




MogHA作为基于MogDB同步和异步流复制技术的一款企业级高可用软件系统,在服务器宕机、实例宕机等多种情况下,能够实现主备自动切换和虚拟IP的自动漂移,使数据库的故障持续时间从分钟级降到秒级,确保业务系统的持续运行。
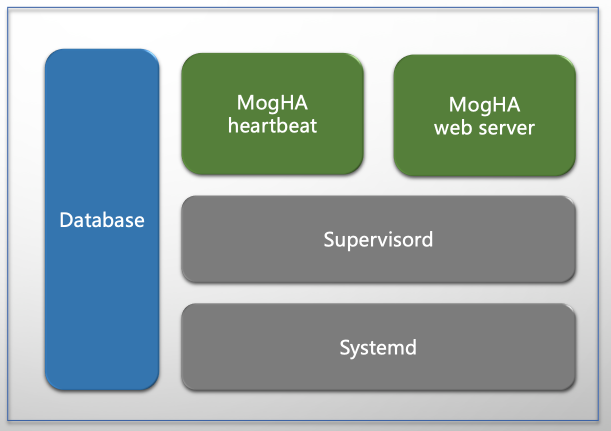
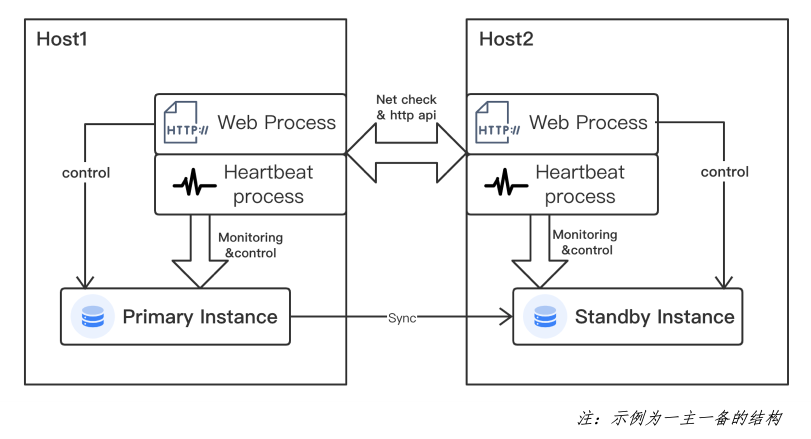
MogHA服务被注册到systemd中,使用supervisord实现MogHA的web 进程和 heartbeat 进程的高可用。MogHA的部署架构和通信模型如下图所示。
MogHA提供了比较丰富的配置用以调整故障探测的评估和速度,并控制故障发生后的处理行为。例如我们可以调小heartbeat_interval和primary_lost_timeout,加快主库故障后的判断时间。也可以配置handle_down_primary、handle_down_standby和primary_down_handle_method等参数 调整主备实例故障后的处理行为。 配置的详细说明如下
# 心跳间隔时间,也是主流程检查的间隔时间,一般设置为3-5s
heartbeat_interval=3
# 主库丢失的探测时间,当主库宕机无法ping到,认为持续到这个时长之后,备库可以切换为主库
primary_lost_timeout=10
# 主库的孤单时间,当主库无法连接到其他机器,ping不到其他任何机器,认为主库网络出现问题
# 当持续超过这个时长,认为主库实例需要关闭(mogdb中会设置为readonly)
primary_lonely_timeout=10
# 当双主状态持续指定时长之后,认为需要做双主判断,
# 因为在维护性操作中,会有可能存在极短时间的双主状态(此时事实上数据库不允许写入)
double_primary_timeout=10
# [v2.1新增] 主实例进程未启动时,是否需要 HA 进行拉起或切换
# 搭配 primary_down_handle_method 使用
handle_down_primary=True
# [v2.1新增] 备库进程未启动时,是否需要 HA 进行拉起
handle_down_standby=True
# [v2.1新增] 主库实例进程未启动时,如何处理
# 支持两种处理方式:
# restart: 尝试重启,尝试次数在 restart_strategy 参数中设定
# failover: 备库升为主,主库尝试重建数据库后启动为备
primary_down_handle_method=restart
# [v2.1新增] 重启实例最大尝试条件: times/minutes
# 例如: 10/3 最多尝试10次或者3分钟,任何一个条件先满足就不再尝试。
restart_strategy=10/3
# [v2.1.1新增] UCE(uncorrected error)故障感知功能,默认开启
# 可选值: True / False
# 内核在收到一些特定的 sigbus 信号的错误时,比如内存坏块等,内核会进行graceful shutdown,
# 坏的内存已经被标记不会被再次分配到,这时候是可以立即拉起实例正常服务的。
uce_error_detection=False
# [v2.1.1新增] UCE检查时,读取最后多少行日志数据进行判断
uce_detect_max_lines=200
首先我们测试下手动的主备切换,这也是在生产环境我们遇到最多的主备切换的场景。如主机计划内的维护,版本升级以及一些计划内的实例重启等 都需要在实施前做主备切换,避免对业务造成较大的影响。
在MogHA的加持下,使用gs_ctl工具 就能非常方便的完成主备切换和vip的漂移,对业务的影响很小。
切换前主库和VIP(172.16.71.29)都在节点mogdb (172.16.71.30)上
[omm@mogdb ~]$ gs_om -t status --detail
[ Cluster State ]
cluster_state : Degraded
redistributing : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state | node node_ip instance state | node node_ip instance state
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 mogdb 172.16.71.30 6001 /mogdb/data/db1 P Primary Normal | 2 mogdb1 172.16.71.31 6002 /mogdb/data/db1 S Standby Need repair(FATAL) | 3 mogdb2 172.16.71.32 6003 /mogdb/data/db1 S Standby Normal
[omm@mogdb ~]$ gs_om -t status --detail
[ Cluster State ]
cluster_state : Normal
