




我们已经熟悉了缓冲区缓存(共享内存的主要对象之一)的结构,并得出结论,当发生所有缓存内容丢失故障后,恢复必须要用到预写日志 (WAL)。
我们上次讲到的问题还没有解决,那就是我们不知道在恢复期间从哪里开始播放WAL记录。从一开始,正如 Lewis Caroll 的Alice的 King 所说的那样,从头开始不是一个好选择:不可能从服务器启动时就保留所有WAL记录—这可能会造成巨大的内存消耗和同样巨大的恢复时间。我们需要这样一个逐渐向前推进的点,并且我们可以从这些点开始恢复(并相应地安全地删除所有之前的 WAL 记录)。这就是(checkpoint)检查点。
检查点
检查点必须具备哪些功能?我们必须确保从检查点开始的所有 WAL 记录都将刷新到磁盘的页面。如果不是这样,在恢复期间,我们可能会从磁盘读取到太旧的页面版本,并应用到这些WAL记录,这样做会不可逆转地损坏数据。
我们怎样才能得到一个检查点?最简单的选择是不时的暂停系统的工作,并将缓冲区和其他缓存的所有脏页刷新到磁盘。(请注意,页面仅被写入,而不会从缓存中释放。)这些点将满足上述条件,但没有人会乐于使用间歇性暂停的系统,这些暂停是不确定的,但非常重要。
实际上,这有点复杂:检查点从一个点变成一个区间。首先我们启动一个检查点。之后,我们会悄悄地将脏缓冲区刷新到磁盘,而不会中断工作或尽可能不造成峰值负载。
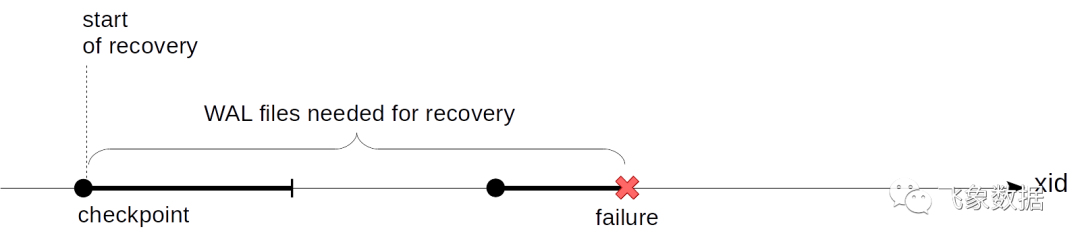
当检查点开始时间点上的所有的脏缓冲区都刷新磁盘上时,检查点被认为是已完成。现在(但不是更早),我们可以使用检查点开始时间点作为恢复开始的点。并且我们不再需这个时间点之前的 WAL 记录。
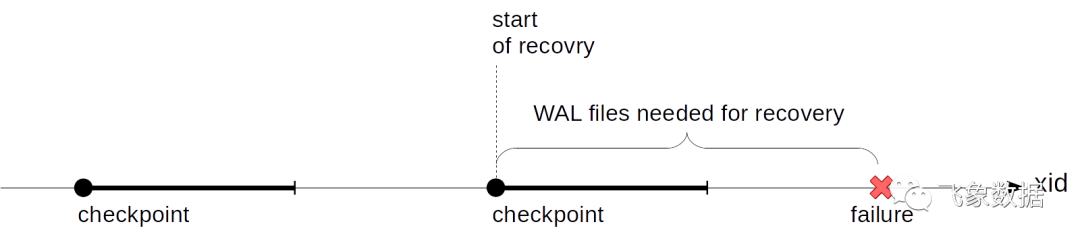
一个叫做 checkpointer
的后台进程执行检查点。
脏缓冲区落盘的持续时间由checkpoint_completion_target
参数值定义。它显示写入完成时两个相邻检查点之间的时间分数。默认值为0.5(如上图所示),也就是说,检查点之间的写入时间占一半。通常,该值会增加到0.9使得检查点负载更均匀。
0.9将成为PostgreSQL 14的默认值。
让我们更详细地说说执行检查点时发生了什么。
首先,checkpointer
将XACT缓冲区刷新到磁盘。因为他们很少(只有128个)。
然后开始执行主任务:刷新缓冲区缓存中的脏页面。但不能立即刷新所有页面,因为正如我们已经提到的,缓冲区缓存的大小可能很大。因此,所有当前脏页面都在缓冲区缓存中以头部中的特殊标志进行标记。
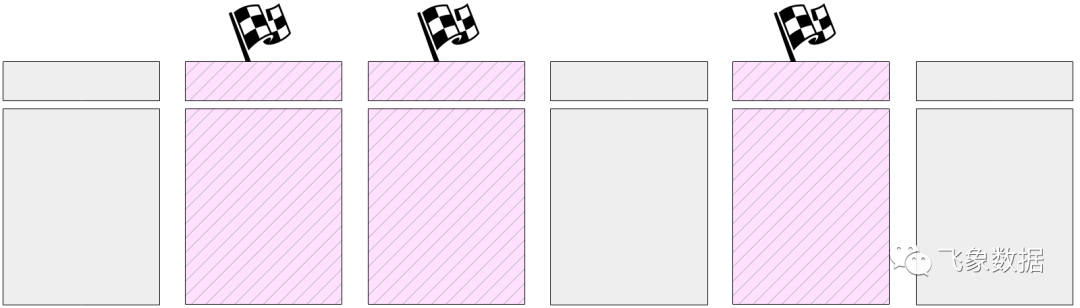
然后checkpointer
逐渐遍历所有缓冲区并将带有标记的缓冲区刷新到磁盘。需要提醒您的是,页面不会从缓存中删除,而是只写入磁盘;因此,您既不需要关注缓冲区的使用计数,也无需关注它是否被固定。
标记的缓冲区也可以由服务进程写入——以最先到达缓冲区的为准。无论如何,写操作会重置之前设置的标志,因此(为了检查点的目的)缓冲区将只被写入一次。
当然,在执行检查点时,缓冲区缓存中的页面会继续更改。但是新的脏缓冲区没有标记,并且checkpointer
不会写入它们。
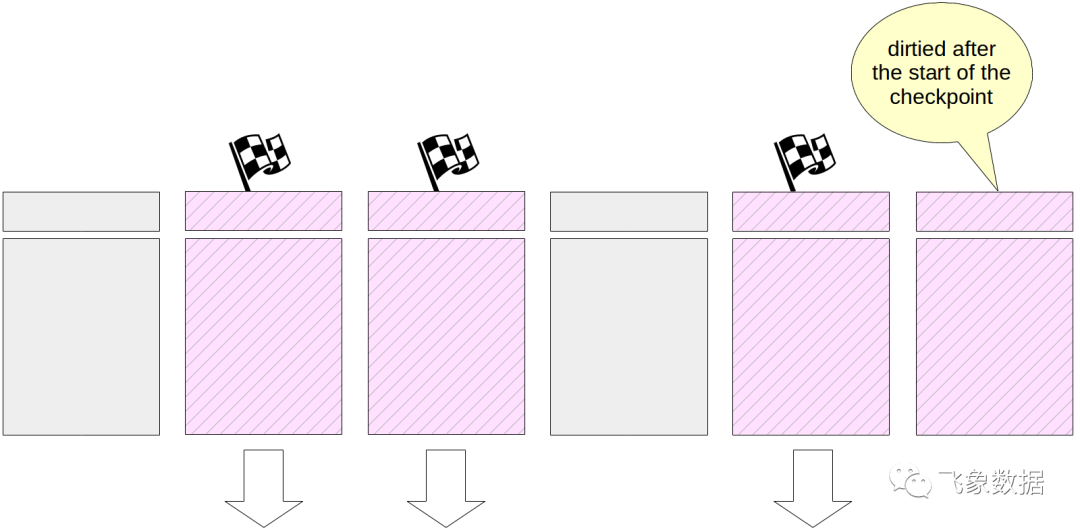
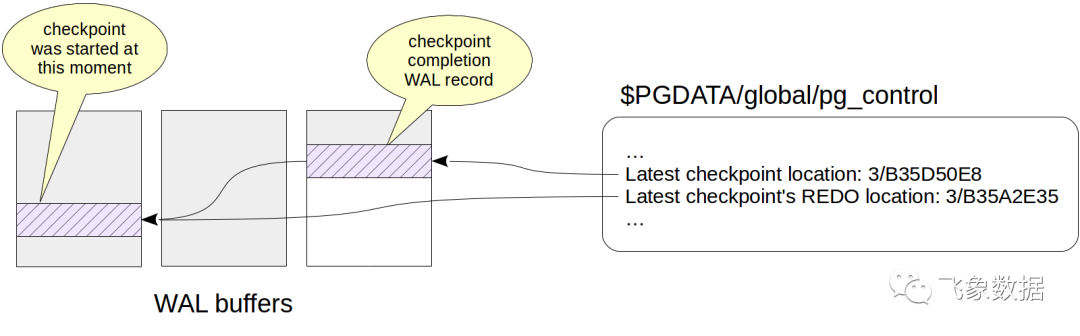
在其工作结束时,进程创建检查点结束时的WAL记录。该记录包含检查点开始时间的LSN。由于检查点在启动时不向WAL写入任何内容,因此任何日志记录都可以定位在这个LSN上。
此外,最后一个完成的检查点的标示在$PGDATA/global/pg_control
