




单机redis的风险与问题
1.机器故障•现象:硬盘故障、系统崩溃•本质:数据丢失,很可能对业务造成灾难性打击2.容量瓶颈•内存不足,从16G升级到64G,从64G升级到128G,但单一机器内存插槽是有限的,无法无限升级内存
为了避免单点Redis服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服务器上,连接在一起,并保证数据是同步的。即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现Redis的高可用,同时实现数据冗余备份。
主从复制
主从复制简介
主从复制即将master中的数据即时、有效的复制到slave中
特征:一个master可以拥有多个slave,一个slave只对应一个master
角色对应的职责:
master:
•写数据•执行写操作时,将出现变化的数据自动同步到slave•读数据(可忽略,一般master节点只负责写入数据)
slave:
•读数据•写数据(一般禁止slave节点直接写数据,因主从结构中,从节点数据不会同步到主节点)
主从复制的作用
•读写分离:master写、slave读,提高服务器的读写负载能力•负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量•故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复•数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式•高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
主从复制工作流程
主从复制过程大体可以分为3个阶段
1.建立连接阶段(即准备阶段)2.数据同步阶段3.命令传播阶段
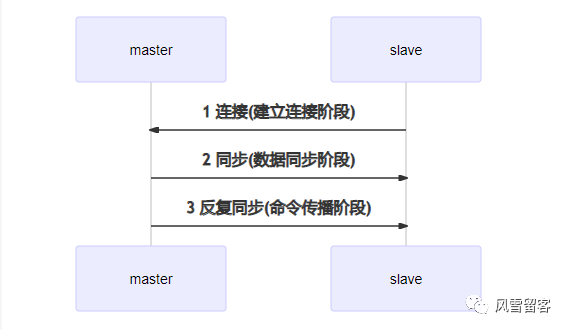
建立连接阶段
建立slave到master的连接,使master能够识别slave,并保存slave端口号
步骤
1.设置master的地址和端口,保存master信息2.建立socket连接3.发送ping命令(定时器任务)4.身份验证5.发送slave端口信息
至此,主从连接成功!
状态:
•slave:保存master的地址与端口•master:保存slave的端口•总体:之间创建了连接的socket

主从连接(slave连接master)
方式一:客户端发送命令
slaveof <masterip> <masterport>
# slave节点请求建立连接127.0.0.1:6380> slaveof 10.0.0.220 6379OK127.0.0.1:6380>##################################### master节点存入数据127.0.0.1:6379> set name zsOK127.0.0.1:6379>##################################### slave节点取出数据127.0.0.1:6380> get name"zs"127.0.0.1:6380>### 我们可以看到,主节点数据已经存入数据之后,从节点已经可以得到数据了
方式二:启动服务器参数
redis-server -slaveof <masterip> <masterport># 我们采用docker方式启动,因此,从节点启动命令如下:# 注意最后面命令 --slaveof 10.0.0.220 6379docker run -p 6380:6379 --name redis2 -v /redis-config/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf --slaveof 10.0.0.220 6379
从节点获取参数
# 可以很明显的看到,刚刚主节点的数据已经被同步了过来127.0.0.1:6379> get name"zs"127.0.0.1:6379>
方式三:服务器配置
slaveof <masterip> <masterport>
修改配置文件,增加下面配置
slaveof 10.0.0.220 6379
docker启动
docker run -p 6380:6379 --name redis2 -v /redis-config/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf
从节点获取参数
# 可以很明显的看到,从配置文件配置主从,刚刚主节点的数据已经被同步了过来127.0.0.1:6379> get name"zs"127.0.0.1:6379>
主节点点查询信息:
127.0.0.1:6379> info# Replication# 当前角色role:master# 连接的从节点数量connected_slaves:1# 从节点信息slave0:ip=172.17.0.1,port=6379,state=online,offset=1132,lag=0master_failover_state:no-failovermaster_replid:bb9fbaf3275de7982095779a01b2b4548cb858dbmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:1132second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:1132127.0.0.1:6379>
从机点查询信息:
127.0.0.1:6379> info# Replication# 当前角色role:slave# 主节点ipmaster_host:10.0.0.220# 主节点端口master_port:6379master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0slave_repl_offset:1412slave_priority:100slave_read_only:1replica_announced:1connected_slaves:0master_failover_state:no-failovermaster_replid:bb9fbaf3275de7982095779a01b2b4548cb858dbmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:1412second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:867repl_backlog_histlen:546127.0.0.1:6379>
主从断开连接
slave节点运行如下指令
# slave断开连接后,不会删除已有数据,只是不再接受master发送的数据slaveof no one
授权访问
方式一: 主节点发送指令
# master客户端发送命令设置密码config set requirepass <password># 运行指令可获取密码config get requirepass
方式二: master配置文件设置密码
requirepass <password>
slave客户端发送命令设置密码
auth <password>
slave配置文件设置密码
masterauth <password>
slave启动服务器设置密码
redis-server –a <password>
数据同步阶段工作流程
•在slave初次连接master后,复制master中的所有数据到slave•将slave的数据库状态更新成master当前的数据库状态
步骤
1.请求同步数据2.创建RDB同步数据3.恢复RDB同步数据4.请求部分同步数据5.恢复部分同步数据
至此,数据同步工作完成!

