







在介绍HashJoin实现之前,首先了解下什么是 JOIN。根据维基百科(WIKIPedia),JOIN是关系数据库中组合一个或者多个表中的columns的算子。

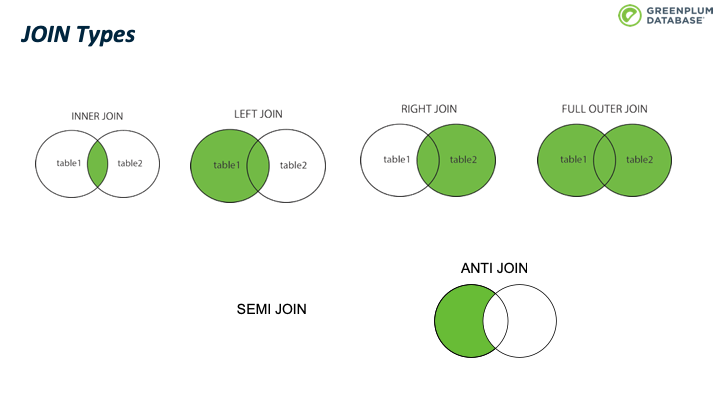
而JOIN 有多种类型, SQL 标准中定义了 INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOIN 等四种类型,用集合论里的操作非常容易理解。我们在下图直观的解释了这四种JOIN类型的效用。
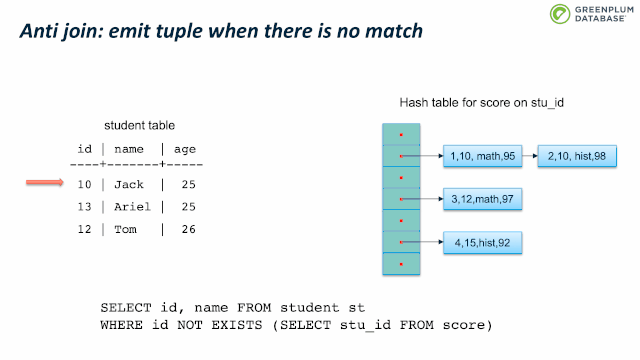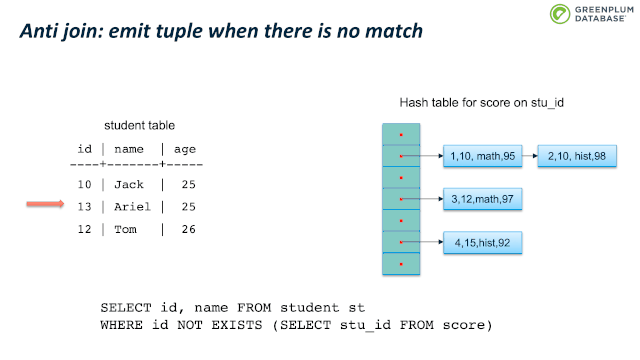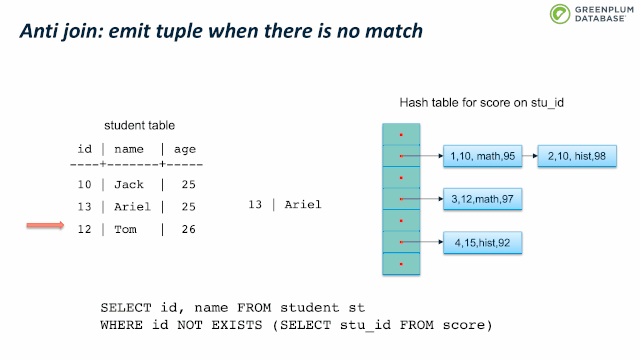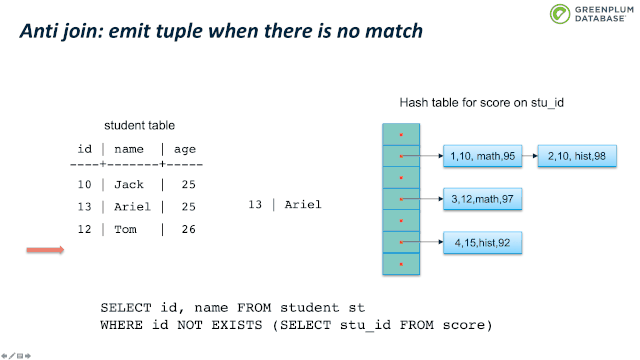
此外还有其中JOIN类型,譬如 SEMI JOIN和 ANTI JOIN。这两种JOIN不是 SQL 语法,然而通常用来实现某些 SQL 功能,后面会详细介绍他们。