redistributing : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state | node node_ip instance state | node node_ip instance state
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 mogdb 172.16.71.30 6001 /mogdb/data/db1 P Primary Normal | 2 mogdb1 172.16.71.31 6002 /mogdb/data/db1 S Standby Normal | 3 mogdb2 172.16.71.32 6003 /mogdb/data/db1 S Standby Normal
[omm@mogdb ~]$
[omm@mogdb ~]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.30 netmask 255.255.255.0 broadcast 172.16.71.255
inet6 fe80::bf6c:c163:d890:aa83 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:8c:47:fa txqueuelen 1000 (Ethernet)
RX packets 14700795 bytes 2112944487 (1.9 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 24224571 bytes 30892701038 (28.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.29 netmask 255.255.255.0 broadcast 172.16.71.255
ether 00:0c:29:8c:47:fa txqueuelen 1000 (Ethernet)
在新主mogdb1(172.16.71.31)上执行切换命令 gs_ctl switchover。注意 switchover 时默认的规则是不等待客户端中断连接,所有活跃事务都被回滚并且客户端都被强制断开,然后服务器将被切换。
[omm@mogdb1 ~]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.31 netmask 255.255.255.0 broadcast 172.16.71.255
inet6 fe80::85a0:8ea3:e41c:5c61 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:74:45:d8 txqueuelen 1000 (Ethernet)
RX packets 13673146 bytes 8932697902 (8.3 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9120981 bytes 2169986315 (2.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[omm@mogdb1 ~]$ gs_ctl switchover -D /mogdb/data/db1/
[2021-12-29 20:01:13.852][61656][][gs_ctl]: gs_ctl switchover ,datadir is /mogdb/data/db1
[2021-12-29 20:01:13.852][61656][][gs_ctl]: switchover term (1)
[2021-12-29 20:01:13.867][61656][][gs_ctl]: Getting state from gaussdb.state!
[2021-12-29 20:01:13.867][61656][][gs_ctl]: waiting for server to switchover...[2021-12-29 20:01:13.884][61656][][gs_ctl]: Getting state from gaussdb.state!
.[2021-12-29 20:01:14.899][61656][][gs_ctl]: Getting state from gaussdb.state!
.[2021-12-29 20:01:15.911][61656][][gs_ctl]: Getting state from gaussdb.state!
.[2021-12-29 20:01:16.923][61656][][gs_ctl]: Getting state from gaussdb.state!
.[2021-12-29 20:01:17.936][61656][][gs_ctl]: Getting state from gaussdb.state!
.[2021-12-29 20:01:18.948][61656][][gs_ctl]: Getting state from gaussdb.state!
.[2021-12-29 20:01:19.961][61656][][gs_ctl]: Getting state from gaussdb.state!
