




Table of Contents
前方导读
对Vertica的回忆回到2015年,那时候的我不止18岁,当时根据项目需求,我调研实践了Vertica,模糊记忆印象中当时Vertica的社区免费上限是100G,而不是现在的1000GB,当时向技术领导反映这个东西不错可以应用于大数据系统项目,项目进行中突然一天却被要求下架,原因是因为它是一个商业版的软件。商务领导发话,公司发你们IT部门高薪,就是为了解决IT问题,为什么额外花钱购买一个商业版软件,领导的思维更想你用开源的工具,然后是lambda框架也好、kappa框架也好或者unifield架构去解决大数据项目相关的问题。多年工作经历,倍觉感受做一个IT项目关键核心取决于三要素,那就是人、方法论、工具等等。一流的人才和一流的方法使用三流的工具也能三个臭皮匠顶个诸葛亮。Vertica是一款即使你只是p1的水平也能轻松实现撑起企业级数据分析解决方案的好工具,作者对Vertica的技术本质理解,结合行业相关产品的对比,对未来数据分析技术方向做了一个探索,希望我把数据分析最关键核心技术的那一点说清楚了,希望我把Vertica的最关键的空间技术点也说清楚了,也希望各位展开OLAP的话题讨论。基于本人能力水平有限,技术描绘不清或者笔力不到之上请批评指正。
开场白
一年一度的天下数据分析比武演讲大会正式开始,擂台上灯光闪烁,台下选手摩拳擦掌,活动筋胳,跃跃欲试,面向最耀眼的舞台中心。一个全身肌肉发达,胡子拉碴的大汉正在激情四射的演讲, “我是Oracle RAC,我90年代就把业务分析遍及全球,全球案例有XX个,我的客户有制造业的XX,金融业的XX,通讯行业的XXX ,我有点贵,但是我的性能很强大”。说完就要脱衣服秀他的胸肌 ,台下观众马上骚动起来,喊着要把Oracle家族驱逐。众所周知,Oracle家族的确有实力,占据了大半壁的江山,一直是所有数据产品的公认的对手,近十年云计算和新技术兴起,很多数据产品在不同业务场景都能与Oracle分庭抗礼,越来越敢和它叫板。司仪看见Oracle又惹仇恨了,赶紧出来救场。
司仪清了清嗓子,大喊"有请下一位选手,vertica",大伙齐唰唰朝着一位其貌不扬的小伙子看去。
“大家好,我是美国选手vertica,出生在美国麻萨诸塞州,突然意识到他的外国选手身份对他不利,vertica补充了一句,我的父亲是Michael Stonebraker!”
喧闹的人群立刻安静下来,Michael Stonebraker是一位获得图灵奖的计算机科学家,地位超群,他在关系数据库方面的理论造诣和数据库产品的应用贡献至今对现今市场上的产品有很深的影响,他也是以下IT公司的创始人:包括Ingres, Illustra, Cohera, StreamBase Systems以及VoltDB。
天下数据分析流派
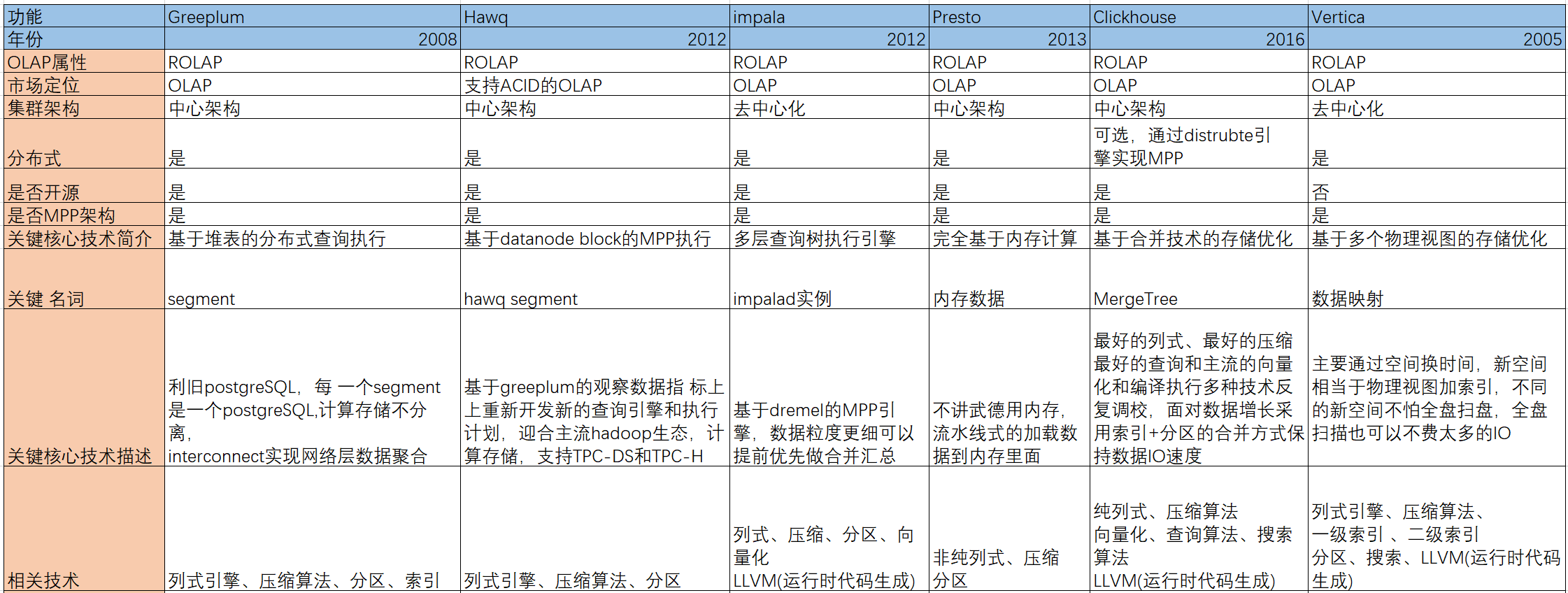
我出生在2005,至今16岁了,我致力于解决当前数据分析平台日益增长的“大数据”和实时分析要求所带来的挑战,可以以传统解决方案30%的成本,实现50倍-1000倍的性能提高。今天我的演讲是天下数据分析流派调研,给各位数据分析产品定义一个标签,穿插介绍我能干什么,给谁做了什么。我看天下数据分析势力可以分为三个流派,传统的数据集中式流派, 分布式计算流派、 新兴技术的预处理流派,按照性质划分我属于分布式计算流派。
数据集中式流派的功夫以软硬件一体结合为主,代表 作oracle exadata、sap hana,它们重视硬件建设,通过优化硬盘、内存、网络达到更高的数据处理性能,但是成本太高,普通的中小企业用户根本根本承受不起,数据集中式流派正在走下陂路,2019年sap hana大裁员就是一个预兆。说完,vertica指着oracle rac说,它也是数据集中式门派中的一员。