数据同步阶段master说明
1.如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行2.复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况(复制缓冲区被塞满,后面的数据进到缓冲区,将会导致缓冲区前面的数据丢失),必须进行第二次全量复制,致使slave陷入死循环状态(全量复制周期太长->复制缓冲区太小被塞满,进而导致全量复制-->全量复制周期太长->复制缓冲区太小被塞满,进而导致全量复制,进而死循环)。
# 修改master缓冲区大小 1mb(默认值)# 30%-50%的内存用于执行bgsave命令和创建复制缓冲区repl-backlog-size 1mb
3.master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执行bgsave命令和创建复制缓冲区
数据同步阶段slave说明
1.为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
# slave节点配置slave-serve-stale-data yes|no
2.数据同步阶段,master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送命令3.多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰4.slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是master,也是slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择
命令传播阶段
•当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播•master将接收到的数据变更命令发送给slave,slave接收命令后执行命令
命令传播阶段的部分复制
如果在命令传播阶段出现了断网现象,Redis会怎么做?
| 意外情况 | 处理方式 |
| 网络闪断闪连 | 忽略 |
| 短时间网络中断 | 部分复制 |
| 长时间网络中断 | 全量复制 |
部分复制的三个核心要素
1.服务器的运行 id(run id)2.主服务器的复制积压缓冲区3.主从服务器的复制偏移量
服务器运行ID(runid)
服务器运行ID介绍
服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
服务器运行ID组成
运行id由40位字符组成,是一个随机的十六进制字符 例如: fdc9ff13b9bbaab28db42b3d50f852bb5e3fcdce
服务器运行ID作用
运行id被用于在服务器间进行传输,识别身份 如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
服务器运行ID实现方式
运行id在每台服务器启动时自动生成的,master在首次连接slave时,会将自己的运行ID发送给slave,slave保存此ID,通过info Server命令,可以查看节点的runid
例如:
127.0.0.1:6379> info# Server# 运行idrun_id:03b992d974ec933eb51e307deaf1da573cbde582tcp_port:6379127.0.0.1:6379>
复制缓冲区
复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
•复制缓冲区默认数据存储空间大小是1M,由于存储空间大小是固定的,当入队元素的数量大于队列长度时,最先入队的元素会被弹出,而新元素会被放入队列
复制缓冲区由来
每台服务器启动时,如果开启有AOF或被连接成为master节点,即创建复制缓冲区
作用
用于保存master收到的所有指令(仅影响数据变更的指令,例如set,select,del等)
数据来源
当master接收到主客户端的指令时,除了将指令执行,会将该指令存储到缓冲区中
sequenceDiagrammaster->>命令传播程序: set指令命令传播程序->>复制缓冲区: master会将指令存储在复制缓冲区命令传播程序->>slave: 由命令传播程序负责分发给每一个slave节点指令
复制缓冲区组成
•偏移量•字节值
# Redis命令存入复制缓冲区之后,会对命令进行拆解,例如set name zs# 上面实名会被拆解为$3 \r \n set \r \n name \r \n zs \r \n# 存入之后,会对指令进行编排偏移量 01 02 03 04 05 06 07 ...字节值 $ 3 \r \n s e t ...
复制缓冲区工作原理
•通过offset区分不同的slave当前数据传播的差异•master记录已发送的信息对应的offset(偏移量)•slave记录已接收的信息对应的offset(偏移量)
其实说白了就是,master发送指令之后,会记录偏移量,而slave可以记录自己读取命令偏移量的位置,这样,即使其中一台slave断网之后,恢复的时候,也能继续读取未读的命令
主从服务器复制偏移量(offset)总结
概念:一个数字,描述复制缓冲区中的指令字节位置
分类:
•master复制偏移量:记录发送给所有slave的指令字节对应的位置(多个)•slave复制偏移量:记录slave接收master发送过来的指令字节对应的位置(一个)
数据来源:
•master端:发送一次记录一次•slave端:接收一次记录一次
作用:同步信息,比对master与slave的差异,当slave断线后,恢复数据使用
数据同步+命令传播阶段工作流程

心跳机制
进入命令传播阶段,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
master心跳
•指令:PING•周期:由repl-ping-slave-period决定,默认10秒•作用:判断slave是否在线•查询:INFO replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
slave心跳任务
•指令:REPLCONF ACK {offset}•周期:1秒•作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令•作用2:判断master是否在线
心跳阶段注意事项
•当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步操作
min-slaves-to-write 2min-slaves-max-lag 8
slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步
•slave数量由slave发送REPLCONF ACK命令做确认•slave延迟由slave发送REPLCONF ACK命令做确认
主从复制常见问题
频繁的全量复制1
伴随着系统的运行,master的数据量会越来越大,一旦master重启,runid将发生变化,会导致全部slave的全量复制操作
内部优化调整方案(redis自动优化):
1.master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave2.在master关闭时执行命令 shutdown save,进行RDB持久化,将runid与offset保存到RDB文件中,通过redis-check-rdb命令可以查看该信息3.master重启后加载RDB文件,恢复数据,并将RDB文件中保存的repl-id与repl-offset加载到内存中,通过info命令可以查看该信息4.本机保存上次runid,重启后恢复该值,使所有slave认为还是之前的master
