




文章目录
1,什么是Jieba分词
2,Jieba分词原理介绍
1)中文分词的原理
2)ieba分词的原理
3,Jieba分词的主要功能
1)分词
2)添加自定义词典
3)关键词提取
什么是Jieba分词
“结巴”中文分词:做最好的 Python 中文分词组件
•Jieba是个开源实现的中文分词工具•源码下载的地址:https://github.com/fxsjy/jieba•功能丰富。Jieba其实并不是只有分词这一个功能,其是一个开源框架,提供了很多在分词之上的算法,如关键词提取、词性标注等•提供多种编程语言实现。Jieba官方提供了Python、C++、Go、R、iOS等多平台多语言支持,不仅如此,还提供了很多热门社区项目的扩展插件,如ElasticSearch、solr、lucene等。在实际项目中,进行扩展十分容易•使用简单。Jieba的API总体来说并不多,且需要进行的配置并不复杂,方便上手•合成词序列的过程复制
Jieba分词原理介绍
理解jieba分词的原理之前我们先看下中文分词的原理与介绍
中文分词的原理
中文分词的模型实现主要分类两大类:基于规则和基于统计
基于规则
基于规则是指根据一个已有的词典,采用前向最大匹配、后向最大匹配、双向最大匹配等人工设定的规则来进行分词。
例如对于“上海自来水来自海上”这句话,使用前向最大匹配,即从前向后扫描,使分出来的词存在于词典中并且尽可能长,则可以得到“上海/自来水/来自/海上”。这类方法思想简单且易于实现,对数据量的要求也不高。
基于统计
基于统计是从大量人工标注语料中总结词的概率分布以及词之间的常用搭配,使用有监督学习训练分词模型。
对于“上海自来水来自海上”这句话,一个最简单的统计分词想法是,尝试所有可能的分词方案,因为任何两个字之间,要么需要切分,要么无需切分。
对于全部可能的分词方案,根据语料统计每种方案出现的概率,然后保留概率最大的一种。很显然,“上海/自来水/来自/海上”的出现概率比“上海自/来水/来自/海上”更高,因为“上海”和“自来水”在标注语料中出现的次数比“上海自”和“来水”更多。
jieba分词的原理
jieba分词结合了基于规则和基于统计两类方法
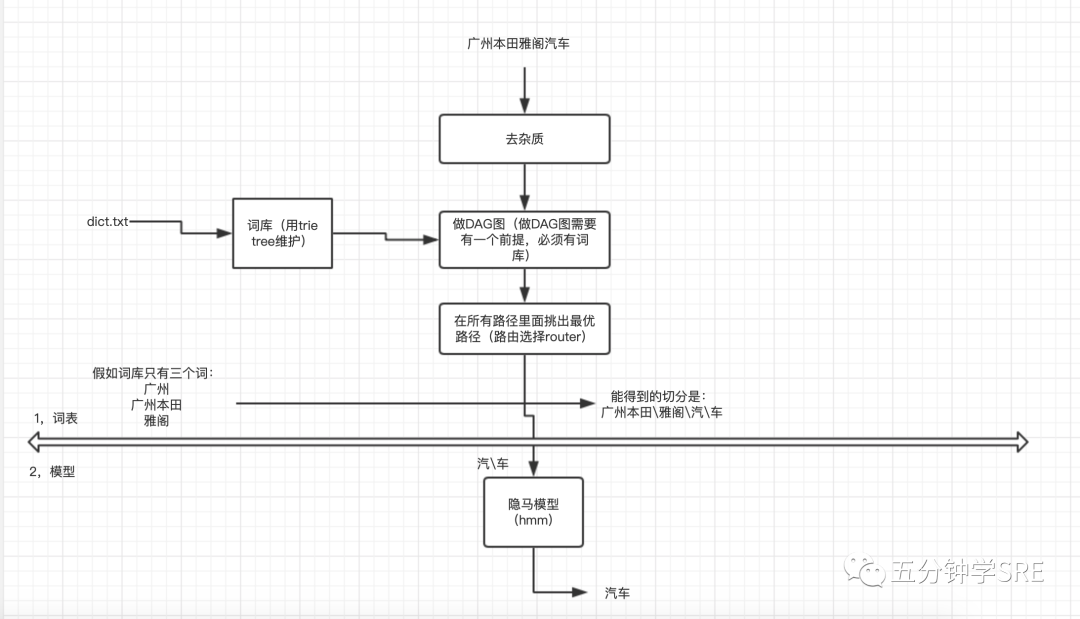
1,基于本地词库,前向遍历方式,构造DAG词图,进行最优路径选择(求概率)
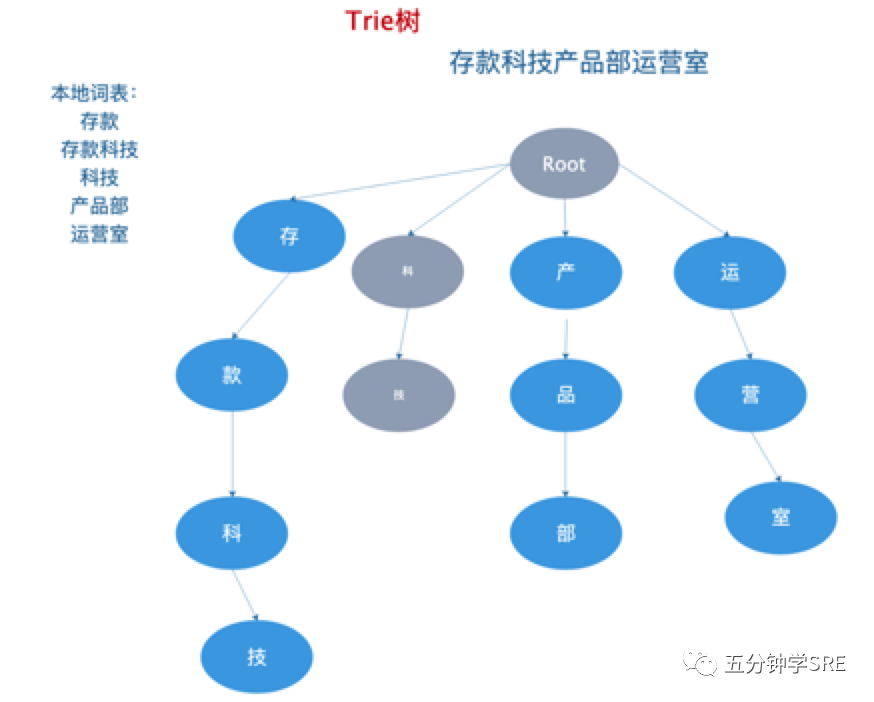
1.)基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
2.)动态规划查找最大概率路径, 找出基于词频的最大切分组合
2,对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
jieba分词原理图
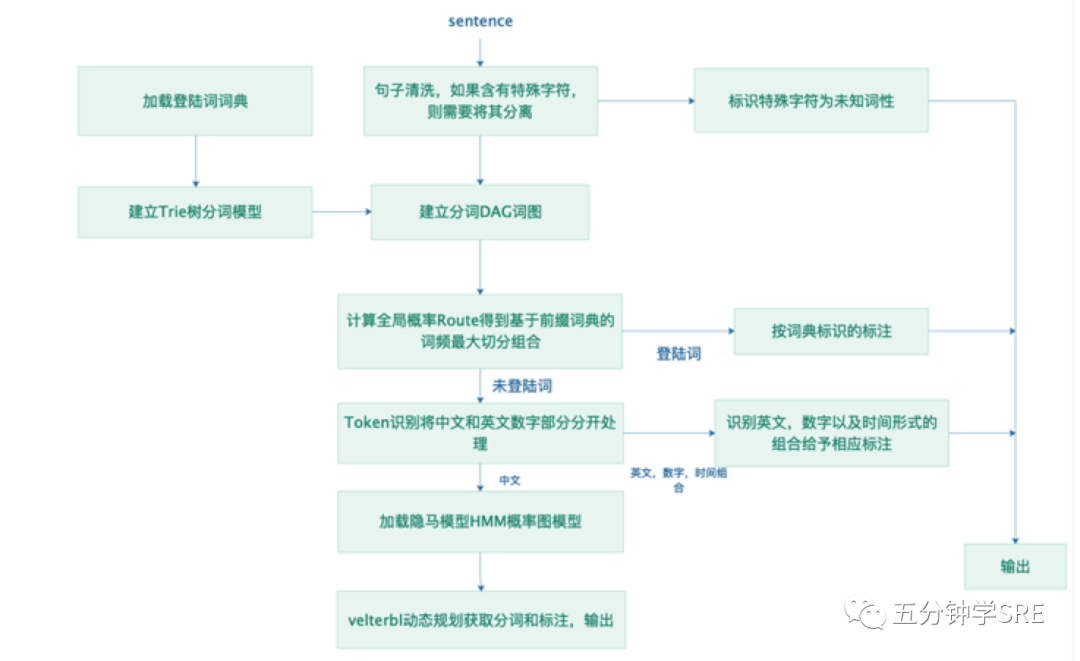
1.基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
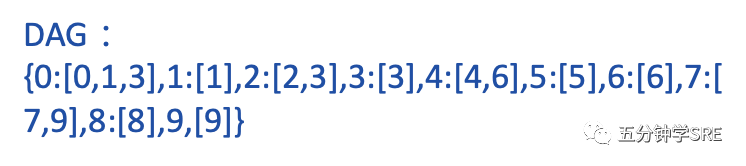
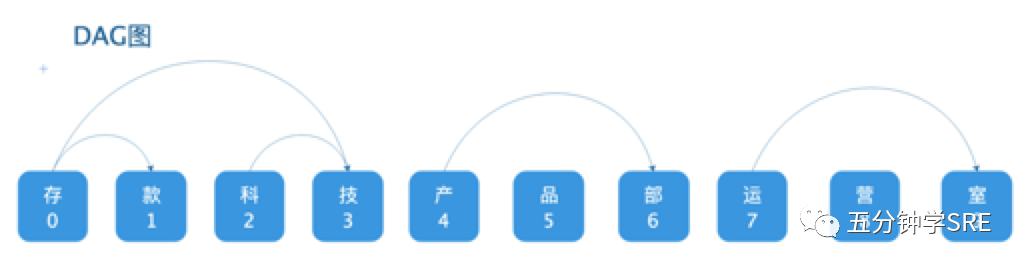
2.动态规划查找最大概率路径, 找出基于词频的最大切分组合
