




1.什么是RDD
RDD 是 Spark 的计算模型。RDD(Resilient Distributed Dataset)叫做弹性的分布式数据集合,是 Spark 中最基本的数据抽象,它代表一个不可变、只读的,被分区的数据集。操作 RDD 就像操作本地集合一样,有很多的方法可以调用,使用方便,而无需关心底层的调度细节。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用。
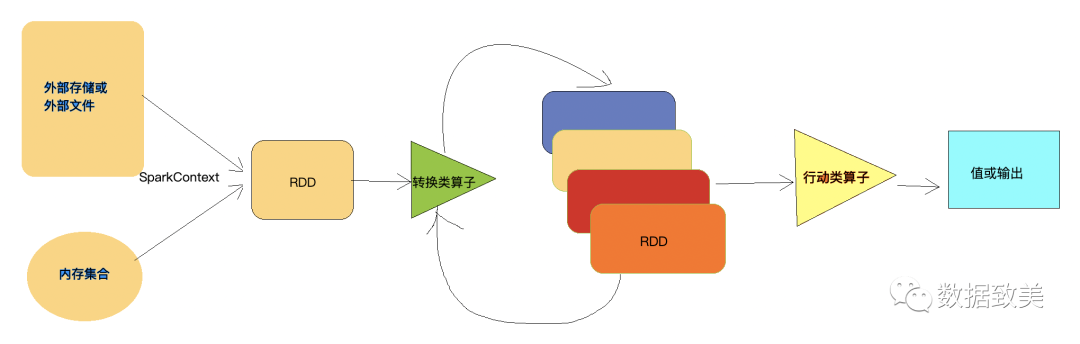
RDD的执行过程大致如下:
通过SparkContext(通往集群的唯一通道)读取外部数据源或内存中的集合创建RDD
RDD经过一系列的
Transformation
(转换类)算子进行操作生成新的RDD最一个RDD经过
Action
类算子触发执行,把结果收集到Driver端或者写入外部存储
RDD采用了惰性(lazy)执行机制,即在RDD的转换操作只是记录了执行逻辑,并不会发生真正的计算,真正的计算发生在对RDD调用了
Action
类算子。
2.RDD的五大特性
Internally, each RDD is characterized by five main properties: (RDD具有五大特性:)
A list of partitions (RDD由一系列partitions组成)
A function for computing each split (算子是作用于partition上的)
A list of dependencies on other RDDs (RDD之间有依赖关系)
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) (分区器是作用于K,V格式的RDD上)
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) (partition对外对供最佳的计算位置,得数据处理的本地化)
1.什么是K,V格式的RDD?
RDD中的每个元素是一个个的二元组,那么这个RDD就是K,V格式的RDD。
2. textFile()底层工作原理
Spark没有直接读取HDFS文件的方法,textFile()底层调用的是Mapreduce读取HDFS文件的方法。首先会split, 每个split的默认大小是128M, 就是一个block大小,每个split对应一个partition。
3.哪里体现了RDD的弹性?
1) RDD的partition的个数可多可少
2) 容错机制,即RDD之间有依赖关系
4.哪里体现了RDD的分布式?
RDD中的partition是分布在多个节点上的。
3. Spark中的Lineage机制(血统)
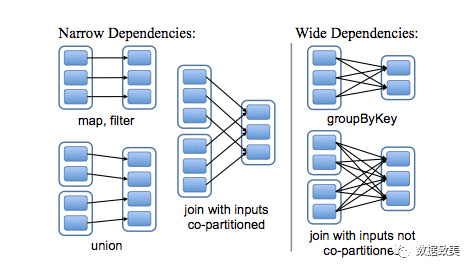
RDD在Lineage依赖方面分为两种:窄依赖(Narrow Dependencies)与宽依赖(Wide Dependencies,源码中称为Shuffle Dependencies),用来解决数据容错的高效性。
3.1.窄依赖与宽依赖
窄依赖:是指父RDD的每一个分区最多被一个子RDD的分区所使用,表现为一个父RDD的分区对应于一个子RDD分区,或者多个父RDD的分区对应一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
这里主要分为两种情况:
1)一个子RDD分区对应一个父RDD分区,如
map
,filter
等算子;2)一个子RDD分区对应N个父RDD分区,如copartitioned
;宽依赖:是指子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。
4.如何创建RDD
4.1.并行化集合创建RDD
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object ParallelizeCollection{
def main(args:Array[String]) {
val conf = new SparkConf().setAppName("ParallelizeCollection").setMaster("local")
val sc = new SparkContext(conf)
val numbers = Array(1,2,3,4,5,6,7,8,9,10)
val numberRDD = sc.parallelize(numbers)
val numberSum = numberRDD.reduce(_+_)
println("The sum of numbers: "+numberSum)
sc.stop()
}
}
4.2.通过makeRDD方法创建RDD
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object MakeRDDFromCollection{
def main(args:Array[String]) {
val conf = new SparkConf().setAppName("ParallelizeCollection").setMaster("local")
val sc = new SparkContext(conf)
val numbers = Array(1,2,3,4,5,6,7,8,9,10)
val numberRDD = sc.makeRDD(numbers)
val numberSum = numberRDD.reduce(_+_)
println("The sum of numbers: "+numberSum)
sc.stop()
}
}
【注】:这个方法是
scala
独有的,在Java
中是没有的。
4.3.通过外部源创建RDD
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object ExternalSources{
def main(args:Array[String]) {
val conf = new SparkConf().setAppName("ExternalSources").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://localhost:9000/words.txt")
val words = lines.flatMap(line=>line.split(" "))
val pairs = words.map((_,1))
val results = pairs.reduceByKey(_+_)
println("The word count is: "+results)
sc.stop()
}
}
4.4.从已有RDD调用Transformation算子创建新RDD
如上面代码中的words, pairs都是通过其父RDD调用Transformation算子得到。