oracle rac红着脸坐立不安,观众响起热烈的掌声。vertica润了润喉咙,我介绍下预处理流派,中国的kylin和美国的druid都属于这个派别。预处理门派的运功法门是把大数据变成小数据,首先确定数据的维度边界,再通过集群强大计算能力综合处理后放在另外一个高性能数据库上。druid和kylin区别在于druid使用批理引擎处理历史全量数据,同时也通过实时引擎处理实时增量数据,而kylin没有对实时增量数据做处理,如果业务涉及的维度有变化,它重新预计算一遍。两者很好,都能以廉价的方式,在不增长硬件的成本给予业务支持。但是预处理是一个蓄力的方式,需要了解业务维度,只能支持固定的分析业务场景,无法满足自定义分析的需求 , 业务瞬息万变,数据实时更新,预处理跟不上数据的变化。
下面我介绍我所属的分布式计算流派,分布式计算流派也有分支,分为非MPP家族 和MPP族,我就是属于MPP家庭,非MPP成员有hadoop、mapredcue、spark等等。而我们MPP家庭 有greeplum、hawq、impala、presto、clickhouse等。我们与hadoop既对立又合作,更多时候我们MPP是弥补他们不足,我们分布式计算门派是解决单点性能不足的问题 ,通过把任务分解成多个子任务分配给分布式廉价多个机器,达到性能提升的目标。与hadoop不同的我们是并行计算,他们是两阶段计算,两阶段计算把全部业务逻辑 分成两部分处理,上部分业务抽像成为map进行处理,下部分业务进行reduce处理。如果数据质量不好或者系统参数欠优甚至算子上的程序容易发生数据倾斜,造成计算时大量的数据集中指定的机器上。
人群中一阵骚动,那些使用hadoop遭遇数据倾斜的人都交 头 接耳讨论,的确MPP引擎很少发生shuffle情况。"那么MPP是怎么做到避免shuffle呢? 当然分布式系统最终肯定是会发生数据传输,我们是把全部业务逻辑 都在每一个计算节点执行,执行结果提交服务节点进行归并。相对于两阶段而言,我们是全部业务放在MAP端进行处理,最后提交到指定的唯一的REDUCE端,这样我们避免了大数据倾斜的数据热点计算。 "
Greenplum
下面我介绍下我们的家族成员Greenplum,Greenplum是基于postgresql的基础上开发,Greenplum的组件有master、segment、interconnect。简单概括精要如下
- master是greenplum的主节点,是集群的入口,主要负责接收客户端连接请求,对SQL语句生成查询计划,计划分解成任务均匀分给每个计算节点。
- segment是greenplum的执行节点,每个segment可以视为一个独立的PostgreSQL数据库。
- interconnect是greenplum的网络节点,负责汇聚合并数据,主要解决查询执行中segment实例之间或者segment和master。
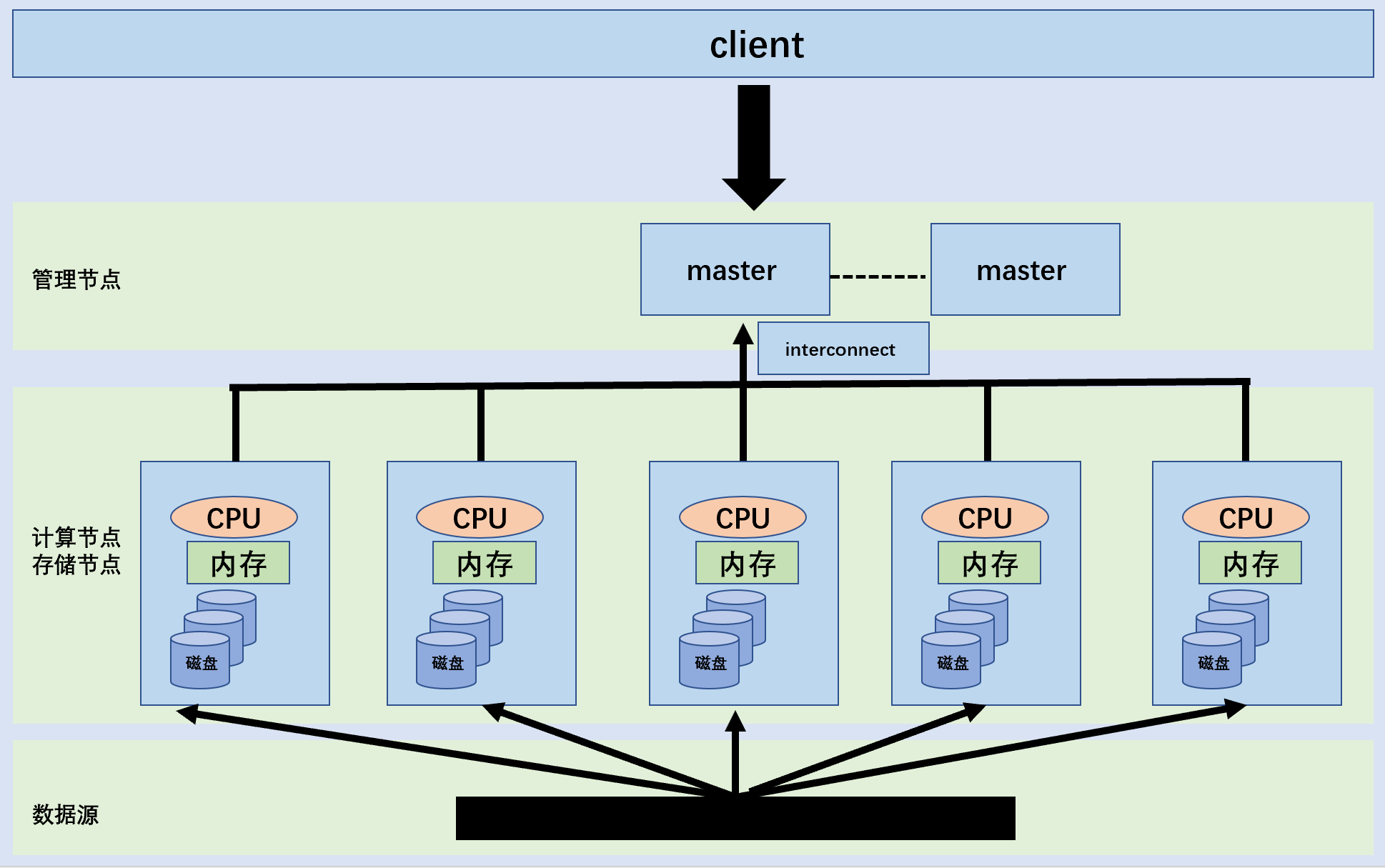
Greenplum的亮点创新,一般而言,Greenplum集群有master和segment就足够了,但是Greenplum额外开了interconnect,通过interconnect减轻了master压力,并减低内部网络转输性能开销,而且它继承postgreSQL,所以有效获得postgreSQL原始社会生态,让那些postgreSQL的开发者能够轻松使用上手。也是因为继承postgreSQL,Greenplum使用还是传统关系数据库的B树索引结构,这里汲及性能理论上限到磁盘传输速度和网络传输速度的技术问题,这导致为什么会研发HAWQ。
