




本篇我们来学习Stream也就是流,在学习流之前,我希望你对Lambda表达式有一定的了解了,如果不懂什么是Lambda表达式,可以参看我之前写过的
前言
将SQL带入Java
简单的Stream示例
GROUP BY 和 JOIN
并行流与流的创建简介
参考资料
前言
我实习的公司的主力开发语言是C#, 我看别人的代码的时候有一种可以在C#中写SQL的感觉一样, 像下面这样:
from r in listStudents where r.score < 60 orderby r.score descending select r;
listStudents.Where(r => r.score < 60).OrderByDescending(r => r.score).Select(r => r) ;
// 这两个等价对应的语义为从50个学生中选择出不及格的人员名单并按分数降序排列复制
我实习的时候还不懂Java 中的Stream流和Lambda表达式,但是我的想法是Java能否将SQL的特性引入进来呢, 像写SQL一样写代码, 对此JDK的开发人员是认可的, 这也就引出了Stream流,借助于流我们就可以在Java中实现SQL的特性,可以让我们统计和过滤数据更加的简单。上面的C#平移到Java中对应的写法是:
studentList = studentList.stream().filter(o->o.getScore() < 60).sorted((o1, o2) -> o2.getScore() - o1.getScore()).collect(Collectors.toList());复制
将SQL带入Java
SQL中常用的关键词如下:
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >复制
Stream接口中的函数与之对应的关系如下:
| 关键字 | 函数 |
|---|---|
| WHERE | filter |
| ORDER BY | sort |
| LIMIT | limit |
| GROUP BY | collect(该函数承接聚合和分组统计) |
| HAVING | collect(该函数承接聚合和分组统计) |
| DISTINCT | distinct |
| SELECT | map |
| ANY | anyMatch |
| ALL | allMatch |
在SQL中最终的结果集是一张表格,也就是一张虚拟的表,在Java中最后形成的结果就是Map、List、Set。如此SQL强大特性便被平移进入了Java中, 这也是我们常说的函数式编程。像学习SQL一样我们依然先学习简单的单表查询过滤、分页、排序, 再是分组与聚合函数、连接操作。
在故事的开始我们先准备一个Person类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student {
private String name; // 学生姓名
private Integer score; // 成绩
}复制
然后准备一个集合, 将数据添加进入集合中:
List<Student> studentList = new ArrayList<>();
Student student = new Student("zs",70);
studentList.add(student);
student = new Student("lisi",75);
studentList.add(student);
student = new Student("wangwu",85);
studentList.add(student);
student = new Student("wangww",90);
student = new Student("wangwww",98);
studentList.add(student);复制
简单的Stream示例
查出超过80分的学生姓名, 按正序排
List<String> resdult = studentList.stream().filter(o -> 80 < o.getScore()).sorted((o1, o2) -> o2.getScore() - o1.getScore()).limit(3).map(o -> o.getName()).collect(Collectors.toList());复制
取出本次考试的前三名
studentList = studentList.stream().filter(o->80 < o.getScore() ).limit(3).collect(Collectors.toList());复制
distinct()
这个的去重稍微特殊点, 默认是调用hashcode和equals方法来判断元素是否重复的。这也就要求我们去重的时候重写类的equals方法进行去重。这个在日常开发中我个人不是很喜欢用这个distinct()方法,对于一些基本包装类型重写好了。但是我们可以用另一种曲线救国的方式来实现按对象的某一个字段进行去重,借助filter函数, 在过滤的时候进行判断。仔细想想,其实distinct是另一种形式的过滤。
首先为filter准备一个方法:
static <T> Predicate<T> distinctByObjectField(Function<? super T, ? > function){
Map<Object,Boolean> map = new HashMap<>();
return t -> map.putIfAbsent(function.apply(t),Boolean.TRUE) == null;
}
// 大致解释一下这个方法,这个方法还是对Java基础有一定的要求的. 首先方法的参数是一个方法,返回的也是一个方法
// Function 是一个函数式接口,其中的函数式方法如下:
R apply(T t);
// 那么对传递进来的函数的要求就是源头是T,返回的则是任意类型的参数不进行限制。
// putIfAbsent() 如果存在返回对应的value,如果不存在则返回为null.
