




点击上方"数据与人", 右上角选择“设为星标”
分享干货,共同成长!


【前言】
经常有一些朋友向我咨询,如何写出高效的SQL,这不是三言两语能说得清的,索性认真来写一下,增删查改方面的知识我不再赘述,如果有基础薄弱的同学,可以好好的补一补再来看。
以MySQL为基础,MySQL调优篇内容主要包含MySQL逻辑架构、索引知识、表关联算法、explain执行计划解读及SQL调优实战等。
文章受众主要为两类人:
第一类人是工作中不可避免的会接触到MySQL的人,比如说一些项目人员、开发人员、测试人员等。
第二类人是专职DBA。
其实不管是专职的还是非专职的,就我接触到的情况而言,很多DBA平时维护MySQL看起来没什么问题,但其实没有很好的理论支撑,知其然而不知其所以然,解释一个简单的问题就能问倒一大部分的人。
比如说:MySQL的逻辑架构,分析当前业务架构优缺点?SQL工作原理是什么样的?
而且很多公司招聘面试的时候,考验的也是背后的原理居多,基本上没有机试。面试官问一个问题,即便你会解决但就是说不出原理,那么你肯定要不了高薪。
理论+实战=高薪
文章能够让大家有所收获、有所借鉴那是最好的。
【SQL调优实战】
1、环境准备
每张表模拟一些数据进去。
article表CREATE TABLE IF NOT EXISTS `article`(`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`author_id` INT (10) UNSIGNED NOT NULL,`category_id` INT(10) UNSIGNED NOT NULL ,`views` INT(10) UNSIGNED NOT NULL ,`comments` INT(10) UNSIGNED NOT NULL,`title` VARBINARY(255) NOT NULL,`content` TEXT NOT NULL);class表CREATE TABLE IF NOT EXISTS `class`(`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`card` INT (10) UNSIGNED NOT NULL);book表CREATE TABLE IF NOT EXISTS `book`(`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`card` INT (10) UNSIGNED NOT NULL);phone表CREATE TABLE IF NOT EXISTS `phone`(`phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`card` INT (10) UNSIGNED NOT NULL)ENGINE = INNODB;staffs表CREATE TABLE staffs(id INT PRIMARY KEY AUTO_INCREMENT,`name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名',`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间')CHARSET utf8 COMMENT'员工记录表';ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`)复制
2、单表优化案例
需求分析:
查询category_id为1且comments大于1的情况下,views最多的article_id
select id, author_idfrom articlewhere category_id = 1and comments > 1order by views desc limit 1;复制
执行计划:

5.7版本后添加了列filtered,意思是:指返回结果的行占需要读到的行(rows列的值)的百分比,filtered的数值其实越高,表示通过索引直接返回的行很多,数值较低时,一般出现在type=ALL或者index的情况。
分析下这个执行计划,type=ALL全表扫,而且产生了filesort。
where条件加个复合索引看看:
create index idx_atc_ccv on article(category_id,comments,views);复制
再看执行计划:

虽然走了索引,但也走到了filesort,还是不够好;这个索引不起作用吗?
在Mysql中,索引中出现了范围查找,后面就失效,comments出现了范围,索引在找的时候,发现comments无法直接定位到,影响了order by views的索引排序,进而出现了filesort。
那假设我们把sql调整为comments = 1再看看执行计划。

filesort没有了,type一下从range变成了ref,执行计划是好的,但是业务变了,不行!
那么怎么创建索引合适呢?既然范围之后索引失效,那么我们能不能绕过去?直接新建category_id, views的复合索引呢。(删除之前创建的索引)
执行计划告诉我们,这个索引加的很合适!

结论:type变成了range,这是可以忍受的,但是Extra里出现了filesort是无法接受的,但是我们建立了索引为什么没有用,这是因为按照Mysql的BTREE工作原理,先排序category_id,如果遇到相同的,再排序comments,如果遇到相同的,再排序views,当comments位置处于联合(复合)索引的中间位置时,Mysql无法对范围(range)后面的字段进行索引排序,从而后面的字段索引失效!
3、两表优化案例
来看个SQL:
select * from class left join book on class.card = book.card;复制
执行计划:

明显这个type为ALL,索引也没有加。问题来了,索引加哪边?是加class.card还是book.card?
我们都试试,先添加右边book表的索引:
alter table book add index idx_b_card(card);复制
执行计划走下:book的很明显的改变,type变成了ref

此时我把book表的索引删掉,而建立class左表的索引看看执行计划:

明显,加了class表的索引后,发现type是index,并且rows20行记录,全索引扫描,性能不会有刚刚的好!
同样的sql,同样的索引列,左连接的时候,加的索引所在的表不同,效果不同;
结论:上面出现效果不同,这个是由左连接的特性决定的,left join 条件用于确定如何从右边搜索行,而左边一定是都有的;左边全有,确定核心的点在于确定如何从右表中搜索数据行,右边是关键点,要加索引!所以左连接索引加在右表上,同理,右连接也是相反加!
有没有人好奇,如果两个索引都建呢会是什么样?我们尝试下加上看看:

现在book和class表上的card字段都加了索引,效果比上面两个都好!
4、三表优化案例
先把之前创建的索引都清除掉。
SQL如下:
select * from classleft join book on class.card = book.cardleft join phone on book.card = phone.card;复制
执行计划:

此时三个表都没有索引:我们走下执行计划后发现,Extra字段多了Using join buffer;首先join buffer意思是使用了连接缓存。
在5.7之后,Mysql对表和表之间的连接,做了优化缓存,实际上在A left join B的过程,Mysql会更在意B的表往A中相同的部分,所以类似一个for循环,最外层for A,内层是for B,找到B中的每一行满足A行的记录,因为是要A的全部,所以最外层一定是A,然后合并行,最后输出;而在3表中,等于3个for循环。
其中其实发现有个Block Nested-Loop Join——BNL算法,这个算法将外层循环的行/结果集存入join buffer, 内层循环的每一行与整个buffer中的记录做比较,从而减少内层循环的次数。所以最外层的表是class,先for整个class,然后放在join buffer里,接下来循环内表的时候,直接取buffer的行去比对,减少对磁盘的IO。
但是整个type=ALL,rows都是20,全表扫,这是我们无法接受的。
那么三张表怎么加索引呢?可以想想,左连接建右表上,那么这个是不是说class左表,建立索引在book和phone上?试试!
走下执行计划看看:很明显,改善很多!

那么很明显这个原则也成立,总结下:
尽可能减少join语句中的NestedLoop循环总次数,永远用小结果集驱动大的结果集,这里的例子,就是左表尽量数据小于右表,外层for的次数就减少了,IO次数也会降低。
其实你可以试试,如果class表加了索引,效果会比右连接稍微好点,哈哈

5、索引失效案例
5.1建个复合索引
create index idx_s_nap on staffs(name,age,pos);复制
SQL如下:
select * from staffs where name='July';复制

select * from staffs where name='July' and age = 25;复制

select pos from staffs where name='July' and age = 25;复制

select * from staffs where age = 23 and pos = 'dev';复制

select * from staffs where name = 'zhangsan';复制

select * from staffs where name = 'zhangsan' and pos = 'dev';复制

select * from staffs where left(name, 4) = 'July';复制

select * from staffs where name = 'July' and age > 14 and pos = 'manager';复制

select * from staffs where name != 'July';复制

select * from staffs where name <> 'July';复制

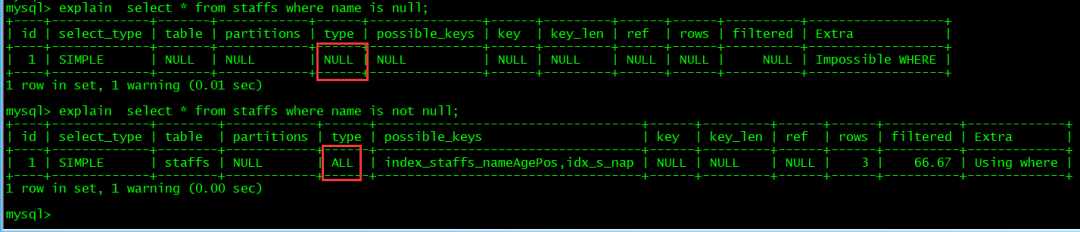
select * from staffs where name is null;select * from staffs where name is not null;复制
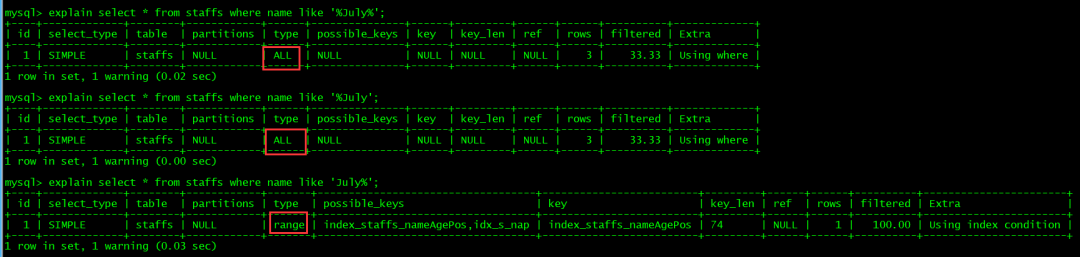
select * from staffs where name like '%July%';select * from staffs where name like '%July';select * from staffs where name like 'July%';复制
explain select * from staffs where name = 222;复制

select * from staffs where name = '222';复制

select * from staffs where name = 'July' or name = 'z3';复制


觉得本文有用,请转发、点赞或点击“在看” 聚焦技术与人文,分享干货,共同成长 更多内容请关注“数据与人”