我们简单聊一下磁盘传输速度和网络传输速度的技术理论问题 ,每一次分布式任务运行都会产生磁盘查找和网络传输数据的动作。而postgreSQL是一个基于B树页存储的数据,基本页单元是8KB,如果任务汲及大量的数据查找,系统内部会有大量的硬盘数据查找动作。为了充分发挥硬盘的性能,我们会把存储基本单元调大一点,让它可以勉强跟上网络的速度性能,否则分布式任务都会发生更多的数据查找,影响全局性能。hdfs不擅长小数据的处理,它的基本数据单元都是64M以上,hadoop1的block设置默认是64MB,后来hadoop2的block设置默认是128MB,目标是磁盘运转速度跟上网络传输速度。
Hawq
技术上来说,hawq大的改变,它替换了segment轮子,换上了hadoop牌,融进当前大数据主流的hadoop生态,hawq还做很有意思的改变,它支持ACID特性,为了做到这一点。它使用了orc存储引擎,orc并非是一个纯粹的列式压引擎,它先按行组划分,再按列组划分。对于数据分析引擎来说,这个性能不会最好。
Impala
另外一个同样基于hadoop的mpp成员impala,提到impala的核心处理技术,不得不说google dremel,google dremel是谷歌的实时处理系统,dremel深刻理解了MPP的精髓,它的查询树是金字塔状的多层次查询结构,由根节点、多个中间节点和多个叶子节点组成。叶子节点执行有部分结果直接向中间节点输出,中间节点向顶部根节点汇报,顶部根节点最后统一输出,最大化发挥数据贴近计算的特性。impala是基于dremel论文实现的MPP查询引擎,底层默认用的是parquet,parquet是真正的列式引擎,更适合数据分析的业务场景。
presto
presto也是很出名的基于hadoop的MPP执行引擎,它是完全基于内存计算,在处理数据上有一个质的提升。相对于处理引擎的独特之处,presto不是充分利用了内存,是完全使用了数据,通过接入数据源把数据全量加载到内存上,再对内存里的数据进行分析计算。缺点是多个节点的内存总量决定处理的数据大小,如果数据比内存大,presto容易挂掉,虽然presto一直在内存硬盘交换寻找方法,但是多年来没有重大突破,截至2021年12月17日,presto最新版本是0.266.1,还没有到标准的1.0版本。即使如此,presto仍然表现出强大的表现力,华为openleekeng就是基于presto基础上研发的。
clickhouse
clickhouse是一款非常出色的MPP处理引擎,特立独行,不走主流路线,它一开始就不打算融入hadoop,从索引到分区,从存储引制到算法调度它是从零开始自我探索建设。它的杰作就是MergeTree,MergeTree是一个强大单机存储引擎表,基于它的基础上派生了ReplaceingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、GraphiteMergeTree六个引擎表,六个引擎表与MergeTree的关系,就像数据间中间件与数据库的关系,中间件赋予数据去重、数据排序、数据聚合等特性。MergeTree的MPP特性本质就是多个MergeTree通过中间件分发路由组成的。MergeTree的性能很强,列式存储、数据压缩、向量化执行引擎是标配,存储机制采用时间范围分段的合并方式,能够达到很高的压缩比。clickhouse擅长个性化的大宽表数据集市业务场景。但是关联多表业务场景性能不佳,甚至功能都达不到要求,经典的tpc-h基准测试和新型tpc-ds基准测试,clickhouse都没法通过。
关于我
下面是自我介绍,我是一个基于列式存储、实现MPP、去中心化、分布式、可扩展、高可用、多映射数据分布的数据库。针对各种数据分析业务场景问题,我的绝招是数据映射,牺性空间换取时间的方式实现数据处理性能提升。