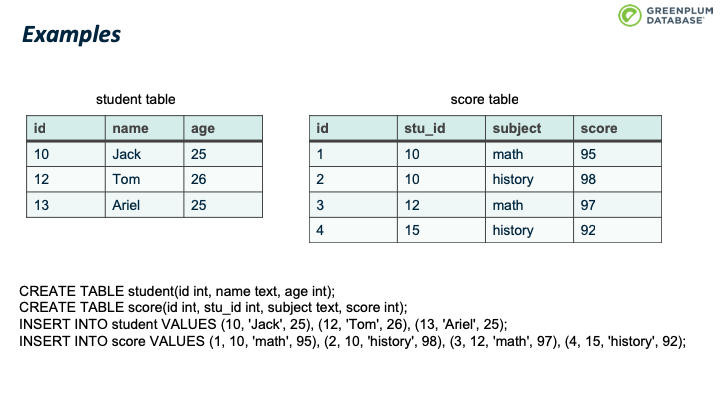
本文将使用这样一个例子。例子里面包含两张表:student表和score表,每张表都有几条记录。

下图展示了查询结果,让我们对图中JOIN的作用有个直观的认知。

JOIN 有三种经典的实现算法:Nested Loop、Merge JOIN、Hash Join。他们各有优缺点,譬如 Nest loop 通常性能不好,但是适用于任何类型的JOIN;Merge join对预排序的数据性能非常好;HashJoin对大数据量通常性能最好,但是只能处理equijoin,而不能处理譬如 c1 > c2 这样的join条件。



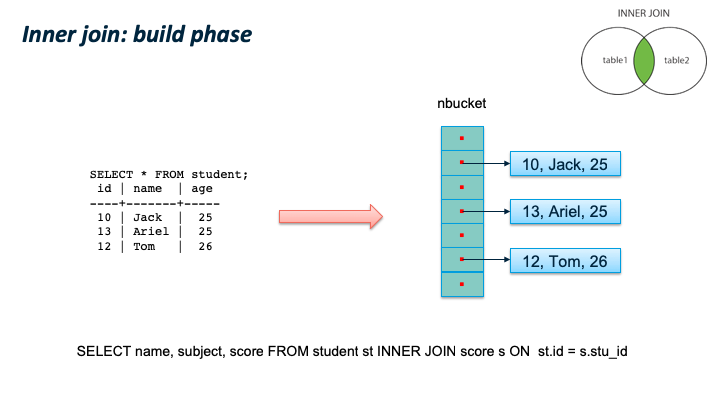
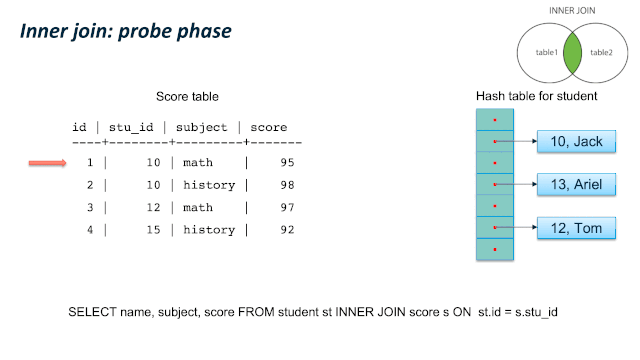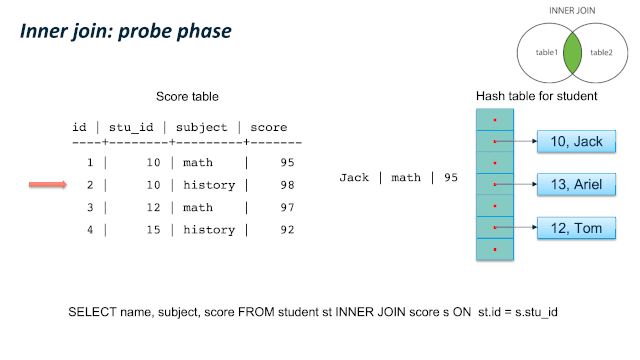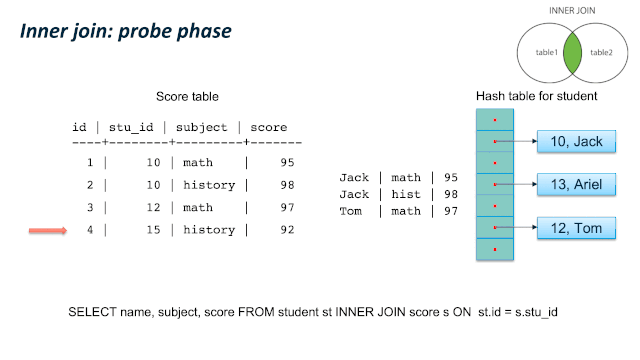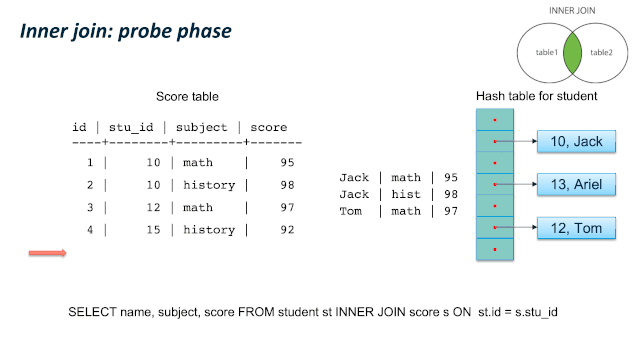