频繁的全量复制2
问题现象与原因
网络环境不佳,出现网络中断,slave不提供服务,而复制缓冲区过小,断网后slave的offset越界,触发全量复制,如此循环,最终slave反复进行全量复制
解决方案
# 修改复制缓冲区大小# 建议修改如下:# 测算从master到slave的重连平均时长second# 获取master平均每秒产生写命令数据总量write_size_per_second# 最优复制缓冲区空间 = 2 * second * write_size_per_secondrepl-backlog-size
频繁的网络中断1
问题现象
master的CPU占用过高 或 slave频繁断开连接
可能的问题原因
•当slave接到了慢查询时(keys * ,hgetall等),会大量占用CPU性能•master每1秒调用复制定时函数replicationCron(),比对slave发现长时间没有进行响应
最终结果
因master需要维护与slave的连接,如果slave长时间不响应,就会导致master各种资源(输出缓冲区、带宽、连接等)被严重占用
解决方案
# 通过设置合理的超时时间,确认是否释放slave,该参数定义了超时时间的阈值(默认60秒),超过该值,释放slaverepl-timeout
频繁的网络中断2
问题现象
slave与master连接断开
可能的问题原因
•master发送ping指令频度较低•master设定超时时间较短•ping指令在网络中存在丢包
解决方案
# 提高ping指令发送的频度# ps: 超时时间repl-time的时间至少是ping指令频度的5到10倍,否则slave很容易判定超时repl-ping-slave-period
数据不一致
问题现象
多个slave获取相同数据不同步
可能的问题原因
网络信息不同步,数据发送有延迟
解决方案
•优化主从间的网络环境,通常放置在同一个机房部署,如使用阿里云等云服务器时要注意此现象•监控主从节点延迟(通过offset)判断,如果slave延迟过大,暂时屏蔽程序对该slave的数据访问
# 开启后仅响应info、slaveof等少数命令(慎用,除非对数据一致性要求很高)slave-serve-stale-data yes|no
哨兵模式
哨兵简介
哨兵(sentinel) 是一个分布式系统,用于对主从结构中的每台服务器进行监控
,当出现故障时通过投票机制选择
新的master并将所有slave连接到新的master。
哨兵的作用
•监控•不断的检查master和slave是否正常运行。•master存活检测、master与slave运行情况检测。•通知(提醒)•当被监控的服务器出现问题时,向其他(哨兵,客户端)发送通知。•自动故障转移•断开master与slave连接,选取一个slave作为master,将其他slave连接到新的master,并告知客户端新的服务器地址
PS: 哨兵也是一台redis服务器,只是不提供数据服务 通常哨兵配置数量为单数
哨兵模式的配置
Redis 源码中包含了一个名为 sentinel.conf 的文件, 这个文件是一个带有详细注释的 Sentinel 配置文件示例。
运行一个 Sentinel 所需的最少配置如下所示:
# sentinel监听端口,默认是26379port 26379# 哨兵进程服务临时文件夹,默认为/tmp,要保证有可写入的权限dir /tem# 选项的基本格式如下:# sentinel <选项的名字> <主服务器的名字> <选项的值># 配置指示 Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6379 , 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)。# 不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。# 换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。# 不需要指定slave的地址,sentinel连接到master之后可以自行获取sentinel monitor mymaster 127.0.0.1 6379 2# down-after-milliseconds 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数。sentinel down-after-milliseconds mymaster 60000# 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟sentinel failover-timeout mymaster 180000# parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。# 你可以通过将这个值设为 1 来保证每次只有一个从服务器处于不能处理命令请求的状态。sentinel parallel-syncs mymaster 1sentinel monitor resque 192.168.1.3 6380 4sentinel down-after-milliseconds resque 10000sentinel failover-timeout resque 180000sentinel parallel-syncs resque 5
启动 Sentinel
对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统:
redis-sentinel sentinel.conf
对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器:
redis-server /path/to/sentinel.conf --sentinel
两种方法都可以启动一个 Sentinel 实例。
启动 Sentinel 实例必须指定相应的配置文件, 系统会使用配置文件来保存 Sentinel 的当前状态, 并在 Sentinel 重启时通过载入配置文件来进行状态还原。
如果启动 Sentinel 时没有指定相应的配置文件, 或者指定的配置文件不可写(not writable), 那么 Sentinel 会拒绝启动。
编写配置文件
# 配置文件除端口外,其他相同[root@localhost redis-config]# lsredis-6379.conf redis-6380.conf redis-6381.conf sentinel-26379.conf sentinel-26380.conf sentinel-26381.conf[root@localhost redis-config]#
启动一主两从
# 主docker run -p 6379:6379 --name redis1 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6379.conf# 从1docker run -p 6380:6380 --name redis2 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6380.conf --slaveof 10.0.0.220 6379# 从2docker run -p 6381:6381 --name redis3 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6381.conf --slaveof 10.0.0.220 6379
启动三哨兵