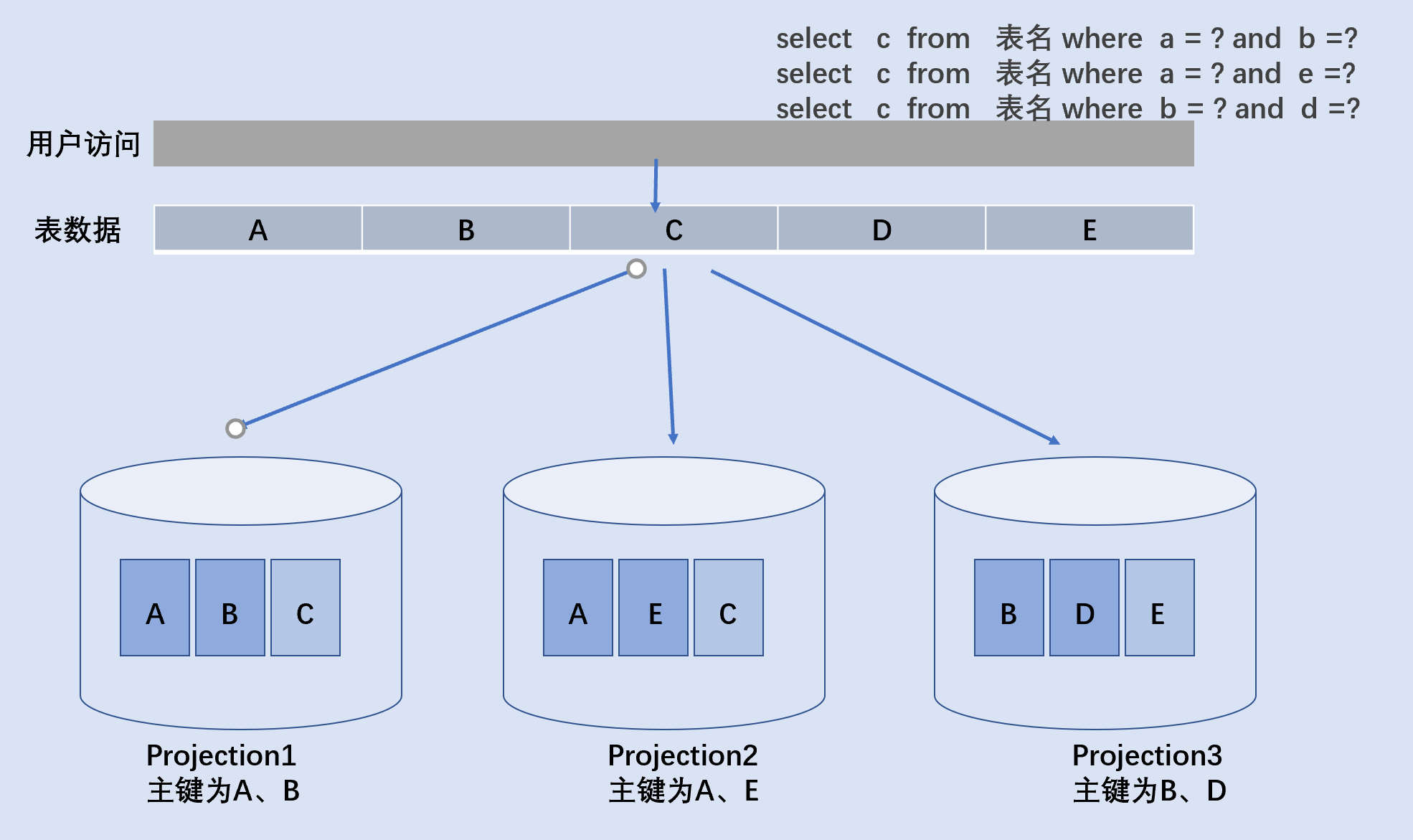
举例一个表数据里面有A、B、C、D、E一共5个列字段,该表会针对不同的列名会冗余存储多个物理视图,每一个物理视图是一个数据映射,vertica称之为projection。
数据映射里面,针对业务规则对相关字段打索引和构建分区,如图表所示,表数据有三个数据映射,一个数据映射以A、B做主键索引,一个数据映射以A、E做主键索引,一个数据映射以B、D做主键索引。vertica维护不同排序有重叠的映射,尽量使得每个查询只来自于一个映射,为提高查询性能,表查询需要的列至少在一个映射中。
用户发起三个SQL请求,每个请求挟带不同的过滤条件,因为数据映射,Vertica将自动选择用于该查询的,都能击中数据库索引,不会造成回表追溯查找或者全盘扫描。
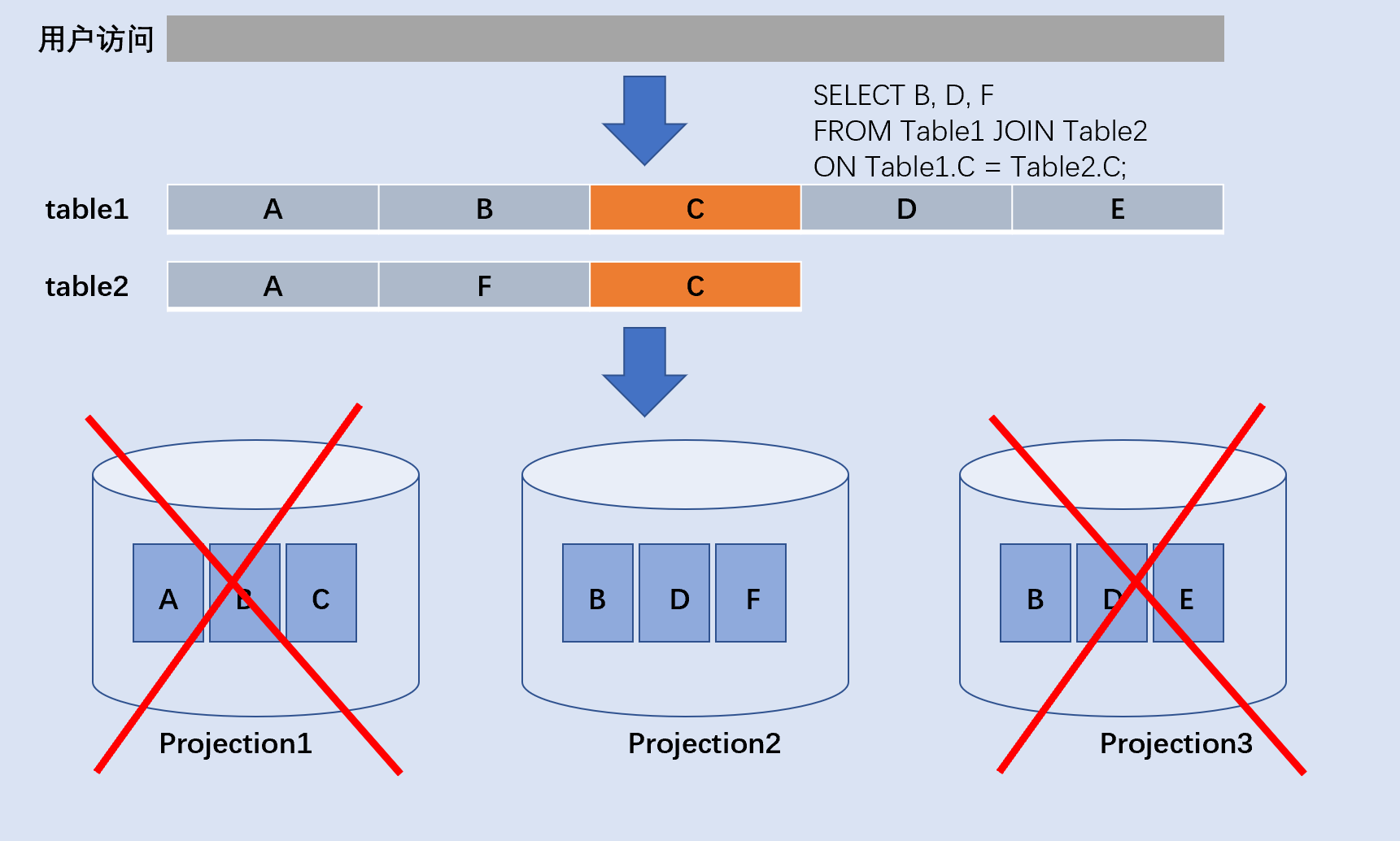
举例一个两表关联查询的例子,table1表有5个字段,table2有3个字段 ,两表关联过滤查询返回结果果。一般的数据库根据过滤条件遍列所有的列,包括A列、B列、D列、E列、F列,选择B列、D列、F列返回。而Vertical是访问指定的数据映射Project2,Project2只包括B列、D列、F列,耗时IO远比全盘扫描快。
而创建Projection2的步骤很简单,如下
( B ENCODING RLE, D, F // Column List and Encodings ) AS SELECT t1.B, t1.D, t2.F FROM table1 t1 INNER JOIN table2 t2 on t1.C = t2.C ORDER BY t1.C复制
综合比较
MPP流派的运功法门关键要点第一如何让数据贴近计算,第二如何实现数据分布。数据贴近计算是MPP任务运行过程如何把存储数据装入进行计算,而数据分布则是数据的物理存储方式,是选择离散的哈希分布还是集中的范围分布的方式,是纯列式还是半列式。
以MPP运气为内功根基,我们各有各的招式,Impala和我的集群架构都是去中心化,每一个节点都是平等的,当外面发出请求,会有一个节点上升成为协调主节点,根据你的准备好的资源,如果该节点宕掉,根据内部算法选举出新的协调节点,此举相对中心架构的master/slave模式无疑充分利用了集群性能。Impala背靠hadoop大树好乘凉,我们开发了有属于自己的独立的存储引擎机制。而presto采用全量数据加入内存,即使表数据没有实现索引分区,它依然运行很快,但是大于内存的数据量业务场景,它束手无策,实验室测试环境同样的硬件配置表明,当数据量大于内存总和的条件下,spark能比presto处理更多的数据。clickhouse追求技术极致,基于硬盘的DBMS在空间、压缩、CPU指令、合并都用上最优的算法,但是它的权衡却忽略了用户关联多表的基本需求,笛卡尔乘积是数据库连接操作最普通的存在。Greeplum和Hawq同属一家公司,它们的市场定位方向开始向OLTP发展,在OLAP领域方面,他们存在共同的痛点,随着数据量不断滚大,数据处理能力下降,需要水平扩展机器提高处理性能,预处理派流派的druid的研发公司Metamarket,就是因为greeplum无法满足业务需求而研发了druid。
我们Vertica的架构设计权衡多个因素,考虑了硬盘、内存、空间、压缩、读写优化、算法、数据库的基本关系代数操作、集合操作、连接操作等等,没有为某个特定的业务场景放弃一些东西。我们最愿意牺牲的是空间,数据映射的本质是通过牺牲空间换取额外的物理视图和索引的技术方式。
助力denodo数据虚拟化建设
客户背景