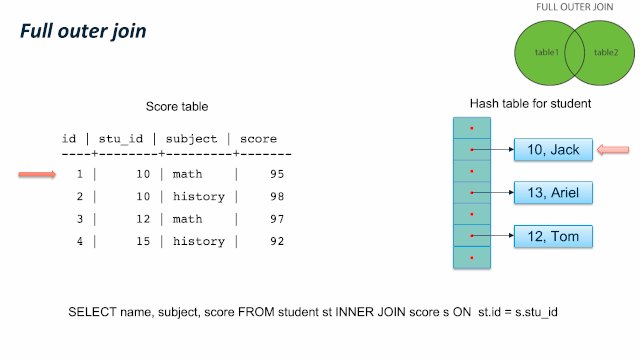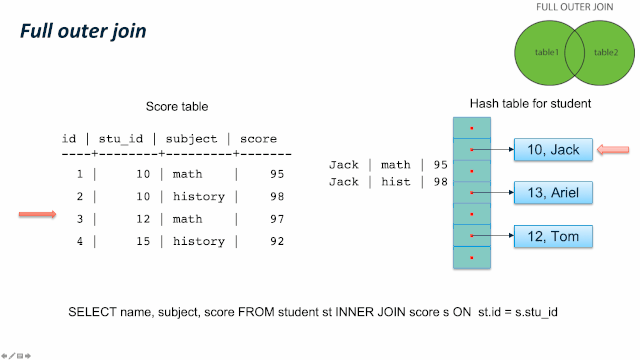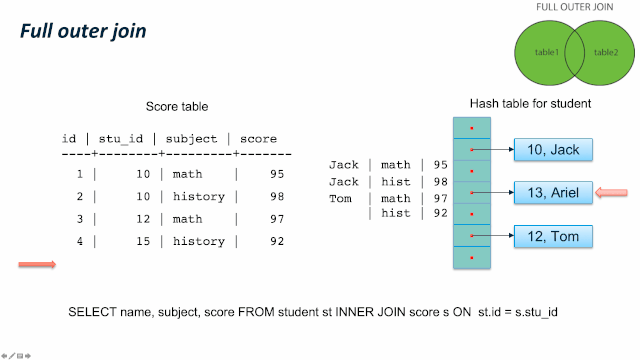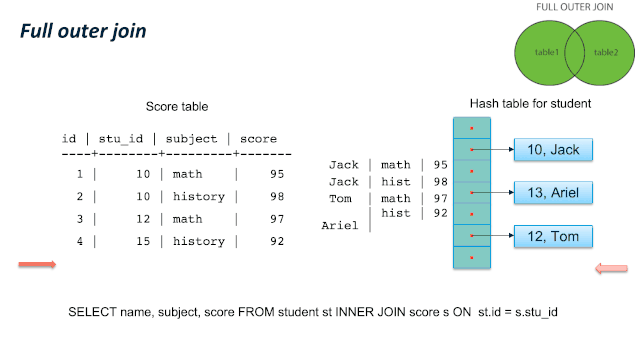
这儿有个比较容易混淆的地方:JOIN 类型的SQL语义和 JOIN的内部实现类型。我们通过一个例子来看,同样是 LEFT JOIN的两个 SQL,内部可以使用 Hash Left JOIN 或者 Hash Right Join。第一个例子是一张大表left join一张小表,它的内部是实现JOIN类型是 Left join;第二个例子是一张小表 left join一张大表,它的内部实现JOIN类型是 right join。原因是优化器尽量选择小表做内表,在其上构建hashtable。

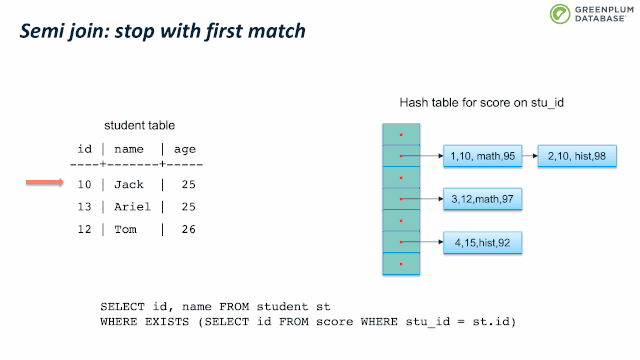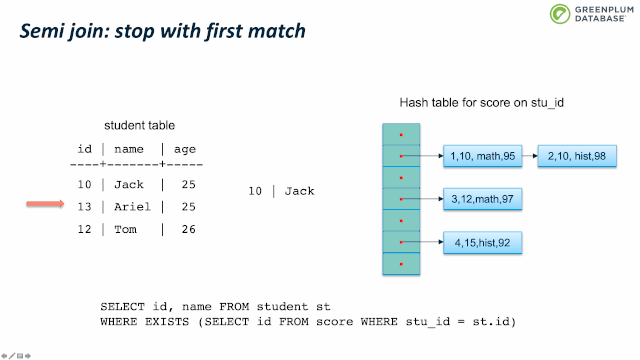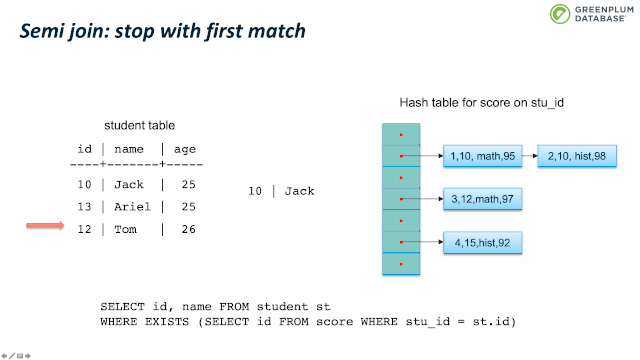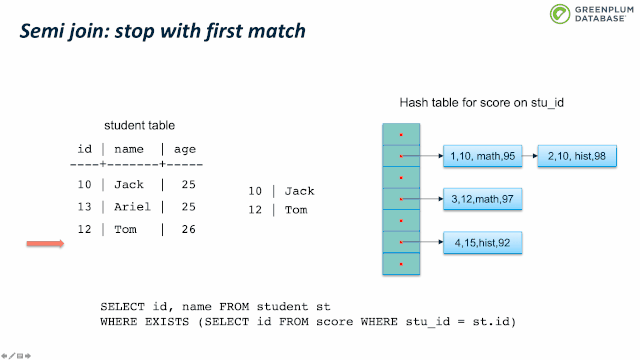
下面我们来看看 semi join。Semi join 通常用来实现 EXISTS。它和 inner join类似,不同支持是 semi join 只关心有没有匹配,而不关心有多少元组匹配。
bucketno = hashvalue MOD nbuckets
nbuckets 是buckets的个数,nbatch是batch的个数,两者都是2的幂,这样可以通过位运算获得 bucketno和batchno
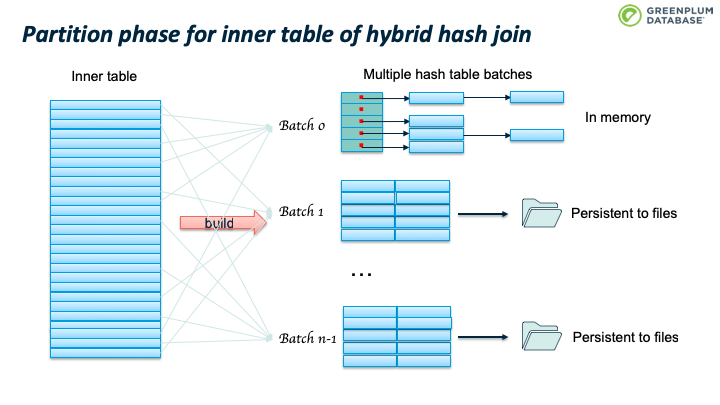
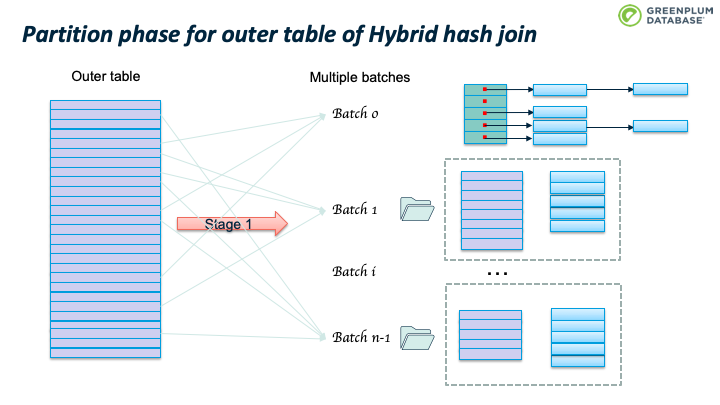
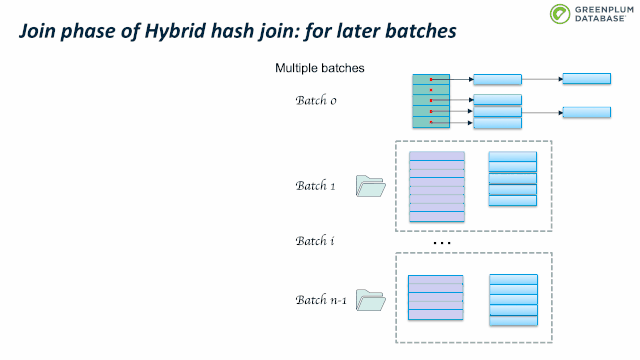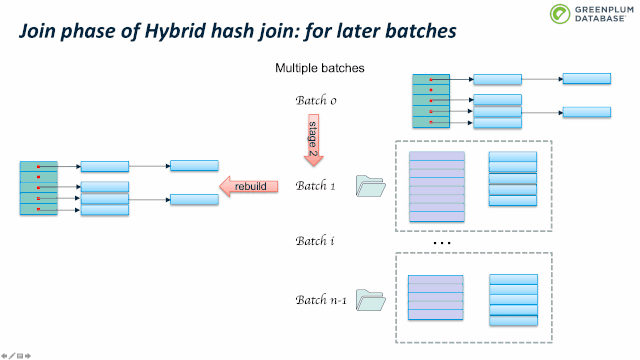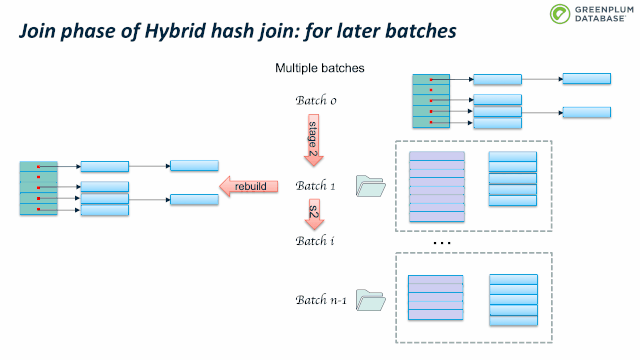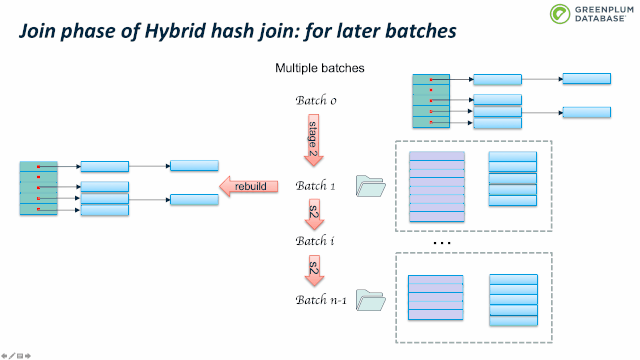
Outer table 扫描结束时, batch 0也处理完了。继续处理 batch 1:加载 batch 1 的inner table临时数据到内存中,构建hashtable,然后扫描batch 1 的outer table临时数据,执行前面跳到的probe 操作。完成batch 1 后,继续处理 batch 2,直到完成所有的batches。
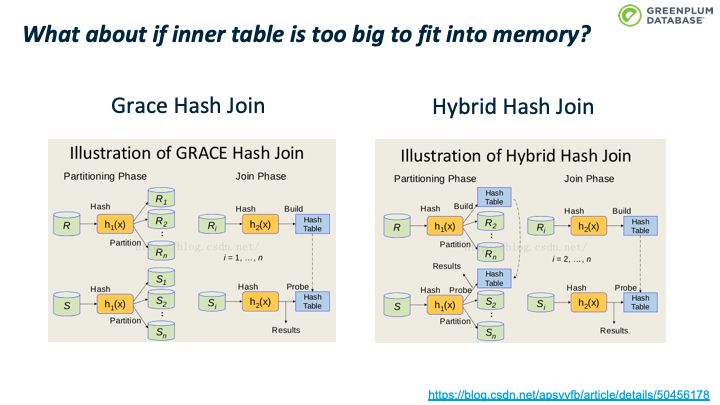
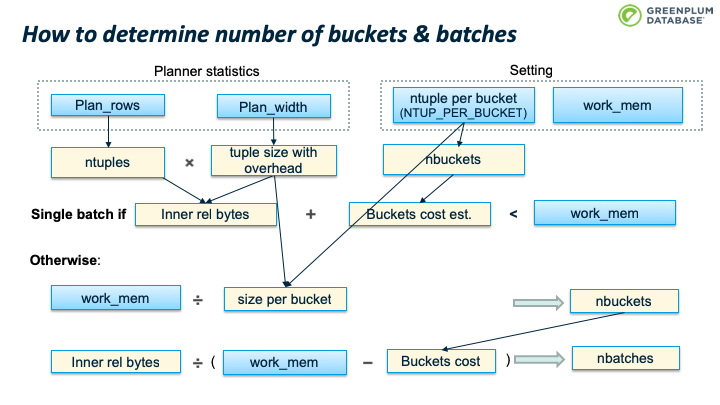
下面这张图介绍了如何判断是否需要多个batch:如果inner table 的大小加上 buckets 的开销小于 work_mem,则使用单个batch;否则需要使用多个batches。
算法的输入:
Plan_rows:预估的inner table 的行数
Plan_width:预估的inner table 的平均行宽
NTUP_PER_BUCKET:单个bucket的tuples数据,老版本这个数值是10,新的版本是1,假设hash冲突很少,平均一个bucket 含有一个 tuple
Work_mem:为hashjoin分配的内存配额
那么如果 batch 0 仍然太大,内存不足以容纳怎么办?
