上篇是MySQL的这篇是Oracle的。总体来说差不多,不一样的地方我会标出来。
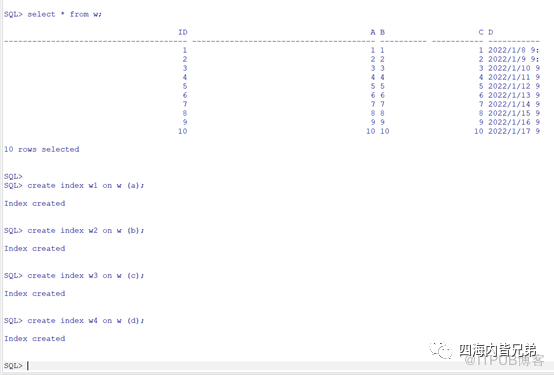
先创建一个表,写入10条数据。 (MySQL5条就行,Oracle10条其实都不行。原因是Oracle处理觉得10条数据有没有索引一样。所以我最后是写入了1万条数据)

分别建立索引
同时把T表也建立好。完全和MySQL场景一样。
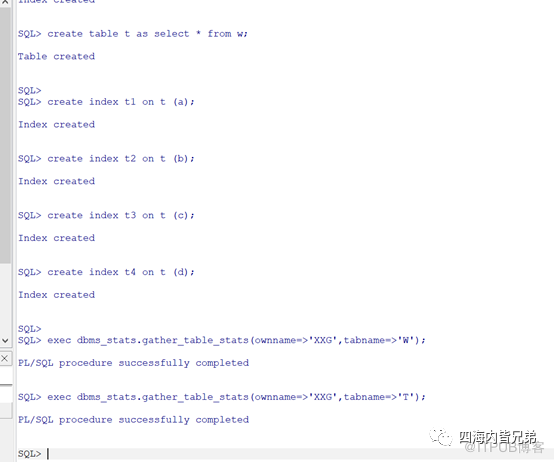
然后为了更好的体现,对两个表都收集一下统计信息。
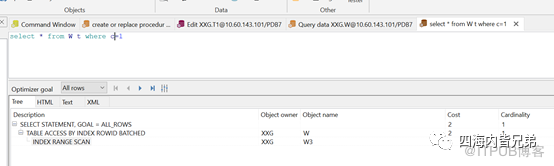
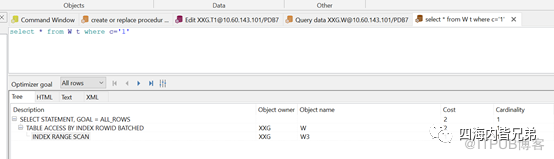
接下来看结果。a列是数值型的用到索引。
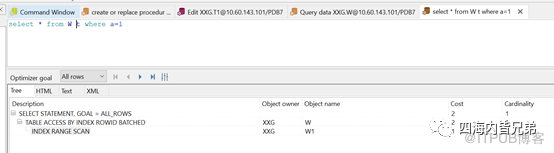
a列是数值型的,遇到字符自动转换了。
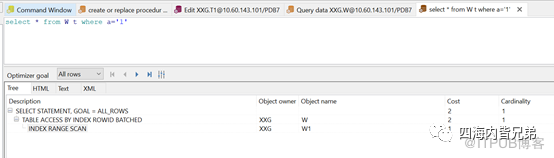
B列是字符型的,只能是字符型才能用到索引。
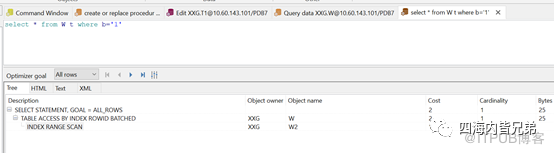
B列是字符型的,数值型的不能用到索引。
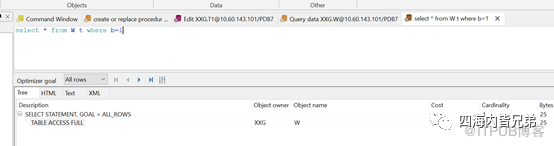
C列是小数型的,照搬数值型规则。都是可以的。
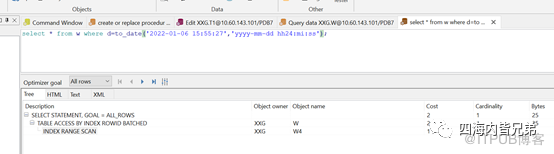
D列是时间,用时间的写法。
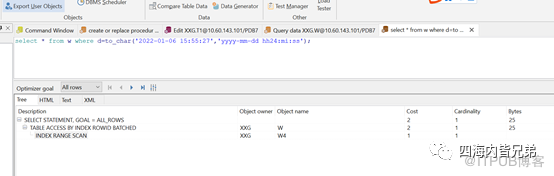
如果用字符串,执行计划可以,但是实际执行是报错的。
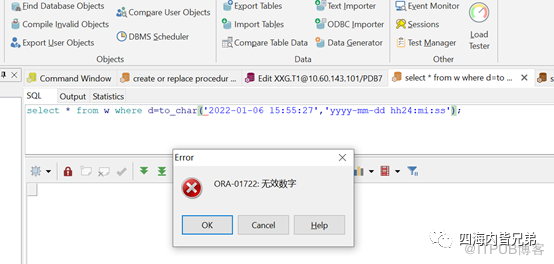
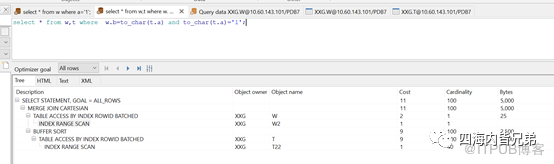
接下来,没有条件的关联。两个全表。不过由于两个列有一个是索引列(T表的ID列故意不是),不至于笛卡尔积。cost不大。
