







上篇文章MySQL之单表查询成本我们学习了单表查询成本的计算过程,今天我们来学习一下连接查询成本的相关知识,话不多说,Let's GO。


Condition Filtering介绍

CREATE TABLE `table_query_cost` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `key1` VARCHAR(100), `key2` INT(11) , `key3` VARCHAR(100), `key_part1` VARCHAR(100), `key_part2` VARCHAR(100), `key_part3` VARCHAR(100), `common_field` VARCHAR(100), PRIMARY KEY (`id`), KEY idx_key1 (`key1`), UNIQUE KEY uq_key2 (`key2`), KEY idx_key3 (`key3`), KEY idx_key_part(`key_part1`, `key_part2`, `key_part3`)) Engine=InnoDB;
单次查询驱动表的成本 多次查询被驱动表的成本(具体查询多少次取决于对驱动表查询的结果集中有多少条记录)
SELECT * FROM table_query_cost AS t1 INNER JOIN table_query_cost2 AS t2;
假设t1表是驱动表,对驱动表的单表查询只能使用全表扫描,有多少条记录扇出值就是多少。根据之前统计信息中t1表的Rows是10056,所以驱动表t1的扇出值就是10056。
SELECT * FROM table_query_cost AS t1 INNER JOIN table_query_cost2 AS t2 WHERE t1.key2 > 99 AND t1.key2 < 999;
同样假设t1表是驱动表,对驱动表的单表查询可以使用uq_key2索引。uq_key2范围区间(99,999)的记录数就是扇出值,根据之前计算的uq_key2范围区间(99,999)的记录数是86,所以此情况下驱动表t1的扇出值就是86。
上述这两种情况是比较简单、理想的场景,但是有的时候,为满足业务上的需求,SQL会写成下面的情况:
e.g. 3:
SELECT * FROM table_query_cost AS t1 INNER JOIN table_query_cost2 AS t2 WHERE t1.common_field > 'a6c5a45';
和e.g. 1类似,在内连接的基础上,多了一个t1.common_field > 'a6c5a45'的搜索条件。查询优化器不会真正去执行,只能猜这10056行记录里有多少条记录满足t1.common_field > 'a6c5a45'这个条件。
e.g. 4:
SELECT * FROM table_query_cost AS t1 INNER JOIN table_query_cost2 AS t2 WHERE t1.key2 > 99 AND t1.key2 < 999 AND t1.common_field > 'a6c5a45';
SELECT * FROM table_query_cost AS t1 INNER JOIN table_query_cost2 AS t2 WHERE t1.key2 > 99 AND t1.key2 < 999 AND t1.key1 IN ('e4', '2f', 'd7') AND t1.common_field > 'a6c5a45';
如果使用的是全表扫描的方式执行的单表查询,那么计算驱动表扇出时需要猜满足搜索条件的记录到底有多少条。 如果使用的是索引执行的单表扫描,那么计算驱动表扇出的时候需要猜满足除使用到对应索引的搜索条件外的其他搜索条件的记录有多少条。
两表连接的成本分析
对于左(外)连接和右(外)连接查询来说,驱动表固定,想要得到最优的查询方案只需要:
分别为驱动表和被驱动表选择成本最低的访问方法。
可是对于内连接来说,驱动表和被驱动表的位置是可以互换的,需要考虑两个方面的问题:
1、不同的表作为驱动表最终的查询成本可能是不同的,也就是需要考虑最优的表连接顺序。
2、然后分别为驱动表和被驱动表选择成本最低的访问方法。
SELECT * FROM table_query_cost AS t1 INNER JOIN table_query_cost2 AS t2 ON t1.key1 = t2.common_field WHERE t1.key2 > 99 AND t1.key2 < 999 AND t2.key2 > 999 AND t2.key2 < 1999;
可以选择两种连接顺序:
1、t1连接t2,t1为驱动表,t2为被驱动表;
2、t2连接t1,t2为驱动表,t1为被驱动表。
查询优化器需要分别考虑这两种情况下的最优查询成本,然后选取那个成本更低的连接顺序以及该连接顺序下各个表的最优访问方法作为最终的查询计划。
t1作为驱动表的情况:
分析对于驱动表的成本最低执行方案:涉及驱动表t1的搜索条件有t1.key2 > 99 AND t1.key2 < 999,这个查询可以用到uq_key2索引,和全表扫描相比,使用uq_key2索引执行查询成本更低。
分析对于被驱动表的成本最低的执行方案:涉及被驱动表t2的搜索条件有两个:
t2作为驱动表的情况:
分析对于驱动表的成本最低执行方案:涉及对驱动表t2的搜索条件有t2.key2 >999 AND t2.key2 <1999,查询可能使用到uq_key2索引,和全表扫描相比,使用uq_key2索引执行查询成本更低。
分析对于被驱动表的成本最低的执行方案:涉及被驱动表t1的搜索条件有两个:
SHOW INDEX FROM test_cost.table_query_cost;

