




上一篇整理了一下Oracle数据库从接收sql后,到经过最终从数据库获取数据,大部分的方式。
今天是上一篇的延续,说说从磁盘读取到内存的方式,和我们的优化思路。今天说的两个等待事件,都是表示等待IO读取请求完成的时间。
先来解释名词:
首先我们都知道Oracle的每个等待事件都有个P1,P2,P3的参数。针对这两个等待事件,参数的意思为:
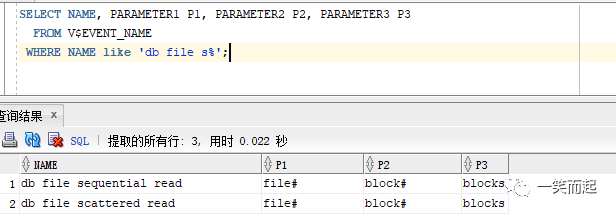
另外,我们还要知道,数据库和磁盘的逻辑关系:
数据库操纵磁盘的方式,是按照自己的逻辑单位,比如Oracle的是块 默认8k,sqlserver的是页,默认8k,mysql的是块,默认16k。
这些数据库的最小逻辑操作单位,再去对应底层操作系统或存储的块大小,比如操作系统默认4K。
好了,下面开始正文:
DB File Sequential Read: 顺序读取:
单个块单个块的从磁盘读取到连续的内存缓冲区中。
常用场景:
使用索引的方式获取数据;包括通过rowid的方式访问(index fast full scan除外)
行迁移、行连接情况;
读块头文件的情况,比如P2=1;
位图管理块;
表或者索引的大部分已在内存中,少数不连续在磁盘上的情况;
lob列上的索引块和cache的lob块;
db_file_multiblock_read_count 设置成了1;
从UNDO 获取数据(为了一致性读,从undo获取的数据都是);
DB File Scattered Read: 离散读取:
会话同时读取多个数据块并分散写入到不同的SGA缓冲区中。
全表扫描(全表扫描不一定只有scattered read,有可能从undo读,有可能大部分在内存,也有可能这个区就剩2个块)
index fast full scan
获取问题:
查看具体的读的块是什么表,可以使用如下sql:
select s.segment_name, s.partition_name
from dba_extents s
where <P2的值> between s.block_id and (s.block_id + s.blocks -1) and s.file_id= <P1的值>
v$session_longops:
通过此动态性能视图(此视图记录了运行超过6s的会话语句),来快速协助我们发现问题;
查看会话事件:
select e.sid,
s.status,
s.osuser,
s.process,
s.MACHINE,
s.PROGRAM,
e.event,
e.time_waited,
round((sysdate - s.logon_time) * 24*60) min_connected
from gv$session_event e
left join gv$session s
on e.sid=s.sid
where e.event like 'db file s%'
order by min_connected ;
根据当前运行事务的锁去看:
select /*+rule*/s.sid,p.spid,l.type,round(max(l.ctime)/60,0) lock_min,s.sql_id,s.USERNAME,b.owner,b.object_type,b.object_name
from gv$session s, gv$process p,gv$lock l,gv$locked_object o,dba_objects b
where o.SESSION_ID=s.sid and s.sid=l.sid and o.OBJECT_ID=b.OBJECT_ID and s.paddr = p.addr and l.ctime >100 and l.type in ('TX','TM','FB')
group by s.sid,p.spid,l.type,s.sql_id,s.USERNAME,b.owner,b.object_type,b.object_name order by 9,1,3,4;
--ctime单位秒
性能优化考虑的点:
SGA的buffer cache:这两个事件的本质就是从磁盘读取数据到SGA中,如果内存不足,会产生频繁的磁盘和内存交互的情况。可以看awr统计的buffer cache 命中率。free buffer waits等待事件一同出现的几率较高
控制数据量:这个算是优化的重点了,我们清楚逻辑,并能进行较好的选择和过滤。
尽量避免过大事务,避免我们的操作从undo获取;
索引本身:1 CBO计算索引的IO代价的时候,有个非常非常重要的指标,就是聚簇因子,我们可以理解为这个io cost的计算和聚簇因子是一致的。这个也要考虑进去,看是否对我们的等待事件产生了影响。2 索引本身的高水位等,这种可以考虑重建索引
根据事件,或者awr,我们可以确定有问题的table,确认是否pctfree设置过低,或者业务的update等操作过多,导致行迁移情况明显;
针对 Scattered Reads事件:可能更多的就是考虑索引问题了,甚至缺少相应的索引。
备注:
优化一定要看意义大小。比如我们为了某一个sql或者某一个不频繁的业务场景,进行了优化,就可能导致其他的场景出现问题,或者随业务增长,我们的优化就是后期的坑。
优化也都是双刃剑,比如优化聚簇因子,我们根据某列调整了表,优化了某A列的聚簇因子,那非常有可能,就会导致B列聚簇因子非常高。
direct path read: 就是跳过sga,直接从磁盘读取到pga中,给用户使用。这块此次没有详细说明。