[2021-12-29 20:01:19.961][61656][][gs_ctl]: done
[2021-12-29 20:01:19.961][61656][][gs_ctl]: switchover completed (/mogdb/data/db1)
[omm@mogdb1 ~]$
[omm@mogdb1 ~]$ gs_om -t status --detail
[ Cluster State ]
cluster_state : Normal
redistributing : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state | node node_ip instance state | node node_ip instance state
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 mogdb 172.16.71.30 6001 /mogdb/data/db1 P Standby Normal | 2 mogdb1 172.16.71.31 6002 /mogdb/data/db1 S Primary Normal | 3 mogdb2 172.16.71.32 6003 /mogdb/data/db1 S Standby Normal
[omm@mogdb1 ~]$
[omm@mogdb1 ~]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.31 netmask 255.255.255.0 broadcast 172.16.71.255
inet6 fe80::85a0:8ea3:e41c:5c61 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:74:45:d8 txqueuelen 1000 (Ethernet)
RX packets 13677481 bytes 8933175819 (8.3 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9125377 bytes 2170477860 (2.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.29 netmask 255.255.255.0 broadcast 172.16.71.255
ether 00:0c:29:74:45:d8 txqueuelen 1000 (Ethernet)
可以看到切换操作后,主库和VIP都迁移到新主mogdb1(172.16.71.31),对业务侧的影响是可控的。
接下来我们进行模拟故障的测试,即关闭新主mogdb1(172.16.71.31)所在服务器,观察MogHA的auto failover功能。
关闭新主mogdb1(172.16.71.31)所在服务器
[root@mogdb1 ~]# init 0
Connection refused
一段时间后我们再次查看集群状态 发现主库和VIP 已经迁移到mogdb (172.16.71.30),MogHA实现了故障的 auto failover。
[omm@mogdb ~]$ gs_om -t status --detail
[ Cluster State ]
cluster_state : Degraded
redistributing : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state | node node_ip instance state | node node_ip instance state
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 mogdb 172.16.71.30 6001 /mogdb/data/db1 P Primary Normal | 2 mogdb1 172.16.71.31 6002 /mogdb/data/db1 S Unknown Unknown | 3 mogdb2 172.16.71.32 6003 /mogdb/data/db1 S Standby Normal
[omm@mogdb ~]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.30 netmask 255.255.255.0 broadcast 172.16.71.255
inet6 fe80::bf6c:c163:d890:aa83 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:8c:47:fa txqueuelen 1000 (Ethernet)
RX packets 14715713 bytes 2114452755 (1.9 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 24239294 bytes 30894432693 (28.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.71.29 netmask 255.255.255.0 broadcast 172.16.71.255
ether 00:0c:29:8c:47:fa txqueuelen 1000 (Ethernet)
查看MogHA日志发现,在集群主节点故障后即发现了异常
[omm@mogdb mogha]$ vi /home/omm/mogha/mogha_heartbeat.log
2021-12-29 20:01:20,126 - instance - INFO [opengauss.py:249]: VIP:172.16.71.29 already offline, local ip list: ['172.16.71.30']
2021-12-29 20:01:20,126 - heartbeat.standby - INFO [standby_heartbeat.py:264]: replication check...
2021-12-29 20:01:20,183 - heartbeat.standby - ERROR [standby_heartbeat.py:279]: not get any standby from primary 172.16.71.30
2021-12-29 20:01:23,795 - heartbeat.loop - INFO [toolkit.py:180]: Ping result:{'172.16.71.31': True, '172.16.71.2': True, '172.16.71.32': True}
2021-12-29 20:01:23,826 - heartbeat.loop - INFO [loop.py:152]: Detect that local instance is active standby
2021-12-29 20:01:23,826 - heartbeat.standby - INFO [standby_heartbeat.py:27]: fetch primary info...
2021-12-29 20:01:23,897 - heartbeat.standby - INFO [standby_heartbeat.py:70]: sync primary_info success, primary_info: {'primary': '172.16.71.30', 'time': 1640779267.922255, 'primary_backup': '172.16.71.31',
'primary_second_backup': None}
在确认原主故障无法拉起后,重新进行主库的选举并将VIP绑定在新主库上。
[2021-12-29 20:06:17.118][57260][][gs_ctl]: waiting for server to failover...
.[2021-12-29 20:06:18.133][57260][][gs_ctl]: Getting state from gaussdb.state!
