1Execution相关
•
hystrix.command.default.execution.isolation.strategy 隔离策略,默认是Thread, 可选Thread|Semaphore
thread 通过线程数量来限制并发请求数,可以提供额外的保护,但有一定的延迟。一般用于网络调用 semaphore 通过semaphore count来限制并发请求数,适用于无网络的高并发请求
•
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds 命令执行超时时间,默认1000ms
•hystrix.command.default.execution.timeout.enabled 执行是否启用超时,默认启用true
•hystrix.command.default.execution.isolation.thread.interruptOnTimeout 发生超时是是否中断,默认true
•hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests 最大并发请求数,默认10,该参数当使用ExecutionIsolationStrategy.SEMAPHORE策略时才有效。如果达到最大并发请求数,请求会被拒绝。理论上选择semaphore size的原则和选择thread size一致,但选用semaphore时每次执行的单元要比较小且执行速度快(ms级别),否则的话应该用thread。semaphore应该占整个容器(tomcat)的线程池的一小部分。
7.2Fallback相关
这些参数可以应用于Hystrix的THREAD和SEMAPHORE策略
•hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests 如果并发数达到该设置值,请求会被拒绝和抛出异常并且fallback不会被调用。默认10•hystrix.command.default.fallback.enabled 当执行失败或者请求被拒绝,是否会尝试调用hystrixCommand.getFallback() 。默认true
7.3Circuit Breaker相关
•hystrix.command.default.circuitBreaker.enabled 用来跟踪circuit的健康性,如果未达标则让request短路。默认true•hystrix.command.default.circuitBreaker.requestVolumeThreshold 一个rolling window内最小的请求数。如果设为20,那么当一个rolling window的时间内(比如说1个rolling window是10秒)收到19个请求,即使19个请求都失败,也不会触发circuit break。默认20•hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds 触发短路的时间值,当该值设为5000时,则当触发circuit break后的5000毫秒内都会拒绝request,也就是5000毫秒后才会关闭circuit。默认5000•hystrix.command.default.circuitBreaker.errorThresholdPercentage错误比率阀值,如果错误率>=该值,circuit会被打开,并短路所有请求触发fallback。默认50•hystrix.command.default.circuitBreaker.forceOpen 强制打开熔断器,如果打开这个开关,那么拒绝所有request,默认false•hystrix.command.default.circuitBreaker.forceClosed 强制关闭熔断器 如果这个开关打开,circuit将一直关闭且忽略circuitBreaker.errorThresholdPercentage
7.4Metrics相关
•hystrix.command.default.metrics.rollingStats.timeInMilliseconds 设置统计的时间窗口值的,毫秒值,circuit break 的打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。默认10000•hystrix.command.default.metrics.rollingStats.numBuckets 设置一个rolling window被划分的数量,若numBuckets=10,rolling window=10000,那么一个bucket的时间即1秒。必须符合rolling window % numberBuckets == 0。默认10•hystrix.command.default.metrics.rollingPercentile.enabled 执行时是否enable指标的计算和跟踪,默认true•hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds 设置rolling percentile window的时间,默认60000•hystrix.command.default.metrics.rollingPercentile.numBuckets 设置rolling percentile window的numberBuckets。逻辑同上。默认6•hystrix.command.default.metrics.rollingPercentile.bucketSize 如果bucket size=100,window=10s,若这10s里有500次执行,只有最后100次执行会被统计到bucket里去。增加该值会增加内存开销以及排序的开销。默认100•hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds 记录health 快照(用来统计成功和错误绿)的间隔,默认500ms
7.5Request Context相关
•hystrix.command.default.requestCache.enabled 默认true,需要重载getCacheKey(),返回null时不缓存•hystrix.command.default.requestLog.enabled 记录日志到HystrixRequestLog,默认true
7.6Collapser Properties相关
•hystrix.collapser.default.maxRequestsInBatch 单次批处理的最大请求数,达到该数量触发批处理,默认Integer.MAX_VALUE•hystrix.collapser.default.timerDelayInMilliseconds 触发批处理的延迟,也可以为创建批处理的时间+该值,默认10•hystrix.collapser.default.requestCache.enabled 是否对HystrixCollapser.execute() and HystrixCollapser.queue()的cache,默认true
7.7ThreadPool相关
线程数默认值10适用于大部分情况(有时可以设置得更小),如果需要设置得更大,那有个基本得公式可以follow:每秒最大支撑的请求数 (99%平均响应时间 + 缓存值) 比如:每秒能处理1000个请求,99%的请求响应时间是60ms,那么公式是:1000 *(0.060+0.012)
基本得原则时保持线程池尽可能小,他主要是为了释放压力,防止资源被阻塞。当一切都是正常的时候,线程池一般仅会有1到2个线程激活来提供服务
•hystrix.threadpool.default.coreSize 并发执行的最大线程数,默认10•hystrix.threadpool.default.maxQueueSize BlockingQueue的最大队列数,当设为-1,会使用SynchronousQueue,值为正时使用LinkedBlcokingQueue。该设置只会在初始化时有效,之后不能修改threadpool的queue size,除非reinitialising thread executor。默认-1。•hystrix.threadpool.default.queueSizeRejectionThreshold 即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝。因为maxQueueSize不能被动态修改,这个参数将允许我们动态设置该值。if maxQueueSize == -1,该字段将不起作用•hystrix.threadpool.default.keepAliveTimeMinutes 如果corePoolSize和maxPoolSize设成一样(默认实现)该设置无效。如果通过plugin(https://github.com/Netflix/Hystrix/wiki/Plugins)使用自定义实现,该设置才有用,默认1.•hystrix.threadpool.default.metrics.rollingStats.timeInMilliseconds 线程池统计指标的时间,默认10000•hystrix.threadpool.default.metrics.rollingStats.numBuckets 将rolling window划分为n个buckets,默认10