文件中更新。在检查点完成之前,pg_control
指向前一个检查点。
为了观察检查点的工作,让我们创建一个表;它的页面将进入缓冲区缓存,并且将是脏的:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n);=> CREATE EXTENSION pg_buffercache;=> SELECT count(*) FROM pg_buffercache WHERE isdirty;复制
count-------78(1 row)复制
让我们记住当前WAL的位置:
=> SELECT pg_current_wal_insert_lsn();pg_current_wal_insert_lsn---------------------------0/3514A048(1 row)复制
现在让我们手动执行检查点,以确保缓存中没有脏页(正如我们已经提到的,可能会出现新的脏页,但在实验中,执行检查点时没有任何变化):
=> CHECKPOINT;=> SELECT count(*) FROM pg_buffercache WHERE isdirty;count-------0(1 row)复制
让我们看看检查点是如何在WAL中体现的:
=> SELECT pg_current_wal_insert_lsn();pg_current_wal_insert_lsn---------------------------0/3514A0E4(1 row)复制
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4复制
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105复制
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online复制
我们在这里看到两个记录。最后一个是检查点完成的记录(CHECKPOINT_ONLINE
)。检查点开始的LSN在redo
之后输出,这个位置对应于检查点开始时最后的WAL记录。
我们会在控制文件中找到相同的信息:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'复制
Latest checkpoint location: 0/3514A07CLatest checkpoint's REDO location: 0/3514A048复制
恢复
现在,我们准备更准确地陈述前一篇文章中概述的恢复算法。
如果服务失败,在随后的启动中,启动进程通过查看pg_control
文件来发现状态与“关闭”不同。在这种情况下自动恢复。
首先,恢复进程将从同一个pg_control
文件中读取检查点开始位置。(为了完成这一过程,请注意,如果backup_label
文件可用,那么将从那里读取检查点记录——这是从备份中恢复所需要的,但这是一个单独系列文章的主题。)
然后,流程将从找到的位置开始读取WAL,并将WAL记录一个接一个地应用到页面上。
最后,所有不记日志表都被其初始化分叉清空。
这是启动进程完成其工作的地方,checkpointer
进程立即执行检查点,以保护磁盘上恢复的状态。
我们可以通过在immediate
模式下强制关闭服务来模拟故障。
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect复制
(这里需要——skip-systemctl-redirect
选项,因为我们使用从Ubuntu包中安装的PostgreSQL。它由pg_ctlcluster
命令控制,该命令实际上调用systemctl
,而systemctl
又调用pg_ctl
。由于所有这些包,模式的名称在过程中丢失了。但是--skip-systemctl-redirect
选项使我们能够不使用systemctl
并保留重要信息。)
让我们来检查一下集群的状态:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep stateDatabase cluster state: in production复制
在开始时,PostgreSQL知道发生了故障,需要进行恢复。
student$ sudo pg_ctlcluster 11 main start复制
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log复制
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A0482019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 02019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet复制
在消息日志中报告了恢复的需要:"database system was not properly shut down; automatic recovery in progress"。然后,在“redo starts at 0/3514A048”位置开始播放WAL记录,并在可能获得下一条WAL记录时继续播放。在“redo done at 0/3514A07C”位置完成恢复,DBMS开始与客户端一起工作(数据库系统已经准备好接受连接)。
服务器正常关闭时会发生什么?为了将脏页面刷新到磁盘,PostgreSQL断开所有客户端连接,然后执行最后的检查点。
让我们记住当前WAL的位置:
=> SELECT pg_current_wal_insert_lsn();pg_current_wal_insert_lsn---------------------------0/3514A14C(1 row)复制
现在我们以常规方式关闭服务器:
student$ sudo pg_ctlcluster 11 main stop复制
让我们检查一下集群状态:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state复制
Database cluster state: shut down复制
WAL有最后一个检查点(CHECKPOINT_SHUTDOWN)的唯一记录:
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C复制
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown复制
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0复制
(通过致命(FATAL)错误消息pg_waldump
只想告诉我们它将WAL读到了最后。)
让我们再次运行实例。
student$ sudo pg_ctlcluster 11 main start复制
后台写进程
正如我们所知道的,检查点是将脏页面从缓冲区缓存刷新到磁盘的进程之一,但不是唯一的一个。
如果后端进程需要从缓冲区刷新页面,但该页面看起来脏了,则该进程必须在磁盘上写入该页面。这种情况是不好的,因为它需要等待——在后台异步完成写操作会更好。
因此,除了checkpointer
进程之外,还有后台写(background writer
)进程(也称为bgwriter或简称writer)。此过程使用与逐出技术相同的算法来搜索缓冲区。最终有两个区别。
使用writer自己的指针,而不是指向
next victim
的指针。它可以在指针指向victim
的前面,但不能在后面。在遍历缓冲区时,使用计数不会减少。
对于这些缓冲区,所有这些都是正确的:
它们包含更改的数据(脏数据)。
它们没有固定(固定计数= 0)。
它们的使用计数为0。
background writer
进程会在逐出之前运行找到那些更容易被收回的缓冲区。因此,理想情况下,后端(backend
)进程必须能够检测它们选择的缓冲区是否可以使用,而不会在写操作上浪费时间。
调整
checkpointer
的设置通常基于以下原因。
首先,我们需要确定在两个随后的检查点之间可以保留多少WAL记录(以及我们可以接受的恢复时间)。越多越好,但由于明显的原因,这个值是有限的。
然后我们可以计算在正常负载下生成该量所花费的时间。我们已经讨论了如何做到这一点(我们需要记住WAL中的位置并从中减去一个位置)。
这将是我们检查点之间通常的间隔时间。我们将其写入checkpoint_timeout
参数。默认值为5分钟,这显然太少了;这个时间通常会增加,比如说,增加到半小时。重申一下:我们能负担得起的检查点频率越低越好——这会降低间接成本。
但是有可能(甚至很有可能),有时候负载会比平时高,并且在参数中指定的时间内会生成大量的WAL记录。在这种情况下,需要更频繁地执行检查点。为此,我们在max_wal_size
参数中指定允许的WAL文件总量。如果实际数量更大,pg将发起计划外检查点。
pg需要保留在最后一个完成的检查点开始时刻的WAL文件,加上当前检查点期间累积的文件。因此,总数量可以估计为一个检查点周期中的数量乘以(1 + checkpoint_completion_target
)。在版本11之前,我们应该乘以(2 + checkpoint_completion_target
),因为PostgreSQL还保留了最后一个检查点的文件。
因此,大多数检查点都按计划执行:每个checkpoint_timeout
时间单位执行一次。但是在负载增加的情况下,当达到max_wal_size
的数量时,执行检查点的频率会更高。
重要的是要了解max_wal_size
参数的值可能会被超过:
max_wal_size
参数的值只是所需的值,而不是严格的限制。可能会更大。如果已经进行了连续归档,那么pg就不能删除还没有通过复制槽并且还没有归档的WAL文件。如果使用此功能,则需要持续监视以避免服务器内存变满。
要完成目标,不仅可以指定最大值,还可以通过min_wal_size
参数指定最小值。此设置的目的是,当文件量达到min_wal_size
时,pg不会删除文件,而只会重命名和重用文件。这允许在连续创建和删除文件时进行保存。
只有在调优checkpointer
时调整background writer
才是有意义的。在后端进程需要脏缓冲区之前,这些进程必须一起设法写入脏缓冲区。
background writer
在bgwriter_lru_maxpages
的最大轮数下工作,并在轮数之间休眠bgwriter_delay
时间单位。
一轮中要写入的页面数由从上一轮开始的后端进程请求的平均缓冲区数确定(这里使用移动平均值来消除轮之间的不一致性,但不依赖于遥远的值)。计算出的缓冲区数乘以bgwriter_lru_multiplier
系数(但无论如何都不会大于bgwriter_lru_maxpages
)。
默认值是:bgwriter_delay = 200 ms(很可能,太多了),bgwriter_lru_maxpages = 100, bgwriter_lru_multiplier = 2.0(让我们尝试提前响应需求)。
