




Spark的存储系统是指通过BlockManager和BlockManagerMaster等相关组件来管理作业运行时所涉及的内存和磁盘溢写数据块的存储管理体系,具体的数据主要包括:broadcast广播变量、执行cache或者persist算子产生的缓存变量,以及在spark shuffle过程中所产生的shuffle中间文件。
Spark存储体系的数据既可以存储在内存中(例如:执行cache方法需要将数据缓存到内存中),也可以写入到磁盘文件中(例如:shuffle文件的溢写需要数据落盘);其中,当采用内存存储数据时使用的是executor的存储内存部分。
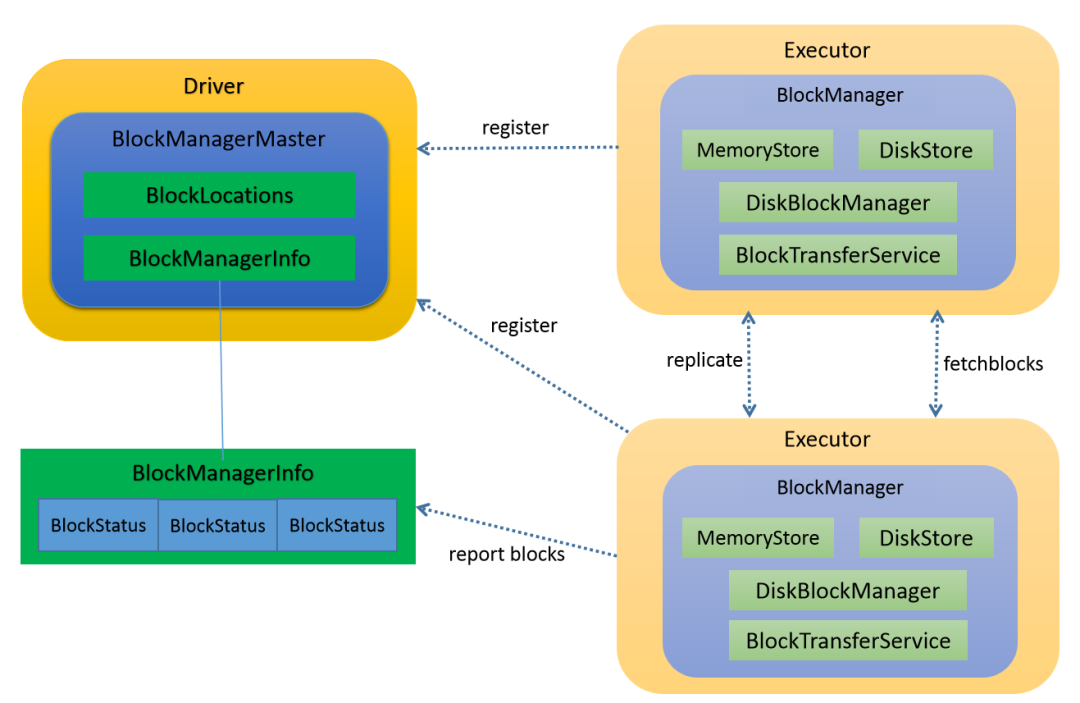
存储系统架构
Spark的存储体系是一个主从架构,由driver端的BlockManagerMaster作为master节点,由driver和executor中的BlockManager作为slave节点。
BlockManagerMaster负责管理整个Spark作业存储系统的元数据,包括所有数据块的状态和存储位置等信息。
BlockManager提供了一套数据块管理的外部接口,负责本地数据的存取以及与远端BlockManager之间的数据传输。在每个BlockManager对象的初始化过程中会向BlockManagerMaster进行注册,并且各BlockManager会定期、或当数据发生变化时向BlockManagerMaster汇报相关数据块的存储状态。
在Spark存储系统中将单个广播变量、数据缓存的一个分区以及单个shuffle文件定义为一个数据块block,block的状态通过BlockStatus类表示,包括block的存储级别(storageLevel)、内存缓存容量(memSize)、磁盘缓存容量(diskSize)等信息。
在BlockManager的构建过程中还创建了MemoryStore、DiskStore、DiskBlockManager以及BlockTransferService等对象。MemoryStore用来管理存储数据在内存中的读写操作和生命周期;DiskStore用于管理存储数据的磁盘读写操作,并且由DiskBlockManager来管理相应磁盘文件的创建和销毁;BlockTransferService则用于各BlockManager之间数据块的拉取和分发操作。
BlockManager初始化与注册
BlockManager是在创建SparkEnv的过程中创建的,通过intialize方法实现BlockManager实例的初始化,主要实现的功能有:初始化blockTransferService用于blockManager之间的数据传输、创建BlockManagerId对象、向BlockManagerMaster注册、以及生成shuffleServerId用于shuffle文件的读写:
def initialize(appId: String): Unit = {
blockTransferService.init(this)
...
val id =
BlockManagerId(executorId, blockTransferService.hostName, blockTransferService.port, None)
val idFromMaster = master.registerBlockManager(
id,
diskBlockManager.localDirsString,
maxOnHeapMemory,
maxOffHeapMemory,
storageEndpoint)
blockManagerId = if (idFromMaster != null) idFromMaster else id
shuffleServerId = if (externalShuffleServiceEnabled) {
logInfo(s"external shuffle service port = $externalShuffleServicePort")
BlockManagerId(executorId, blockTransferService.hostName, externalShuffleServicePort)
} else {
blockManagerId
}
...