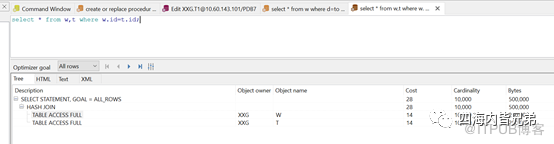
当有索引列带上索引,立刻看到只找一行,相对来说总的cost变化小了大约一半。
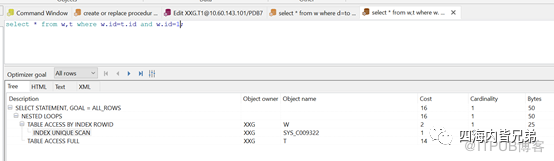
条件从w.id换成t.id,验证优化器的SQL改写。与MySQL一样。(下一次看PG的估计也是一样,这是基本逻辑)
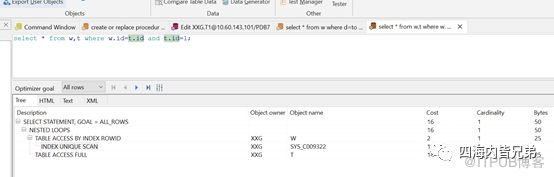
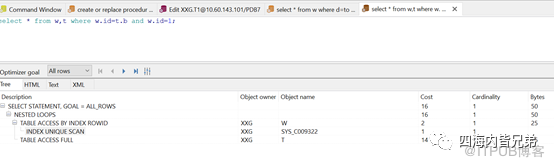
都是索引列且类型匹配情况下:效果很好。
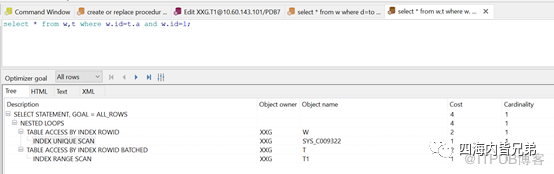
当关联列数据类型不匹配时候:就和没建立索引是一样的效果了。
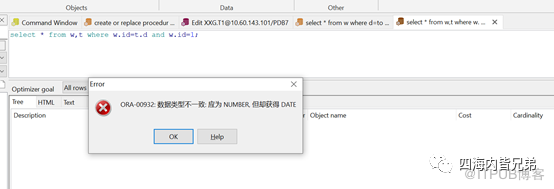
如果类型差距较大,直接报错。
继续:w.b是字符型,w.b和t.c关联。t.c是小数类型。尽管不匹配但是最终cost和匹配的几乎一样。这里Oracle处理的比MySQL好。
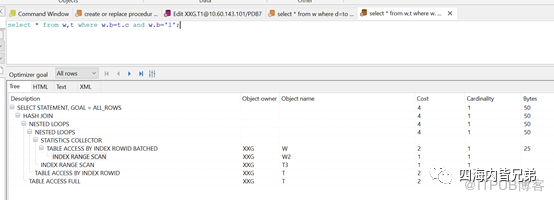
w.c是小数型,w.c和t.b关联。t.b是字符类型。条件是w.b字符型。关联列不匹配,导致一个表全表。
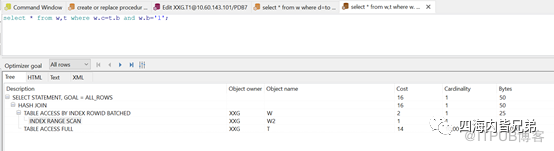
最后看看类型转换。w.a是数值型,一旦转换(在等号左边转换)就是全表,索引失效。
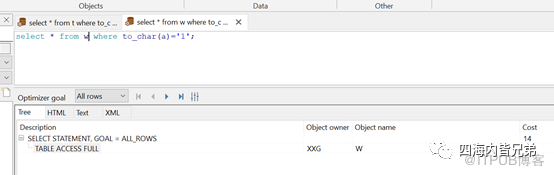
在T表上给A建立一个函数索引。所以在T表上用同样的语句,则用到了索引T22.
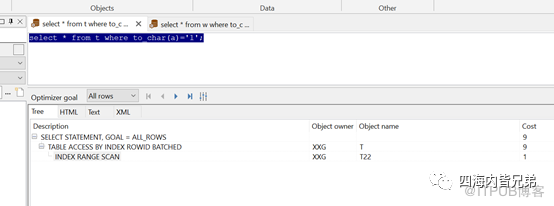
解决问题的思路就是让数据类型匹配。大概不匹配时候如下:
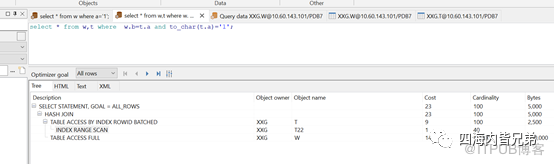
改成这样就可以了。虽然这不是推荐的,但是已经类型不对的场景下的下下策。上上策还是表的类型要选择对。