docker run -p 26379:26379 --name sentinel1 --net=host -v /redis-config:/etc/redis -d redis redis-sentinel /etc/redis/sentinel-26379.confdocker run -p 26380:26380 --name sentinel2 --net=host -v /redis-config:/etc/redis -d redis redis-sentinel /etc/redis/sentinel-26380.confdocker run -p 26381:26381 --name sentinel3 --net=host -v /redis-config:/etc/redis -d redis redis-sentinel /etc/redis/sentinel-26381.conf
查看启动的服务
首先我们先启动一个哨兵,然后检查服务启动情况
[root@localhost ~]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES11f45c8f3835 redis "docker-entrypoint.s…" 2 minutes ago Up 2 minutes sentinel1c71552219c46 redis "docker-entrypoint.s…" 3 minutes ago Up 3 minutes redis3b655f7525144 redis "docker-entrypoint.s…" 3 minutes ago Up 3 minutes redis2ba41e5ba5c53 redis "docker-entrypoint.s…" 3 minutes ago Up 3 minutes redis1[root@localhost ~]#
进入哨兵容器,查询哨兵信息
# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0# status状态ok address主服务地址 slaves从节点数量 sentinels哨兵数量master0:name=mymaster,status=ok,address=10.0.0.220:6379,slaves=2,sentinels=1127.0.0.1:26379>
测试哨兵功能
启动三个哨兵,查看信息
# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0# 我们看到,现在哨兵已经已经启动是三个了,目前主服务器仍然是10.0.0.220:6379master0:name=mymaster,status=ok,address=10.0.0.220:6379,slaves=2,sentinels=3127.0.0.1:26379>
停止6379服务,观察哨兵信息
# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0# 此时,主服务已经从6379切换到6380master0:name=mymaster,status=ok,address=10.0.0.220:6380,slaves=2,sentinels=3
主观下线和客观下线
Redis 的 Sentinel 中关于下线(down)有两个不同的概念:
•主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。•客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。(一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复(valid reply), 那么 Sentinel 就会将这个服务器标记为主观下线。
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
•返回 +PONG 。•返回 -LOADING 错误。•返回 -MASTERDOWN 错误。
如果服务器返回除以上三种回复之外的其他回复, 又或者在指定时间内没有回复 PING 命令, 那么 Sentinel 认为服务器返回的回复无效(non-valid)。
注意, 一个服务器必须在 master-down-after-milliseconds 毫秒内, 一直返回无效回复才会被 Sentinel 标记为主观下线。
举个例子, 如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒), 那么只要服务器能在每 29 秒之内返回至少一次有效回复, 这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议:如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。
客观下线条件只适用于主服务器:对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对失效的主服务器执行自动故障迁移操作。
每个 Sentinel 都需要定期执行的任务
•每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。•如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。一个有效回复可以是:+PONG 、 -LOADING 或者 -MASTERDOWN 。•如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。•如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。•在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。•当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主观下线状态就会被移除。
自动发现 Sentinel 和从服务器
一个 Sentinel 可以与其他多个 Sentinel 进行连接, 各个 Sentinel 之间可以互相检查对方的可用性, 并进行信息交换。
你无须为运行的每个 Sentinel 分别设置其他 Sentinel 的地址, 因为 Sentinel 可以通过发布与订阅功能来自动发现正在监视相同主服务器的其他 Sentinel , 这一功能是通过向频道 sentinel:hello 发送信息来实现的。
与此类似, 你也不必手动列出主服务器属下的所有从服务器, 因为 Sentinel 可以通过询问主服务器来获得所有从服务器的信息。
•每个 Sentinel 会以每两秒一次的频率, 通过发布与订阅功能, 向被它监视的所有主服务器和从服务器的 sentinel:hello 频道发送一条信息, 信息中包含了 Sentinel 的 IP 地址、端口号和运行 ID (runid)。•每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的 sentinel:hello 频道, 查找之前未出现过的 sentinel (looking for unknown sentinels)。当一个 Sentinel 发现一个新的 Sentinel 时, 它会将新的 Sentinel 添加到一个列表中, 这个列表保存了 Sentinel 已知的, 监视同一个主服务器的所有其他 Sentinel 。•Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。•在将一个新 Sentinel 添加到监视主服务器的列表上面之前, Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel , 如果是的话, Sentinel 会先移除列表中已有的那些拥有相同运行 ID 或者相同地址的 Sentinel , 然后再添加新 Sentinel 。
