





* Lucene的倒排索引可以比mysql的b-tree检索更快。
* 在Mysql中给两个字段独立建立的索引无法联合起来使用,必须对联合查询的场景建立复合索引。而lucene可以任何 AND 或者 OR 组合使用索引进行检索。
* Elasticsearch支持nested document,可以把一批数据点嵌套存储为一个document block,减少需要索引的文档数。
* Mysql如果经过索引过滤之后仍然要加载很多行的话,出于效率考虑query planner经常会选择进行全表扫描。所以Mysql的存储时间序列的最佳实践是不使用二级索引,只使用 clustered index 扫描主表。
时间序列数据库的秘密
1、什么是倒排索引?
先给一个比较通俗的定义,通过文档的内容来查找文档的方式就是倒排索引,我们正向的思维是查文档中包含哪些词,这是正向检索。
Elasticsearch是基于Lucene实现的分布式、海量数据的存储分析引擎,其中Lucene最主要的倒排索引结构,赋予了ES全文检索、模糊匹配、联合索引查询等等快速检索文档数据的能力,使得ES在这些查询的应用场景下优于数据库。
索引我们在数据库中经常提到,它将数据库中的数据进行编排管理,通过索引能够快速地定位数据、获取数据。类似于图书的目录。
Q:要介绍倒排索引,或许要先明白一个问题,什么数据存储需要用到索引?
A:查询数据的时候,最耗时的操作并不是CPU计算,也不是内存聚合,而是去磁盘将文档查到并拉取回来的过程。我们都知道在磁盘IO的过程中,顺序读写效率高于随机读写,磁盘的查找次数也决定最终的响应时间。在使用索引的过程中,我们将数据按照指定方式顺序存放好,然后利用各种数据结构(b树、b+树、倒排索引)等来减少我们查询数据的次数,提高定位和获取数据的效率,这就是索引的作用。
2、什么是倒排索引?
我们在ES进行文档存储的时候,例如我们要存储的文档是李三的个人信息:李三,男
在MySQL中我们存储的是关系型数据,通过表结构来表示数据之前的关系,对于李三这一条数据的编号是1。
| id | name | gender |
| 1 | 李三 | 男 |
而在ES中,我们会用内容映射文档的方式建立索引,这就是倒排索引;
| Term | docId |
| 李三 | 1 |
| 男 | 1 |
这样我们在查询“包含李三的文档有哪些?”,我们的Query:term=李三就可以根据索引查出docId=1,然后直接拉取该文档的内容进行输出。
这样倒排索引基本的样子,但是实际的数据并不是这么简单,例如id=1的文档中还包含李四的信息、其他的文档还包含李三的信息、并不只有“李三”、“男”两个词,还有几万几千个词项,我们当然可以像上面表格的逻辑那样进行记录,但这样的方式就会产生很大的索引维护成本,索引占据的空间就会随着文档的增加变得不可控制。那ES中的倒排索引是如何进行管理的呢?
3、什么是倒排索引?
通过上面的简单介绍我们大致了解了倒排索引模糊的样子,但--
Q:在ES中倒排索引的真面目是什么?
A:倒排索引中两个关键的信息:词项(term)和文档Id,存入ES的文档经过分词器分词后生成词项(ES内包含默认的分词器,有Ik、pinyin等等),词项映射存在的文档id。
词项(term)太多如何存储,在ES中将所有的词项通过字典顺序排列好后存储起来,这个数据结构叫词项字典(Term Directory)。实际业务中每一个词项并不只存在一个文档中,而是关联一个文档id的列表,ES中称为Posting List(关联文档ID的列表)。
