前两次是Oracle和MySQL的。今天来一个PostgreSQL的。
x=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | a | table | postgres
(1 row)
x=# create table w (id int,a int,b varchar(10),c decimal(10,0),d date,primary key (id));
CREATE TABLE
x=# insert into w values (1,1,1,1,now());
x=# insert into w values (2,2,2,2,now());
x=# insert into w values (3,3,3,3,now());
x=# insert into w values (4,4,4,4,now());
x=# insert into w values (5,5,5,5,now());
x=# insert into w values (6,6,6,6,now());
x=# insert into w values (7,7,7,7,now());
x=# insert into w values (8,8,8,8,now());
x=# insert into w values (9,9,9,9,now());
x=# insert into w values (10,10,10,10,now());
如图。

这里遇到了一个和Oracle一样的问题,就是10条数据的索引建立和没建立一个样。都不用索引。
其实PostgreSQL有的场景挺像Oracle,语法有不少和MySQL相近。感觉就是介于两者之间的。
这个场景下看执行计划其实是看不出来的。和Oracle一样,对小数量级别不敏感。不屑一顾,10条数据的全表查询也就顺带做了。
写个存储过程补1万数据进去。
create or replace function us() returns
boolean AS
$BODY$
declare i integer;
begin
i:=1;
FOR i IN 1..10000 LOOP
INSERT INTO w (id,a,b,c,d) VALUES (i,i,i,i,now());
end loop;
return true;
end;
$BODY$
LANGUAGE plpgsql;
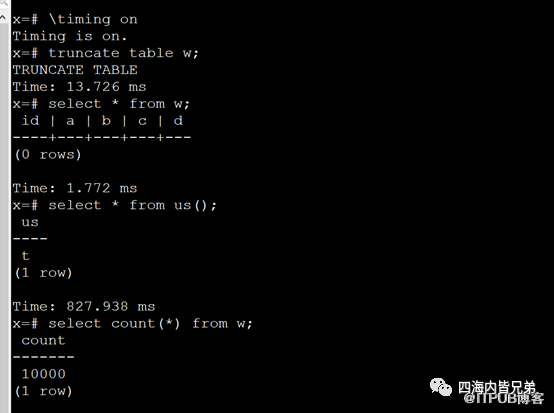
可以看出写入1万条数据也就0.8秒左右。这是一个普通的虚拟机。环境很普通。这个性能不错了。
所以大家只要是正常使用数据库现如今的数据库单机就能满足绝大多数应用。甚至不少NoSQL和消息队列等都不需要就可以满足。甚至我觉得大部分公司都不具备大数据场景。即使具备,类似Oracle、PostgreSQL也能处理。
来看一下执行计划。id=1如下图。和预期一样。a=1也和预期一样。b=1这里就不一样了。直接报错。说类型不对等。
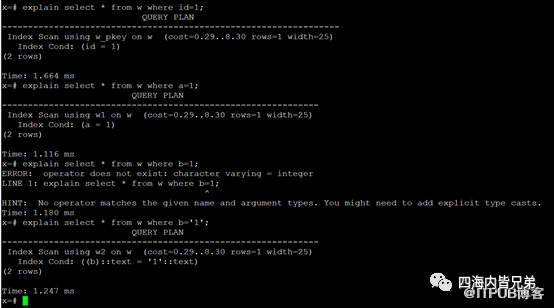
遇到b='1'又是正确的了。
好了做到这里我觉得基于前两次的实验很多就不用做了。因为类型不匹配是无法做下去的,那么有些问题就不是问题了。
我用的是PostgreSQL14版本。这里我还没研究过是不是可以调整参数忽略数据类型不一致?也不知道有没有。
但是我觉得这个默认的挺好的。就应该这样。严谨是为了后续问题少。
我们直接到函数环节。可以看出如果不带函数转换还是出错的。
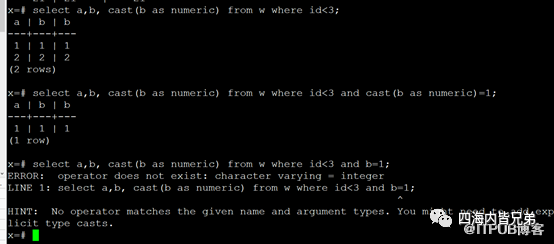
建立函数索引以后,直接可以识别用到了。
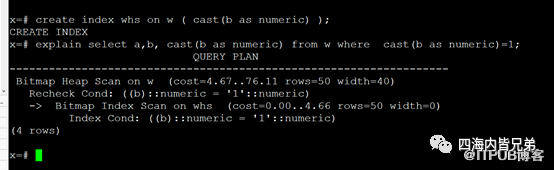
可见天下数据库基本原理差不多。当一个数据库用不好使用,换其他数据库,放心也用不好。
反过来一个数据库玩的溜的、换其他的数据库问题不是太大。