Denodo创立于1999年,2002年推出Denodo 平台第 1 版,2016年Denodo 发布 Denodo Platform 6.0,推出云中数据虚拟化和动态查询优化。同年,Denodo 获评 Gartner 数据集成魔力象限“远见者”。2017年Denodo 发布 Denodo Platform 7.0,推出大规模并行处理 (MPP) 功能,以及业界首个完全集成的数据目录。Denodo 获评 Gartner 数据集成魔力象限“挑战者”和 Forrester Wave 大数据结构“领导者”。Denodo 客户 Autodesk 因使用数据虚拟化技术改造业务模式而荣获 CIO100 奖。2019年Denodo正式进入中国,注册成立丹诺德软件(北京)有限公司。2020年Denodo 获评 Gartner 数据集成工具魔力象限和 Forrester Wave 企业数据结构“领导者”,Denodo 宣布 Denodo Platform 8.0,加速混合/多云集成,使用 AI/ML 自动管理数据并提高性能。凭借20余年的创新历程及行业领先的数据虚拟化解决方案,公司致力于在金融、制造、汽车、医疗等领域,通过实时统一数据资产、转变国内企业的创新和业务运营方式,为最广大范围的企业、云端、大数据和非结构化数据来源,提供灵活、高性能的数据集成、数据抽象化和实时数据服务。
客户愿景
Denodo广泛应用于数据管理、主数据建设、大数据分析平台、商业智能,帮助其解决供应商管理、监管合规性、数据即服务、系统现代化等多个复杂应用场景痛点,以传统解决方案一半的成本,提升企业业务灵活性和投资回报率。
Denodo的愿景是,成为行业领先的数据虚拟化和逻辑数据结构供应商,通过创建逻辑数据层,帮助企业集中管理分散的数据,提升敏捷性,降低系统维护的复杂程度。借助此方法,用户可以从高性能的单一访问点获取任何信息,并使其灵活地选择自己喜欢的应用程序来使用信息。同时,数据虚拟化还消除了移动或复制数据的必要性,在带来技术优势的同时,还能节省 50% 至 60% 的数据集成成本。
Denodo与Vertica的关系
见官方公开声明,官方强烈建议使用vertica做为Denodo的缓存管理使用工具。
In the current Denodo architecture, Denodo server does push down processing to other data sources.
However, it first retrieves data from disparate sources and performs a Join and other required processing in the Denodo server without caching. This requires a lot of system resources. Since Vertica has a more powerful processing capability, you can push the Join and other processing to Vertica and observe significant performance improvements. We recommend configuring Vertica as a cache. For more information about using Vertica as the cache and the different cache modes, see Vertica Integration with Denodo: Tips and Techniques.