当时词项可能有非常多,我们通过顺序的查找字典来确定,这样的效率也不高。所以ES将词项的前缀(Term Index)拿出,构建了一个FST(这里其实与Trie前缀树还不一样,FST除了支持前缀匹配外,还支持后缀匹配,下文会简单介绍,当前例子仍旧使用前缀树概念便于理解)的结构存储在内存中,就像是字典的目录一样。
| Term | docId |
| tim | 1,2 |
| tom | 1,4 |
| too | 3,5 |
| So | 1,2 |
则根据上述的回答描述,ES中的倒排索引结构是如下图所示的结构:
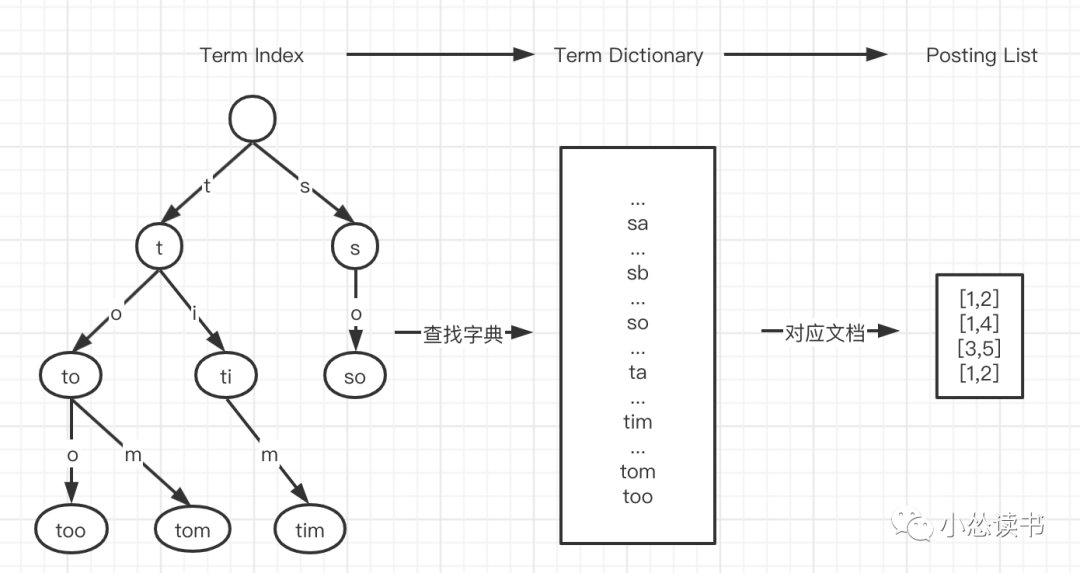
前缀匹配:如上图所示,将所有词项的相同前缀复用成树。
就像too和tom两个词,前缀to相同。
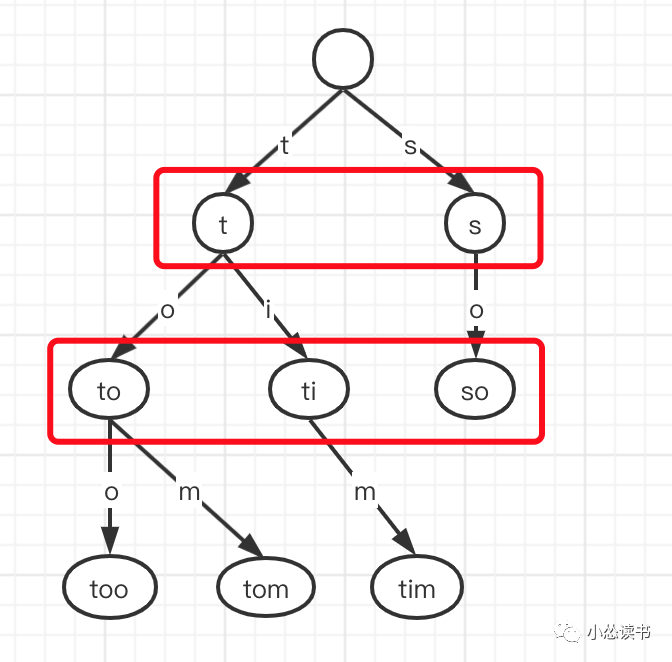
Q:为什么Elasticsearch/Lucene检索可以比mysql快?
A:mysql通过b+数结构将索引存储在磁盘上,相当于TermDictionary的作用,可以方便的根据词典查到文档的编号。但是在查索引的过程中也需要进行磁盘随机IO的操作,当然b+数的特性让磁盘IO基本在2-3次内遍历出结果。但是ES增加了Term Index的结构,将索引的前缀再抽出形成前缀树,放在内存中进行,大大减少了IO的次数。FST特点是非常节省内存。Term dictionary在磁盘上是以分区的方式保存的,一个block内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样term dictionary可以比 b-tree更节约磁盘空间。
4、FST(Finite State Transducer 有穷状态转换器)
上面介绍了很多倒排索引的组成,基本上可以理解内容,但是对于FST的概念却有点模糊,是一种前缀树?NO,FST(Finite State Transducer 有穷状态转换器),一种类似前缀树的结构。FST不仅仅是一种前缀匹配树,它的实现还包含了后缀匹配操作。
FST是也一个有限状态机(FSM),具有这样的特性:
确定:意味着指定任何一个状态,只可能最多有一个转移可以遍历到。
无环:不可能重复遍历同一个状态
transducer:接收特定的序列,终止于final状态,同时会输出一个值。
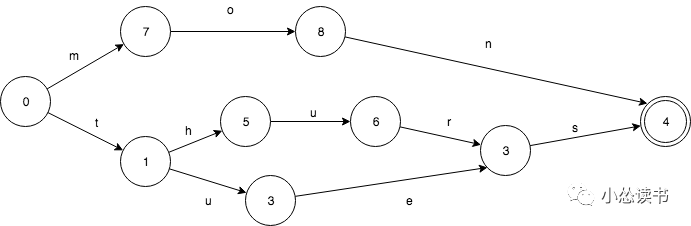
例如,假设我们有一个这样的Set: mon,tues,thurs。FSA是这样的:
相应的TRIE则是这样的,只共享了前缀。
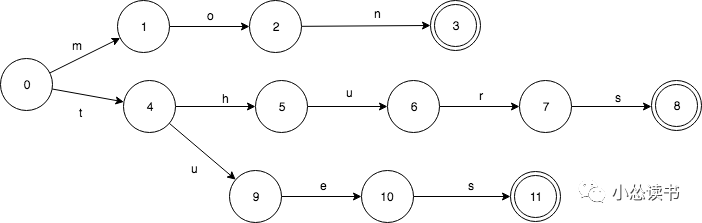
TRIE有重复的3个final状态3,8,11. 而8,11都是s转移,是可以合并的。
1)对FST构建过程的理解:
输入的词项进行拆分成多个Node,Node与Node之间通过边进行连接,边上有对应的字符和outputValue,例如上面mon:2,对应第一条边是m字符,outputValue是2。outputValue并不是固定在第一条边上,也并不是一个字符对应的值,而是所有边遍历结果之和。
输入第二个词项后,如果跟第一个词项没有共同的前缀,那么第一个词项所形成的路径被冻结,不可修改