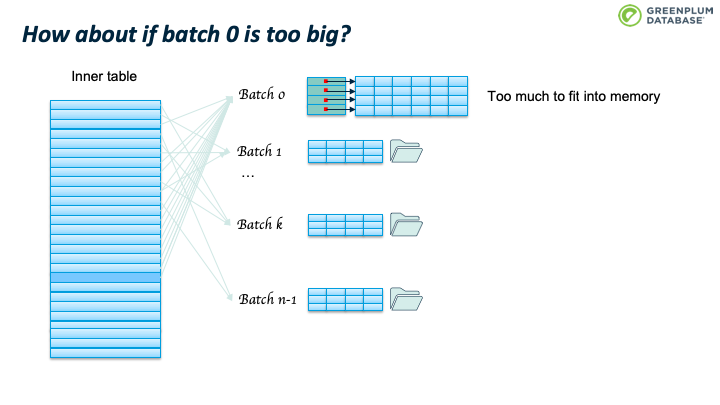
办法是batches个数翻倍,从n变成2n。这时会重新扫描 batch 0里面的tuples,根据2n重新计算其所属的batch,如果仍然属于batch 0,则保留在内存中,否则从内存中移除,写入到tuple对应的新batch中。
此时不会移动 Batch 文件中的已有的tuple,当处理该 batch 时会进行处理。
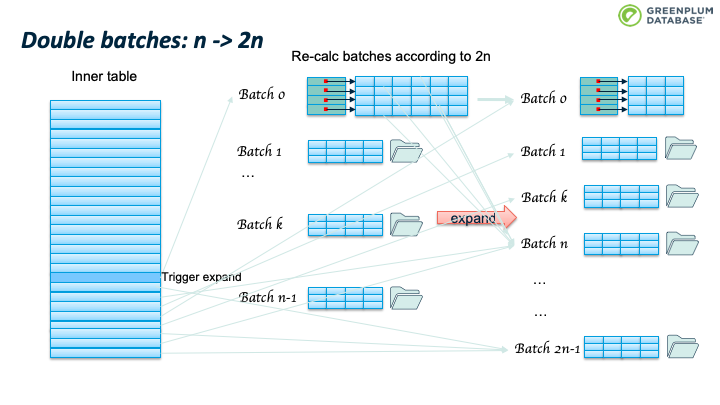
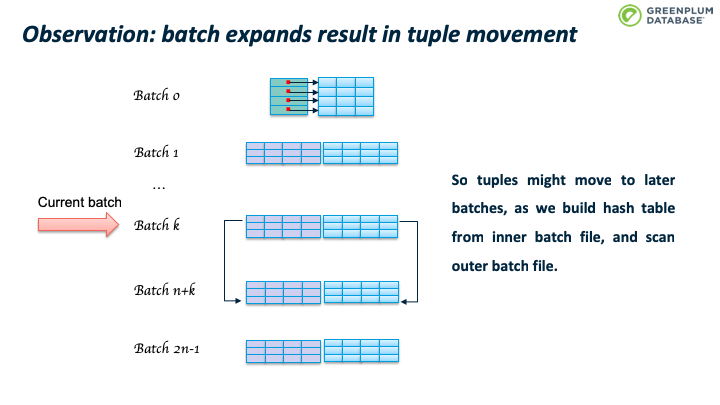
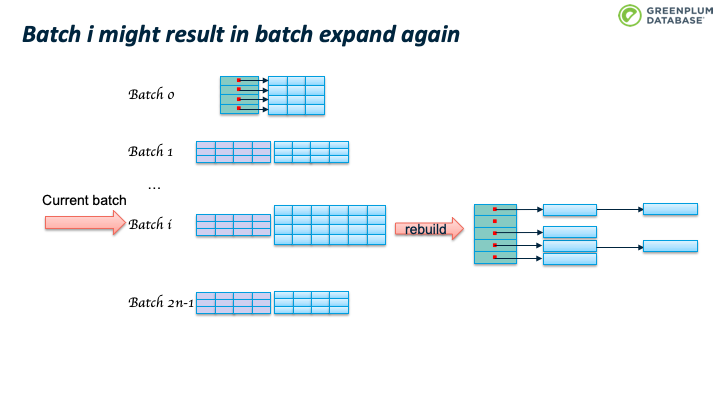
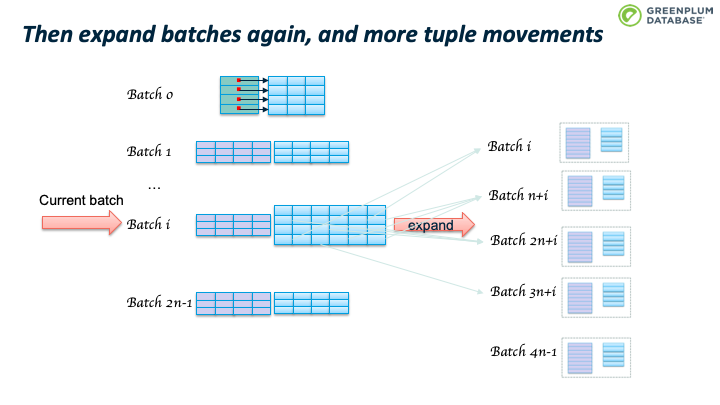
这会造成 batch 数目继续翻番。如下图所示。
当前batch里的tuple所属的batchno也会变化。举一个具体例子,假设 Nbatch = 10; 2次翻番后,Nbatch = 40;batch 3 中已有的tuple满足 hashvalue % 10 = 3, 所以batch 3 中的tuple的hashvalue可能是 3, 13, 23, 33, 43, 53, … 当 nbatch从10变为40时,hashvalue % 40 可能的结果是3, 13, 23, 33。
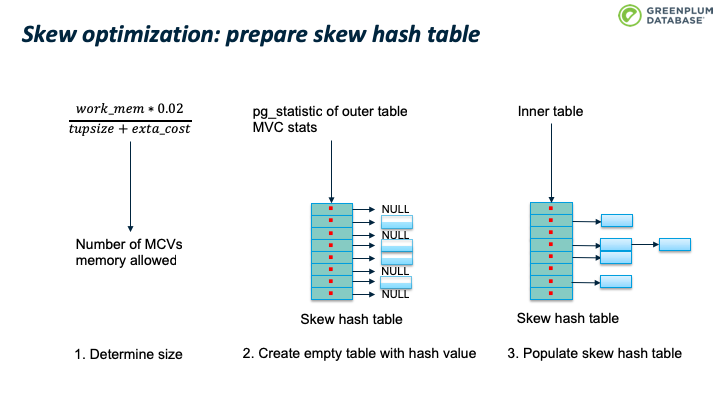
PostgreSQL 的hashjoin实现在经典的 Hybrid hash join之上还做了一些优化,一个重要的优化是对倾斜数据的优化。现实中的数据很多是非正态分布的数据,譬如宠物,假设地球上每个人都有一个宠物,那么养猫或者养狗的人会占据大多数。
Skew优化的核心思想是尽量避免磁盘io:在 batch 0阶段处理outer table最常见的 (MCV,Most common value) 数据。选择 outer table 的MCV而不是inner table的 MCV的原因是优化器通常选择小表和正态分布的表做 inner table,这样outer table会更大,或者更大概率是非正态分布。




首先介绍下Greenplum。Greenplum 本质上是很多 PostgreSQL 节点组成的集群,然而单单把很多PostgreSQL节点放在一起,不能给用户提供一个透明的,满足ACID的逻辑数据库。

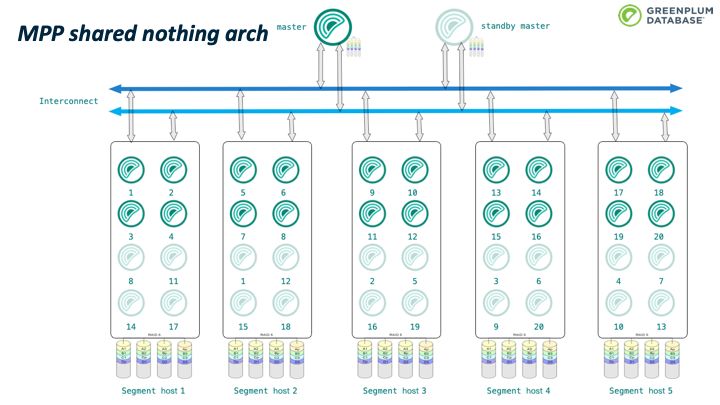
Greenplum 有两个关键概念:
1.分布策略:控制每个tuple保存在那个segment上,目前支持hash分布、随机分布、复制表,也支持自定义
2.Motion:在不同的segments之间传输数据,有三种方式:Gather,重分布和广播

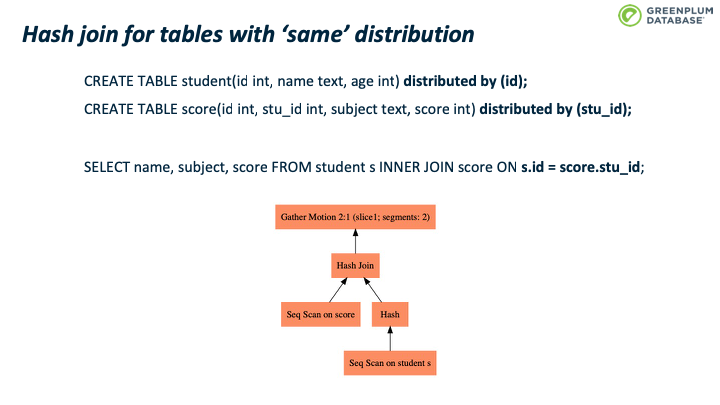
这个例子里student表按照学生id分布数据到不同segments,而 score 表按照score 表的id分布数据到不同segments上,这样同一个学生的score 信息可能分布在不同的节点上,所以上页图片的查询计划会产生错误结果。为了解决这个问题,查询计划中引入了一个 Broadcast motion。这样 Hashjoin node 的outer node是一个广播motion节点,所以可以得到outer table 的全量数据,保证hashjoin的结果是正确的。

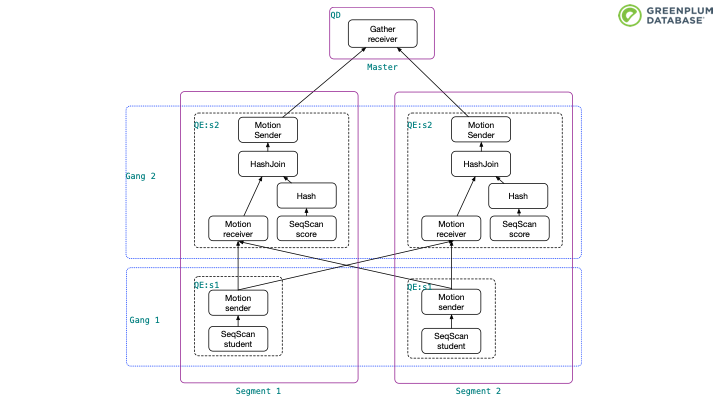
可见单节点的 PostgreSQL 和并行数据库Greenplum在hashjoin的执行层面都是基于 Hybrid hash join 算法,执行器层面实现细节几乎没有什么不同,主要修改在于优化器层面。其他并行数据库如 CitusDB 也是如此。


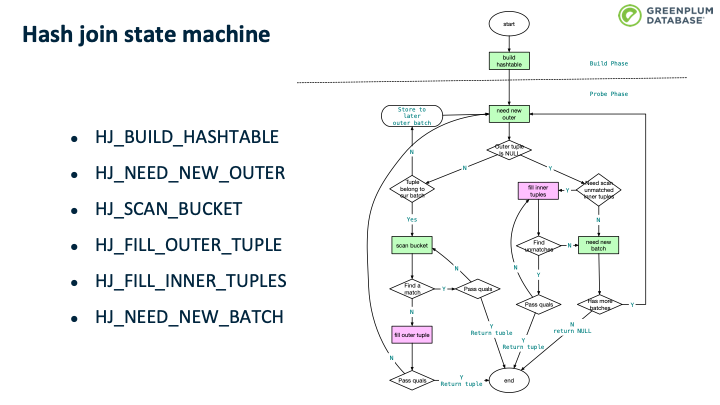
主要的代码逻辑在 execHashJoin() 中,该函数实现了一个状态机,其中有6个主要状态,状态变换大体如上上图所示,仅做参考。

I Love PG
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:PG分会)于2017年成立,由国内多家PG生态企业所共同发起,业务上接受工信部产业发展研究院指导。PG分会致力于构建PG产业生态,推动PG产学研用发展,是国内一家PG行业协会组织。
技术文章精彩回顾 PostgreSQL学习的九层宝塔 PostgreSQL职业发展与学习攻略 搞懂PostgreSQL数据库透明数据加密之加密算法介绍 一文读懂PostgreSQL-12分区表 PostgreSQL源码学习之:RegularLock Postgresql源码学习之词法和语法分析 PostgreSQL buffer管理 最佳实践—PG数据库系统表空间重建 PostgreSQL V12中的流复制配置 2019,年度数据库舍 PostgreSQL 其谁? PostgreSQL使用分片(sharding)实现水平可扩展性 一文搞懂PostgreSQL物化视图 PostgreSQL原理解析之:PostgreSQL备机是否做checkpoint PostgreSQL复制技术概述 PG活动精彩回顾 见证精彩|PostgresConf.CN2019大会盛大开幕 PostgresConf.CN2019大会DAY2|三大分论坛,精彩不断 PostgresConf.CN2019培训日|爆满!Training Day现场速递! 「PCC-Training Day」培训日Day2圆满结束,PCC2019完美收官 创建PG全球生态!PostgresConf.CN2019大会盛大召开 首站起航!2019“让PG‘象’前行”上海站成功举行 走进蓉城丨2019“让PG‘象’前行”成都站成功举行 中国PG象牙塔计划发布,首批合作高校授牌仪式在天津举行 PostgreSQL实训基地落户沈阳航空航天大学和渤海大学,高校数据库课改正当时 群英论道聚北京,共话PostgreSQL 相聚巴厘岛| PG Conf.Asia 2019 DAY0、DAY1简报 相知巴厘岛| PG Conf.Asia 2019 DAY2简报 相惜巴厘岛| PG Conf.Asia 2019 DAY3简报 独家|硅谷Postgres大会简报 全球规模最大的PostgreSQL会议等你来! PG培训认证精彩回顾 关于中国PostgreSQL培训认证,你想知道的都在这里! 首批中国PGCA培训圆满结束,首批认证考试将于10月18日和20日举行! 中国首批PGCA认证考试圆满结束,203位考生成功获得认证! 中国第二批PGCA认证考试圆满结束,115位考生喜获认证! 请查收:中国首批PGCA证书! 重要通知:三方共建,中国PostgreSQL认证权威升级! 一场考试迎新年 | 12月28日,首次PGCE中级认证考试开考! 近500人参与!首次PGCE中级、第三批次PGCA初级认证考试落幕!