来自 https://www.vertica.com/blog/tips-and-techniques-for-vertica-integration-with-denodo/
Denodo运行原理及技术分析
简单概括Denodo,可以在无需共享任何数据源、数据结构、数据中心、或数据库技术的情况下,合并来自不同数据源的实时数据,并让这些数据真正能够为企业所用。没有Denodo,我们是通过sqoop或者dataX或者canal等工具对不同的数据源进行ETL,在数据仓库中进行加工、提纯、转化操作,最后放到数据集市对外开放。Denodo把这一切做到了 透明化、自动化、智能化,那么它是怎么做到的?
Denodo的数据虚拟化有以下三个能力域。
1.统一数据语言的标准化和转换层,对外提供SQL,屏蔽Python、Scala 、Java各种语言。
2.统一元数据标准规范,比如表格的结构、转换和清洗操作、聚合等 。当使用数据虚拟化时,元数据规范只需要被执行一次,不需要把它们复写给更多的数据消费者。换句话说,数据消费者共享和重复使用这些规范。
3.统一数据存储中心,支持从多个数据存储区中集成数据,具备数据下推往数据源执行的能力。
隐藏底层数据源(关系型数据库、NOSQL、NEWSQL、数据仓库)等技术访问细节,将数据源的抽象和聚合要求将物理资源抽象出来,对外为用户提供一个统一的数据接口。用户在定义数据源的初始化配置文件后,能够自由查询和操作各个目标源的数据源,一言简之,数据虚拟化技术实现前端与后端多源异构的解耦,轻量级简单解决数据集成多源异构的困难。
数据虚拟化对外实现了高访问性用性和高易用性,对内实现了多种数据处理技术协调共存,具备多源异构的数据处理能力
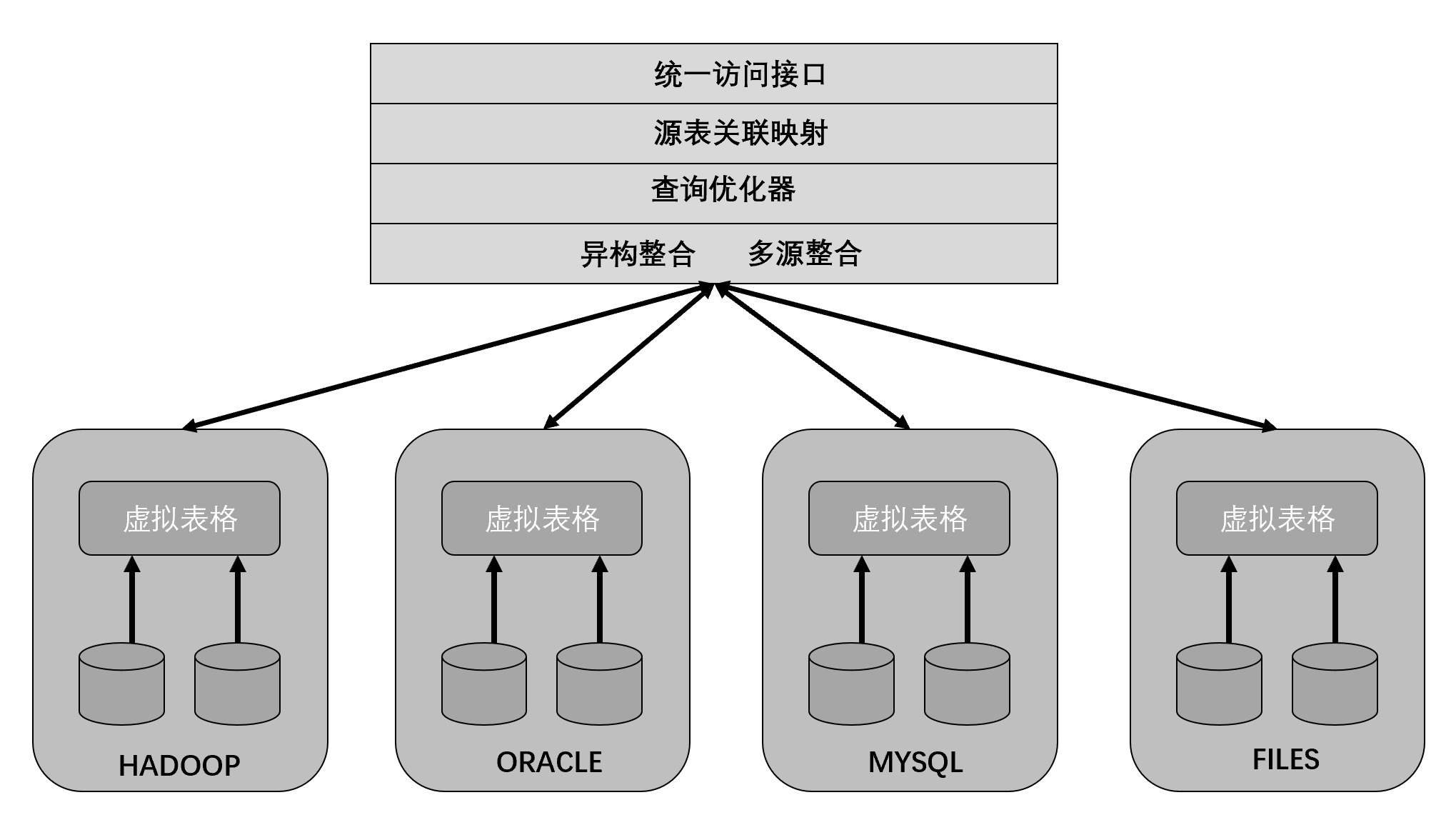
为什么Denodo需要Vertica?Denodo面对的是真正千万吨海量数据压力,它可以对接中台,对接数仓或者各种不同的数据产品。在数据整合充分流动的过程中,数据源hadoop不断在增大,oracle随着业务增长也会上升,面对数据源的不断水涨船高,Denodo需要一个稳定可靠的数据管理系统,对数据进行高效存储管理。特别是多源异构的数据整合时,Denodo需要开辟一个暂存区和多模状态数据存储区区域 ,对数据进行有效的分类分级管理存放,Denodo的缓存数据管理系统需要达到以下指标要求。
- 数据暂存区支持的数据存储空间能够支持数据源。
- 支持分布式部署使用
- 支持分布式扩展
- 支持高可用,意外集群意外宕机能够继续使用。
- 随着数据增长,能够不增加节点的方式提高算力
- 支持自动自助查询和即席查询。
- 支持数据分析有关的所有函数和SQL操作
- 数据管理系统本身能与自治数据源有统一共识的接口。
- 可靠性、稳定性、轻捷的使用性
这一切vertica都做到了,所以高规格的Denodo是选择Vertica做为缓存数据管理系统。
助力smartbi
客户背景
广州思迈特软件有限公司(以下简称思迈特软件)成立于 2011年,以提升和挖掘企业客户的数据价值为使命,专注于商业智能(BI)与大数据分析软件产品与服务,旗下主要产品是smartBI。
smartBI是民族BI软件领先品牌,坚持践行技术创新、“数尽其用”,颠覆了企业软件必须依赖Web端浏览器的传统习惯,充分融会贯通现有企业报表工具,为用户提供丰富的展现力、强大的互动性和灵活的布局能力,严慎细实、全力以赴,有效支撑天问一号火星探测任务、神舟十二号载人飞行任务等高标准航天项目,为中国构建自主创新格局强根筑基。
smartBI与Vertica的关系
2017年7月27日,Smartbi Insight与HPE Vertica正式携手,达成战略合作,打造新一代MPP大数据自助分析方案,为客户提供“基于新一代MPP的高性能大数据自助分析解决方案”。