Jieba的Route概率-计算:http://note.youdao.com/noteshare?id=07dccf00abd2b3467b705cbde6158b5f

3.对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
隐马模型是一个双边队列
马尔可夫模型解析:http://note.youdao.com/noteshare?id=765bf925afbe796415b97ea7a25ee9a2
如果我们输入汽车,得到的是汽<B,n>,车<E,n>,我们就可以把汽车连接起来,如果得到的是汽<S,n>,车<S,n>,我们得到的是汽\车。
Jieba分词的主要功能
1,分词
jieba分词支持三种分词模式:
精确模式, 试图将句子最精确地切开,适合文本分析
全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义
搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词
调用方法
jieba.cut:该方法接受三个输入参数:参数1:需要分词的字符串;参数2:cut_all参数用来控制是否采用全模式,默认为精确模式;cut_all=True 全模式cut_all=false 精确(默认)模式参数3:HMM参数用来控制是否适用HMM模型jieba.cut_for_search:该方法接受两个参数:参数1:需要分词的字符串;参数2:是否使用HMM模型,该方法适用于搜索引擎构建倒排索引的分词,粒度比较细。
- 三种分词的例子
复制
# encoding=utf-8import jieba# 全模式seg_list = jieba.cut("", cut_all=True) print("【全模式】:" + "/ ".join(seg_list))# 精确模式seg_list = jieba.cut("", cut_all=False) print("【精确模式】:" + "/ ".join(seg_list))# 搜索引擎模式seg_list = jieba.cut_for_search("") print("【搜索引擎模式】:" + "/ ".join(seg_list))
2,添加自定义词典复制
载入词典
自定义词典补充
我们可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
用法:
jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径复制
复制
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码
词频省略时使用自动计算的能保证分出该词的词频
停用词词库补充
在分词过后,遍历一下停用词表,去掉停用词。在做数据清洗的时候为去掉一些已知逇杂质数据,往往需要自定义自己的停用词字典库
使用
用jieba.analyse.extract_tags时,设置jieba.analyse.set_stop_words才有用
jieba.analyse.set_stop_words("/stopword.txt")复制
复制
用jieba.lcut时,设置jieba.analyse.set_stop_words没有用,需要自己写过滤代码