属性有点多,介绍一下:
| 属性名 | 描述 |
|---|---|
| Table | 索引所属的表名 |
| Non_unique | 索引列的值是否唯一,聚簇索引和唯一二级索引的值为0,普通二级索引的值为1 |
| Key_name | 索引的名称 |
| Seq_in_index | 索引列在索引中的位置,从1开始计数。比如复合索引idx_key_part,key_part1、key_part2、key_part3对应的位置分别是1、2、3 |
| Column_name | 索引列的名称 |
| Collation | 索引列中值的排序方式,A代表ASC升序存放,NULL为降序存放 |
| Cardinality | 索引列中不重复值的数量 |
| Sub_part | 对于存储字符串或者字节串的列来说,我们只会将这些串的前N个字符或字节创建索引,这个属性就是那个N值,NULL表示对完整列建立了索引 |
| Packed | 索引列如何被压缩,NULL表示未压缩 |
| Null | 该索引列是否允许存储NULL值 |
| Index_type | 使用的索引类型,常见的就是BTREE,就是B+树 |
| Comment | 索引列注释信息 |
| Index_comment | 索引信息 |
上述属性大家应该都能看懂。我们最关注的就是Cardinality属性,Cardinality直译过来就是基数,表示索引列中不重复值的个数。如表中有10W行记录,Cardinality属性值为10W,表示这个字段没有重复值,如果Cardinality属性值为1的话,那就意味着该字段全是重复值。结合Rows统计数据,我们可以针对索引列,计算出平均一个值重复多少次。
一个值的重复次数 ≈ Rows ÷ Cardinality
10056 ÷ 256 ≈ 39(条)
一般情况下,ref的访问方式要比range成本更低,这里假设使用idx_key1进行对t1的访问。
所以,使用t2作为驱动表的总成本就是:
使用uq_key2访问t2的成本 + t2的扇出 × 使用idx_key1访问t1的成本
最后优化器会比较这两种方式的最优访问成本,选取那个成本更低的连接顺序去真正的执行查询。从上边的计算过程也可以看出来,连接查询成本占大头的其实是驱动表扇出数 x 单次访问被驱动表的成本,所以我们的优化重点其实是下边这两个部分:
尽量减少驱动表的扇出
对被驱动表的访问成本尽量低
这一点对于我们实际书写连接查询语句时十分有用,我们需要尽量在被驱动表的连接列上建立索引,这样就可以使用ref访问方法来降低访问被驱动表的成本了。如果可以,被驱动表的连接列最好是该表的主键或者唯一二级索引列,这样就可以把访问被驱动表的成本降到更低了。
多表连接的成本分析
两表,比如A表和B表连接:
共有AB、BA两种连接顺序,相当于2 × 1 = 2种连接顺序。
三表,比如A表、B表和C表连接:
共有ABC、ACB、BAC、BCA、CAB、CBA六种连接顺序,相当于3 × 2 × 1 = 6中连接顺序。
四表,则有4 × 3 × 2 × 1 = 24种连接顺序。
对于n张表,则有 n × (n-1) × (n-2) × ··· × 1种连接顺序,就是n的阶乘种连接顺序,也就是n!。
调节成本常数
SHOW TABLES FROM mysql LIKE '%cost%';
MySQL分为Server层和存储引擎层,在server层进行连接管理、查询缓存、语法解析、查询优化等操作,在存储引擎层执行具体的数据存取操作。也就是说一条语句在server层中执行的成本是和它操作的表使用的存储引擎是没关系的,所以关于这些操作对应的成本常数就存储在了server_cost表中,而依赖于存储引擎的一些操作对应的成本常数就存储在了engine_cost表中。
mysql.server_cost表:
SELECT * FROM mysql.server_cost;
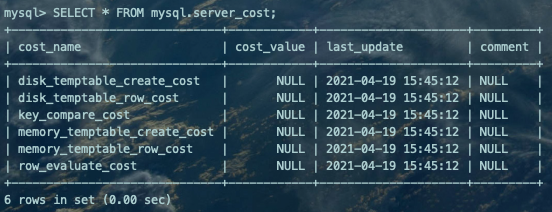
cost_name:成本常数的名称。
cost_value:成本常数对应的值。如果该列的值为NULL的话,意味着对应的成本常数会采用默认值。
last_update:表示最后更新记录的时间。
comment:注释。
目前在Server层的一些操作对应的成本常数有以下几种:
| 成本常数名称 | 默认值 | 描述 |
|---|---|---|
| disk_temptable_create_cost | 40.0 | 创建基于磁盘的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于磁盘的临时表。 |
| disk_temptable_row_cost | 1.0 | 向基于磁盘的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于磁盘的临时表。 |
| key_compare_cost | 0.1 | 两条记录做比较操作的成本,多用在排序操作上,如果增大这个值的话会提升filesort的成本,让优化器可能更倾向于使用索引完成排序而不是filesort。 |
| memory_temptable_create_cost | 2.0 | 创建基于内存的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。 |
| memory_temptable_row_cost | 0.2 | 向基于内存的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。 |
| row_evaluate_cost | 0.2 | 这个就是我们之前一直使用的检测一条记录是否符合搜索条件的成本,增大这个值可能让优化器更倾向于使用索引而不是直接全表扫描。 |
这些成本常数在server_cost中的初始值都是NULL,意味着优化器会使用它们的默认值来计算某个操作的成本,如果我们想修改某个成本常数的值的话,需要做两个步骤:
1、对我们感兴趣的成本常数做更新操作,比方说我们想把检测一条记录是否符合搜索条件的成本增大到0.4,那么就可以这样写更新语句:
UPDATE mysql.server_cost SET cost_value = 0.4 WHERE cost_name = 'row_evaluate_cost';
2、让系统重新加载这个表的值:
FLUSH OPTIMIZER_COSTS;
在你修改完某个成本常数后想把它们再改回默认值的话,可以直接把cost_value的值设置为NULL,再使用FLUSH OPTIMIZER_COSTS语句让系统重新加载它即可。
mysql.engine_cost表:
SELECT * FROM mysql.engine_cost;