[2021-12-29 20:06:18.144][57260][][gs_ctl]: Getting state from gaussdb.state!
[2021-12-29 20:06:18.144][57260][][gs_ctl]: done
[2021-12-29 20:06:18.144][57260][][gs_ctl]: failover completed (/mogdb/data/db1)
err:
2021-12-29 20:06:18,145 - heartbeat.standby - INFO [standby_heartbeat.py:240]: Start change replconninfo.
2021-12-29 20:06:18,216 - heartbeat.standby - INFO [standby_heartbeat.py:149]: set primary for 172.16.71.32 ...
2021-12-29 20:06:18,576 - heartbeat.standby - INFO [standby_heartbeat.py:155]: set primary for 172.16.71.32 result: new primary set success.
2021-12-29 20:06:18,576 - heartbeat.standby - INFO [standby_heartbeat.py:242]: End old change replconninfo.
2021-12-29 20:06:18,600 - heartbeat.standby - INFO [standby_heartbeat.py:247]: Already become primary
2021-12-29 20:06:18,600 - heartbeat.standby - INFO [standby_heartbeat.py:248]: Start change VIP...
2021-12-29 20:06:21,644 - heartbeat.standby - INFO [standby_heartbeat.py:250]: End change VIP...
2021-12-29 20:06:21,645 - heartbeat.standby - INFO [standby_heartbeat.py:251]: Failover success
2021-12-29 20:06:21,645 - heartbeat.standby - INFO [standby_heartbeat.py:165]: Writing primary info to /home/omm/mogha/primary_info ...
2021-12-29 20:06:21,645 - heartbeat.standby - INFO [standby_heartbeat.py:173]: Write meta file success
2021-12-29 20:06:21,646 - heartbeat.loop - INFO [loop.py:175]: [20001] normal break: Failover success. restart heartbeat.
2021-12-29 20:06:26,648 - heartbeat.loop - INFO [toolkit.py:180]: Ping result:{'172.16.71.31': False, '172.16.71.2': True, '172.16.71.32': True}
2021-12-29 20:06:26,682 - heartbeat.loop - INFO [loop.py:148]: Detect that local instance is active primary
2021-12-29 20:06:26,682 - heartbeat.primary - INFO [primary_heartbeat.py:37]: primary lonely check...
2021-12-29 20:06:28,686 - heartbeat.primary - INFO [primary_heartbeat.py:263]: double primary check...
2021-12-29 20:06:31,720 - heartbeat.primary - ERROR [primary_heartbeat.py:279]: get dbRole from 172.16.71.31 failed. all of ['172.16.71.31'] request failed, errs: {'172.16.71.31': '<urlopen error timed out>'
}
2021-12-29 20:06:31,757 - instance - INFO [opengauss.py:211]: VIP: 172.16.71.29 already set in local host: ['172.16.71.30', '172.16.71.29']
2021-12-29 20:06:31,757 - heartbeat.primary - INFO [primary_heartbeat.py:353]: sync primary info...
2021-12-29 20:06:31,784 - heartbeat.primary - INFO [primary_heartbeat.py:400]: standby check...
2021-12-29 20:06:36,843 - heartbeat.loop - INFO [toolkit.py:180]: Ping result:{'172.16.71.31': False, '172.16.71.2': True, '172.16.71.32': True}
2021-12-29 20:06:36,875 - heartbeat.loop - INFO [loop.py:148]: Detect that local instance is active primary
2021-12-29 20:06:36,875 - heartbeat.primary - INFO [primary_heartbeat.py:37]: primary lonely check...
2021-12-29 20:06:38,880 - heartbeat.primary - INFO [primary_heartbeat.py:263]: double primary check...
2021-12-29 20:06:41,912 - heartbeat.primary - ERROR [primary_heartbeat.py:279]: get dbRole from 172.16.71.31 failed. all of ['172.16.71.31'] request failed, errs: {'172.16.71.31': '<urlopen error timed out>'
}
综上,MogHA不但能在计划内的手动主备切换场景下实现VIP的漂移,也能在集群主节点出现宕机等灾难性的场景下及时监测到异常,并完成新主的选举和VIP的迁移等工作,快速恢复MogDB集群的服务。 在后续的文章中我们会进一步介绍MogHA的重要参数,以及不同配置对RTO的影响。
