




常见问题和案例分析
● MIN/MAX函数执行计划优化
对于单独查询MIN/MAX聚集函数,如果根据where条件没有选择到索引的话,建议在函数的参数字段上创建索引,优化器就会选择index aggr执行计划,大大提升执行性能。例如: select max(a) from t1 where b < 3;
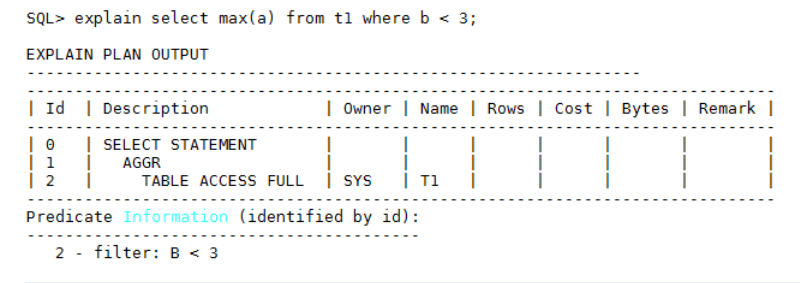
如果在字段a上创建索引的话,优化器会选择 INDEX AGGR执行节点。

● count函数执行计划优化
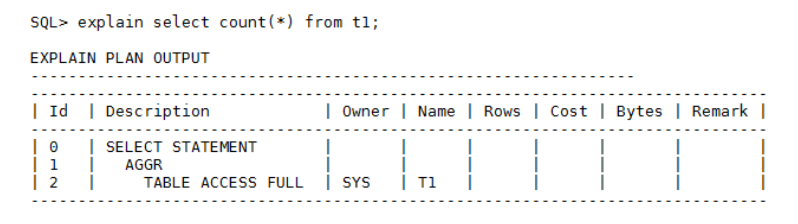
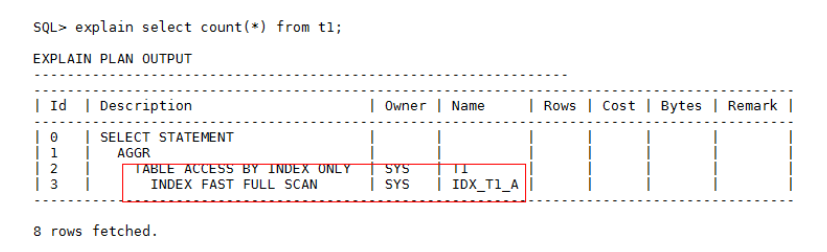
对于count函数来说,如果表上没有索引的话,建议创建单字段索引(count(A)需要在A字段上创建索引,count()或count(1)字段不限制),调整执行计划,从原来的table access full调整为index fast full scan,这样会减少存储层页面访问。例如:select count() from t1;
如果在T1表上创建索引后,执行计划如下:
● 子查询、视图关联条件下推优化
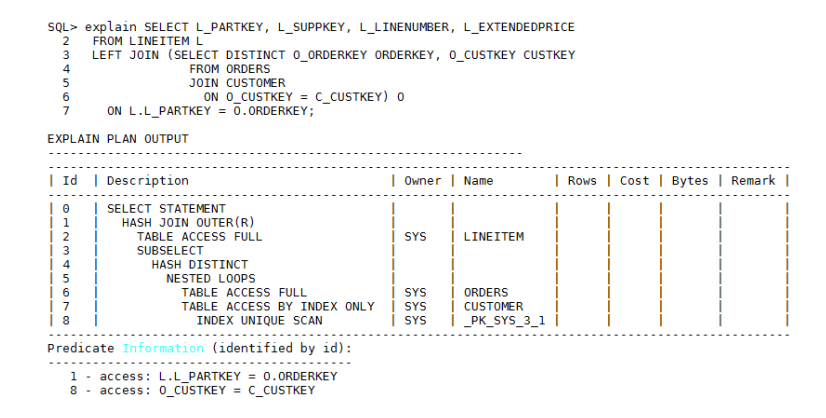
对于右表是子查询或者视图的场景,如果子查询的驱动表能够根据父表关联条件选择索引,并且索引字段重复度很小的话,此时使用父表关联条件进行索引扫描的性能最高,执行计划最优。使用父表关联条件有两个必要条件:
– 子查询或者视图必须不能是驱动表;
– 子查询或视图与驱动表必须走Nest Loop Join。