第三个词项tues与第二个词项thur存在前缀t相同,这样需要进行以t为入度的Node节点的分裂,由于tues的词项output为3,所以分裂后thur的词项中h的边携带的value是2,最终遍历t-h-u-r = 3+2=5;t-u-e-s = 3
2)实际构建过程
mon:2,tues:3,thur:5为例构建
第一步:从第1个key, mon:2开始

第二步:下面继续把thurs:5插入
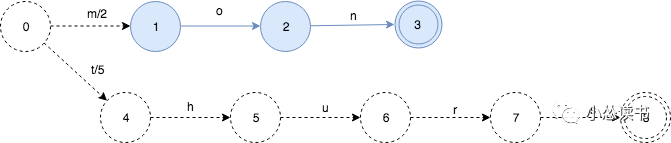
FST的mon部分(蓝色)就不会再变了(冻结)。
由于mon和thurs没有共同的前缀,只是简单的2个map中的key. 所以他们的output value可以直接放置在start状态的第1个转移上。
第三步:下面,继续插入tues:3
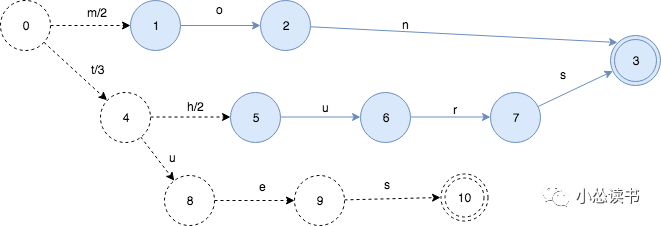
这引起了新的变化。有一部分被冻住了,并且知道以后不会再修改了。output value也出现了重新的分配。因为tues的output是3,并且tues和thurs有共同的前缀t, 所以5和3的prefix操作得出的结果就是3. 状态0->状态4的value被分配为3,状态4->状态5设置为2。
3)FST在源码的中的数据结构
current[ ]数组:构建FST后生成的信息都最终保存到字节数组current[ ]数组中,即生成FST的最终结果就是该数组。
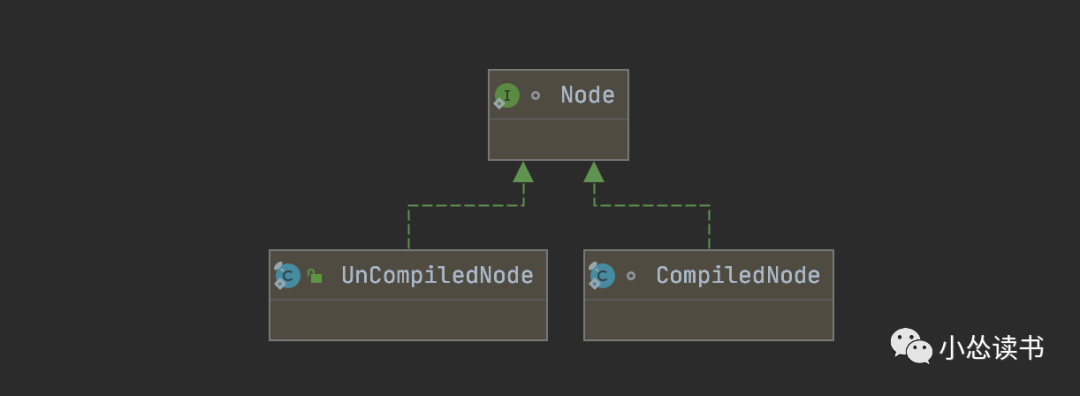
Node(节点)、Arc(弧、边):Node之间使用一个Arc连接,一个Node跟一个或多个Node连接。Node还具有两种状态:UnCompiledNode和CompiledNode。在源码中,使用两个对象来描述这两种状态,如下所示:
5、倒排索引联合查询
倒排索引的作用是根据词项快速定位到文档的idList,ES查询过程包括query和fetch两步,query是查找对应的文档,fetch是将文档的内容取回,其他额外的聚合、过滤操作则在协调节点内部进行处理。
那么查找多个词项如何操作?这涉及到索引的联合查询,在MySQL中如果使用两个索引进行查询,mysql内部会决定最优的索引选择,然后根据所选择的索引取回数据,而另一个联合的索引则会在内存中进行过滤操作。

如上图,mysql中给出了可能用到的索引idx_date、idx_org,最终选择idx_date索引
而在ES中,由于每个词项对应的是一个list,两个词项的联合最终的操作实际是两个list取交集,找出两个list公共的id即为联合查询的结果。
两个list取交集,ES中给出了两种方式:跳表和bitset
跳表方式:
Tab1:
| 1 | 3 | 5 | 6 | 7 | 8 | 9 |
Tab2:
| 2 | 4 | 5 | 7 | 9 | 11 | 12 |
有序的两个list构成两个跳表,简单的过程描述如下:
->tab1:1,tab2没有跳过;tab1:3,tab2没有跳过
->tab2:5, tab2有,id=5存入结果集
->tab2:7, tab1跳过6,找到7,id=7写入结果集
...
而对于bitset存储更简单
例如一个list为[1,3,5,6],另一个为[1,4,6,7]
那么两个list对应的bitset
[1,3,5,6] =>
| bit位 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| List1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