对用户来说,实现大数据分析需要同时具备功能易用的前端BI工具和性能强劲的数据平台,Smartbi Insight专注于前端功能十几年,形成了以电子表格、自助探索、分析报告为特色的数据展现分析功能,HPE Vertica作为新一代MPP数据库软件,从设计原理上有天然的性能优势。因此,Smartbi Insight+HPE Vertica的强强联合,将为客户带来必不可少的应用价值,也为广大解决方案提供商提供了完备的产品组合。
https://www.kejixun.com/article/170807/358278.shtml
商业智能理解和痛点分析
商业智能实质上是数据转化成信息和知识的过程。构建一个完整的商业智能系统需要以下几种核心的技术:数据仓库、数据挖掘和分析、ETL处理技术、联机分析处理技术、可视化分析、大数据技术、元数据管理,最终用户对商业智能的访问使用包括:即席查询、报表、联机分析处理、数据挖掘等。
从数据到信息,从信息到知识,技术和相关工具必须提供基本的数据的存储能力和数据的处理能力,目前所有的数据广泛产品都包含这两个能力,只是强弱高低之分已。单机分析能力弱,分布式能力强,MPP能力更强,计算能力是商业智能考察的一个重要指标,数据挖掘发现数据的规律也是商业智能重点考察的指标。
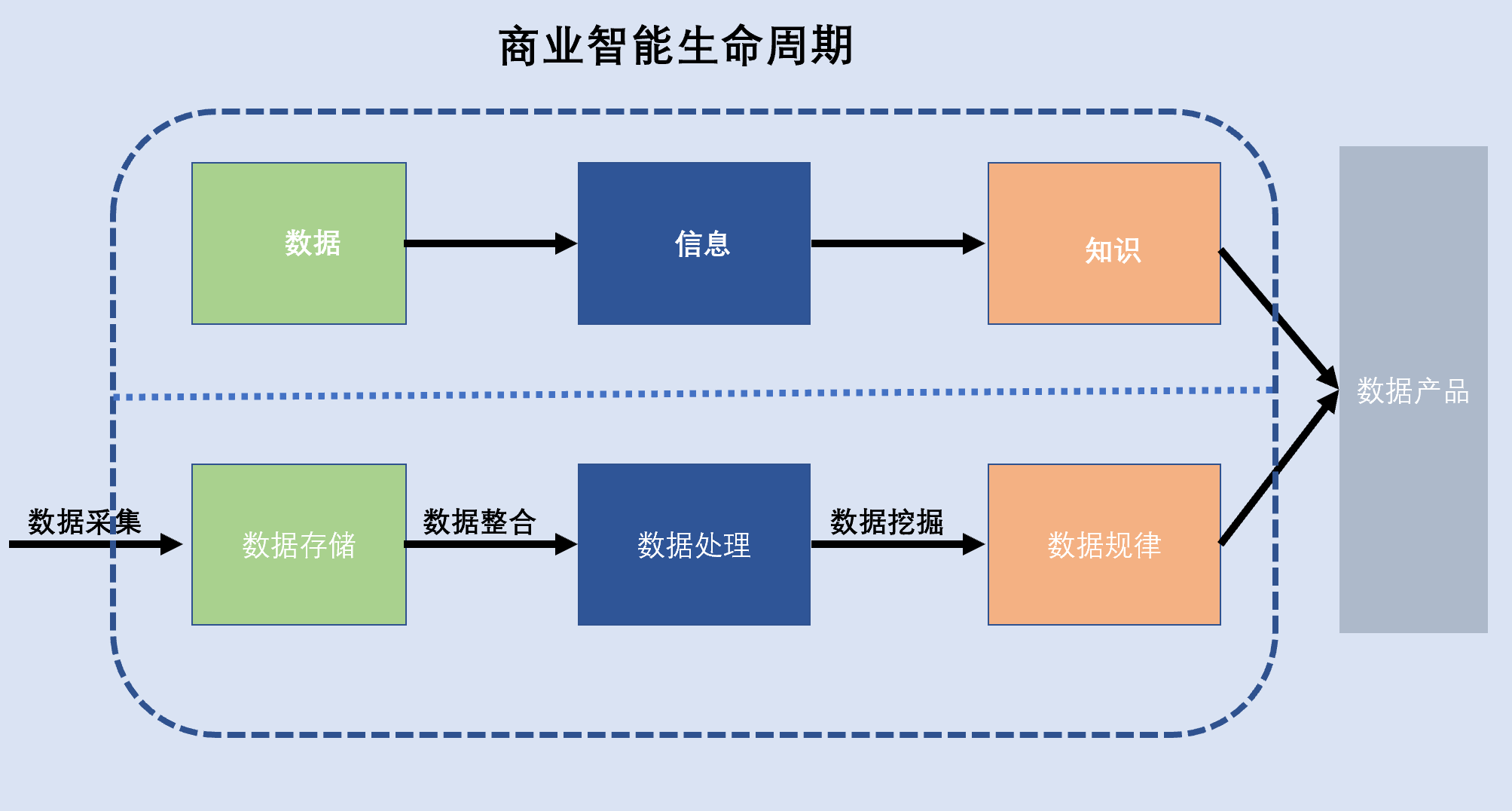
市场内大部分的BI产品都实现了数据的描述性分析,即把业务的运营过程和实时分析结合起来,通过把历史数据和当前数据合并,用于营销活动分析、销售预测、风险管理。描述性分析做的事情是事后结论,即过去发生了什么事情,对数据更有价值和意义的是预测性分析和规范性分析,预测性分析做到将来要发生什么事情,规范性分析则做到什么样的因素会导致这个事情的发生。
过去,BI产品为了预测性分析和规范性分析,都会集成开源或者成熟的学习框架,例如tensorflow或者Deeplearning4j,显然机器学习框架与BI产品融合需要二次开发,即使融合成功,如果数据结果很多或者数据持续不断的输出,存在计算不一致性或者读取数据错误等挑战,发生错误后,需要重新对数据源读取。
Vertica的数据库内算法,让预测性分析和规范性分析有了新的选择。
数据库内算法可以在每个计算节点独立的执行,因此可以在计算节点级别实现新形式的分析处理,提供数据、统计的功能,确保移动是在数据库内完成的,不是库外接口数据传输在应用端完尥。通过移动计算接近数据,可显著提高减少复杂算法(如k-means、逻辑或线性回归)的计算时间。下面是库外计算和库内计算的对比图。
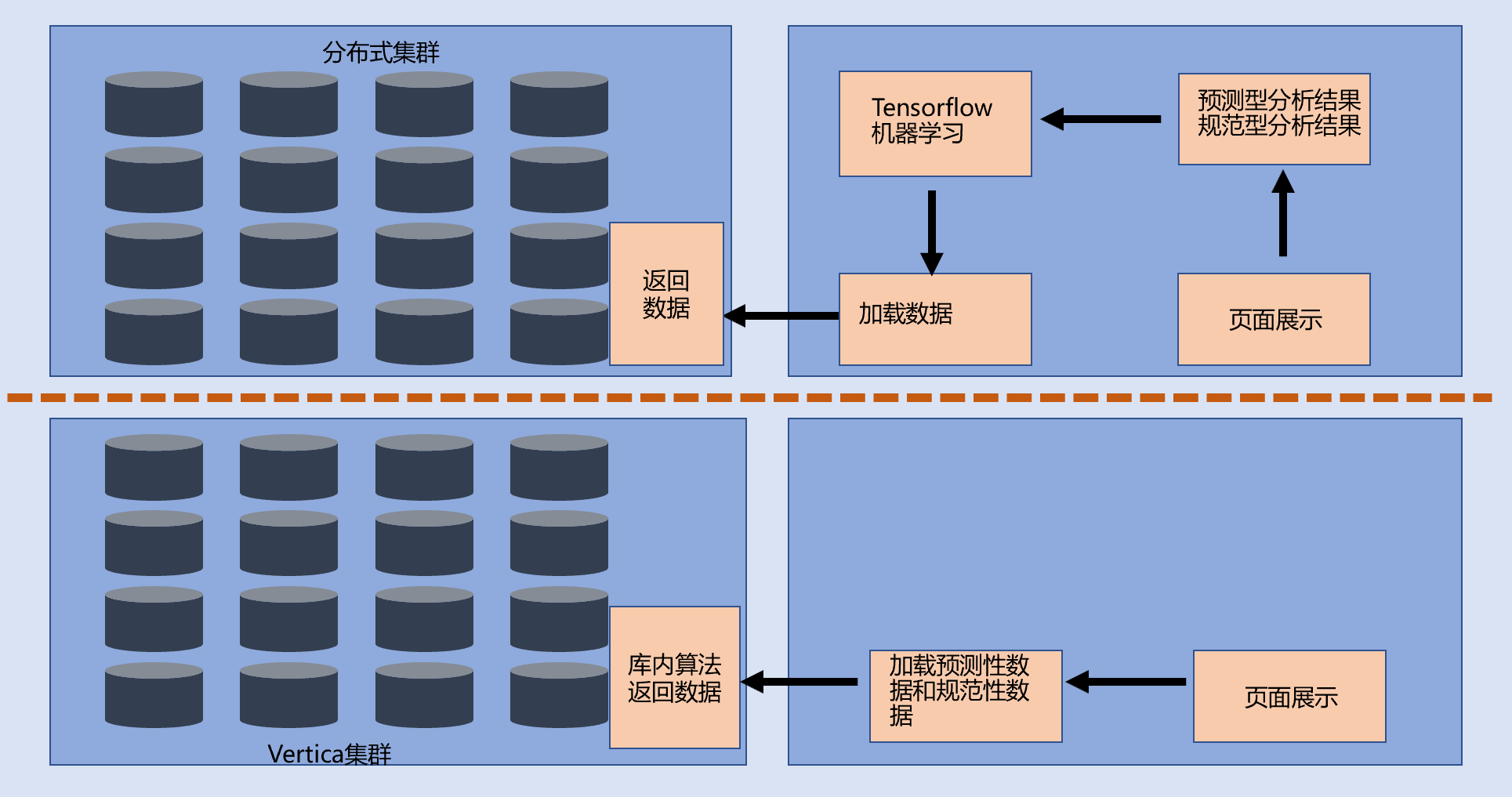
附Vertica聚类算法实现的例子
Clustering Data Using k-means
This k-means example uses two small data sets named agar_dish_1 and agar_dish_2. Using the numeric data in the agar_dish_1 data set,
you can cluster the data into k clusters. Then, using the created k-means model,
you can run APPLY_KMEANS on agar_dish_2 and assign them to the clusters created in your original model.
Before you begin the example, make sure that you have loaded the Machine Learning sample data.