}
其中向BlockManagerMaster注册是由BlockManager向BlockManagerMasterEndpoint发送RegisterBlockManage RPC消息,然后BlockManagerMasterEndpoint收到消息后执行register方法来完成该BlockManager的注册;
在register方法中将该BlockManager的信息作为元数据保存起来,主要的操作包括:将BlockManagerId和对应的executorId登记到blockManagerIdByExecutor哈希列表中,以及生成BlockManagerInfo对象并与BlockManagerId保存到blockManagerInfo哈希列表中:
blockManagerIdByExecutor(id.executorId) = id
...
blockManagerInfo(id) = new BlockManagerInfo(id, System.currentTimeMillis(),
maxOnHeapMemSize, maxOffHeapMemSize, storageEndpoint, externalShuffleServiceBlockStatus)
同时,在BlockManagerMaster中还保存了作业中所有block的位置和状态信息,分别通过blockLocations对象和_blocks对象表示;
blockLocations对象的结构为:JHashMap[BlockId, mutable.HashSet[BlockManagerId]],保存了各个block的对应的BlockManagerId列表;_blocks对象的结构为JHashMap[BlockId, BlockStatus],保存了各个block的状态信息;
BlockManager通过心跳、或者当block创建和更新时会向BlockManagerMaster汇报相应block的位置和状态信息。
BlockManager发送心跳和block汇报
由于executor每隔一定时间(默认10秒)会向driver汇报心跳,driver收到心跳信息后向BlockManagerMasterHeartbeatEndpoint发送BlockManagerHeartbeat消息:
def executorHeartbeatReceived(
...
blockManagerMaster.driverHeartbeatEndPoint.askSync[Boolean](
BlockManagerHeartbeat(blockManagerId),
new RpcTimeout(blockManagerMasterDriverHeartbeatTimeout, "BlockManagerHeartbeat"))
}
BlockManagerMasterHeartbeatEndpoint则检查blockManagerInfo中是否有该blockManagerId的信息,如果有则返回成功,没有则需要重新汇报该executor的block信息:
// Messages received from executors
case heartbeat @ Heartbeat(executorId, accumUpdates, blockManagerId, executorUpdates) =>
var reregisterBlockManager = !sc.isStopped
if (scheduler != null) {
if (executorLastSeen.contains(executorId)) {
executorLastSeen(executorId) = clock.getTimeMillis()
eventLoopThread.submit(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
val unknownExecutor = !scheduler.executorHeartbeatReceived(
executorId, accumUpdates, blockManagerId, executorUpdates)
reregisterBlockManager &= unknownExecutor
val response = HeartbeatResponse(reregisterBlockManager)
context.reply(response)
}
当executor接收到driver的响应指令后发现需要重新汇报block信息,则由blockManager调用reregister方法将本地的block信息全部汇报给blockManagerMaster:
try {
val response = heartbeatReceiverRef.askSync[HeartbeatResponse](
message, new RpcTimeout(HEARTBEAT_INTERVAL_MS.millis, EXECUTOR_HEARTBEAT_INTERVAL.key))
if (response.reregisterBlockManager) {
logInfo("Told to re-register on heartbeat")
env.blockManager.reregister()
}
其中在reregister方法中通过调用reportAllBlocks方法将该BlockManager管理的所有block的信息汇报给BlockManagerMaster,在reportAllBlocks方法的实现中针对各个block执行tryToReportBlockStatus方法进行block汇报;
同时,每当BlockManager有写入、删除block操作或者block的状态发生变化时均会调用BlockManager的reportBlockStatus方法向BlockManagerMaster汇报,而reportAllBlocks方法也是调用tryToReportBlockStatus方法来实现的。
在tryToReportBlockStatus方法中,实际是将该block的blockManagerId、blockId以及当前的存储级别、内存使用空间和磁盘使用空间通过发送RPC消息UpdateBlockInfo给BlockManagerMaster:
private def tryToReportBlockStatus(
blockId: BlockId,
status: BlockStatus,
droppedMemorySize: Long = 0L): Boolean = {
val storageLevel = status.storageLevel
val inMemSize = Math.max(status.memSize, droppedMemorySize)
val onDiskSize = status.diskSize
master.updateBlockInfo(blockManagerId, blockId, storageLevel, inMemSize, onDiskSize)
}
BlockManagerMasterEndPoint收到UpdateBlockInfo消息后,会更新该block状态BlockStatus,以及blockLocations中关于该block的存储位置等:
blockManagerInfo(blockManagerId).updateBlockInfo(blockId, storageLevel, memSize, diskSize)
...
if (blockLocations.containsKey(blockId)) {
locations = blockLocations.get(blockId)
} else {
locations = new mutable.HashSet[BlockManagerId]
blockLocations.put(blockId, locations)
}
if (storageLevel.isValid) {
locations.add(blockManagerId)
} else {
locations.remove(blockManagerId)
}
...