| List2 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
| &结果 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
两者1010110&1001011=>1000010=>id=1和id=6的文档
当然Lucene对于这两种合并方式所产生的中间跳表block和bitset结构还进行了数据的压缩,真是将空间利用最大化啊。
6、倒排索引结构中涉及的压缩
1)Frame Of Reference
例如:PostingList:[1,3,13,101,105,108,255,256,257]
我们可以把这个 list 分成三个 block:
[1,3,13] [101,105,108] [255,256,257]
然后可以构建出 skip list 的第二层:
[1,101,255]
1,101,255 分别指向自己对应的 block,1指向的block是[1,3,13]
对于这个block,Lucene通过Frame Of Reference的方式进行压缩
压缩过程:
>>> [1,3,13,101,105,108,255,256,257]
>>> 前后元素做差 [1,2,10,88,4,3,147,1,1]
>>>对应的3个block数据4:[1,2,10],7:[88,4,3],8:[147,1,1]
说明:[1,2,10] 这三个值用4个bit位就可以表示,因为2的4次方最大是16;同理[88,4,3]这个block需要7位
那这样压缩之后,一共需要3*4 = 12位=2bytes;3*7 = 21位=3bytes;3*8=24位=3bytes,一共存储8个bytes
相比之前存储9*4(int是4byte)=36bytes节省非常大的空间。
用 Frame of Reference 编码进行压缩可以极大减少磁盘占用,这个优化对于减少索引尺寸有非常重要的意义。mysql b-tree 里也有一个类似的 posting list 的东西,是未经过这样压缩的。
2)Roaring Bitmap
bitset的压缩采用的是一种叫做:Roaring Bitmap的算法,其思路是:其压缩的思路其实很简单。要保存100个0,则存储为value=0,次数=100。
例如,postingList[1000,65536,65537,131358,196658]
压缩过程:
>>> 1000,65536,65537,131358,196658(%65536)
>>>(0,1000),(1,0),(1,1),(2,313),(3,50)
>>>[1000][0,1][313][50] 通过block的下标来表示%65536的商,获取数据时,例如[50]下标3,3*65536+50=196658
针对倒排索引的结构理解上面的一些内容还是很有帮助,毕竟我们使用ES过程避不开倒排索引。
上面的内容是基于两篇文章参考,加上一点自己学习后的想法而成。参考文章如下:
01.时间序列数据库的秘密
https://www.infoq.cn/article/database-timestamp-02
02:关于Lucene的词典FST深入剖析
https://www.shenyanchao.cn/blog/2018/12/04/lucene-fst/
