




关于Oracle绑定变量

摘自——Oracle 11g concept 中英文对照版
使用了绑定变量能提高性能主要是因为这样做可以尽量避免不必要的硬解析而节约了时间,同时节约了大量的CPU资源。
绑定变量的本质就是本来需要做Oracle 硬解析的SQL 变成软解析,以减少ORACLE 花费在SQL解析上的时间和资源。
简单的说,绑定变量就是拿一个变量来代替谓词常量,让Oracle每次对用户发来的SQL做hash 运算时,运算出的结果都是同样的Hash值,于是将所有的用户发来的SQL看作是同一个SQL来对象。
假如有两条SQL:
Select salary from user where name=’A’;
Select salary from user where name=’B’;
如果没有用绑定变量,那么这2条SQL 会被解析2次,因为他们的谓词部分不一样。 如果我们用了绑定变量,如:
Select salary from user where name=:X;
这时,之前的2条SQL就变成了一种SQL, Oracle 只需要对每一种SQL做一次硬解析,之后类似的SQL 都使用这条SQL产生的执行计划,这样就可以大大降低数据库花费在SQL解析上的资源开销。 这种效果当SQL执行的越多,就越明显。
测试如下图:
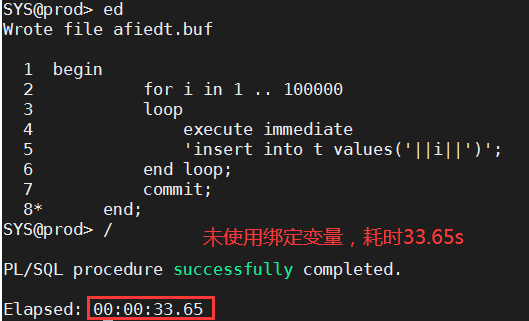
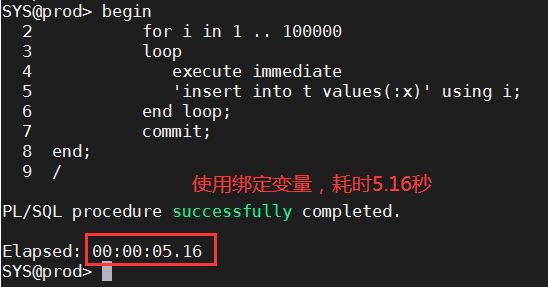
绑定变量在OLAP系统和OLTP系统
在OLAP系统中,不需要使用绑定变量,因为整个系统的执行量很小,分析时间对于执行时间来说,可以忽略,而且可避免出现错误的执行计划。但是OLAP中可以大量使用位图索引,物化视图,对于大的事务,尽量寻求速度上的优化,没有必要像OLTP要求快速提交,甚至要刻意减慢执行的速度。
对于OLAP系统中的绑定变量,有以下原则:
(1)OLAP 系统完全没有必要绑定变量,那样只会带来负面的影响,比如导致SQL选择错误的执行,
这个代价有时是灾难性的;让Oracle对每条SQL做硬分析,确切的知道谓词条件的值,这对执行计划的选择至关重要,这样做的原因是,在OLAP系统中,SQL硬分析的代价是可以忽略的,系统的资源基本上是用于做大的SQL查询,和查询比起来,SQL解析消耗的资源显得微不足道。所以得到一个最优的执行计划就非常重要。
(2)在OLAP系统中,让Oracle确切地知道谓词的数值至关重要,它直接决定了SQL执行计划的选择,这样做的方式就是不要绑定变量。
(3)在OLAP系统中,表,索引的分析显得直观重要,因为它是Oracle 为SQL做出正确的执行计划的信息的来源和依据,所以需要建立一套能够满足系统需求的对象分析的执行Job。
结论:如果Oracle中有大量的类似sql,基本结构一样,但是条件的取值不一样,那么,应该采用绑定变量的方法,来减少sql的硬解析。因此绑定变量真正的用途是在OLTP系统中,这个系统通常有这样的特点,用户并发数很大,用户的请求十分密集,并且这些请求的SQL 大多数是可以重复使用的。
评论

 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