if (locations.size == 0) {
blockLocations.remove(blockId)
}
Spark存储系统的公共接口
由于具体的数据读写是通过MemoryStore和DiskStore来负责实施的,本节将讲解MemoryStore和DiskStore这两个类的读写接口。
数据存储级别
在解释读写接口之前先介绍一个Spark存储系统中的重要概念:“存储级别”(StorageLevel),存储级别是数据块的属性。
StorageLevel类具有三个维度:第一个维度表示数据块的存储位置,第二个维度表示数据块否做序列化,第三个维度表示数据块的副本数:
def useDisk: Boolean = _useDisk //是否可存储在磁盘
def useMemory: Boolean = _useMemory //是否可存储在堆内内存
def useOffHeap: Boolean = _useOffHeap //是否可存储在堆外内存
def deserialized: Boolean = _deserialized //是否可序列化
def replication: Int = _replication //副本数
不同的存储级别对应如上5个参数的值也不同:
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false) //数据块不存在于存储系统中
val DISK_ONLY = new StorageLevel(true, false, false, false) //仅可以存储在磁盘中
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val DISK_ONLY_3 = new StorageLevel(true, false, false, false, 3)
val MEMORY_ONLY = new StorageLevel(false, true, false, true) //仅可以存储在堆内内存中
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) // 既可以存储在堆内内存也可以存储在磁盘中
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
// 既可以存储在堆内内存也可以存储在磁盘中,并且序列化存储为两个副本:
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
// 既可以存储在磁盘,也可以存储在堆内内存,或者存储在堆外内存中:
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
MemoryStore
如果数据需要通过存储系统需要写入到内存时,可以写入为JVM数据对象,也可以序列化为二进制字节进行写入,前者占用较多的内存空间,但数据读取较快,后者则反之,工程师可以根据自身的需求和资源情况采用不同的数据写入形式。
MemoryStore在初始化的过程中创建了一个LinkedHashMap[BlockId, MemoryEntry[_]]结构的entries对象,该哈希链表结构中存放着物化到executor内存中的所有block的blockId和MemoryEntry;其中MemoryEntry表示一个数据块的抽象,如果数据块是以JVM对象的方式存储则通过DeserializedMemoryEntry类实现,如果需要序列化为字节数组则采用SerializedMemoryEntry类来实现。
MemoryStore数据写入接口
MemoryStore对外提供的写入接口主要有putIteratorAsValues(将数据逐步展开并以JVM对象方式写到内存)、putIteratorAsBytes(将block数据逐步展开并以二进制字节方式写入内存)和 putBytes(将block直接序列化写入内存)。
其中,逐步展开写入的方式是根据实际的内存需求量不断去申请少量的内存,适用于较大数据块的内存写入场景;而putBytes则一次性申请所需的内存,如果内存空间不足则失败返回,该方法适用于写入较小的数据分片的场景。
1、putIterator方法
由于MemoryStore的putIteratorAsValues和putIteratorAsBytes方法的底层主要都是通过其内部方法putIterator实现的,并且通过ValuesHolder接口来屏蔽JVM对象和二进制字节数组的差异,接下来我们来看一下putIterator方法的实现:
// Request enough memory to begin unrolling
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, memoryMode)
if (!keepUnrolling) {
logWarning(s"Failed to reserve initial memory threshold of " +
s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.")
} else {
unrollMemoryUsedByThisBlock += initialMemoryThreshold
}
// Unroll this block safely, checking whether we have exceeded our threshold periodically
while (values.hasNext && keepUnrolling) {
valuesHolder.storeValue(values.next())
if (elementsUnrolled % memoryCheckPeriod == 0) {
val currentSize = valuesHolder.estimatedSize()
// If our vector's size has exceeded the threshold, request more memory
if (currentSize >= memoryThreshold) {
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
// New threshold is currentSize * memoryGrowthFactor
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
}
if (keepUnrolling) {
val entryBuilder = valuesHolder.getBuilder()
val size = entryBuilder.preciseSize
if (size > unrollMemoryUsedByThisBlock) {
val amountToRequest = size - unrollMemoryUsedByThisBlock
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
}
if (keepUnrolling) {
val entry = entryBuilder.build()
// Synchronize so that transfer is atomic
memoryManager.synchronized {
releaseUnrollMemoryForThisTask(memoryMode, unrollMemoryUsedByThisBlock)
val success = memoryManager.acquireStorageMemory(blockId, entry.size, memoryMode)
assert(success, "transferring unroll memory to storage memory failed")
}
entries.synchronized {
entries.put(blockId, entry)
}
...