参考:
复制
import jieba# 读取停用词列表def get_stopword_list(file):with open(file, 'r', encoding='utf-8') as f: #stopword_list = [word.strip('\n') for word in f.readlines()]return stopword_list# 分词 然后清除停用词语def clean_stopword(str, stopword_list):result = ''word_list = jieba.lcut(str) # 分词后返回一个列表 jieba.cut() 返回的是一个迭代器for w in word_list:if w not in stopword_list:result += wreturn resultif __name__ == '__main__':stopword_file = '../Dataset/stopwords-master/hit_stopwords.txt'process_file = '../Dataset/stopwords-master/LCSTS_test.json'stopword_list = get_stopword_list(stopword_file) # 获得停用词列表sents =open(process_file) # 打开要处理的文件for s in sents:print(s['src'])print(clean_stopword(s['src'], stopword_list))
调整词典
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
词典格式
词语 词频(可省略) 词性(可省略)
示例文本
复制
# 示例文本# encoding=utf-8import jiebasample_text = "# 未加载词典print("【未加载词典】:" + '/ '.join(jieba.cut(sample_text)))# 载入词典jieba.load_userdict("userdict.txt")# 加载词典后print("【加载词典后】:" + '/ '.join(jieba.cut(sample_text)))
3,关键词提取复制
jieba 提供了两种关键词提取方法,分别基于 TF-IDF 算法和 TextRank 算法。
我们只介绍常用的第一种基于 TF-IDF 算法的关键词提取
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的一份文件的重要程度,其原理可概括为:
一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章
调用方法
复制
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())•sentence 为待提取的文本•topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20•withWeight 为是否一并返回关键词权重值,默认值为 False•allowPOS 仅包括指定词性的词,默认值为空,即不筛选复制
复制