如果进程根本没有找到脏缓冲区(即系统中没有发生任何事情),那么它将“进入休眠状态”,当服务进程请求缓冲区时,它将进入休眠状态。醒来后,这个过程又恢复了正常。
监控
您可以且需要根据监控反馈调整checkpointer
和background writer
。
如果过多地执行超过WAL文件数量所导致的检查点,checkpoint_warning
参数将输出一个警告。它的默认值是30秒,我们需要将其调整为checkpoint_timeout
的值。
log_checkpoints
参数(在默认情况下是关闭的)使我们能够从pg的消息日志中获得正在执行的检查点的信息。让我们打开它。
=> ALTER SYSTEM SET log_checkpoints = on;=> SELECT pg_reload_conf();复制
现在让我们更改数据中的一些内容并执行检查点。
=> UPDATE chkpt SET n = n + 1;=> CHECKPOINT;复制
在消息日志中,我们将看到如下信息:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB复制
我们可以在这里看到写入了多少缓冲区,在检查点之后,WAL文件的集合是如何改变的,执行检查点需要多长时间,相邻检查点之间的距离(以字节为单位)是多少。
但是最有用的信息可能是pg_stat_bgwriter
视图中checkpointer
和background writer
进程的统计信息。视图是两个进程共享的,因为以前一个进程执行两个任务,然后职责被划分,但视图仍然存在。
=> SELECT * FROM pg_stat_bgwriter \gx复制
-[ RECORD 1 ]---------+------------------------------checkpoints_timed | 0checkpoints_req | 1checkpoint_write_time | 1checkpoint_sync_time | 13buffers_checkpoint | 79buffers_clean | 0maxwritten_clean | 0buffers_backend | 42buffers_backend_fsync | 0buffers_alloc | 363stats_reset | 2019-07-17 15:27:49.826414+03复制
这里,我们可以看到执行的检查点的数量:
checkpoints_timed
— 按计划(到达checkpoint_timeout
时)。checkpoints_req
— 按需(包括在达到max_wal_size
时执行的那些)。
较大的checkpoint_req
值(与checkpoints_timed
值相比)表明检查点出现的频率高于预期。
以下是关于写入页数的重要信息:
buffers_checkpoint
- 由checkpointer
。buffers_backend
— 通过后端进程。buffers_clean
- 由background writer
。
在一个调优的系统中,buffers_backend
的值必须比buffers_checkpoint
和buffers_clean
的和小得多。
maxwritten_clean
的值还有助于调优background writer
。它显示了进程由于超过bgwriter_lru_maxpages
的值而停止的次数。
您可以在调用中重置收集的统计信息:
=> SELECT pg_stat_reset_shared('bgwriter');复制