与server_cost相比,engine_cost多了两个列:
engine_name:成本常数适用的存储引擎名称。如果该值为default,意味着对应的成本常数适用于所有的存储引擎。
device_type:存储引擎使用的设备类型,这主要是为了区分常规的机械硬盘和固态硬盘。
目前支持的存储引擎成本常数只有两个:
| 成本常数名称 | 默认值 | 描述 |
|---|---|---|
| io_block_read_cost | 1.0 | 从磁盘上读取一个块对应的成本。请注意我使用的是块,而不是页这个词儿。对于InnoDB存储引擎来说,一个页就是一个块,不过对于MyISAM存储引擎来说,默认是以4096字节作为一个块的。增大这个值会加重I/O成本,可能让优化器更倾向于选择使用索引执行查询而不是执行全表扫描。 |
| memory_block_read_cost | 1.0 | 与上一个参数类似,只不过衡量的是从内存中读取一个块对应的成本。 |
在MySQL目前的实现中,并不能准确预测某个查询需要访问的块中有哪些块已经加载到内存中,有哪些块还停留在磁盘上,所以MySQL很粗暴的认为不管这个块有没有加载到内存中,使用的成本都是1.0。
与更新server_cost表中的记录一样,我们也可以通过更新engine_cost表中的记录来更改关于存储引擎的成本常数,我们也可以通过为engine_cost表插入新记录的方式来添加只针对某种存储引擎的成本常数:
1、插入针对某个存储引擎的成本常数,比如我们想增大InnoDB存储引擎页面I/O的成本,书写正常的插入语句即可:
INSERT INTO mysql.engine_cost VALUES ('InnoDB', 0, 'io_block_read_cost', 2.0, CURRENT_TIMESTAMP, 'increase Innodb I/O cost');
2、让系统重新加载这个表的值:
FLUSH OPTIMIZER_COSTS;
小结


参考资料
小孩子4919《MySQL是怎样运行的:从根上理解MySQL》

end
