




微信公众号:大黄奔跑
关注我,可了解更多有趣的面试相关问题。
写在之前
如文章标题所言,遍历Map是开发过程中比较常见的行为,实现的方式也有多种方式,本文带领大家一起看看更加高效的遍历 Map
。
『茴』的十种写法
首先一起来看看,有哪些遍历 Map
的方式
1. 利用 iterator 和 Map.Entry
long i = 0;
Iterator<Map.Entry<Integer, Integer>>
it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, Integer> pair = it.next();
i += pair.getKey() + pair.getValue();
}
2. 利用 foreach 和 Map.Entry
long i = 0;
for (Map.Entry<Integer, Integer> pair
: map.entrySet()) {
i += pair.getKey() + pair.getValue();
}
3. 利用 Java 8中的foreach
这种应该算是比较常见的使用方式,也是比较容易理解的
final long[] i = {0};
map.forEach((k, v) -> i[0] += k + v);
4. 利用keySet 和 foreach
keySet:获取 map
中所有的 key
,然后依次遍历每个 key
。
long i = 0;
for (Integer key : map.keySet()) {
i += key + map.get(key);
}
5. 利用keySet and iterator
long i = 0;
Iterator<Integer> itr2 = map.keySet().iterator();
while (itr2.hasNext()) {
Integer key = itr2.next();
i += key + map.get(key);
}
6. 利用for循环和Map.Entry
long i = 0;
for (Iterator<Map.Entry<Integer, Integer>>
entries = map.entrySet().iterator(); entries.hasNext(); ) {
Map.Entry<Integer, Integer> entry = entries.next();
i += entry.getKey() + entry.getValue();
}
7. 利用 Java8 的Stream API
这种是我平时开发中用的最多的方式,简单通俗易懂。
但是其性能如何呢?后续待揭秘。
final long[] i = {0};
map.entrySet().stream()
.forEach(e -> i[0] += e.getKey()
+ e.getValue());
8. 利用Java8 中的 Stream API parallel
不知道有多少人用过 Java8 中的 parallel模式,本质是一种并行处理方式。
性能如何?稍后揭晓。
final long[] i = {0};
map.entrySet().stream().parallel()
.forEach(e -> i[0] += e.getKey() + e.getValue());
9. 利用 Apache 包的 IterableMap of
不行就找找外援试试?
long i = 0;
MapIterator<Integer, Integer> it