// 写到这里在想为什么,JDK的设计者为什么不将distinct包装成这种形式。复制
调用示例:
studentList.stream().filter(distinctByObjectField(e -> e.getScore())).collect(Collectors.toList());复制
max、min、count
// 求最高分
studentList.stream().max((o1, o2) -> o1.getScore() - o2.getScore());
// 另一种等价写法
studentList.stream().max(Comparator.comparingInt(Student::getScore));
// Comparator.comparingInt 包装了一层
// 求最低分
studentList.stream().min((o1, o2) -> o1.getScore() - o2.getScore());
studentList.stream().min(Comparator.comparingInt(Student::getScore));
// 求流中元素的数量
studentList.stream().filter(o -> o.getScore() >= 80).count();复制
reduce 合并
写到这里突然想要MapReduce这个大数据框架。也是分解合并。也可以理解为迭代运算器, 结果重新作为一个参数,不断地参与到运算之中,直到最后结束。
studentList.stream().map(Student::getScore).reduce(0, (o1,o2)-> o1 + o2); // 求全班同学的总和
studentList.stream().map(Student::getScore).reduce(0,Integer::sum);复制
map与flatMap
为了介绍flatMap,这里我们再引入一个班级类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Grade {
private List<Student> studentList;
private String className; // 班级名称
}复制
那我们该如何提取这个所有班级的学生成绩呢,像下面这样吗?
List<List<Student>> resultList = grades.stream().map(o -> o.getStudentList()).collect(Collectors.toList());复制
我们其实可以将这个grades中的每个元素也都转成流来计算,这也就是flatMap();
grades.stream().flatMap(o -> o.getStudentList().stream().map(e -> e.getScore())).collect(Collectors.toList());复制
contact 方法
将两个流进行合并。
GROUP BY 和 JOIN
collect 意味收集
经过流的操作最终形成到一个集合中, 上面我们已经有意无意的用到了这个函数。
JDK为我们写好的在Collectors接口中:
toList() // 转的是List toSet() // 最终是HashSet toMap() / 最终是HashMap
分组
按班级进行分组
Map<String, List<Grade>> mapList = gradeList.stream().collect(Collectors.groupingBy(Grade::getClassName));复制翻阅源码发现这个最后形成的Map是HashMap,HashMap是允许key为空的,
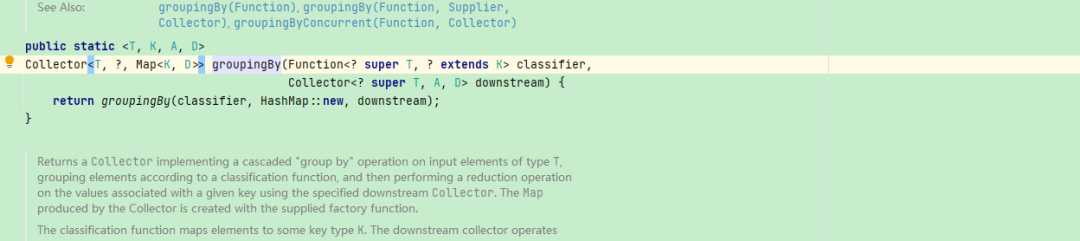
但是奇怪在形成Map的时候, 做了校验发现key为空直接抛出错误:
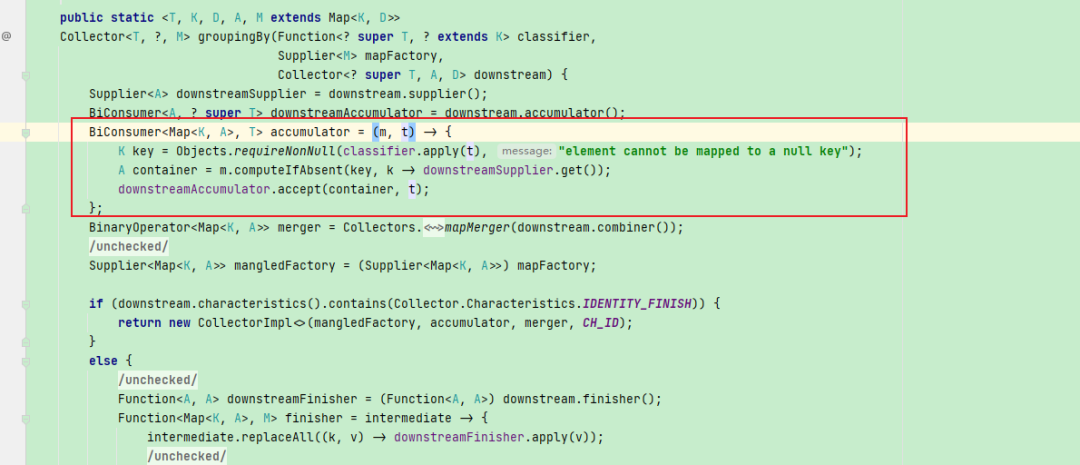
解决这个问题我们可以在分组之前将key为null的改为空字符串,或者过滤掉。亦或者是用另一种形式的分组, 不采用Collectors内置的groupingBy, 我们仔细思考下分组操作,转换成map也就是对应的key在进入到map的时候先判断这个key在map中是否存在,如果存在则将其并入到对应的value中。这也就是Map接口中的merge操作. 我们来大致看一下流是怎么转化为Map的:
keyMapper 和 valueMapper 用来产生key和value, 那这个mergeFunction呢?