Sentinel API
在默认情况下, Sentinel 使用 TCP
端口 26379 (普通 Redis 服务器使用的是 6379 )。
Sentinel 接受 Redis 协议格式的命令请求, 所以你可以使用 redis-cli 或者任何其他 Redis 客户端来与 Sentinel 进行通讯。
有两种方式可以和 Sentinel 进行通讯:
•第一种方法是通过直接发送命令来查询被监视 Redis 服务器的当前状态, 以及 Sentinel 所知道的关于其他 Sentinel 的信息, 诸如此类。•另一种方法是使用发布与订阅功能, 通过接收 Sentinel 发送的通知:当执行故障转移操作, 或者某个被监视的服务器被判断为主观下线或者客观下线时, Sentinel 就会发送相应的信息。
Sentinel 命令
以下列出的是 Sentinel 接受的命令:
•PING :返回 PONG 。•SENTINEL masters :列出所有被监视的主服务器,以及这些主服务器的当前状态。•SENTINEL slaves :列出给定主服务器的所有从服务器,以及这些从服务器的当前状态。•SENTINEL get-master-addr-by-name :返回给定名字的主服务器的 IP 地址和端口号。如果这个主服务器正在执行故障转移操作, 或者针对这个主服务器的故障转移操作已经完成, 那么这个命令返回新的主服务器的 IP 地址和端口号。•SENTINEL reset :重置所有名字和给定模式 pattern 相匹配的主服务器。pattern 参数是一个 Glob 风格的模式。重置操作清楚主服务器目前的所有状态, 包括正在执行中的故障转移, 并移除目前已经发现和关联的, 主服务器的所有从服务器和 Sentinel 。•SENTINEL failover :当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移 (不过发起故障转移的 Sentinel 会向其他 Sentinel 发送一个新的配置,其他 Sentinel 会根据这个配置进行相应的更新)。
故障转移
一次故障转移操作由以下步骤组成:
•发现主服务器已经进入客观下线状态。•对我们的当前纪元进行自增(详情请参考 Raft leader election ), 并尝试在这个纪元中当选。•如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。如果当选成功, 那么执行以下步骤。•选出一个从服务器,并将它升级为主服务器。•向被选中的从服务器发送 SLAVEOF NO ONE
命令,让它转变为主服务器。•通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。•向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。•当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
Sentinel 使用以下规则来选择新的主服务器:
•在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。•在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。•在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器;如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。
Sentinel 自动故障迁移的一致性特质
Sentinel 自动故障迁移使用 Raft 算法来选举领头(leader) Sentinel , 从而确保在一个给定的纪元(epoch)里, 只有一个领头产生。
这表示在同一个纪元中, 不会有两个 Sentinel 同时被选中为领头, 并且各个 Sentinel 在同一个纪元中只会对一个领头进行投票。
更高的配置纪元总是优于较低的纪元, 因此每个 Sentinel 都会主动使用更新的纪元来代替自己的配置。
简单来说, 我们可以将 Sentinel 配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他 Sentinel 。
举个例子, 当出现网络分割(network partitions)时, 一个 Sentinel 可能会包含了较旧的配置, 而当这个 Sentinel 接到其他 Sentinel 发来的版本更新的配置时, Sentinel 就会对自己的配置进行更新。
如果要在网络分割出现的情况下仍然保持一致性, 那么应该使用 min-slaves-to-write 选项, 让主服务器在连接的从实例少于给定数量时停止执行写操作, 与此同时, 应该在每个运行 Redis 主服务器或从服务器的机器上运行 Redis Sentinel 进程。
Sentinel 状态的持久化
Sentinel 的状态会被持久化在 Sentinel 配置文件里面。
每当 Sentinel 接收到一个新的配置, 或者当领头 Sentinel 为主服务器创建一个新的配置时, 这个配置会与配置纪元一起被保存到磁盘里面。
这意味着停止和重启 Sentinel 进程都是安全的。
Sentinel 在非故障迁移的情况下对实例进行重新配置
即使没有自动故障迁移操作在进行, Sentinel 总会尝试将当前的配置设置到被监视的实例上面。特别是:
•根据当前的配置, 如果一个从服务器被宣告为主服务器, 那么它会代替原有的主服务器, 成* 为新的主服务器, 并且成为原有主服务器的所有从服务器的复制对象。那些连接了错误主服务器的从服务器会被重新配置, 使得这些从服务器会去复制正确的主服务器。
不过, 在以上这些条件满足之后, Sentinel 在对实例进行重新配置之前仍然会等待一段足够长的时间, 确保可以接收到其他 Sentinel 发来的配置更新, 从而避免自身因为保存了过期的配置而对实例进行了不必要的重新配置。
TILT 模式
Redis Sentinel 严重依赖计算机的时间功能:比如说, 为了判断一个实例是否可用, Sentinel 会记录这个实例最后一次相应 PING 命令的时间, 并将这个时间和当前时间进行对比, 从而知道这个实例有多长时间没有和 Sentinel 进行任何成功通讯。
不过, 一旦计算机的时间功能出现故障, 或者计算机非常忙碌, 又或者进程因为某些原因而被阻塞时, Sentinel 可能也会跟着出现故障。
TILT 模式是一种特殊的保护模式:当 Sentinel 发现系统有些不对劲时, Sentinel 就会进入 TILT 模式。
因为 Sentinel 的时间中断器默认每秒执行 10 次, 所以我们预期时间中断器的两次执行之间的间隔为 100 毫秒左右。Sentinel 的做法是, 记录上一次时间中断器执行时的时间, 并将它和这一次时间中断器执行的时间进行对比:
•如果两次调用时间之间的差距为负值, 或者非常大(超过 2 秒钟), 那么 Sentinel 进入 TILT 模式。•如果 Sentinel 已经进入 TILT 模式, 那么 Sentinel 延迟退出 TILT 模式的时间。
当 Sentinel 进入 TILT 模式时, 它仍然会继续监视所有目标, 但是:
•它不再执行任何操作,比如故障转移。•当有实例向这个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令时, Sentinel 返回负值:因为这个 Sentinel 所进行的下线判断已经不再准确。
如果 TILT 可以正常维持 30 秒钟, 那么 Sentinel 退出 TILT 模式。
Redis集群
Redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令.