调整后的SQL语句执行计划如下:
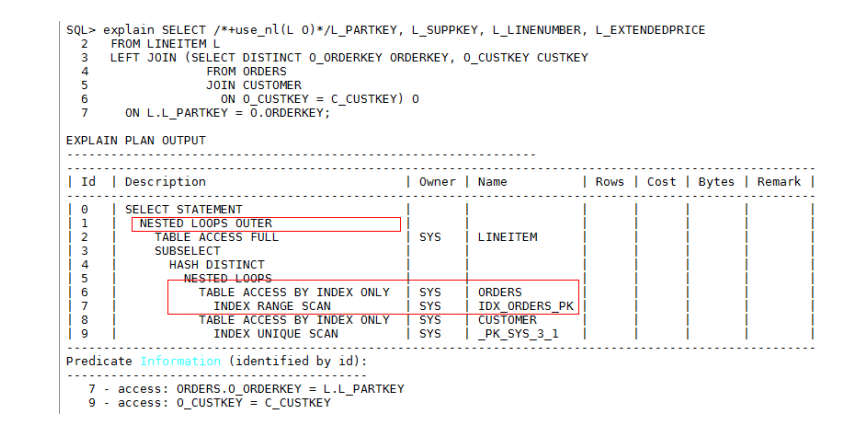
● IN/NOT IN/EXISTS/NOT EXISTS子查询优化
出现在上述表达式中的子查询,通常情况下,RBO优化器根据规则(CBO优化器根据代价)会把子查询转换为查询表,与外表关联执行。子查询转换为Join以后,与父表关联查询,如果子查询表作为驱动表,父表能够根据关联条件选择索引扫描的话,则子查询表与父表进行Nest Loop Join,否则IN、EXISTS子查询会转换为Hash Semi Join,NOT IN、NOT EXISTS子查询会转换为Hash Anti Join。
RBO很据规则判断是否转换为Join,这种规则不是适用于所有场景,某些场景下转
换为Join执行性能较低,反之某些场景不转换执行性能也比较低,如果出现这种误
判的场景,则需要人工调整SQL语句,干预优化器执行计划选择。
– 场景一:如果父表数据量比较小,子查询表数据量很大时,则不能转换为JOIN处理。例如:
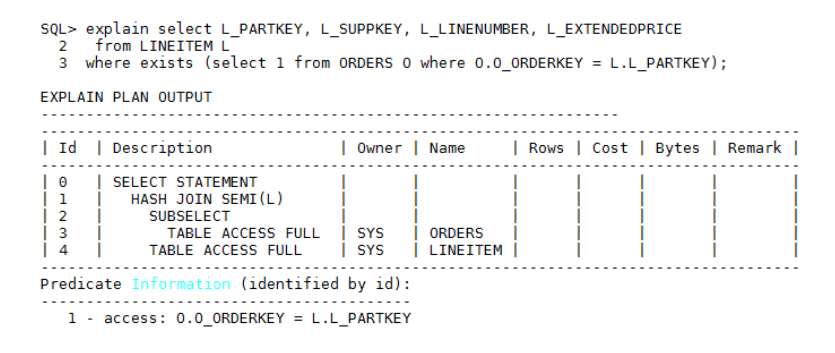
对于Hash Semi/Hash Anti join,都是使用子查询结果集创建hash表,如果ORDERS是大表的话,建hash表的代价很大,并且还会占用很多TEMP BUFFER内存,影响其他语句执行。这种场景下,我们可以在子查询的where条件中添加rownum > 0条件,既不影响结果集,也能指示优化不要把子查询转换为Join,执行计划如下:
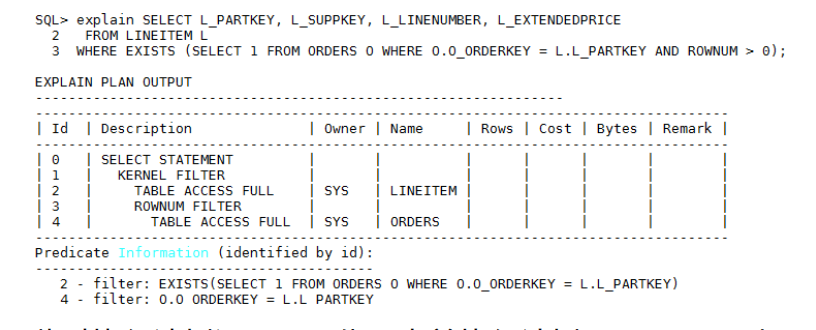