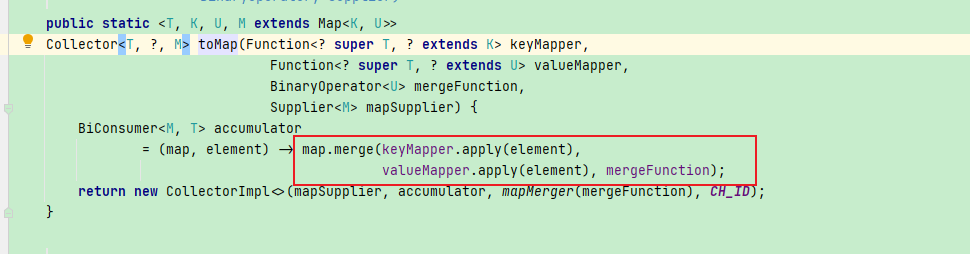
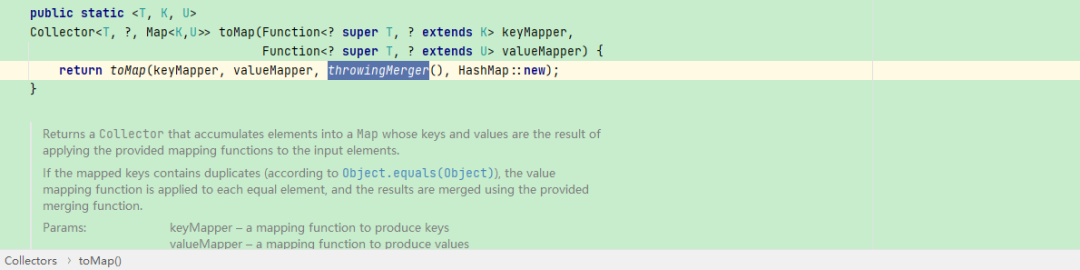
我们看下throwingMerge的实现:
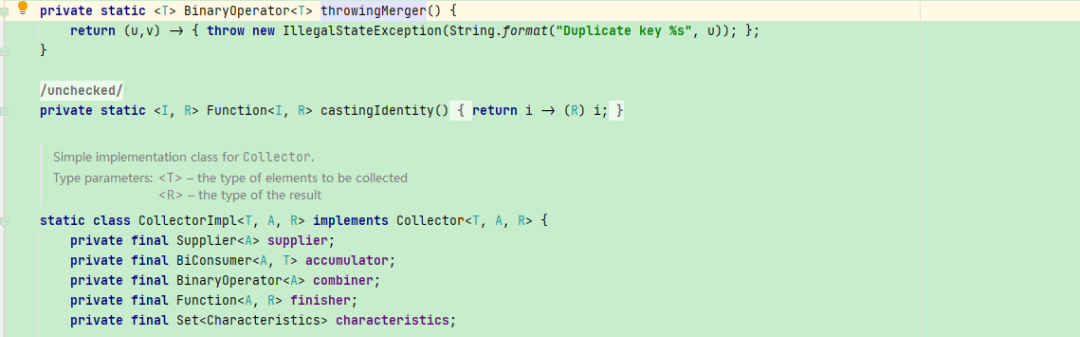
发现这个函数也的行为也就是抛出了不允许为重复的key的异常,我们上面看到的传递进来的是HashMap, 那么调用其实是HashMap的merge方法,我们看下HashMap的merge的方法:
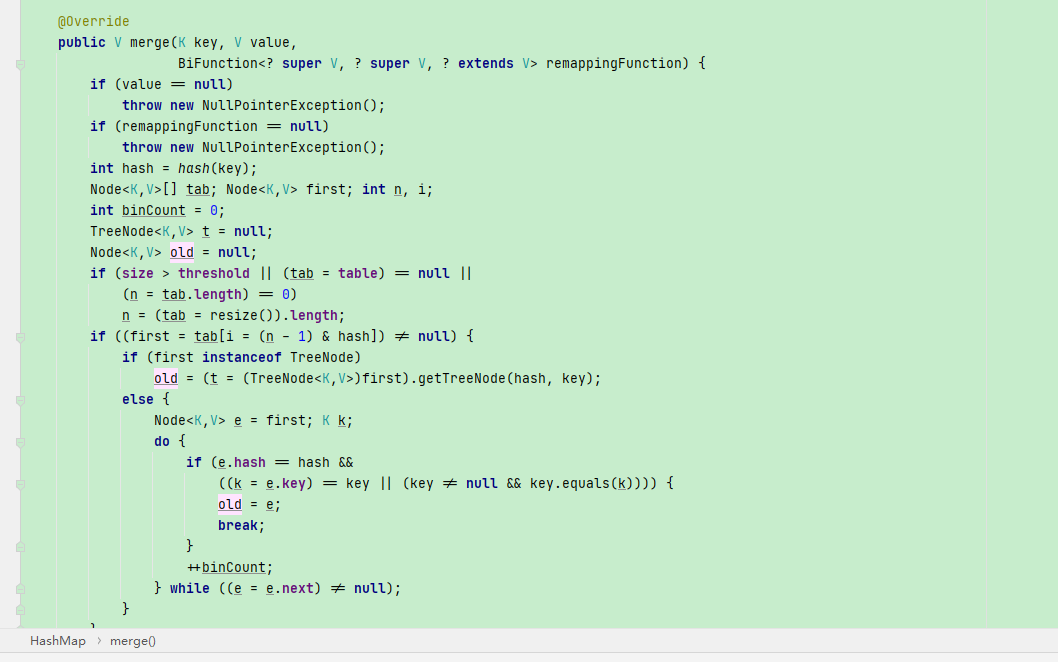