= iterableMap.mapIterator();
while (it.hasNext()) {
i += it.next() + it.getValue();
}
10. 利用Eclipse (CS) collections 中的MutableMap
final long[] i = {0};
mutableMap.forEachKeyValue((key, value)
-> {i[0] += key + value;
});
性能测试
测试环境如下:Intel i7-4790 3.60 GHz, 16 GB
场景1:小数据集
测试集为小的Map集合(大约100个元素),各个方法耗时如下:
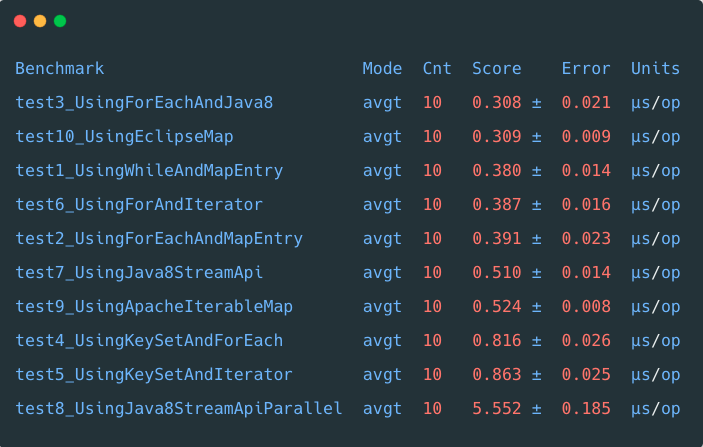
从结果看出,在数据量比较小时,利用 Java 8中的foreach 暂时领先。
场景2:中等数据集
测试集为元素数据量 1000
的 Map
集合,测试结果如下:
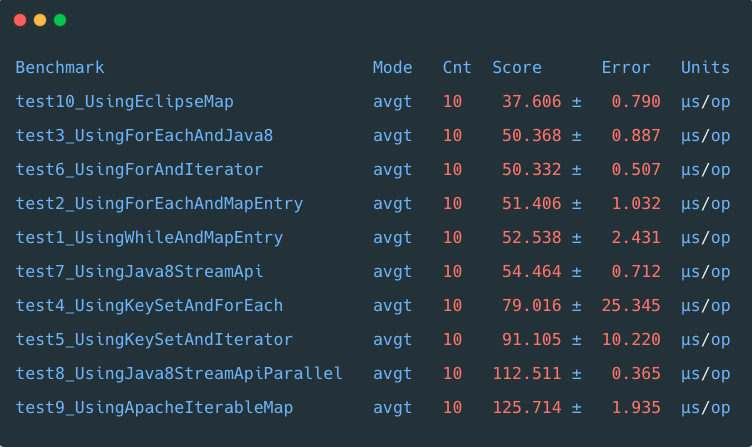
从结果集合看,在中等数据量情况下,外援 Eclipse (CS) collections
中的 MutableMap
表现最为优异,勇得第一。
其次为 Java 8
中的 foreach
,位列第二。
场景3:大数据集
测试集为元素数据量 100000
(十万级别) 的 Map
集合,测试结果如下:
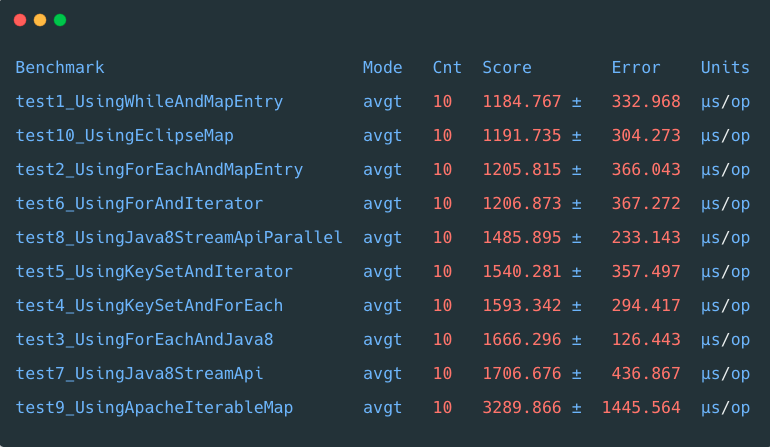
利用 iterator
和 Map.Entry
【方法1】稳居第一,领先 第二名差不多7s。
第二名为 Eclipse (CS) collections
中的 MutableMap
位列第二,在大数据量下表现表现比较出色。
指的注意的是之前在小数据量下表现比较出色的 Java 8
中的 foreach
,排名却比较靠后,但是仍然超过了利用 Java8
的Stream API
。
其中还有另一个现象:利用并行模式计算的 Java8
中的 Stream API parallel
,在大数据量时表现好于 foreach
和 stream api
。
总结性能
下表为不同数据量情况下的各个方法性能表现
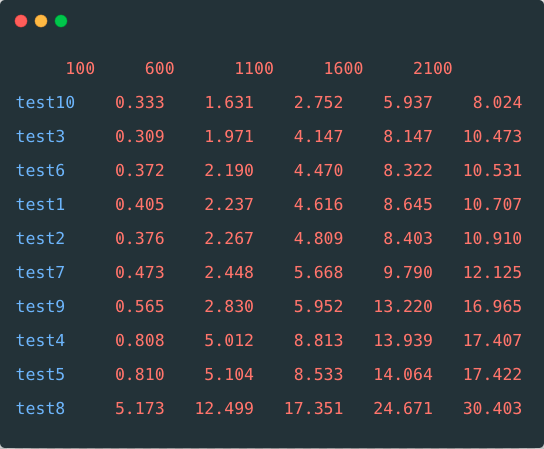
在平时开发中,数据量都不算太大时,剖除外援而言, Java 8
中的 foreach
【方法3】,表现比较优异。而并行运算的 Stream API parallel
【方法8】表现没有想象中好,Stream API
【方法7】表现中规中矩。
总结
主要罗列了多种遍历 Map
的方式,每个实现方式都有各自的特点,有的人喜欢 foreach
的通俗易懂;有的人喜欢 stream
的干净利落。
如果从性能来看,小数据量情况下:优先推荐使用 Java8 Foreach
【方法3】。
大数据量情况下推荐 使用 iterator
和Map.Entry
【方法1】。
本文非原创文章,翻译自stackoverflow 上的How do I efficiently iterate over each entry in a Java Map?问题答案之一。
原文地址为:(https://stackoverflow.com/questions/46898/how-do-i-efficiently-iterate-over-each-entry-in-a-java-map
也可以通过阅读原文跳转。
我是大黄,一个只会写 HelloWorld
的程序员,下期见。
往期推荐