以上代码片段的主要逻辑如下:
1)到executor的存储内存池中申请初始展开内存大小initialMemoryThreshold(默认1M)的存储内存空间;
2)如果内存申请失败则返回;如果申请成功,则开始累计该block所使用的展开内存空间unrollMemoryUsedByThisBlock;
3)逐个展开记录并写入到valuesHolder中,当记录为JVM对象时valuesHolder采用DeserializedValuesHolder类来实现,当记录需要序列化时采用SerializedValuesHolder类来实现;
4)如果已展开的记录数elementsUnrolled与memoryCheckPeriod取模为0时,判断如果当前valuesHolder中数据所占用的空间大于memoryThreshold时则尝试申请( currentSize * memoryGrowthFactor - memoryThreshold )大小的展开内存,其中memoryGrowthFactor 是扩容因子(默认为1.5),memoryThreshold 是之前已申请到的展开内存的大小(初始值为initialMemoryThreshold);如果申请成功则累加unrollMemoryUsedByThisBlock、elementsUnrolled以及memoryThreshold的值;
5)如果所有记录已经展开完成,则推测valuesHolder中的记录所占用的内存空间为size,如果size大于之前申请到的展开内存则继续申请这部分存储内存差额;
6)如果第5)步执行成功,则将valuesHolder中的所有记录整合为一个MemoryEntry对象(DeserializedMemoryEntry对象或SerializedMemoryEntry对象,分别对应于非序列化和序列化的场景)。
7)释放unrollMemoryUsedByThisBlock所申请的展开内存空间(推测内存大小),并根据前面得到的MemoryEntry对象的实际大小申请存储内存空间,注意这一步加了线程锁,以确保该block可以申请到存储内存;
8)将该block的blockId和MemoryEntry对象放置到哈希链表entries中,从而完成该block的内存写入流程。
2、putBytes方法:
1)根据数据块的blockId、数据空间大小、内存memoryMode,通过调用MemoryManager的acquireStorageMemory尝试获取存储内存;
2)如果成功获取到所需的存储内存,则将数据封装成SerializedMemoryEntry对象,并将该数据块的blockId以及SerializedMemoryEntry对象的引用存到哈希链表中;
3)如果没有申请到足够的存储内存空间,则写入内存失败。
def putBytes[T: ClassTag](
blockId: BlockId,
size: Long,
memoryMode: MemoryMode,
_bytes: () => ChunkedByteBuffer): Boolean = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
if (memoryManager.acquireStorageMemory(blockId, size, memoryMode)) {
// We acquired enough memory for the block, so go ahead and put it
val bytes = _bytes()
assert(bytes.size == size)
val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]])
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as bytes in memory (estimated size %s, free %s)".format(
blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
true
} else {
false
}
}
MemoryStore数据读取接口
MemoryStore支持通过blockId获取存储内存中的数据,同样根据数据在内存中的存储形式不同,分别采用getBytes 或者 getValues方法通过MemoryStore来进行数据读取。
读取的接口较为简单,以getValues方法为例,根据blockId从前面提到的entries哈希链表中获取相应的MemoryEntry对象,如果获取成功则返回:
def getValues(blockId: BlockId): Option[Iterator[_]] = {
val entry = entries.synchronized { entries.get(blockId) }
entry match {
case null => None
case e: SerializedMemoryEntry[_] =>
throw new IllegalArgumentException("should only call getValues on deserialized blocks")
case DeserializedMemoryEntry(values, _, _) =>
val x = Some(values)
x.map(_.iterator)
}
}
存储内存的数据驱逐
我们知道,存储系统所使用的内存是executor的存储内存部分,当需要使用存储内存而当前存储内存不足时需要驱逐部分block,该过程是通过MemoryStore的evictBlocksToFreeSpace方法来实现的;
由于MemoryStore中的block记录是通过LinkedHashMap组织的,因此这些记录可以采用LRU策略将最近最少使用的block驱逐出去。
evictBlocksToFreeSpace的实现逻辑
1、轮询entries哈希链表中的记录逐个判断是否可以用于驱逐:如果该block的memoryMode与所需让出的内存memoryMode一致,并且该block与当前申请内存的block不属于同一个RDD(也就是说,当一个RDD正在申请存储内存时不会驱逐该RDD已经进入存储内存的分区数据块),同时该block上没有读锁的情况下,则该记录可以用于驱逐;
2、将可以驱逐的block记录到selectedBlocks列表中,并累加这些block的内存空间之和记为freedMemory,如果freedMemory大于所需让出的内存空间space的值则停止轮询;
3、通过BlockManager的dropFromMemory方法逐个将selectedBlocks列表中的block溢写到磁盘并从entries列表中删除;
private[spark] def evictBlocksToFreeSpace(
blockId: Option[BlockId],
space: Long,
memoryMode: MemoryMode): Long = {
assert(space > 0)
memoryManager.synchronized {
var freedMemory = 0L
val rddToAdd = blockId.flatMap(getRddId)
val selectedBlocks = new ArrayBuffer[BlockId]
def blockIsEvictable(blockId: BlockId, entry: MemoryEntry[_]): Boolean = {
entry.memoryMode == memoryMode && (rddToAdd.isEmpty || rddToAdd != getRddId(blockId))
}
entries.synchronized {
val iterator = entries.entrySet().iterator()
while (freedMemory < space && iterator.hasNext) {
val pair = iterator.next()
val blockId = pair.getKey
val entry = pair.getValue
if (blockIsEvictable(blockId, entry)) {
// We don't want to evict blocks which are currently being read, so we need to obtain
// an exclusive write lock on blocks which are candidates for eviction. We perform a
// non-blocking "tryLock" here in order to ignore blocks which are locked for reading:
if (blockInfoManager.lockForWriting(blockId, blocking = false).isDefined) {
selectedBlocks += blockId
freedMemory += pair.getValue.size
}
}
}
}
def dropBlock[T](blockId: BlockId, entry: MemoryEntry[T]): Unit = {
val data = entry match {
case DeserializedMemoryEntry(values, _, _) => Left(values)
case SerializedMemoryEntry(buffer, _, _) => Right(buffer)
}
val newEffectiveStorageLevel =
blockEvictionHandler.dropFromMemory(blockId, () => data)(entry.classTag)
...