Redis 集群的优势:
•自动分割数据到不同的节点上。•整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
•节点 A 包含 0 到 5500号哈希槽.•节点 B 包含5501 到 11000 号哈希槽.•节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味着在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
•客户端向主节点B写入一条命令.•主节点B向客户端回复命令状态.•主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。注意:Redis 集群可能会在将来提供同步写的方法。Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项。
集群的配置
# 开实例的集群模式cluster-enabled yes# 保存节点配置文件的路径, 默认值为 nodes.conf.节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。cluster-config-file nodes-{port}.conf# 节点超时时间cluster-node-timeout 5000# 是否开启AOF持久化appendonly yes# 保证redis集群中不会出现裸奔的主节点(这个主节点没有对应的从节点),当某个主节点的从节点挂掉裸奔后,会从其他富余的主节点分配一个从节点过来,确保每个主节点都有至少一个从节点,不至于因为主节点挂掉而没有相应从节点替换为主节点导致集群崩溃不可用。1意味着一个从节点只有在其主节点另外至少还有一个正常工作的从节点的情况下才会被分配...cluster-migration-barrier 1
启动六个Redis实例
docker run -p 6379:6379 --name redis1 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6379.confdocker run -p 6380:6380 --name redis2 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6380.confdocker run -p 6381:6381 --name redis3 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6381.confdocker run -p 6382:6382 --name redis4 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6382.confdocker run -p 6383:6383 --name redis5 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6383.confdocker run -p 6384:6384 --name redis6 --net=host -v /redis-config:/etc/redis -d redis redis-server /etc/redis/redis-6384.conf[root@localhost ~]# ps -ef | grep redispolkitd 28552 28532 0 19:59 ? 00:00:01 redis-server 0.0.0.0:6379 [cluster]polkitd 28620 28600 0 19:59 ? 00:00:01 redis-server 0.0.0.0:6380 [cluster]polkitd 28685 28664 0 19:59 ? 00:00:01 redis-server 0.0.0.0:6381 [cluster]polkitd 28750 28729 0 19:59 ? 00:00:00 redis-server 0.0.0.0:6382 [cluster]polkitd 28817 28796 0 20:00 ? 00:00:00 redis-server 0.0.0.0:6383 [cluster]polkitd 28884 28863 0 20:00 ? 00:00:00 redis-server 0.0.0.0:6384 [cluster][root@localhost ~]#
创建Redis集群
docker方式
## 进入容器[root@localhost ~]# docker exec -it 6e2ec4ac841b /bin/sh# 执行如下命令redis-cli --cluster create 10.0.0.220:6379 10.0.0.220:6380 10.0.0.220:6381 10.0.0.220:6382 10.0.0.220:6383 10.0.0.220:6384 --cluster-replicas 1# redis-cli --cluster create 10.0.0.220:6379 10.0.0.220:6380 10.0.0.220:6381 10.0.0.220:6382 10.0.0.220:6383 10.0.0.220:6384 --cluster-replicas 1>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383# 分配主从关系Adding replica 10.0.0.220:6383 to 10.0.0.220:6379Adding replica 10.0.0.220:6384 to 10.0.0.220:6380Adding replica 10.0.0.220:6382 to 10.0.0.220:6381>>> Trying to optimize slaves allocation for anti-affinity[WARNING] Some slaves are in the same host as their masterM: a6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379slots:[0-5460] (5461 slots) masterM: 8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380slots:[5461-10922] (5462 slots) masterM: 942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381slots:[10923-16383] (5461 slots) masterS: f350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382replicates a6e516711387d64421440538ebbffeda923b95dbS: a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383replicates 8f3927fb47fec5cc974a7721e977a87009997fc0S: c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384replicates 942cb70a27a5db2a05101b979b2d6684dea50a71Can I set the above configuration? (type 'yes' to accept):# 输入yes继续Can I set the above configuration? (type 'yes' to accept): yes>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the clusterWaiting for the cluster to join# 以下M为主节点, S为从节点 slots:[0-5460]为每个主节点分配的槽>>> Performing Cluster Check (using node 10.0.0.220:6379)M: a6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379slots:[0-5460] (5461 slots) master1 additional replica(s)M: 8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380slots:[5461-10922] (5462 slots) master1 additional replica(s)S: a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383slots: (0 slots) slavereplicates 8f3927fb47fec5cc974a7721e977a87009997fc0S: f350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382slots: (0 slots) slavereplicates a6e516711387d64421440538ebbffeda923b95dbS: c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384slots: (0 slots) slavereplicates 942cb70a27a5db2a05101b979b2d6684dea50a71M: 942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381slots:[10923-16383] (5461 slots) master1 additional replica(s)[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...# 分配成功[OK] All 16384 slots covered.
非docker方式