此时执行计划还不是最优,当前执行计划是LINEITEM表驱动ORDERS全表扫描,计算代价非常大,CPU占用很高,需要在与父表关联的字段上创建索引,如果有多个关联字段,则需要创建联合索引,对于此例,需要在O_ORDERKEY字段上创建索引,执行计划如下:
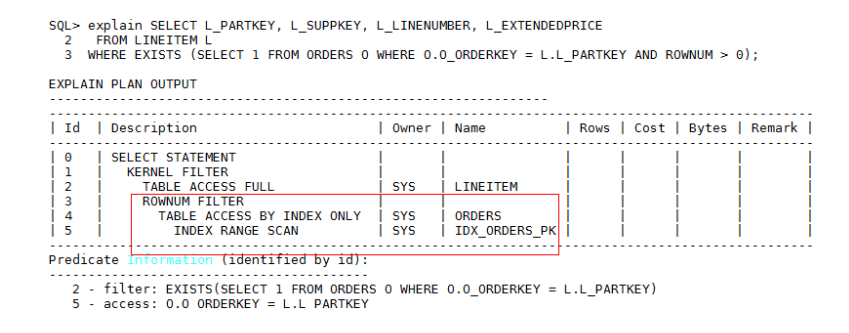
– 场景二:如果子查询表数据量比较小、或者与父表数据量相当的情况下,要考虑2种情况:
▪ 如果子查询表能够根据父表字段选择索引扫描,并且索引扫描性能比较高时,子查询不需要转换为JOIN,如果优化器选择转JOIN执行计划时,就需要手动干预,参见场景一操作;
▪ 如果子查询表不能根据父表字段选择索引,或者是索引扫描性能差的话,就需要转换为JOIN处理,如果优化器因为选择索引导致没有转换的话,则需要在该索引的首字段+0(字符类型||’’)屏蔽该索引。
子查询转换JOIN后,如何选择JOIN算法?
○ 对于NOT IN、NOT EXISTS,只能选择Hash Anti Join,对于IN、EXISTS表达式,可以选择Nest Loop和Hash Semi。
○ 如果子查询表结果集很小的话,建议选择Nest Loop Join,要求父表必须能够通过关联条件选择索引,并且索引字段重复度不能太高,如果父表不存在这类索引,建议创建这样的索引,执行计划如下:
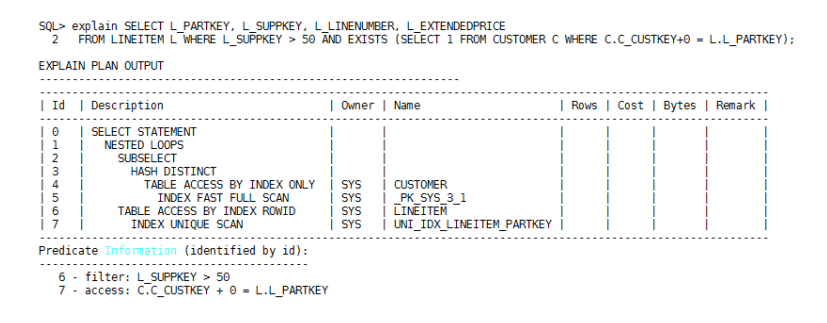
子查询表数据量与父表相当的情况下,如果父表能够根据与子查询关联条件选择索引扫描,并且索引字段重复度很小时,建议选择Nest Loop Join算法,执行计划如上;反之需要选择Hash Semi Join,执行计划如下:
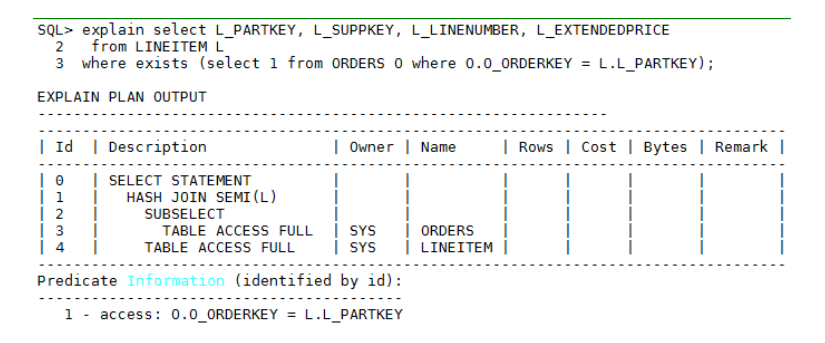
● order by执行计划优化
对于单表查询语句存在order by子句的场景,如果根据where条件没有选择到索引扫描的话,建议根据order by字段顺序创建索引,这样优化器会把全表扫描优化为index full scan,并且消除sort执行节点,优化前执行计划如下:
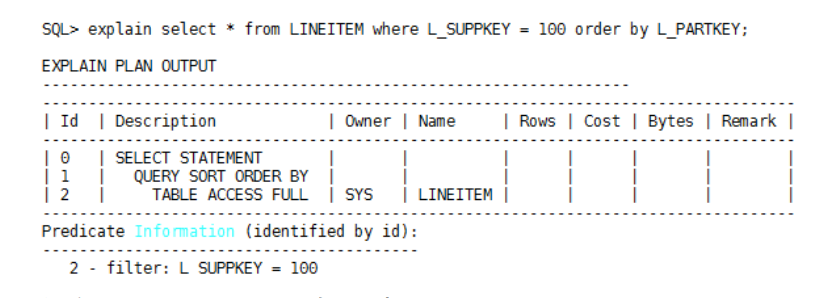
在字段L_PARTKEY上创建索引后,通过index full scan即可消除排序操作,执行计划如下:
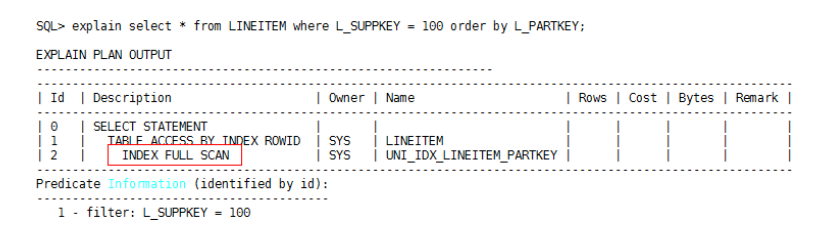
如果查询语句能够根据where条件选择索引扫描,并且是索引全部字段等值匹配的话,建议把排序字段添加到索引后面,这样即可消除排序。例如上述SQL语句,如果表LINEITEM在L_SUPPKEY字段上存在索引,则该查询语句可以走index range scan:
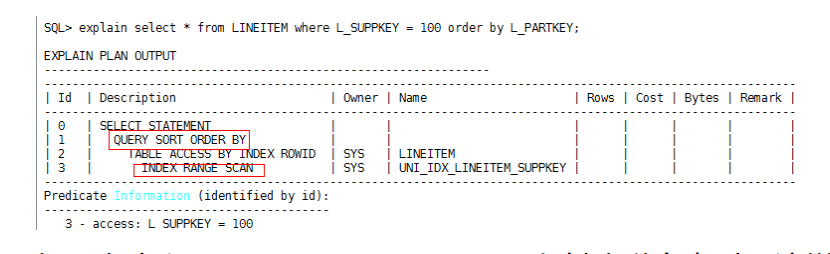
如果在字段L_SUPPKEY,L_PARTKEY上创建联合索引,这样就既可以走index range scan,又可以消除排序操作:
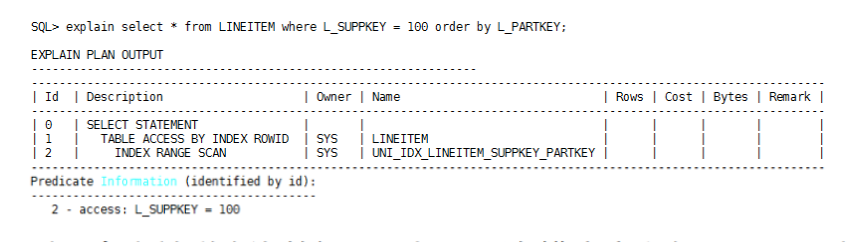
对于多表关联查询的场景,如果所有排序字段都属于同一张表,并且该表是关联
查询的驱动表,则可以参照上述步骤进行调优。例如:
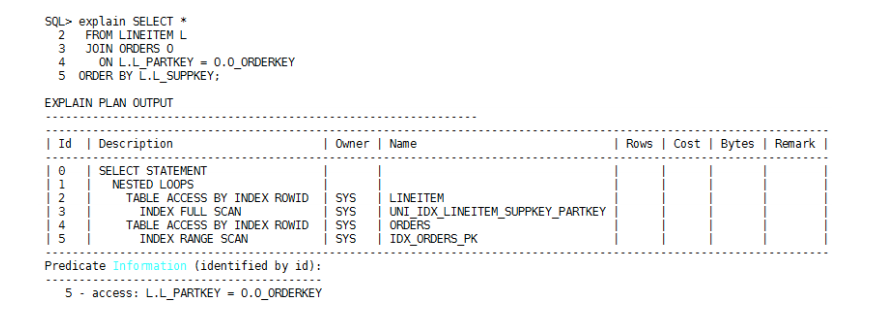
在此例中,LINEITEM是驱动表,参照上述调优手段,在字段L_SUPPKEY上创建索
引,即可消除排序。