}
if (freedMemory >= space) {
var lastSuccessfulBlock = -1
try {
logInfo(s"${selectedBlocks.size} blocks selected for dropping " +
s"(${Utils.bytesToString(freedMemory)} bytes)")
(0 until selectedBlocks.size).foreach { idx =>
val blockId = selectedBlocks(idx)
val entry = entries.synchronized {
entries.get(blockId)
}
if (entry != null) {
dropBlock(blockId, entry)
afterDropAction(blockId)
}
...
DiskStore
DiskStore数据写入接口
由于磁盘中数据只能以序列化方式存储,在Spark存储系统中通过DiskStore的put方法或者putBytes方法进行数据的写入,我们以put方法为例来了解相关原理,主要的代码片段如下:
def put(blockId: BlockId)(writeFunc: WritableByteChannel => Unit): Unit = {
...
val file = diskManager.getFile(blockId)
val out = new CountingWritableChannel(openForWrite(file))
var threwException: Boolean = true
try {
writeFunc(out)
blockSizes.put(blockId, out.getCount)
threwException = false
} finally ...
DiskStore的写入过程非常简单,注意DiskStore是DiskBlockManager类来管理本地文件的生命周期的:
1、根据blockId通过DiskBlockManager在数据节点本地获取或者创建与该blockId对应的磁盘文件;
2、将数据写入输出缓冲区将数据输出到磁盘文件;
3、将数据的blockId和所占的字节数记录到blockSizes中,为数据读取做准备。
DiskStore数据读取接口
DiskStore对外提供的数据读取接口包括def getBytes(blockId: BlockId)和def getBytes(f: File, blockSize: Long)两种,实现原理也非常简单,由于在存储系统中所有存储在磁盘的block在DiskStore中都登记为一个磁盘文件,需要获取该block的数据时找到该文件并读取即可,本文不再展开。
存储系统在广播变量中的应用
写入广播变量
Spark中的广播变量将占用空间较小的、可以由executor所共享的数据,通过SparkContext的broadcast方法进行广播,针对每次广播BroadcastManager均会创建一个TorrentBroadcast对象来负责广播变量的管理,并在TorrentBroadcast初始化的过程中通过调用writeBlocks()方法完成广播变量的写入。
接下来我们具体看一下writeBlocks()方法的处理过程:
1、根据该broadcast的序列号构建出BroadcastBlockId对象broadcastId(编码方式:"broadcast_" + id),以及需要广播的数据作为一个interator对象等信息,通过调用putSingle方法将广播变量存放在本地,以便当本地的excutor需要使用该广播变量时可以直接通过blockId从本地存储系统中获取。
putSingle方法实际上调用BlockManager的doPutIterator方法,数据存储级别为MEMORY_AND_DISK,并且不向broadcastManager汇报:
if (!blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
在BlockManager的doPutIterator方法中,由于存储级别 MEMORY_AND_DISK,则通过执行MemoryStore的putIteratorAsValues方法将数据对象写入到内存中:
if (level.useMemory) {
// Put it in memory first, even if it also has useDisk set to true;
// We will drop it to disk later if the memory store can't hold it.
if (level.deserialized) {
memoryStore.putIteratorAsValues(blockId, iterator(), classTag)
如果写入内存失败,则将数据进行序列化并调用DiskStore的put方法将数据写到磁盘文件:
case Left(iter) =>
// Not enough space to unroll this block; drop to disk if applicable
if (level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
serializerManager.dataSerializeStream(blockId, out, iter)(classTag)
}
size = diskStore.getSize(blockId)
}
2、将广播数据根据spark.broadcast.blockSize配置的大小(默认4MB)拆分成多个序列化为二进制数组的block,每个block的BroadcastBlockId的编码格式为"broadcast_" + id + "piece" + i,然后本地的BlockManager执行putBytes方法将各个block的数据写入到本地存储系统中,并且向BlockManagerMaster汇报block的状态,以便当其他executor需要该广播变量时可以找到该BlockManager并获取相应的数据:
val blocks =
TorrentBroadcast.blockifyObject(value, blockSize, SparkEnv.get.serializer, compressionCodec)
if (checksumEnabled) {
checksums = new Array[Int](blocks.length)
}
blocks.zipWithIndex.foreach { case (block, i) =>
if (checksumEnabled) {
checksums(i) = calcChecksum(block)
}
val pieceId = BroadcastBlockId(id, "piece" + i)
val bytes = new ChunkedByteBuffer(block.duplicate())
if (!blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(s"Failed to store $pieceId of $broadcastId " +
s"in local BlockManager")
}
}
注意第二次数据写入的存储级别是MEMORY_AND_DISK_SER,即采用二进制的方式进行写入,不仅可以节省存储空间,并且当需要传输到其他executor时不再需要经过序列化操作,有利于提升执行性能。
在putBytes方法中实际调用了抽象类BlockStoreUpdater的save方法,在该方法中首先通过执行saveSerializedValuesToMemoryStore方法尝试将该block通过MemoryStore的putBytes方法写入到内存中,如果写入内存失败则调用saveToDiskStore方法通过DiskStore的putBytes方法将数据写入到本地磁盘文件中:
if (level.useMemory) {
// Put it in memory first, even if it also has useDisk set to true;
// We will drop it to disk later if the memory store can't hold it.