注意到这上面有@Overide注解, 而且方法参数中有一个参数是函数,所以我们可以断定这个merge方法是1.8才有,JDK1.8才引入了方法引用我们略掉上面这些放节点和转化为树结点的代码,这不是我们研究的重点,我们重点研究传入的merge函数在哪个地方被使用。粗略的说上面的一串操作也就是从HashMap中根据key获取对应结点。HashMap内部维护了一个静态内部类:
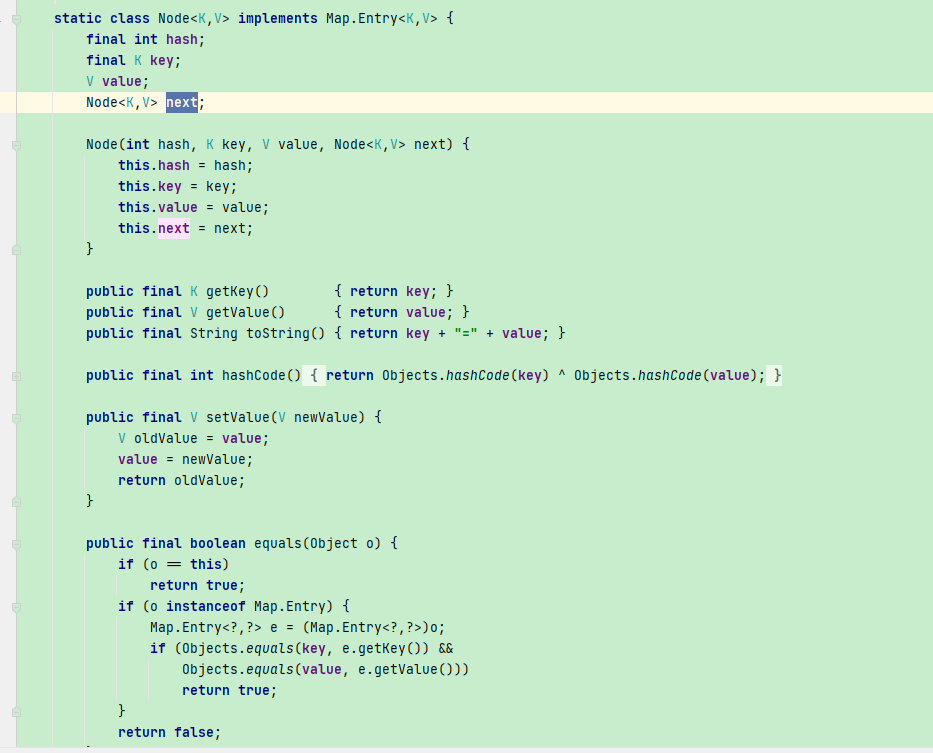
下面是执行 merge函数的地方:
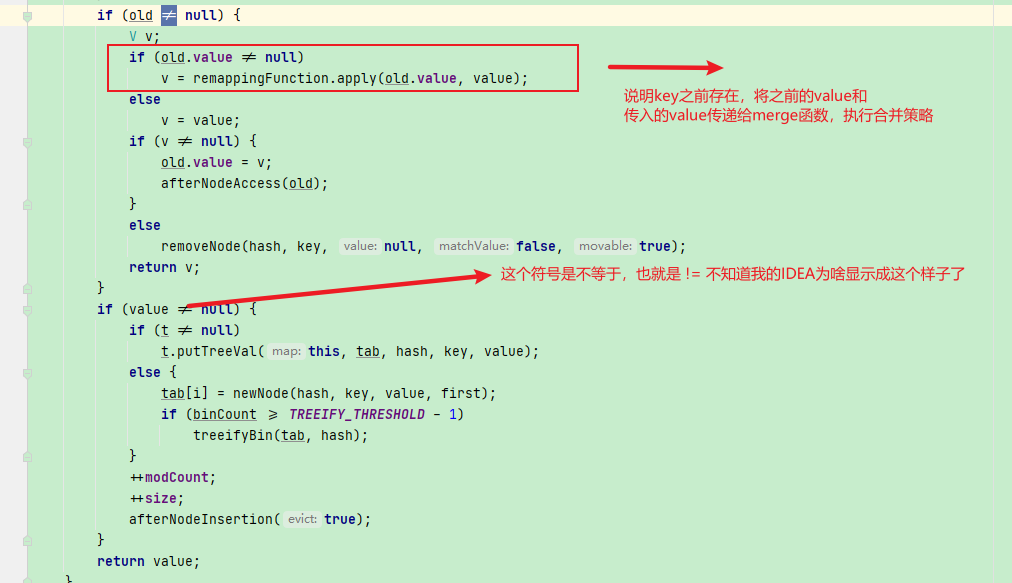
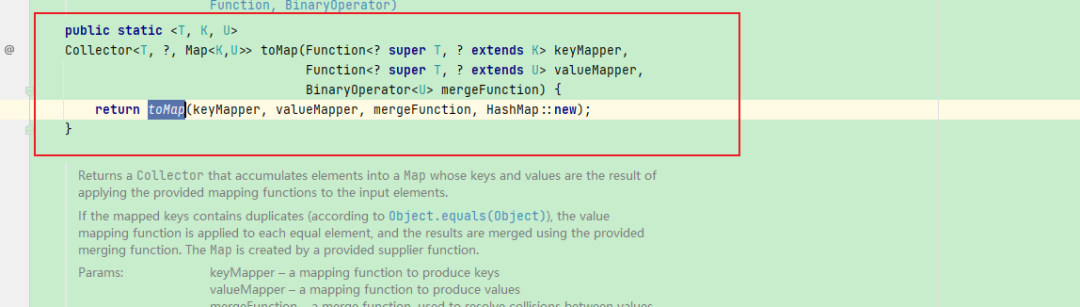
那根据上面传入的经验,调用Stream转Map的时候,如果有重复的key,那么这个流就被打断了,直接抛出异常。所以我们可以模仿着写产生Map的策略,弃用JDK内置的合并策略。也就是这个方法::
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
// keyMapper 和 valueMapper 都是函数式接口,这也就要求我们传递的是一个函数.