1.Clustering Training Data into k Clusters
Using the KMEANS function, run k-means on the agar_dish_1 table.
=> SELECT KMEANS('agar_dish_kmeans', 'agar_dish_1', '*', 5
USING PARAMETERS exclude_columns ='id', max_iterations=20, output_view=agar_1_view,
key_columns='id');
KMEANS
---------------------------
Finished in 7 iterations
(1 row)
The example creates a model named agar_dish_kmeans and a view containing the results of the model named agar_1_view. You might get different results when you run the clustering algorithm. This is because KMEANS randomly picks initial centers by default.
2.View the output of agar_1_view.
=> SELECT * FROM agar_1_view;
id | cluster_id
-----+------------
2 | 4
5 | 4
7 | 4
9 | 4
13 | 4
.
.
.
(375 rows)
3.Because you specified the number of clusters as 5, verify that the function created five clusters. Count the number of data points within each cluster.
=> SELECT cluster_id, COUNT(cluster_id) as Total_count
FROM agar_1_view
GROUP BY cluster_id;
cluster_id | Total_count
------------+-------------
0 | 76
2 | 80
1 | 74
3 | 73
4 | 72
(5 rows)
From the output, you can see that five clusters were created: 0, 1, 2, 3, and 4.
You have now successfully clustered the data from agar_dish_1.csv into five distinct clusters.
Summarizing Your Model
You can also view a summary of the model you created using the SUMMARIZE_MODEL function. This summary tells you how many cluster centers your model contains, along with other metrics.
=> SELECT SUMMARIZE_MODEL('agar_dish_kmeans');
-[ RECORD 1 ]---+-------------------------------------------------------------------------------------------------
SUMMARIZE_MODEL | k-Means Model Summary:
Number of clusters: 5
Input columns: x, y
Cluster centers:
0: {x: -7.4811859, y: -7.5257672}
1: {x: -3.5061558, y: -3.5570295}
2: {x: -5.5205715, y: -5.4919726}
3: {x: -1.5623823, y: -1.5056116}
4: {x: 0.4970753, y: 0.5111612}
Evaluation metrics:
Total Sum of Squares: 6008.4619
Within-Cluster Sum of Squares:
Cluster 0: 12.389038
Cluster 1: 11.210146
Cluster 2: 12.994356
Cluster 3: 12.639238
Cluster 4: 12.083548
Total Within-Cluster Sum of Squares: 61.316326
Between-Cluster Sum of Squares: 5947.1456
Between-Cluster SS / Total SS: 98.98%
Number of iterations performed: 6
Converged: True
Call:
kmeans(model_name=agar_dish_kmeans, input_table=agar_dish_training, input_columns=*, num_clusters=5,
exclude_columns=id, max_iterations=20, epsilon=0.0001, init_method=random, initial_centers_table=,
distance_method=euclidean, outputView=agar_training_view, key_columns=id
)
Clustering Data Using a k-means Model
Using agar_dish_kmeans, the k-means model you just created, you can classify the agar_dish_2 data set.
Create a table named kmeans_results, using the agar_dish_2 table as your input table and the agar_dish_kmeans model for your initial cluster centers.
Add only the relevant feature columns to the arguments in the APPLY_KMEANS function.
=> CREATE TABLE kmeans_results AS
(SELECT id,
APPLY_KMEANS(x, y
USING PARAMETERS
model_name='agar_dish_kmeans') AS cluster_id
FROM agar_dish_2);
The kmeans_results table shows that the agar_dish_kmeans model correctly clustered the agar_dish_2 data.
复制Smartbi支持各种各样的数据产品,包括传统SQL数据库oracle、DB2、mysql,nosql系列hbase、cassandra、redis以及newsql系列hana、tidb,还有各种数据处理引擎spark、hive、presto等等,万花丛中一点红,唯独Vertica与Smartbi结成战略合作伙伴关系,不但是看中Vertica强大的计算能力,更重要的是Vertica对商业智能业务的理解。
未来数据分析技术展望
物理学里面抖动是一种物理现象,物体彼此之间互有联系需要进行交互,如果物体太多产生的传输和通讯会破坏原来的系统的秩序稳定,导致熵混乱。用中国人的老话说,林子大了什么鸟都有,分布式系统技术存在的数据传输、节点通信、心跳感应、计算监控、计算调度和计算分布时刻都在发生,随着集群节点不断扩大,量变导致质变,集群的复杂度不断提升,发生在DBA上面的事,抖动引起的故障级别叫做闪断。闪断就是有时候故障现象会出现,有时候故障现象不出现,有时候日志打印错误信息,有时候什么信息也没有,你根本无法一下子定位到是系统问题、硬件问题、软件问题、网络问题。
从这个角度来看,集中式流派有独特之处,它虽然昂贵,但是它可靠、稳定、高效,最重要是健壮,如果有世界末日发生洪水灾害,人们登上诺亚方舟逃难,因为方舟空间有限,船上必然安放的是一个集中式流派的系统。如果地球还有几千年的技术发展和文明进步,未来数据分析技术必然是分布式流派的世界,但是分布式集群越做越大,必然要面对抖动现象。例如greeplum集群上升到1000个节点,再往上扩展会有更多的问题和挑战,例如你需要要考虑网段分配和长网络传输耗时,其中一个节点的网卡异常或者系统不稳定,都会影响整个集群。在抖动问题的方案上,预处理和空间处理是较成熟理想的选择,面对不断增长的大数据隐式派生新空间,通过新空间的访问减少IO,而不是全局空间接触。
空间技术不但可以避免抖动,同时也是未来数据分析技术的主流方向,现在的数据中台框架,从原始数据源层到数据域层、轻汇到重汇、个性化大表、数据集市其实就是空间技术的理念,通过对数据提前有效整合,做到应用需要时拿来就用,数据分析的比较其实就是如何对数据源实现高效的数据集成。不计较硬件成本的前提下,presto应该是最快的的MPP利器,但是presto只能处理内存范围内的数据为人诟病。presto另辟溪径,借助Alluxio在数据层面的优势,实现presto与Alluxio的集成提供给客户更优质的体验。Alluxio通过管理内存和本地存储,实现不同存储系统之间的高效数据管理,达到加速数据访问的目标。DorisDB的核心的秘密武器就是物化视图,就是优化后的数据放进新空间,以至大数据增速下依然能保障原来的运行性能。
结尾词
以上是Vertica两个案例的介绍,我相信以后的数据分析技术发展,MPP是宏观必备的基本条件,空间技术是细节的关键核心技术,永不过时的, 最近出现的中国选手StarRocks,它也是MPP的,至此我的演讲完毕。我是Vertica,专业OLAP16年,我会继续深耕数据分析领域,坚持100年不动摇,围绕数据仓库、信息管理、数据管理 、主数据管理、商业智能、数据中台、仓湖建设、数字化转型领域刻苦修行,大放异彩,希望我的经验和能力能够帮到大家,谢谢大家!
附Vertical相关入门和学习了解
https://www.vertica.com/documentation/vertica/11-0-x-documentation/
https://www.vertica.com/knowledgebase/
https://www.modb.pro/db/210638 安装方法
文章被以下合辑收录
评论

 0 点赞
0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞


