




1. gbase 8a hint简述:
Hint 是GBase提供的一种SQL语法,它允许用户在SQL语句中插入相关的语法,从而影响SQL的执行方式。使用hint主要是将集群的hint发到node层上去,也就是/*+ … */不会直接被客户端忽略而会发送到server 端。
hint使用约束:
当使用gccli客户端登录集群时,如果要使用hint,需要使用-c参数,即 gccli -uxxxx -pxxxx -hxxxx -c方式登录集群。
-c 参数的作用,让hint也就是/*+ … */不会直接被客户端忽略,会发送到server 端。
对于采用JDBC、ODBC连接GBase的应用端查询,已默认开启类似客户端 -c -q参数。
具体gbase 8a支持的hint类型可以参考其他gbase 8a文档,本文中只介绍 grouped('-1') hint用法及实际使用案例
2. grouped('-1') hint 效果及原理:
grouped('-1') 类型hint主要控制 select ... from ... 类型语句中的from 子句数据在节点间的重分布方式,hint中的 -1 表示按照随机方式均匀分布。
这个hint可以解决目标表为随机分布表,insert select的select部分数据在各节点的分片分布不均的问题。
简单举例说明:
t_target 随机分布表
t_source hash分布表或随机分布表
如下sql:
insert into t_target select * from t_source
在集群中的执行计划示意图如下:
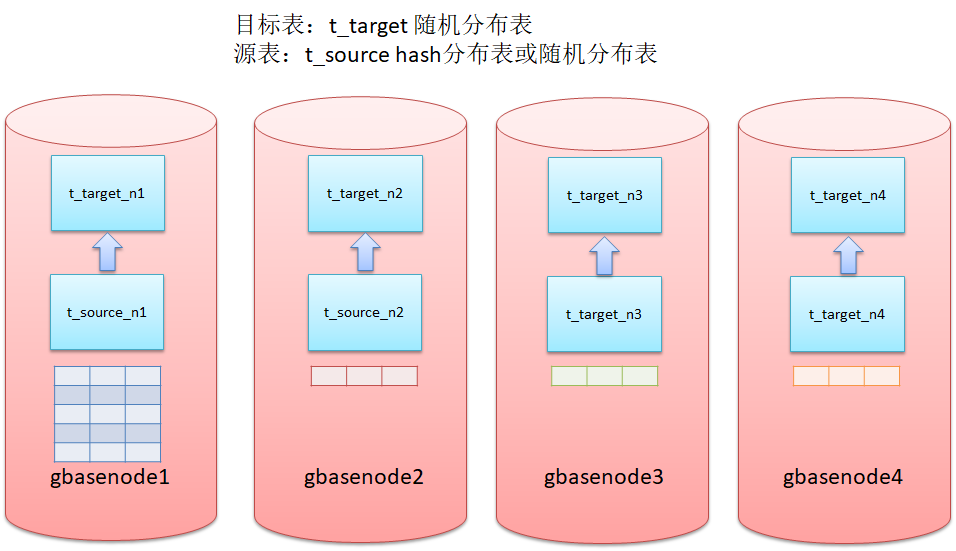
由上图可见,默认执行计划中由于目标表是随机分布表,则源表无论是hash分布表还是随机分布表,insert into可以在各节点上直接执行,即源表的对应分片数据直接插入目标表对应分片,整过insert select过程无节点间数据重分布。
这种执行计划将导致如果源表的数据发生倾斜,目标表中的数据将出现相同的倾斜分布。
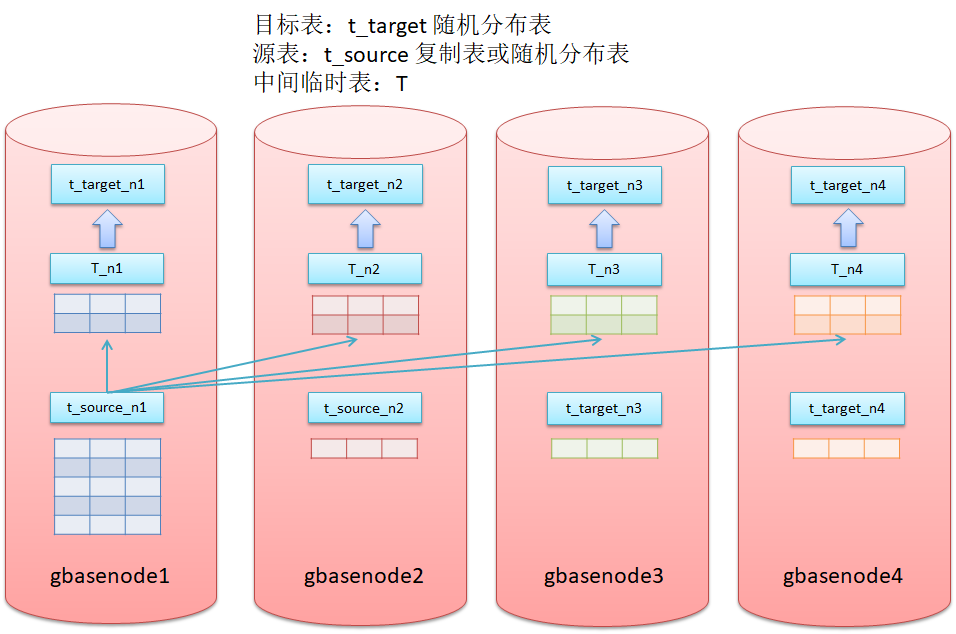
如果采用grouped('-1') hint,则可以强制生成一个中间表并重分布在节点间不均匀分布的数据,之后在插入目标表就可以实现目标表中数据的均匀分布,化简hint用法和执行原理图如下:
insert into t_target select */*+ grouped('-1') */ from ( select * from t_source) T
3.实际hint优化案例:
具体原始SQL语句如下:
insert
into
TR_BDGPAYOUT_NORM_CJ3_1
select
20000000,
'2020-03-31'
as D_ACCT,
b.S_TRECODE,
b.S_OFCOUNTYTRECODE,
b.S_OFCITYTRECODE,
b.S_OFPROVTRECODE,
a.S_STATSBTCODE
as S_STATFUNCSBTCODE,
'NNNNNNNNNNNNNNNNNNNNNNNNNNNNNN'
as S_STATECOSBTCODE,
'NNNNNNNNNNNNNNN'
as S_BDGORGCODE,
'NNNNNNNNNNNN'
as S_BNKCODE,
'NN'
as S_BNKCLASS,
a.S_STATSBTKIND
as S_BDGKIND,
a.S_STATSBTLEVEL
as S_BDGLEVEL,
rand()*
100000.00 as F_DAYAMT,
0.0
as F_TENDAYSAMT,
0.0
as F_MONAMT,
0.0
as F_QUARTERAMT,
rand()*
10000000.00 as F_YEARAMT,
a.S_STATSBTSORT,
a.S_STATSBTLEVEL,