# 需要安装 ruby依赖,参考如下:# https://blog.csdn.net/HeyShHeyou/article/details/108937918# --replicas 1 1代表1个master连接1个slave,2代表1个master连接2个slave# 后面的ip地址,只填写masterid与端口,slave会根基你的配置进行自动分配,且数量需要匹配# 进入redis源码中找到src目录下的 redis-trib.rb 文件./redis-trib.rb create --replicas 1 10.0.0.220:6379 10.0.0.220:6380 10.0.0.220:6381
查看Redis生成的配置文件
# 我们可以看到,该配置文件中记录的所有的主从ip列表,并且记录了每个主服务对应的槽root@localhost:/data# cat nodes-6379.conf8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380@16380 master - 0 1633698639280 2 connected 5461-10922a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383@16383 slave 8f3927fb47fec5cc974a7721e977a87009997fc0 0 1633698638000 2 connectedf350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382@16382 slave a6e516711387d64421440538ebbffeda923b95db 0 1633698640000 1 connected# myself代指自己 connected所对应的槽a6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379@16379 myself,master - 0 1633698639000 1 connected 0-5460c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384@16384 slave 942cb70a27a5db2a05101b979b2d6684dea50a71 0 1633698640301 3 connected942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381@16381 master - 0 1633698639000 3 connected 10923-16383vars currentEpoch 6 lastVoteEpoch 0root@localhost:/data#
测试Redis集群
集群存放数据与获取数据
root@localhost:/data# redis-cli127.0.0.1:6379> set name zs# 使用set命令不能直接存放数据,提示需要移动到对应的主节点存放(error) MOVED 5798 10.0.0.220:6380127.0.0.1:6379># 此时我们需要在连接的时候指定为针对集群操作root@localhost:/data# redis-cli -c127.0.0.1:6379> set name zs# 数据正常存放,并自动移动到对应的主节点与槽中-> Redirected to slot [5798] located at 10.0.0.220:6380OK10.0.0.220:6380># 如果在连接时,不指定直接获取数据,同样会出现异常10.0.0.220:6380> get name"zs"10.0.0.220:6380># 正确的操作root@localhost:/data# redis-cli127.0.0.1:6379> get name(error) MOVED 5798 10.0.0.220:6380127.0.0.1:6379>
测试主从自动切换
下线slave节点
# 主从关系明细:Adding replica 10.0.0.220:6383 to 10.0.0.220:6379Adding replica 10.0.0.220:6384 to 10.0.0.220:6380Adding replica 10.0.0.220:6382 to 10.0.0.220:6381# 我们以Adding replica 10.0.0.220:6382 to 10.0.0.220:6381 为测试对象# 根据docker启动Redis命令可只,对应的容器名为redis3,redis4,对应的端口分别为6381,6382,id为43f8c89fccb4,952d14c50148# 下载从节点,即 952d14c50148[root@localhost src]# docker stop 952d14c50148# 查询节点信息127.0.0.1:6379> cluster nodes8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380@16380 master - 0 1633700577810 2 connected 5461-10922a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383@16383 slave 8f3927fb47fec5cc974a7721e977a87009997fc0 0 1633700577000 2 connected# 6382被标记为 fail ,即下线f350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382@16382 slave,fail a6e516711387d64421440538ebbffeda923b95db 1633700543982 1633700539000 1 disconnecteda6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379@16379 myself,master - 0 1633700576000 1 connected 0-5460c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384@16384 slave 942cb70a27a5db2a05101b979b2d6684dea50a71 0 1633700576000 3 connected942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381@16381 master - 0 1633700575000 3 connected 10923-16383127.0.0.1:6379># 重新启动6382[root@localhost src]# docker start 952d14c50148# 查询节点信息,6382已经正常127.0.0.1:6379> cluster nodes8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380@16380 master - 0 1633700703182 2 connected 5461-10922a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383@16383 slave 8f3927fb47fec5cc974a7721e977a87009997fc0 0 1633700702150 2 connectedf350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382@16382 slave a6e516711387d64421440538ebbffeda923b95db 0 1633700701131 1 connecteda6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379@16379 myself,master - 0 1633700702000 1 connected 0-5460c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384@16384 slave 942cb70a27a5db2a05101b979b2d6684dea50a71 0 1633700701131 3 connected942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381@16381 master - 0 1633700702000 3 connected 10923-16383127.0.0.1:6379>
下线master节点