val putSucceeded = if (level.deserialized) {
saveDeserializedValuesToMemoryStore(blockData().toInputStream())
} else {
saveSerializedValuesToMemoryStore(readToByteBuffer())
}
if (!putSucceeded && level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
saveToDiskStore()
}
当每个block写入完成之后,将该block的存储信息汇报给BlockManagerMaster,其中reportBlockStatus调用的其实是前面介绍过的BlockManager的tryToReportBlockStatus方法:
val putBlockStatus = getCurrentBlockStatus(blockId, info)
val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid
if (blockWasSuccessfullyStored) {
// Now that the block is in either the memory or disk store,
// tell the master about it.
info.size = blockSize
if (tellMaster && info.tellMaster) {
reportBlockStatus(blockId, putBlockStatus)
}
读取广播变量
当访问广播变量时需要执行其value方法,例如在spark任务中通过执行taskBinary.value获取被序列化的task:
override def runTask(context: TaskContext): MapStatus = {
...
val rddAndDep = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
而value方法最终通过调用TorrentBroadcast类的readBroadcastBlock方法来实现广播变量的读取:
private def readBroadcastBlock(): T = Utils.tryOrIOException {
TorrentBroadcast.torrentBroadcastLock.withLock(broadcastId) {
val broadcastCache = SparkEnv.get.broadcastManager.cachedValues
Option(broadcastCache.get(broadcastId)).map(_.asInstanceOf[T]).getOrElse {
setConf(SparkEnv.get.conf)
val blockManager = SparkEnv.get.blockManager
blockManager.getLocalValues(broadcastId) match {
case Some(blockResult) =>
if (blockResult.data.hasNext) {
val x = blockResult.data.next().asInstanceOf[T]
releaseBlockManagerLock(broadcastId)
if (x != null) {
broadcastCache.put(broadcastId, x)
}
x
...
case None =>
...
val blocks = readBlocks()
logInfo(s"Reading broadcast variable $id took ${Utils.getUsedTimeNs(startTimeNs)}")
try {
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks.map(_.toInputStream()), SparkEnv.get.serializer, compressionCodec)
val storageLevel = StorageLevel.MEMORY_AND_DISK
if (!blockManager.putSingle(broadcastId, obj, storageLevel, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
if (obj != null) {
broadcastCache.put(broadcastId, obj)
}...
以上代码片段的主要处理流程如下:
1、先根据broadcastId从broadcastCache中读取广播变量, 如果获取成功则返回;
2、如果在broadcastCache中不存在,则调用getLocalValues方法尝试从本地存储系统中获取,如果可以取到则将该数据放到broadcastCache中并返回;
3、否则继续调用readBlocks()方法通过以分片为单位来获取数据,readBlocks()方法的实现逻辑如下:
1)本地的blockManager根据各分片的blockId调用getLocalBytes尝试从本地存储系统中获取该数据分片,如果数据分片存在本地则将该其放入blocks数组(blocks数组是存放广播数据分片的二进制数组)中用于返回;
2)否则数据就存放在其他executor的存储系统中,则通过调用BlockManager的getRemoteBytes方法从其他executor中拉取数据:
首先,发送GetLocationsAndStatus消息给BlockManagerMaster的RPC对象BlockManagerMasterEndpoint,BlockManagerMasterEndpoint接收到该消息后,从blockLocations中查找包含该blockId的所有blockManagerId列表,并根据各个blockManagerId从对应的BlockManagerInfo中获取广播数据块的BlockStatus信息(包括:存储级别、在内存和磁盘中的存储容量):
val locations = Option(blockLocations.get(blockId)).map(_.toSeq).getOrElse(Seq.empty)
val status = locations.headOption.flatMap { bmId =>
if (externalShuffleServiceRddFetchEnabled && bmId.port == externalShuffleServicePort) {
Option(blockStatusByShuffleService(bmId).get(blockId))
} else {
blockManagerInfo.get(bmId).flatMap(_.getStatus(blockId))
}
}
然后,通过BlockManager的fetchRemoteManagedBuffer方法遍历前面所得到的blockManager地址列表,通过blockTransferService向这些blockManager尝试拉取该广播变量的数据分片,如果拉取成功则退出循环并将数据分片放入到blocks数组中:
while (locationIterator.hasNext) {
val loc = locationIterator.next()
val data = try {
val buf = blockTransferService.fetchBlockSync(loc.host, loc.port, loc.executorId,
blockId.toString, tempFileManager)
4、通过unBlockifyObject方法将blocks数组中的所有数据分片组装到一起并反序列为一个数据对象,接下来BlockManager调用putSingle方法将该数据对象保存在本地的存储系统中,并将该block的id以及对象引用登记到broadcastCache中。
存储系统在缓存中的应用
当某些RDD的计算结果在后续将被多次引用,或者作业发生异常重算该RDD的代价非常大的情况下,我们可以考虑通过执行cache或者persist方法将该RDD缓存下来,从而提升执行性能。
其中,cache是persist的一个特例,只能被缓存在内存中:
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
同时,persist算子并不是立即执行的,是由action算子触发任务执行后,当执行RDD的iterator方法并需要访问该缓存数据的时候,如果发现该RDD需要被缓存才会通过执行getOrCompute方法真正执行缓存操作,也就是说,缓存数据的写入是在第一次读取该缓存数据的时候执行的:
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
}
而数据缓存底层是通过执行BlockManger的doPutIterator方法来实现的,主要的代码片段如下:
if (level.useMemory) {
if (level.deserialized) {
memoryStore.putIteratorAsValues(blockId, iterator(), classTag) match {
case Right(s) =>
size = s
case Left(iter) =>
// Not enough space to unroll this block; drop to disk if applicable
if (level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
serializerManager.dataSerializeStream(blockId, out, iter)(classTag)
}...
}
} else { // !level.deserialized
memoryStore.putIteratorAsBytes(blockId, iterator(), classTag, level.memoryMode) match {
case Right(s) =>
size = s
case Left(partiallySerializedValues) =>
// Not enough space to unroll this block; drop to disk if applicable
if (level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
partiallySerializedValues.finishWritingToStream(out)
}...
}
}
} else if (level.useDisk) {
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
serializerManager.dataSerializeStream(blockId, out, iterator())(classTag)
}
size = diskStore.getSize(blockId)
}
val putBlockStatus = getCurrentBlockStatus(blockId, info)
val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid
if (blockWasSuccessfullyStored) {
// Now that the block is in either the memory or disk store, tell the master about it.
info.size = size
if (tellMaster && info.tellMaster) {
reportBlockStatus(blockId, putBlockStatus)
}
...
if (level.replication > 1) {
val remoteStartTimeNs = System.nanoTime()
val bytesToReplicate = doGetLocalBytes(blockId, info)
...
try {
replicate(blockId, bytesToReplicate, level, remoteClassTag)
} ...
以上代码的处理流程较为复杂,可见数据缓存的实现逻辑设计的非常精细,主要的处理过程如下:
1、根据存储级别判断,如果数据可以缓存在内存中:
1)如果数据不需要序列化存储:调用MemoryStore的putIteratorAsValues方法尝试数据将以JVM对象的方式缓存在内存的存储资源池中;如果存储到内存失败,并且根据存储级别数据可以存放在磁盘上,则并通过DiskStore的put方法将数据序列化并写入到磁盘文件中:
val ser = getSerializer(implicitly[ClassTag[T]], autoPick).newInstance()
ser.serializeStream(wrapForCompression(blockId, byteStream)).writeAll(values).close()
其中values是一个interator,其实现如下,可见实际的处理过程是先将已展开到内存中的记录序列化并写到磁盘文件中,然后释放已占用的存储内存;最后将尚未展开到内存中的记录执行序列化并写到磁盘文件中:
override def hasNext: Boolean = {
if (unrolled == null) {
rest.hasNext
} else if (!unrolled.hasNext) {
releaseUnrollMemory()
rest.hasNext
} else {
true
}
}
2)如果数据需要序列化存储:并通过调用MemoryStore的putIteratorAsBytes方法将数据序列化为二进制数组缓存在内存中;
如果写入内存失败,且根据存储级别缓存的数据可以存放在磁盘中,则首先将已经序列化到内存中的数据写到输出缓冲区,并释放展开内存所占用的存储内存,再将未展开到内存中的数据序列化后写到输出缓冲区中,最后刷写到磁盘文件中去:
ByteStreams.copy(unrolledBuffer.toInputStream(dispose = true), os)
memoryStore.releaseUnrollMemoryForThisTask(memoryMode, unrollMemory)
redirectableOutputStream.setOutputStream(os)
while (rest.hasNext) {
serializationStream.writeObject(rest.next())(classTag)
}
serializationStream.close()
2、如果根据存储级别该缓存数据只能存储在磁盘中:
则直接调用DiskStore的put方法将数据进行序列化后写入到磁盘文件中。
3、如果该block被成功缓存,则通过执行reportBlockStatus将该block的信息汇报给blockManagerMaster,而reportBlockStatus方法调用的正是我们前面介绍过的tryToReportBlockStatus方法。
4、根据存储级别判断,如果副本数大于1,则BlockManager根据blockId、需要分发的数据执行replicate方法再将该block的数据分发到(level.replication - 1)个非driver的BlockManager中,并且数据的分发是通过blockTransferService实现的:
val numPeersToReplicateTo = level.replication - 1
...
while(numFailures <= maxReplicationFailureCount &&
!peersForReplication.isEmpty &&
peersReplicatedTo.size < numPeersToReplicateTo) {
val peer = peersForReplication.head
try {...
val buffer = new BlockManagerManagedBuffer(blockInfoManager, blockId, data, false,
unlockOnDeallocate = false)
blockTransferService.uploadBlockSync(
peer.host,
peer.port,
peer.executorId,
blockId,
buffer,
tLevel,
classTag)
其中具体分发到哪些BlockManager上根据spark.storage.replication.policy配置项来指定(默认随机分发):
blockReplicationPolicy = {
val priorityClass = conf.get(config.STORAGE_REPLICATION_POLICY)
存储系统在Shuffle中的应用
Shuffle的过程中涉及shuffle文件的读写操作,这部分内容在《Spark Shuffle原理与源码解析》文章中有相关的讲解,下面从存储的角度再做一个简单的概括:
Shuffle文件的写入
1、在MapTask的内存溢写阶段,当内存不足时将内存中的shuffle数据溢写到临时磁盘文件中:
1)执行如下代码,通过DiskBlockManager创建临时文件和文件对应的blockId,并且由BlockManager构建了一个DiskBlockObjectWriter对象:
val (blockId, file) = diskBlockManager.createTempShuffleBlock()
...
val writer: DiskBlockObjectWriter =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)
2)执行DiskBlockObjectWriter的commitAndGet方法实现磁盘刷写:
def flush(): Unit = {
val segment = writer.commitAndGet()
batchSizes += segment.length
_diskBytesSpilled += segment.length
objectsWritten = 0
}
2、在合并溢写文件阶段,将所有的临时文件合并为一个data文件:
1)构建写磁盘文件的mapOutputWriter对象:
val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
dep.shuffleId, mapId, dep.partitioner.numPartitions)
在mapOutputWriter的构建过程中通过IndexShuffleBlockResolver创建出 .data文件,即首先根据shuffleId、mapId构建出.data文件的ShuffleDataBlockId,然后通过DiskBlockManager创建相应的磁盘文件:
def getDataFile(shuffleId: Int, mapId: Long, dirs: Option[Array[String]]): File = {
val blockId = ShuffleDataBlockId(shuffleId, mapId, NOOP_REDUCE_ID)
dirs
.map(ExecutorDiskUtils.getFile(_, blockManager.subDirsPerLocalDir, blockId.name))
.getOrElse(blockManager.diskBlockManager.getFile(blockId))
}
2)根据mapOutputWriter将对应mapId的临时溢写文件进行合并,然后将相关记录写到.data文件中:
sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
3、相应的.index文件的创建和落盘与.data文件类似,此处不再赘述。
4、shuffle write执行完成之后生成MapStatus对象,其中blockManager.shuffleServerId一般是指BlockManagerId,partitionLengths是在.index文中各个reduce分区对应的数据量,mapId是map任务的分区Id:
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId)
5、最后有DAGScheduler将该MapTask的结果信息登记到到作业的MapOutTracker中,用于后续的shuffle文件拉取:
case smt: ShuffleMapTask =>
...
val status = event.result.asInstanceOf[MapStatus]
...
mapOutputTracker.registerMapOutput(
shuffleStage.shuffleDep.shuffleId, smt.partitionId, status)
Shuffle文件的读取
1、首先根据shuffleId、reduceId从MapOutputTracker中获取该reduce分区所对应的所有shuffle文件的存储位置信息blocksByAddress,该对象的数据结构为Iterator[(BlockManagerId, Seq[(BlockId, Long, Int)])],包括所需数据的blockManagerId及对应的shuffle文件的blockId、blocksize、mapId等属性:
val blocksByAddress = SparkEnv.get.mapOutputTracker.getMapSizesByExecutorId(
handle.shuffleId, startMapIndex, endMapIndex, startPartition, endPartition)
2、然后根据blocksByAddress中的shuffle文件存储信息向各BlockManager获取shuffle记录:
1)如果shuffle文件在本地,则通过BlockManager在本地存储系统中获取相应的.data文件和.index文件,然后读取该reduce分区的shuffle记录;
2)如果shuffle文件存储在远端executor中,则由本地的NettyBlockTransferService向对应远端的BlockManager发送FetchShuffleBlocks RPC请求;对应远端的NettyBlockRpcServer接收到该请求后,从其本地存储系统中读取对应的shuffle记录并返回。
总结
Spark存储系统的重要组件包括:主节点BlockManagerMaster和从节点BlockManager,在主节点中维护了整个作业中所有BlockManager的元信息以及所有block的状态;从节点BlockManager定期或者当block发生变化时向BlockManagerMaster同步block的状态信息,并且提供了数据块的读写接口;
在BlockManager中,通过MemoryStore来管理存储在内存中的数据块,通过DiskStore来管理存储在文件系统中的数据块,并且由NettyBlockTransferService和NettyBlockRpcServer实例负责BlockManager之间的数据通信。
MemoryStore所管理的是存储内存部分的空间,将存储对象以MemoryEntry为单位存放在哈希链表中,当存储内存空间不足时则采用RLU的策略驱逐最近最少使用的数据块从而取得存储内存。
当内存空间不足并且数据块的存储级别支持磁盘存储的情况下发生磁盘溢写时、以及在写shuffle文件的情况下数据块是通过DiskStore来管理的,并且采用DiskBlockManager来创建和维护相关磁盘文件。
本文还介绍了MemoryStore以及DiskStore所提供的底层公共接口的实现原理,并且通过具体的场景:广播变量、Spark缓存以及shuffle文件读写的实现过程进一步解析了Spark存储系统的运行机制。
作者简介
焦媛,主要负责民生银行Hadoop大数据平台的生产运维工作,并负责HDFS和Spark相关开源产品的技术支持,以及Spark云原生技术的支持和推广工作。