b.S_TRELEVELEXTEND,
b.S_TRECODE
as S_RPTSNDTRECODE
from
TP_STATSBT a,
TP_TREASURY
b
where
a.I_YEAR
= 2020
and
a.S_STATSBTSORT = 2
and
a.S_IFMINITEM = 1
and
b.i_year = 2020
;
此步骤为第一个数据生成SQL语句,作为起始语句后续数据汇总操作均在此步骤产生数据上进行。后续语句类型特点为,在第一步生成数据的表基础上进行group by汇总操作,具体如下:
insert
into
TR_BDGPAYOUT_NORM_CJ3_1
select
20000000,
'2020-03-30'
as D_ACCT,
S_TRECODE,
S_OFCOUNTYTRECODE,
S_OFCITYTRECODE,
S_OFPROVTRECODE,
substr(
a.S_STATFUNCSBTCODE,
1,
7
)
as S_STATFUNCSBTCODE,
S_STATECOSBTCODE,
S_BDGORGCODE,
S_BNKCODE,
S_BNKCLASS,
S_BDGKIND,
S_BDGLEVEL,
sum(
F_DAYAMT ) as F_DAYAMT,
sum(
F_TENDAYSAMT ) as F_TENDAYSAMT,
sum(
F_MONAMT ) as F_MONAMT,
sum(
F_QUARTERAMT ) as F_QUARTERAMT,
sum(
F_YEARAMT ) as F_YEARAMT,
S_STATSBTSORT,
S_STATSBTLEVEL,
S_TRELEVELEXTEND,
S_RPTSNDTRECODE
from
TR_BDGPAYOUT_NORM_CJ3_1
a
where
D_ACCT
= '2020-03-31'
and
length(S_STATFUNCSBTCODE)>= 7
and
length(S_STATFUNCSBTCODE)<= 9
group by
S_TRECODE,
S_OFCOUNTYTRECODE,
S_OFCITYTRECODE,
S_OFPROVTRECODE,
substr(
a.S_STATFUNCSBTCODE,
1,
7
),
S_STATSBTSORT,
S_STATECOSBTCODE,
S_BDGORGCODE,
S_BNKCODE,
S_BNKCLASS,
S_BDGKIND,
S_BDGLEVEL,
S_STATSBTLEVEL,
S_TRELEVELEXTEND,
S_RPTSNDTRECODE
;
由于第一步生成数据产生cross
join所使用的的表TP_STATSBT
a,TP_TREASURY b均为数据量较小的维表(TP_STATSBT
6150rows,tp_treasury 17079rows),在支出数据自有查询场景中这些表作为维表与基于TR_BDGPAYOUT_NORM表创建的视图VW_TR_BDGPAYOUT_NORM进行join连接操作,因此从建模星型模型优化的角度,将此两个小表建为复制表(即每个节点上均有一份全量表数据)。由于第一步生成数据的cross join所使用的两表均为复制表,因此执行时会随机选择集群中的一个节点作为执行节点,在该节点上两个表的全量数据产生的叉乘结果集将被插入目标表的本地分片中(本例中的目标表TR_BDGPAYOUT_NORM_CJ3_1为随机分布表),也就是说执行此步骤后,将在目标表TR_BDGPAYOUT_NORM_CJ3_1中产生数据倾斜,此步骤产生的所有结果数据均会存储在集群中的一个节点下。具体如下示意图:
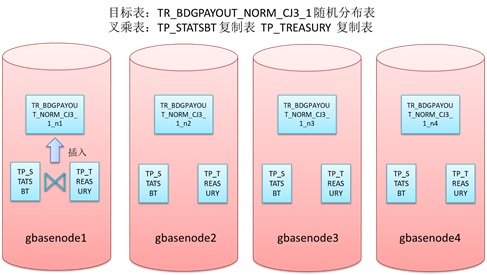
由于第一步生成数据时产生了数据分布上的倾斜,后续针对基表TR_BDGPAYOUT_NORM_CJ3_1的汇总操作均会出现由于基表TR_BDGPAYOUT_NORM_CJ3_1数据分布不均造成的倾斜和负载不均问题,上图所示的gbasenode1节点将成为后续汇总计算的瓶颈。
针对这种由于计算过程中产生的数据分布倾斜问题,需要考虑将第一步产生的数据通过重分布的方式均匀分布到集群所有节点上,这样就避免了后续步骤中使用基表数据时会遇到的数据分布倾斜问题,各节点相对均衡的数据量和负载将提升后续sql的执行性能。测试中采用了在第一步的SQL语句中加入hint方式,指示优化器生成一个多出来的数据重分布步骤,从而将插入到目标表上的数据得以均分。
具体改写方法如下:
insert
into
TR_BDGPAYOUT_NORM_CJ3_1
(
I_ENROLSRLNO,
D_ACCT,
S_TRECODE,
S_OFCOUNTYTRECODE,
S_OFCITYTRECODE,
S_OFPROVTRECODE,
S_STATFUNCSBTCODE,
S_STATECOSBTCODE,
S_BDGORGCODE,
S_BNKCODE,
S_BNKCLASS,
S_BDGKIND,
S_BDGLEVEL,
F_DAYAMT,
F_TENDAYSAMT,
F_MONAMT,
F_QUARTERAMT,
F_YEARAMT,
S_STATSBTSORT,
S_STATSBTLEVEL,
S_TRELEVELEXTEND,
S_RPTSNDTRECODE
)
select * from (
select
/*+
grouped('-1') */
20000000,
'2020-03-31'
as D_ACCT,
b.S_TRECODE,
b.S_OFCOUNTYTRECODE,
b.S_OFCITYTRECODE,
b.S_OFPROVTRECODE,
a.S_STATSBTCODE
as S_STATFUNCSBTCODE,
'NNNNNNNNNNNNNNNNNNNNNNNNNNNNNN'
as S_STATECOSBTCODE,
'NNNNNNNNNNNNNNN'
as S_BDGORGCODE,
'NNNNNNNNNNNN'
as S_BNKCODE,
'NN'
as S_BNKCLASS,
a.S_STATSBTKIND
as S_BDGKIND,
a.S_STATSBTLEVEL
as S_BDGLEVEL,
rand()*
100000.00 as F_DAYAMT,
0.0
as F_TENDAYSAMT,
0.0
as F_MONAMT,
0.0
as F_QUARTERAMT,
rand()*
10000000.00 as F_YEARAMT,
a.S_STATSBTSORT,
a.S_STATSBTLEVEL,
b.S_TRELEVELEXTEND,
b.S_TRECODE
as S_RPTSNDTRECODE
from
TP_STATSBT
a,
TP_TREASURY
b
where
a.I_YEAR
= 2020
and
a.S_STATSBTSORT = 2
and
a.S_IFMINITEM = 1
and
b.i_year = 2020
) T
改写后的SQL在原SQL的SELECT部分包装饿了一层子查询,并在子查询内层的SELECT部分加入了hint /*+
grouped('-1') */,这个hint的左右是指示优化器将子查询中的SELECT部分做一次重分布插入外层子查询包围的临时表中:

此步骤的效果如下图所示:
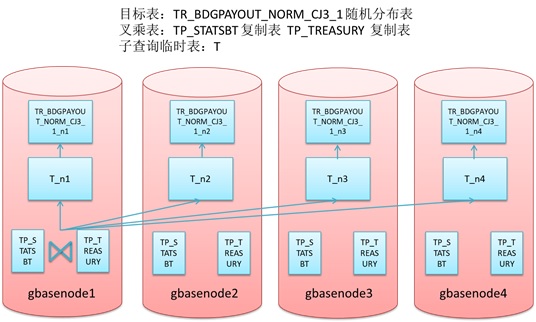
经过重分布后数据可以在目标表TR_BDGPAYOUT_NORM_CJ3_1各节点分片上均匀分布,再执行后面基于该表的group by汇总操作时由于数据分布均匀,执行性能也得到提升。
该场景在进行修改前执行时间为164s,进行SQL优化后执行时间为98s,性能提升40%。