# 下线master节点[root@localhost src]# docker stop 43f8c89fccb4# 查询节点信息# 从以下信息我们可以看出,目前master节点显示为4个,但其中一个被标记为fail状态,即Redis将其中一个从节点升级为主节点,并将之前主节点的槽分配给新上任的master,数据进行了故障转移操作127.0.0.1:6379> cluster nodes8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380@16380 master - 0 1633701040436 2 connected 5461-10922a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383@16383 slave 8f3927fb47fec5cc974a7721e977a87009997fc0 0 1633701039406 2 connectedf350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382@16382 slave a6e516711387d64421440538ebbffeda923b95db 0 1633701038000 1 connecteda6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379@16379 myself,master - 0 1633701039000 1 connected 0-5460c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384@16384 master - 0 1633701038386 7 connected 10923-16383# 该master被标记为fail942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381@16381 master,fail - 1633701009769 1633701005000 3 disconnected# 重新上线该master[root@localhost src]# docker start 43f8c89fccb4127.0.0.1:6379> cluster nodes8f3927fb47fec5cc974a7721e977a87009997fc0 10.0.0.220:6380@16380 master - 0 1633701753219 2 connected 5461-10922a976c92dbd102cb908ca5b98590899883ea470dc 10.0.0.220:6383@16383 slave 8f3927fb47fec5cc974a7721e977a87009997fc0 0 1633701752000 2 connectedf350f49766a521acc2d20850d12902eb18ac681e 10.0.0.220:6382@16382 slave a6e516711387d64421440538ebbffeda923b95db 0 1633701752198 1 connecteda6e516711387d64421440538ebbffeda923b95db 10.0.0.220:6379@16379 myself,master - 0 1633701751000 1 connected 0-5460c95f2942fc99918171edeaa9f2bb470c1697e47c 10.0.0.220:6384@16384 master - 0 1633701751177 7 connected 10923-16383# 重新上线后,该master变为从节点重新加入节点942cb70a27a5db2a05101b979b2d6684dea50a71 10.0.0.220:6381@16381 slave c95f2942fc99918171edeaa9f2bb470c1697e47c 0 1633701751000 7 connected127.0.0.1:6379>
总结
•下线slave节点,集群角色并不会发生改变,但仍需要关注集群健壮性•下线master会将slave节点变成master,并会进行数据故障转移,待原来的master节点重新上线后,变成slave节点加入到集群中
Redis集群命令
# 查看集群节点信息cluster nodes# 进入一个从节点 redis,切换其主节点cluster replicate <master-id># 发现一个新节点,新增主节点cluster meet ip:port# 忽略一个没有solt的节点cluster forget <id># 手动故障转移cluster failover# 添加节点redis-trib.rb add-node# 删除节点redis-trib.rb del-node# 重新分片redis-trib.rb reshard
Redis之缓存预热,雪崩,击穿,穿透
缓存预热
缓存预热就是系统上线后,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
缓存预热解决方案:
1.直接写个缓存刷新页面,上线时手工操作下;2.数据量不大,可以在项目启动的时候自动进行加载;3.定时刷新缓存;
缓存雪崩
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接请求数据库,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果重启数据库,马上又会有新的流量导致数据库崩溃。这就是缓存雪崩。
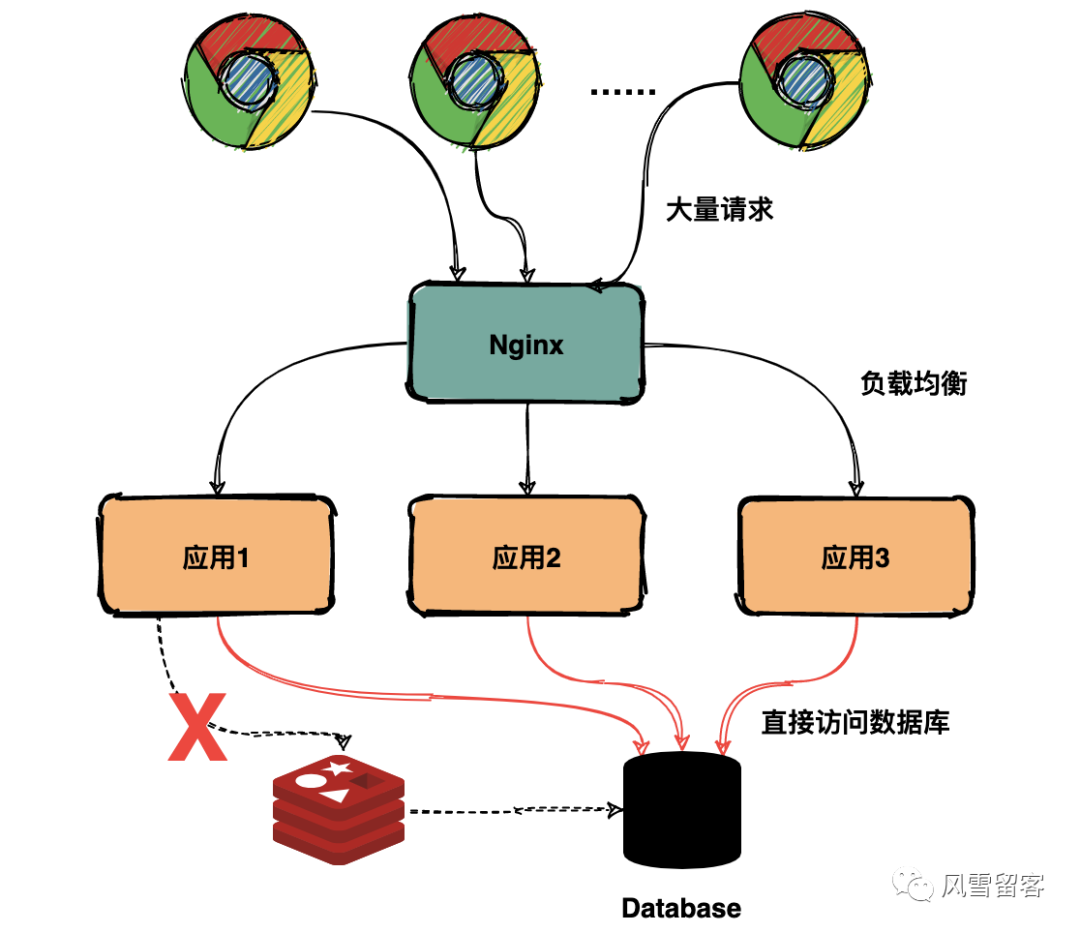
造成缓存雪崩的关键在于在同一时间大规模的key失效。出现这个问题有两种可能,第一种可能是Redis宕机,第二种可能是采用了相同的过期时间。
解决方案:
1、在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
如果真的发生了缓存雪崩,有没有什么兜底的措施?
2、使用熔断机制。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
3、提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
4、为了防止Redis宕机导致缓存雪崩的问题,可以搭建Redis集群,提高Redis的容灾性。
缓存击穿
什么是缓存击穿?
其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
分析:
关键在于某个热点的key失效了,导致大并发集中打在数据库上。所以要从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
解决方案:
1、如果业务允许的话,对于热点的key可以设置永不过期的key。
2、使用互斥锁。如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库崩溃。当然这样会导致系统的性能变差。
缓存穿透
什么是缓存穿透?
我们使用Redis大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在Redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
分析:
关键在于在Redis查不到key值,这和缓存击穿有根本的区别,区别在于缓存穿透的情况是传进来的key在Redis中是不存在的。假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示,要对调用方保持这种“不信任”的心态。
解决方案:
1、把无效的Key存进Redis中。如果Redis查不到数据,数据库也查不到,我们把这个Key值保存进Redis,设置value="null",当下次再通过这个Key查询时就不需要再查询数据库。并设定短时限,例如30-60秒,最高5分钟。但这种处理方式肯定是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
2、使用布隆过滤器。布隆过滤器的作用是某个 key 不存在,那么就一定不存在,它说某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询 key 是否存在,如果不存在就直接返回。