// 我们只是对key进行处理,所以我们的Collectors.toMap可以写成下面这样.
studentList.stream().collect(Collectors.toMap(Student::getScore, o -> Collections.singletonList(o),(o1,o2)->{
List<Student> stringList = new ArrayList<>();
stringList.addAll(o1);
stringList.addAll(o2);
return stringList;
}));
// 其实这里还可以进行化简,只是下面这样有点难以理解
studentList.stream().collect(Collectors.toMap(Student::getScore, Collections.singletonList,(o1,o2)->{
List<Student> stringList = new ArrayList<>();
stringList.addAll(o1);
stringList.addAll(o2);
return stringList;
}));
// 还可以将上面的函数抽象出来,我们仿照着这个静态函数写即可
// public static <T, K, U>
// Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
// Function<? super T, ? extends U> valueMapper,
// BinaryOperator<U> mergeFunction) {
// return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
/**
*
* 泛型A是返回类型,
* 传入的泛型是T,最终分组的类型也是T
* @param classifier
* @param <T>
* @param <A>
* @return
*/
public static <T, A> Collector<T, ?, Map<A, List<T>>> groupByWithNullKeys(Function<T, A> classifier) {
return Collectors.toMap(
classifier,
Collections::singletonList,
(List<T> oldList, List<T> newEl) -> {
List<T> newList = new ArrayList<>();
newList.addAll(oldList);
newList.addAll(newEl);
return newList;
}
);
}复制Map<Boolean, List<Student>> result = studentList.stream().collect(Collectors.partitioningBy(o -> "男".equals(o.getSex())));复制partitioningBy
groupBy是多组的话, 那么 partitioningBy 只会宏观的分为两组,
group by join 并不是SQL中的join 但是可以实现另类的拼接,将集合转为对应的字符串,很像是Guava中扩展了的Joiner
List<String> stringList = studentList.stream().map(o -> o.getName()).collect(Collectors.toList());
System.out.println(stringList.stream().collect(Collectors.joining(",")));复制List<String> stringList = studentList.stream().map(o -> o.getName()).collect(Collectors.toList());
System.out.println(stringList.stream().collect(Collectors.joining(",","[","]")));
// 最终拼接的样子为
[zs,lisi,wangwu,wangww,wangwww,wangww]复制示例1 list 转逗号分割 聚合函数
示例:
Double avgList = studentList.stream().collect(Collectors.averagingDouble(Student::getScore));
System.out.println("平均分:"+avgList);
Integer total = studentList.stream().collect(Collectors.summingInt(Student::getScore));
System.out.println("总分:"+total);
Optional<Student> maxScore = studentList.stream().collect(Collectors.maxBy((o1, o2) -> o1.getScore() - o2.getScore()));
System.out.println("最高分的学生"+maxScore.get().getScore());
DoubleSummaryStatistics result = studentList.stream().collect(Collectors.summarizingDouble(Student::getScore));
System.out.println("统计以上所有的信息:"+result);复制输出结果:
平均分:86.0 总分:516 最高分的学生98 统计以上所有的信息:DoubleSummaryStatistics{count=6, sum=516.000000, min=70.000000, average=86.000000, max=98.000000}
均值组: averagingDouble averagingInt averagingLong 最值组: maxBy minBy 求和组: summingInt summingDouble summingLong 统计均值,最值、求和: summarizingDouble summarizingInt summarizingLong
并行流与流的创建简介
Java中对应的代码一定有确定的线程在执行, 我们上面的流大多都是单线程的, 如果我们希望多线程加速呢,其实也比较简单,在Collection接口中给了流的默认实现, 有两种:
parallelStream
多线程形式来操作流中的元素,要注意线程安全的问题。
stream
所有Collection的子类的对象都可以直接使用。那Map呢,Map不是Collection的子类,那如何使用呢?答案是通过entrySet使用,像下面这样:
HashMap<String,String> stringStringHashMap = new HashMap<>();
stringStringHashMap.entrySet().stream().max()复制
那如果是数组呢?
Arrays.stream()复制
除了以上方式,还有:
// 产生四个数,从0开始遍历每个元素加3
Stream<Integer> stream = Stream.iterate(0, (x) -> x + 3).limit(4);
stream.forEach(System.out::println);
// 使用Stream.of的静态方法:
of(T... values)
of(T t)
//生成10个love
Stream<String> stream3 = Stream.generate(() -> "love").limit(10);
String[] strArr3 = stream3.toArray(String[]::new);
System.out.println(Arrays.toString(strArr3));复制
参考资料
重走Java基础之Streams(三) https://zhuanlan.zhihu.com/p/24891693?refer=dreawer java函数式编程归约reduce概念原理 stream reduce方法详解 reduce三个参数的reduce方法如何使用 https://www.cnblogs.com/noteless/p/9511407.html Java Stream中map和flatMap方法 https://zhuanlan.zhihu.com/p/264811643
